Сначала расскажем, как получилось, что мы начали писать свои системы с нуля, а не взяли вендорскую коробку и стали ее дорабатывать. Затем обсудим плюсы и минусы такого подхода. После этого обозначим масштабы наших систем, чтобы было понятно, какого они размера, сколько в них работает пользователей и какие у них важные свойства.
Немного про нашу историю
В мире 1С большинство привыкло, что покупается коробочное решение, которое на протяжении всего жизненного цикла дорабатывается отделом разработки. На заре наших систем, примерно 15 лет назад, на рынке не было решения для покрытия бизнес-процессов заказчика. В некоторых подразделениях бизнес-процессы только налаживались или их вовсе не было, они создавались заново.
Специфика заказчика в том, что он занимается не только ритейлом, но и разработкой, производством одежды, инвентаря и спортивных товаров. Период планирования в компании коллекционный: весна-лето, осень-зима – две коллекции в год. На рынке не было готового решения, но у нас были отличные компетенции в разработке 1С. Мы решили написать на коленке MVP и показать заказчику: понравится – будем развивать, не понравится – быстро выбросим и выберем другое решение. Тогда слова MVP не было, мы это называли пилотированием продукта.
Мы написали пилотную систему, заказчику она понравилась. Система начала развиваться, появилась система управления закупками 1С Buying.
Проходили годы, система развивалась, к ней добавлялись новые функциональные блоки. В т.ч. крупный блок управления жизненным циклом товара (PLM). В подразделении мы параллельно с оптимизацией и созданием бизнес-процесса писали код. Это было пилотирование и макетирование одновременно.
Прошло 5–7 лет. В нашей системе помимо управления закупками и PLM появились дополнительные блоки: управление контрактами, согласование закупочных документов, часть MDM. В какой-то момент мы почувствовали все проблемы монолита. Развиваться было необходимо, но стало сложно, поэтому мы начали выделять крупные функциональные блоки в отдельные информационные системы.
Так как бизнес-процессы у заказчика уже были устоявшимися, мы делали это с оглядкой на них, пересматривая ошибки архитектуры и ориентируясь на современный рынок и технологии. В этот момент у нас появилась собственная библиотека подсистем, которая помогла оперативно выделять системы в блоки. В ней хранилась одинаковая функциональность (аналог БСП).
Код не только добавляется, но и удаляется. Так и наши системы со временем не только развивались, но и выводились из эксплуатации. Например, так произошло с нашей PLM-системой, созданной в самом начале: заказчик купил готовый коробочный блок, не на 1С, и доработал его под свои процессы.
Текущий ландшафт информационных систем
На текущий момент мы дорабатываем и сопровождаем следующие информационные системы:
-
Система 1С Buying – тот монолит, про который я говорил выше. Она автоматизирует закупочную деятельность компании.
-
Система POM (Purchase order management) – закупочная деятельность другой компании, которая входит в нашу группу компаний. Почему две системы? На этапе становления бизнес-процессов закупки этих компаний были настолько разными, что мы приняли решение разделить базы, и сейчас понимаем, что это было правильным.
-
Система SOM (Supplier order management) – согласование заказов с поставщиками товара.
-
Система Material management – управление предпродажной подготовкой товара.
-
Система Shipment documents – согласование отгрузочных документов.
-
Система Calendars – управление событиями разработки и производства товара.
Эволюция процесса разработки

Вместе с эволюцией наших систем происходила эволюция процесса разработки. В начальном состоянии было три разработчика. Вместо Jira, которой тогда не было, мы использовали блокноты и Excel. С ростом систем релизы становились все сложнее. Так мы пришли к тому, что нам необходимо написать свой таск-трекер, потому что подходящего решения на рынке не было. Мы написали его и назвали Inner Works. Он создан на 1С, это еще одна нетиповая система.
