


















































Нейросеть для анализа резюме 1С-специалистов
(маленький эксперимент на базе реальных вакансий)
Недавно я пошёл учиться на программу по искусственному интеллекту.
В рамках учебной практики нам дали задачу:
Сделать сервис анализа резюме кандидатов на основе данных вакансий.
В базовом задании предполагалось взять около 100 вакансий из любой области и построить систему, которая:
- анализирует резюме
- извлекает навыки
- сравнивает их с требованиями рынка
- показывает рекомендации.
Но мне показалось странным делать универсальную модель.
Поэтому я решил попробовать сделать локальную версию для рынка 1С.
Причины простые:
- рынок достаточно специфический
- вакансии имеют понятную структуру
- роли часто смешаны (консультант / аналитик / программист / архитектор)
Кроме того, мне самому было интересно посмотреть как сейчас распределены роли на рынке 1С.
Времени на проект было немного (это был хакатон), поэтому получился рабочий прототип, но сам подход оказался довольно интересным.
Исходный код проекта:
GitHub:
https://github.com/graphbuh/1c-resume-coach
Как работает система
Идея достаточно простая.
Мы берём:
вакансии → извлекаем навыки → строим профиль роли
резюме → извлекаем навыки → сравниваем с рынком
На выходе система показывает:
- предполагаемую роль кандидата
- найденные навыки
- недостающие навыки
- рекомендации
Система работает полностью локально.
Архитектура решения
Pipeline проекта выглядит так:
вакансии
↓
очистка и дедупликация
↓
извлечение навыков
↓
классификация ролей
↓
профили рынка
↓
анализ резюме
↓
gap-анализ
↓
рекомендации
Сбор данных
Я собрал вакансии из двух источников:
- HeadHunter
- Telegram-каналы с вакансиями 1С
Вакансии сохранялись в текстовом виде.
После очистки и удаления дублей получилось:
562 исходных вакансии (скачал 2 марта 26 года за последнюю неделю)
467 уникальных вакансий (с март 25 года по 2 марта 26 года)
Удаление дублей делалось в два этапа:
- точные дубли (hash текста)
- похожие вакансии (TF-IDF + cosine similarity)
В итоге финальный корпус — 467 вакансий.
Построение словаря навыков
Следующая задача — понять:
какие навыки вообще встречаются в вакансиях.
Для этого я использовал TF-IDF и n-граммы.
Из текста вакансий извлекаются:
1-граммы
2-граммы
3-граммы
Например:
СКД
язык запросов
управляемые формы
1С: ERP
система компоновки данных
После этого получаем список наиболее частых терминов.
Но TF-IDF выдаёт и мусор:
график работы
оформление по ТК
дружный коллектив
Поэтому финальный словарь чистился вручную.
В итоге получился словарь навыков, включающий:
- платформу 1С
- типовые конфигурации
- интеграции
- базы данных
- бизнес-процессы
- архитектуру
- dev-tools
Извлечение навыков
Далее словарь применяется к вакансиям.
Для каждой вакансии извлекается список навыков.
Например:
language_1c
queries
skd
erp
integration_http
mssql
Таким образом каждая вакансия превращается в структурированный профиль навыков.
Классификация ролей
Следующий шаг — определить роль вакансии.
Я использовал rule-based модель.
Поддерживаются роли:
programmer
analyst
consultant
architect_technical
architect_functional
hybrid
Например:
Programmer
сигналы:
язык 1С
запросы
СКД
SQL
оптимизация
Consultant
сигналы:
внедрение
консультирование
обучение пользователей
регламентированный учет
Architect
сигналы:
architecture
integration architecture
tech lead
mentoring
Что получилось по рынку
После классификации вакансий распределение ролей получилось таким:
consultant: 135
architect_functional: 100
programmer: 89
analyst: 41
architect_technical: 26
hybrid roles: 76
Меня больше всего интересовали Архитекторы, поэтому по ним я взял все вакансии за период…
Несколько интересных наблюдений:
- консультанты — самая большая категория
- функциональных архитекторов больше, чем технических
- гибридных ролей довольно много
Это хорошо совпадает с тем, что видно на рынке.
Нейросеть
В задании было требование обучить нейросеть.
Я попробовал baseline модель:
TF-IDF + MLPClassifier
Задача:
role classification
Результат:
accuracy ≈ 0.35
Для 8 классов это лучше случайного выбора, но недостаточно хорошо для продакшена.
Причины:
- маленький датасет (467 вакансий)
- роли пересекаются
- много HR-шума в тексте
Поэтому итоговая архитектура стала гибридной:
rules + словарь навыков + ML scoring
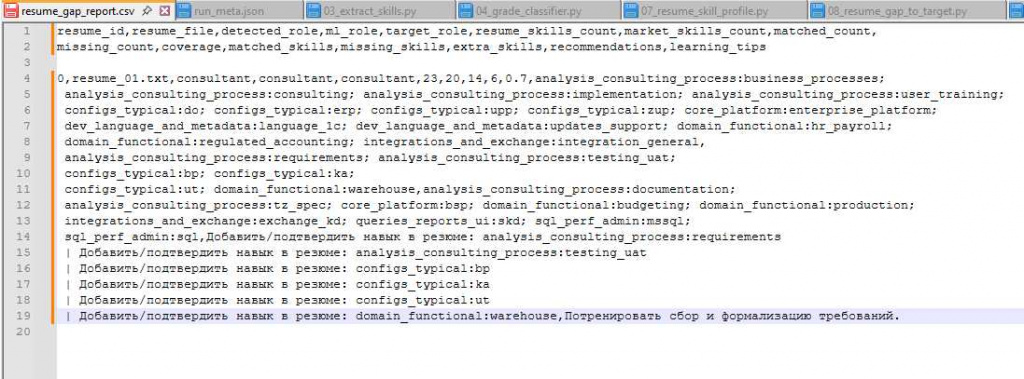
Анализ резюме
Далее система анализирует резюме.
Алгоритм:
1 извлекаем навыки
2 определяем роль
3 строим профиль
Пример результата:
skills found: 23
role: consultant
Gap-анализ
После этого выполняется сравнение с рынком.
Система смотрит:
какие навыки есть
каких навыков не хватает
И рассчитывает coverage.
Например:
coverage = 0.70
Это означает, что кандидат покрывает примерно 70% требований рынка для этой роли.
Интерфейс
Для демонстрации я сделал простой интерфейс на Streamlit.
Он позволяет:
- загрузить резюме
- запустить анализ
- увидеть навыки
- посмотреть gap-анализ
- получить рекомендации.
Как попробовать
- скачать проект с GitHub
- перевести резюме в txt
- положить файл в папку
data/resumes_txt
- запустить
streamlit run scripts/09_streamlit_app.py
После этого откроется веб-интерфейс.

Что можно улучшить
Этот проект — прототип, поэтому есть очевидные направления развития:
- добавить больше вакансий
- научить систему читать PDF
- улучшить модель ролей
- использовать LLM для генерации рекомендаций
- добавить карьерные траектории
Итог
Даже простой прототип показал несколько интересных вещей:
- рынок 1С хорошо структурируется по навыкам
- роли сильно пересекаются
- rule-based подход с хорошим словарём работает лучше, чем маленькая нейросеть
Проект получился небольшим, но он хорошо показывает, как можно применять NLP и машинное обучение для анализа рынка вакансий.
Вступайте в нашу телеграмм-группу Инфостарт


{kind=link}