Хочется начать с небольшой провокации: сейчас бесплатные ИИ-модели массово интегрируются в продукты 1С – через сервер, напрямую и другими способами. Все это рассматривается всерьез как механизм прогресса, в котором мы живем и существуем. Однако в реальности работа с ИИ ушла намного дальше.
Возьмем, к примеру, DeepSeek – модель продемонстрировала очень высокие финансовые результаты, в том числе успешно торгуя акциями на фондовом рынке. В прошлогоднем эксперименте Гонконгского университета (HKU) DeepSeek на Nasdaq-100 показал 10,61% годовой доходности, обогнав GPT, Claude и индекс QQQ, полагаясь только на цены, новости и ордера без предустановок. Deep Seek используется для автоматизации торговых ботов (интеграция с TradingView), анализа настроений рынка, обнаружения мошенничества и управления рисками в банках. В сценариях с предустановками под конкретные рынки система была еще более эффективна.
Тот, кто сейчас раньше конкурентов создаст ИИ-систему, которая превзойдет остальные, возьмет весь банк. Именно этим объясняется жесточайшая схватка за первенство в сфере ИИ.
Первые практические кейсы ИИ в Документообороте
На сегодня доступен целый ряд типовых или дорабатываемых возможностей применения ИИ в 1С:Документооборот:
-
Распознавание документов и текста (OCR) и, как следствие, автозаполнение карточек документов, классификация и маршрутизация документов, проверка комплектности.
-
Предиктивный анализ процессов: прогнозирует задержки в согласованиях и движении документов.
-
Речевые технологии (STT/TTS): перевод речи в текст и наоборот, протоколирование совещаний и создание поручений (задач).
-
Виртуальный помощник (чат-бот Ася): поиск файлов, создание задач, ответы на вопросы 24/7.
-
ИИ-ассистент для разработчиков и аналитиков (1С:Напарник).
-
Интеграции с внешними LLM-моделями (GigaChat, YandexGPT) для расширенной аналитики.
-
Поиск по семантике – по смыслу документов.
Помимо типового функционала и доработок, если говорить именно о кейсах внедрения ИИ в целевые системы 1С:ДО, то сейчас на практике тестируются или используются преднастроенные ИИ-ассистенты на базе LLM в разных ролях, выступающие помощниками в работе с документами. Они проводят анализ, сравнение, формируют резюме, оценку рисков, юридические заключения.
Трансформация документа: от бумажного артефакта к активу
Бумажный документ, с которым мы все были знакомы и который в первую очередь определял организационно-распорядительные инструкции, стал из двухмерного многомерным. Кто знаком с SAP, знает, какое количество служебных полей, которые двигают его по процессу, несет документ. Фактически сейчас документ в СЭД – это актив, ценность. Она меняется в ходе движения по бизнес-процессу, начинает влиять на все остальное.
Если говорить честно, все СЭДы стали в каком-то смысле «потогонной» системой. Для всех белых и синих воротничков это угроза, это «морковка», которая не только висит перед тобой, но и подталкивает тебя сзади. Электронный документ как часть бизнес-процесса стал мощным инструментом влияния на жизнь среднего офисного работника.
Проблемы человеческого фактора и надежды на ИИ
По-прежнему основная причина появления ошибок в СЭД – человеческий фактор. Там, где машина работает как надо, человек допускает колоссальное количество проблем. Исследования говорят о том, что в крупных корпорациях человек делает ошибок на 20 тысяч долларов в год, а стресс испытывают 67% сотрудников.
Сейчас те, кто пользуется СЭД, тратят больше трех часов в день на поиск, обработку информации, согласование и прочее. Рутина никуда не делась, и она серьезно влияет на то, что происходит. Искусственный интеллект здесь рассматривается как панацея, потому что считается, что уже через пару лет почти три четверти решений с документами будет приниматься на стороне ИИ.
Парадокс документного оборота: меньше документов – больше эффективности
Лучший документооборот – тот, в котором минимум документов. Правильный процесс идет таким путем, что начинает влиять на происходящее, не требуя лишней подписи или согласования.