Ее ключевая особенность в том, что система учитывает изменения метаданных 1С. Мы видим по каждой задаче, какие метаданные изменены, и благодаря этому во время сборки релиза понимаем, какие метаданные нужно переносить, где есть конфликты, а какие переносить не нужно, потому что задачи еще не готовы. На ранних стадиях Inner Works, много лет назад, мы вносили эту информацию вручную в каждой задаче. Сейчас с современным стеком все делается автоматически. Теперь у нас есть Jira, CI-конвейеры, GitLab, прокси-хранилища, и в SonarQube разработчики быстро видят свои замечания. Сборка релиза стала гораздо легче.
Так искусственный интеллект видит наш процесс изменения разработки.

Устройство процесса разработки
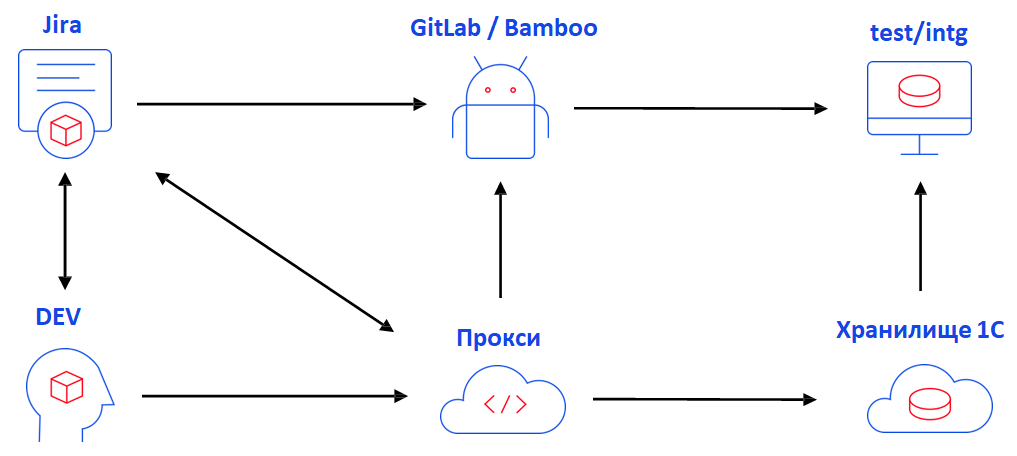
Есть разработчик, он берет задачу из Jira, делает работу и хочет поместить код в хранилище. Да, мы до сих пор разрабатываем в хранилище. Перед помещением кода он обращается к прокси хранилища, написанному собственноручно на OneScript. Прокси проверяет, что комментарий, указанный в хранилище, похож на задачу в Jira, что это действительно задача из Jira, что она существует, что исполнителем указан текущий разработчик, что она в правильном статусе, а так же выполняет множество других проверок. После этого, если все проверки пройдены, код уходит в хранилище.
Затем у разработчика два пути. Он может перевести задачу в статус code review, и тогда код будет перенесен на тестовые и интеграционные стенды. Перенос выполняется не из хранилища, а из репозитория, и переносится код именно по этой задаче. Либо, если статус не code review, он может нажать специальную кнопку деплоя в Jira, кастомную, и по этой задаче код также будет перенесен на интеграционную и тестовую среду.
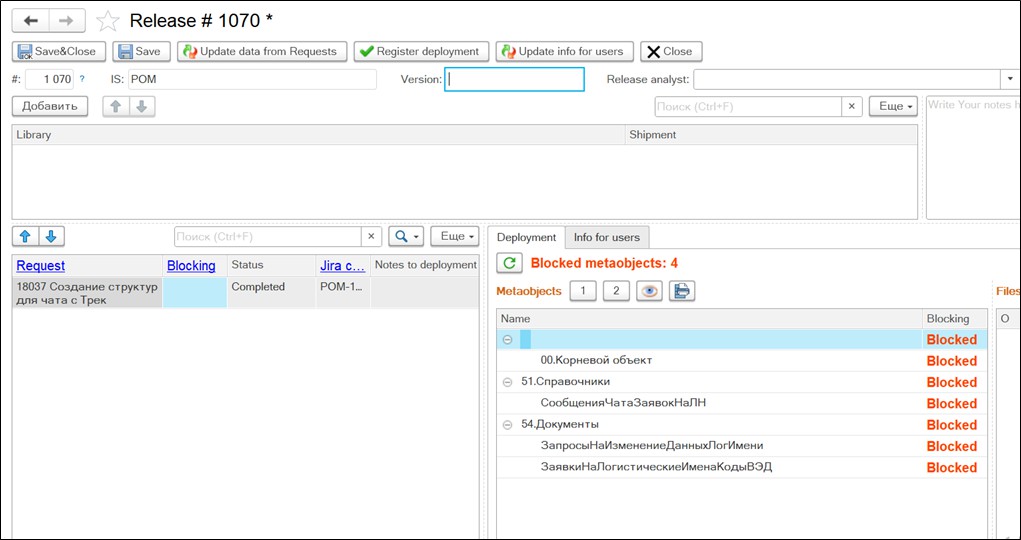
Релизы проходят раз в неделю. Вот так выглядит релиз в системе Inner Works. Для примера указана одна задача, и мы видим в дереве метаданных те метаданные, которые были изменены по ней. Таким образом мы понимаем, что нужно переносить в прод, а что не нужно. Мы видим это не только на уровне метаданных, а до третьего уровня.
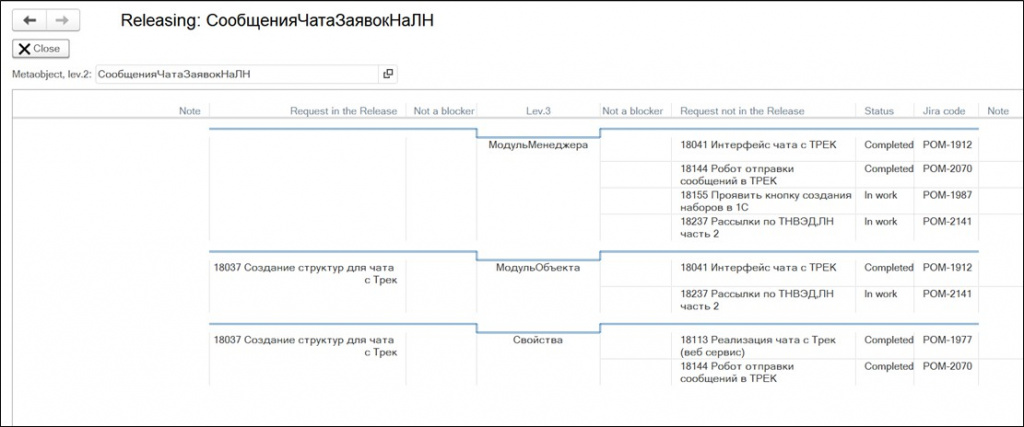
Например, мы можем понимать, что модуль объекта по конкретной задаче нужно переносить в релиз вместе с реквизитами – это указано в блоке свойств. А модуль менеджера сейчас переносить не нужно: изменения по нему относятся к другим задачам, которые еще не готовы к релизу.
Хранение секретов и безопасность
Также одна из фишек, которую мы изобрели – это хранение секретов в системе HashiCorp Vault.
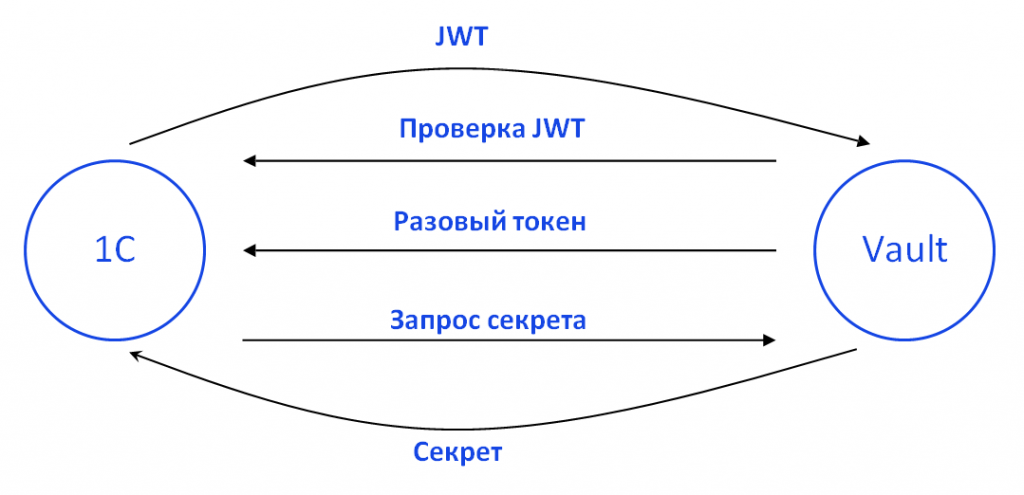
У нас есть HashiCorp Vault – защищенное хранилище секретов. 1С каждые полчаса генерирует авторизационный JSON веб-токен для входа в Vault. 1С идет с этим токеном в Vault. Vault идет в 1С, проверяет опубликованный ключ и определяет, совпадает токен или нет. Если совпадает, Vault отдает 1С разовый сессионный токен. 1С идет с этим токеном в Vault за секретом, и Vault возвращает этот секрет.