В классических СЭД документ – главный объект: все крутится вокруг его создания, согласования, подписания, хранения.
В подходе оркестрации процесс становится первичным, а документ – лишь один из возможных артефактов, который возникает там, где это нужно регуляторно или юридически, но не диктует ход работы. Современные СЭД/BPMS платформы именно так и устроены: они хранят состояние процесса, решения и события, а документы прикладываются только на тех шагах, где без них нельзя.
Хороший пример «документооборота без документов» – кейсы управления доступами (IDM), реализованные на связке IDM системы и Camunda BPM.
В кейсе Comindware Platform оркестрация выстраивает сквозной процесс «от заявки до оплаты» между BPMS и учетными системами («1С/ERP»).
Пользователь создает заявку на оплату в BPMS. Дальше платформа:
-
автоматически сверяет ее с бюджетными лимитами,
-
отправляет на согласование нужным ролям,
-
после утверждения передает данные в 1С для формирования платежных документов,
-
затем ежедневно получает из 1С фактические оплаты и автоматически контролирует превышение лимитов, уведомляя ответственных.
В кейсе фармкомпании, описанном Citeck, СЭД/BPMS решение развернули как «надстройку» над существующими системами согласования юридической службой и бухгалтерией, чтобы не трогать их схему данных и не переносить документы.
Процессы согласования договоров, заявок и операций были перенесены в СЭД/BPMS: пользователи работают с задачами и статусами, а не с файлами договоров. Документы остаются в привычных системах (ECM, 1С, файловые хранилища), а оркестратор через интеграции включает их в нужные шаги – подгружает версии, отслеживает сроки, инициирует согласование.
Эволюция СЭД: от цифрового архива к адаптивной системе
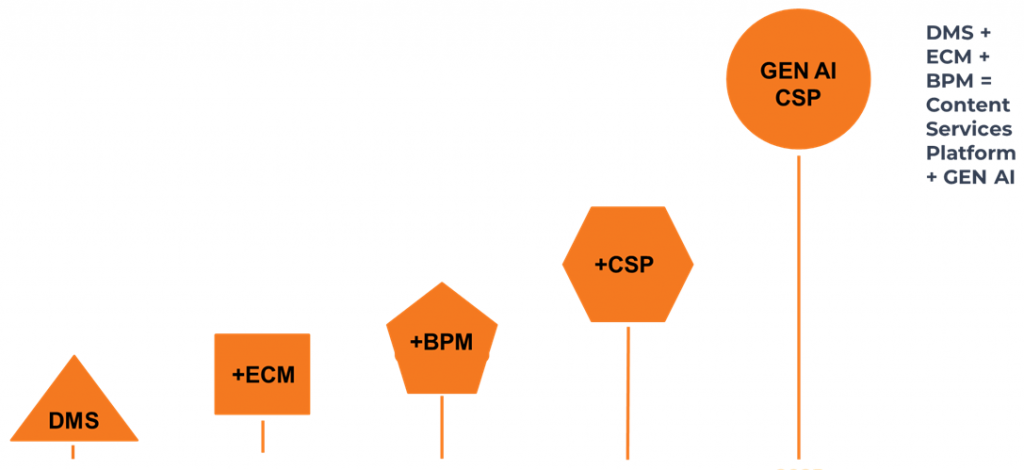
Хочется сказать несколько слов об эволюции СЭД.
К 2000 году, когда вертикально интегрированные компании создавали электронные архивы, в целях минимизации рисков оставляли три электронные копии в разных местах.
Позже началась интеграция с внешними системами. К 2010 году появилась работа с контентом и базовые стандарты в отрасли: метаданные, их хранение и обработка. И, наконец, началось влияние документов на движение всего бизнес-процесса.
К настоящему моменту adaptive case management стал мейнстримом, когда документ изменяет процессы, влияет на поведение людей, отслеживает ошибки, отлавливает трансформацию связанных документов и, собственно, создает эту трансформацию. К ней начал подключаться искусственный интеллект. Многие коллеги тестируют ИИ-сотрудников, комментарии, для этого и добавляют LLM-модели.