Таким образом, в наших бэкапах секретов не существует. А токены, которые там могут остаться, протухают, потому что обновляются раз в полчаса. Наш IT-ландшафт благодаря этому защищен. Если наши бэкапы куда-то утекут, проблем не возникнет.
Плюсы и минусы нетиповых конфигураций
Наконец мы подошли к главному вопросу нашей статьи – плюсам и минусам разработки нетиповых конфигураций. Как правило, когда 1С-ник слышит слова «нетиповые» или «самописные», он думает, что это небольшие базы, которые мало за что отвечают. Но это не так. Нетиповые – это не хуже и не лучше, просто другой подход к разработке. Наш кейс – живой пример того, что серьезную систему можно разрабатывать таким способом.
Этот способ подходит не каждому. Мы, например, не советуем писать 1С:Бухгалтерию с нуля – это бессмысленно. Но если в компании есть уникальный процесс, как наше управление закупками или управление логистическими данными, который часто меняется и требует высокой скорости доработки, то, скорее всего, наш подход будет полезен.
Теперь предлагаю пройтись по плюсам и минусам, которые нам удалось найти.
Плюсы
Первый плюс – нет внезапных обновлений от вендора. Такие обновления сложно планировать, так как законодательство меняется часто, а трудозатраты на их внедрение заранее оценить трудно. Кроме того, следом обычно требуется обновлять платформу под требования вендорской конфигурации. Мы обновляем свою платформу и следим за актуальностью, но делаем это в более спокойном темпе: между накатом на тестовую и продуктивную среду проходит около месяца.
В наших системах меньше сложность кода, потому что мы автоматизируем не весь пласт процессов, а конкретный бизнес-процесс. Соответственно, кодовая база меньше, меньше ошибок и легаси.
Быстрая скорость разработки – один из ключевых плюсов для заказчика и для команды. Мы вносим точечные изменения: например, в форму (а не реализуем их через расширения). В коде нет следов вида «сделал Вася», «добавил Петя» и сохраняется свобода разработки. В большинстве случаев мы не отвечаем заказчику фразой «мы это не можем сделать». Ограничения существуют – это здравый смысл и особенности платформы, – но они не мешают гибко развивать систему. При этом расширения мы используем для автотестов и инструментов разработчика.
Благодаря небольшой кодовой базе мы знаем почти весь код и всегда находимся в контексте происходящих изменений. Существенным недостатком в коде обычно считают то, что он написан не текущей командой. В нашем случае код написан нами, и мы помним его структуру. Рядом всегда есть коллега, который подскажет детали, мы делимся знаниями, чтобы обеспечить преемственность.
Часть общей функциональности вынесена в отдельную библиотеку подсистем. Мы упоминали ее выше. Эта библиотека – наше собственное решение, мы разрабатываем ее так же, как и нетиповую конфигурацию.
Мы не покупали коробку, что обеспечивает ощутимую экономию.
Разработка остается прозрачной для заказчика. Мы не адаптируем бизнес-процессы под купленную коробку, а пишем код под конкретные процессы. Это большой плюс для заказчика.
Также отсутствует оверинжиниринг: в типовых конфигурациях часто содержится большой объем функциональности, который не используется. У нас такого нет, мы создаем только то, что действительно нужно. Мы регулярно убираем старый код, у нас нет устаревших процессов, поэтому отсутствуют проблемы с производительностью.
Как следствие, нам не требуются дополнительные манипуляции с базой: например, не нужна свертка базы.
В плане трудоустройства для нас подходит любой аналитик. В команде работают аналитики, которые приходят к нам из других стэков разработки. У нас нет требования, чтобы аналитик знал типовую конфигурацию. Важны знания SQL, умение проектировать, работать с аннотациями и писать технические задания. Мы быстро объясняем основы метаданных в 1С, и после этого специалист может полноценно включаться в работу.
Минусы
Первый минус совпадает с первым плюсом: отсутствие обновлений. Нет возможности полагаться на вендора, все приходится делать самостоятельно. Каждая строка кода, каждое исправление создается вручную. Это накладывает на команду дополнительную ответственность при создании любых систем.
Следующий минус – ограниченное число разработчиков нужной квалификации. В эксплуатации наших систем мы сталкивались с тем, что не все разработчики на рынке готовы писать функциональность с нуля. Некоторые согласны дорабатывать только существующее решение. Даже если это не произносится напрямую, заметно, что одним специалистам легко дается создание нового функционала, а у других оно вызывает затруднения. Это важно учитывать при выборе подхода к построению нетиповых систем.
Еще один минус – необходимость отучать разработчиков от типовых систем. Это происходит не само по себе: разработчиков приходится сознательно перестраивать. У типичного 1С-ника часто присутствует страх обновлений, и он стремится писать код так, чтобы не мешать будущему обновлению конфигурации. В нашем случае требуется регулярно напоминать, что обновлений не будет, что можно менять любую форму и любой код без ограничений.
Последний минус – долгое погружение в предметную область. Невозможность воспользоваться привычным для мира 1С подходом, когда на рынке можно найти специалиста, который знает типовые бизнес-процессы, и он быстро включится в работу. Мы, как и коллеги из других стэков разработки, долго погружаем каждого сотрудника в контекст и предметную область.
Масштабы систем
Часто кажется, что нетиповая конфигурация – это небольшая система, однако размеры наших решений говорят об обратном. Объем информационных баз составляет от 0,5 ТБ до более чем 1 ТБ. Это не минимальный объем, но и не экстремально большой – типичный размер для полноценных корпоративных систем.
В шести наших системах ежедневно одновременно работают более 500 пользователей. Их обслуживают 24 сервера, включая серверы СУБД и серверы приложений. В эту инфраструктуру входят продуктивный контур, тестовые среды, интеграционный контур и среда разработки.
Возраст наших информационных баз составляет от 3 до 15 лет. Самой молодой системе – три года, самая зрелая работает уже пятнадцать лет. Системы критичны для бизнеса, так как процесс закупки является долгосрочным, планируется заранее и напрямую влияет на прибыль компании. В цепочке закупки множество точек контроля: товар должен быть заказан вовремя, прибыть вовремя и иметь корректную стоимость. Любое нарушение приводит к финансовым потерям.
В системах реализовано большое количество интеграционных связей. Основной обмен идет через внутренние корпоративные Oracle шины данных. Мы передаем данные не только в другие системы компании, но и между собственными решениями, что обеспечивает удобство и согласованность процессов.

В заключение стоит отметить, что наш опыт построения нетиповых систем обширен, и о нем можно рассказать значительно больше, чем позволяет формат статьи. Мы не призываем создавать системы с нуля, однако в крупных компаниях с уникальными бизнес-процессами, где критична скорость доработки, подход с быстрым макетированием пилотных решений может оказаться эффективным. Такие «пилоты» переходят в продуктивную среду и затем успешно эксплуатируются.
Подход требует аккуратной организации, но при правильном применении дает предсказуемый результат. Мы уверены, что он может оказаться полезным и для других команд.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