К 2024 году все модели, связанные с распознаванием голоса и текста, стали работать достаточно хорошо. Общее движение СЭД – открытый мир. Документы обычно «живут» в закрытой системе, но сегодня все поменялось: мессенджеры, хостинги, внешние коммуникации. Это потребовало открытого API и работы с интеллектуальными процессами: распознавания текстовых слоев, их увязку с другими документами и процессами.
Современные технологии обработки документов: IDP и семантика
Общий тренд сейчас – развитая система СЭД, фактически комплексный процесс IDP.
Он включает в себя технологии оптического распознавания, семантику для извлечения из текста смыслов, чтобы комментировать документ и двигать его по процессу.
Технология, которая уже состоялась – распознавание изображения. Простейший пример – фотосъемка битой машины: она соединяется с документами, текстовые слои присоединяются, запускается расчет на основании битых деталей. В результате мы получаем примерную сумму ущерба. Это IDP-процесс, который так в настоящее время работает и в России.
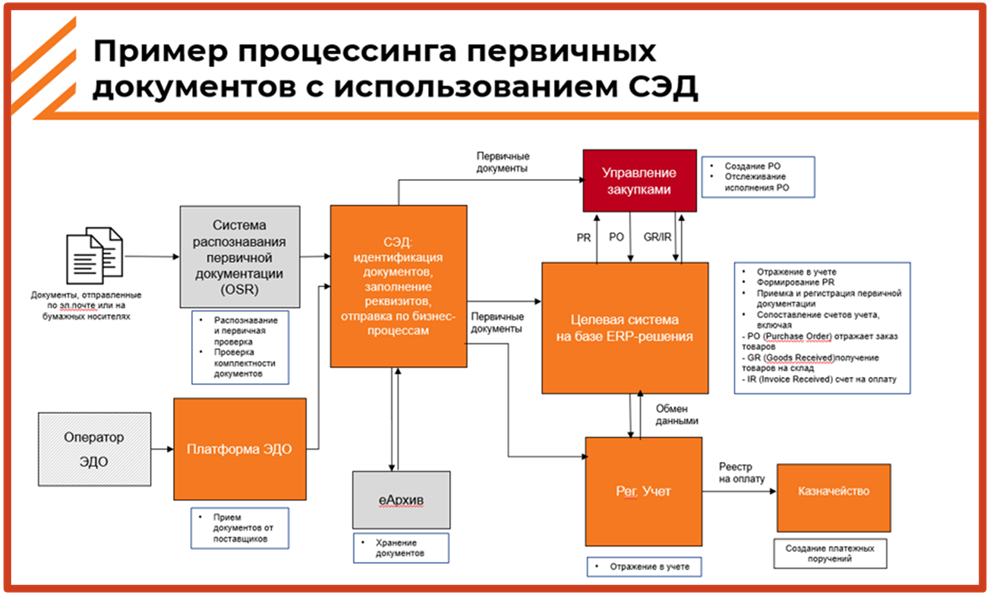
Как это работает в документообороте: корпоративный СЭД принимает через распознавание первичную документацию, берет документы из ЭДО и начинает двигать по процессу – в Directum, в ELM.
В рамках нашего решения платформы GenAI, которая позволяет создавать цифровых помощников на базе технологий генеративного ИИ, мы тренируем своих ассистентов, которые могут оказывать влияние на процессы в СЭД, проводим с ними активные эксперименты.
И, конечно, есть привязка к внешним генеративным моделям, которые позволяют в большое контекстное поле формировать более локализованные запросы.
Архитектурные принципы и сквозные паттерны платформы
Архитектурные принципы и сквозные паттерны ИИ-платформы для СЭД – это безопасность, валидация, аудит, графы знаний, мультимодальность. От паттерна идем к техническому эффекту, бизнес-метрикам.
Критические факторы успеха – доменные векторные хранилища, четкие границы между генерацией и решением (human-in-the-loop), наблюдаемость (observability) и data governance. Нельзя все отдавать искусственному интеллекту, поскольку ошибка может быть критичной.
Генерация документов и риски доверия к ИИ
Сейчас стоит вопрос: искусственный интеллект – это соавтор? Огромное количество ошибок связано с соавторством со стороны бесплатных моделей искусственного интеллекта. 12% компаний, которые пользуются искусственным интеллектом в России, не доверяют им, потому что серьезно обжигались. По данным аналитической компании Gartner, к 2027 году 40% документов будет создаваться без участия человека.
В этой реальности требования к СЭД критичны, поскольку они находятся на переднем крае взаимодействия с данными: при работе с архивами мы пытаемся загрузить большие объемы информации в генеративную модель, чтобы она проанализировала их и выдала релевантный ответ. Однако здесь возникает техническое ограничение: без использования векторных баз данных (векторов) это работает неэффективно.
Мультимодальность, персонализация и кибербезопасность
ChatGPT 5 показывает впечатляющую производительность: мы и читаем, и делаем саммари больших документов, и анализируем изображения и рисунки, и все это – одновременно.
Мультимодальность современных ИИ-инструментов позволяет создавать их кастомное исполнение для разных специалистов. У бухгалтера – одни виджеты, у экономиста – другие, у аналитиков – еще один вариант исполнения. Человек работает с машиной, а она под него подстраивается: что ему дать, какую информацию в первую очередь, в каком виде и т.д.
Один из исследователей искусственного интеллекта бросил работу, когда обнаружил, что система «умный дом» в его доме включает свет в туалете раньше, чем он решил туда идти. Это реальный случай.
При этом искусственный интеллект уязвим к инъекциям, забросам негативной информации, технологиям накачки инъекциями кода. Есть много механизмов атаки на ИИ, и мы все с этим столкнемся, как только начнем массово его себе устанавливать.
По-прежнему ИИ-модели придумывают несуществующие факты и страдают галлюцинациями. Поэтому на выходе модели работает целый слой экспертных систем или модулей, которые верифицируют результат. Сама же модель прежде всего стремится к экономии вычислительных ресурсов: она анализирует, какие вопросы задает пользователь, и пытается направить запрос в тот экспертный слой, который способен выдать наиболее адекватный ответ, затратив при этом минимум ресурсов. Экономия на потреблении электроэнергии приводит к тому, что она может галлюцинировать еще больше.
Тренды и инструменты
CONTEXT / COGNITIVE ENGENEERING – новый термин, с которым все уже столкнулись. Сначала был промт-инжиниринг, потом контекст-инжиниринг, а сейчас когнитив. Это означает, что мы хотим работать с искусственным интеллектом, но должны обеспечить его данными, создать RAG-систему, задать векторы, обозначить все, с чем мы будем работать дальше. Мы обучаем его определенным образом взаимодействовать с нами.
Более того, нужно задавать ему динамику, объяснять, в каком случае и как он будет реагировать. Сейчас человек должен управлять вниманием агента, его памятью, благо такая возможность появилась. И управление рассуждениями, управление доказательностью – те принципы работы с искусственным интеллектом, которые сейчас используются при подготовке любого ИИ-ассистента.
В сфере искусственного интеллекта сегодня реализуется только каждый двадцатый проект. В ИТ в целом всерьез взлетает каждый третий. Это реальность. Взлетают проекты, авторы которых четко понимают, чего хотят.
Простой пример из нашей практики. На заводах компании в разных странах эксплуатируется огромное количество оборудования. Постоянно нужны запчасти – а база номенклатуры очень широкая. На то, чтобы обучить ИИ и получить рабочую «концепцию совместимости» (какие детали к чему могут подходить), ушел примерно месяц.
Дальше была обнаружена еще более ценная возможность: на тех же данных ИИ способен строить прогноз – когда конкретная деталь выйдет из строя.
Представляете, насколько быстро окупился этот месяц обучения на одном прикладном кейсе – и какие результаты он в итоге дал?
Еще один тренд, который надо учитывать – сквозная интеграция. Тот самый диалог, дизайн и интеграция с целевыми системами. Можно попытаться разобраться в конкретной конфигурации, получить ее слепок и с ним работать. Тому есть полноценные примеры.
Классификация агентов по Google и экономическая оценка ИИ
Google выделила шесть ключевых типов агентов:
-
клиентские;
-
внутренние;
-
кодовые;
-
с безопасностью;
-
с креативом;
-
доменные.
Есть масса публикаций, сотни успешных примеров по внедрению конкретных объектов на облачных технологиях Google.
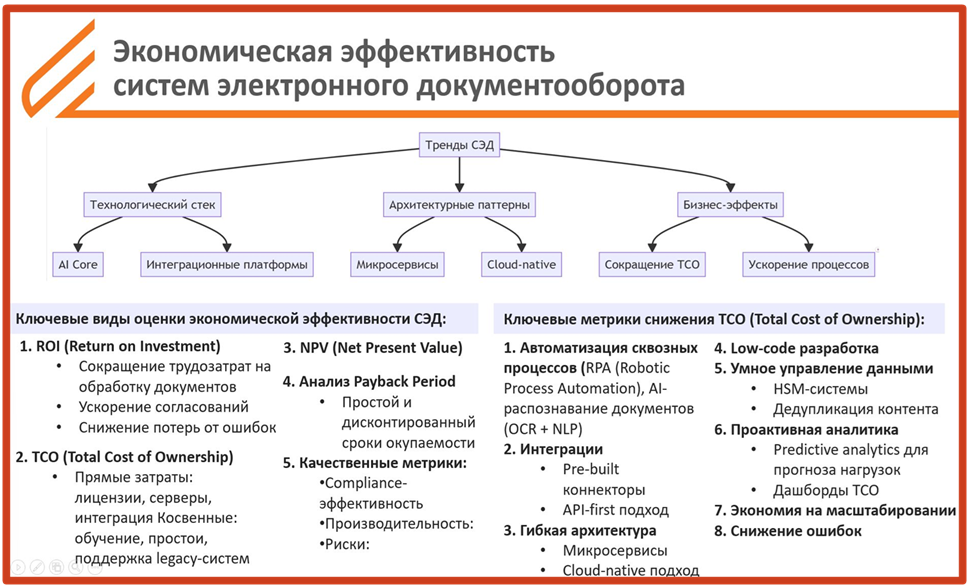
Все финансовые подразделения требуют от нас: «Как вы оцениваете эффективность? Посчитайте». Мы вынуждены были работать с оценкой экономической эффективности, изучением технологического стека, разбором архитектурных паттернов, бизнес-эффектов с тем, чтобы добраться до качественных и количественных критериев.
И оказалось, что при работе с искусственным интеллектом мы можем позволить себе все эти типовые механизмы. Более того, они хорошо считаются с помощью самого искусственного интеллекта: во что это обходится и какой эффект приносит.
Риски внедрения ИИ и необходимость контроля
Основные риски:
-
Контекстная слепота, когда генеративный искусственный интеллект не понимает логику и бизнес-специфику;
-
Раскрытие конфиденциальных данных;
-
Ложная информация и ее распространение;
-
Отравление данных;
-
Некорректная обработка выводов;
-
Все, что связано с инъекцией промптов;
-
Уязвимости плагинов, цепочек поставок и так далее.
Это неполный список. Например, надо понимать, что ИИ-агенты эволюционировали в операционные слои бизнеса, что несет целый ряд угроз.
Поэтому выводы такие: мы должны быть проактивны, не отдавать все искусственному интеллекту, вести контроль и четко понимать параметры, по которым его надо внимательно контролировать.
Прогнозы на будущее и заключение
Через пять лет 80% решений в документообороте будет принимать ИИ.
Актуальные тренды на сегодня:
-
Мультиагентные «рои». Одного агента мало: пока у вас нет того, кто его проверяет, того, кто тестирует, того, кто добивается от него более конкретного контекста, ничего не получится;
-
Приватное развертывание.
Почему акцент на платформенных решениях? За ними будущее всего направления в России: вертикально интегрированные компании слишком недоверчивы ко всем, кто предлагает облако.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.


Вступайте в нашу телеграмм-группу Инфостарт