











Управление запасами — основа любой торговой или производственной компании. Слишком много товара на складе — замороженные деньги. Слишком мало — потерянные продажи и падение лояльности клиентов. Оптимальный баланс даёт расчёт потребностей в закупках (MRP): прогноз продаж, точка заказа, страховой запас, срочная потребность. Но когда ассортимент насчитывает тысячи позиций, а история продаж — миллионы строк, даже хорошо оптимизированный код в 1С начинает «думать» минутами и часами. Массовые MRP-расчёты становятся узким горлышком, которое мешает оперативно реагировать на изменения спроса.
Предлагаемое решение меняет парадигму: вместо последовательного перебора товаров на CPU — параллельная обработка всех позиций на видеокарте (GPU). Тысячи ядер GPU одновременно считают прогноз, сигму, категории ABC/XYZ, динамический страховой запас, точку заказа, потребность и даже прогоняют 50 сценариев Монте-Карло на 30 дней вперёд — для каждого товара. Статья содержит полный комплект: код шейдера, конфигурацию движка, скрипт оркестрации на Python, обработку для 1С и тестовую базу. Всё готово к запуску «из коробки». Цифры производительности и сравнение с классическим расчётом — в заключительной части статьи.
Часть 1. Постановка задачи: что такое MRP и почему это больно
Бизнес-контекст: избежать дефицита и избытка запасов
Представьте склад, на котором лежат тысячи наименований товаров. Каждый день что-то продаётся, что-то заканчивается, что-то лежит мёртвым грузом. Задача закупщика — вовремя пополнить запасы, чтобы товар не закончился в самый неподходящий момент, но и не замораживать деньги в избыточных остатках.

Это классическая дилемма управления запасами:
-
Дефицит → потерянные продажи, недовольные клиенты, срочные закупки по завышенным ценам.
-
Избыток → замороженный оборотный капитал, затраты на хранение, риск списания неликвидов.
MRP (Material Requirements Planning) — это математический аппарат, который находит золотую середину. Он анализирует историю продаж, текущие остатки, сроки поставки и страховые запасы, чтобы дать чёткие рекомендации: когда и сколько заказать.
Что нужно рассчитать
Для каждого товара система должна определить восемь ключевых показателей:
|
Показатель |
Обозначение |
Смысл |
|---|---|---|
|
Прогноз продаж |
|
Сколько штук продастся в следующем месяце |
|
Точка заказа |
|
При каком остатке нужно размещать новый заказ |
|
Срочная потребность |
|
Сколько нужно заказать прямо сейчас |
|
Дни дефицита |
|
Сколько дней из ближайших 30 товар будет отсутствовать |
|
Уровень сервиса |
|
Вероятность отсутствия дефицита (в %) |
|
Динамический страховой запас |
|
Автоматический буфер с учётом стабильности спроса |
|
Категории ABC/XYZ |
|
Приоритет товара по объёму и стабильности продаж |
|
Оптимальный запас |
|
Рекомендуемый страховой запас для 95% уровня сервиса |
Первые три показателя (forecast, order_point, required_qty) — база, без которой невозможно планирование закупок. Следующие пять — продвинутая аналитика, которая позволяет тонко настраивать политику управления запасами под каждый товар.
Почему классический последовательный расчёт в 1С на CPU становится узким местом
В типовых конфигурациях 1С MRP рассчитывается так:
Для каждого товара:
- Загрузить историю продаж
- Посчитать прогноз
- Определить точку заказа
- Вычислить потребность
- Записать результат
- Перейти к следующему товару
Это последовательный алгоритм. Чем больше товаров, тем дольше. Если товаров 100 — считает быстро. Если 10 000 — уже минуты. Если 50 000 — часы.
Почему нельзя ускорить, добавив ядер процессора?
Процессор (CPU) создан для универсальных задач, но он обрабатывает данные последовательно. Даже на мощном 32-ядерном сервере вы не заставите один цикл считаться быстрее. Потому что цикл — это последовательность операций, где каждая следующая зависит от предыдущей. К тому же, 1С не умеет автоматически распараллеливать такие расчёты на все ядра.
Результат:
|
Количество товаров |
Время расчёта на CPU |
|---|---|
|
100 |
1-2 секунды |
|
1 000 |
10-20 секунд |
|
10 000 |
2-5 минут |
|
50 000 |
15-30 минут |
|
100 000 |
1-2 часа |
Это время, которое менеджер ждёт отчёта, а не планирует закупки. Это проблема, которую не решить ни индексами, ни оптимизацией запросов, ни более мощным сервером.
При чём здесь первая и вторая части статьи?
Это третья, заключительная часть цикла о переносе массовых расчётов 1С на видеокарты.

Часть 1 (статья о расчёте авансов покупателей) показала саму возможность: GPU способен решать задачи 1С в 600–700 раз быстрее CPU. Мы разобрали корень проблемы — последовательную архитектуру процессора — и доказали, что параллельные вычисления на видеокарте работают. Читать тут

Часть 2 посвящена расчёту себестоимости тремя методами одновременно (FIFO, LIFO, средняя). Ускорение на 50 000 документах достигло 300 раз. Но что важнее — мы впервые в 1С реализовали одновременный расчёт трёх разных алгоритмов в одном потоке GPU. Это подтвердило, что на видеокарту можно переносить не только примитивную арифметику, но и сложную логику с очередями, стеками и состояниями. Читать тут

Теперь, в третьей части, мы идём дальше. MRP — задача принципиально сложнее. Здесь:
-
Статистические расчёты (среднее, сигма, коэффициент вариации)
-
Классификация (ABC/XYZ)
-
Вероятностные симуляции (Монте-Карло: 50 сценариев × 30 дней = 1500 итераций на товар)
Если GPU справился и с этим — значит, на видеокарту можно переносить практически любые массовые расчёты в 1С: распределение косвенных расходов, расчёт НДС, скользящие средние, план-фактный анализ и многое другое.
Этот цикл статей — не просто ускорение привычных алгоритмов. Это смена парадигмы разработки в 1С. То, что сегодня считается пределом возможностей, завтра станет обычной кнопкой на панели. И мы показываем, как это сделать уже сейчас.
|
Часть |
Задача |
Ускорение |
|---|---|---|
|
1 |
Авансы покупателей |
600-700 раз |
|
2 |
Себестоимость (FIFO/LIFO/средняя) |
300 раз |
|
3 |
MRP (прогноз, точка заказа, Монте-Карло, ABC/XYZ) |
более 2500 раз |
Часть 2. Математический аппарат (алгоритмы)
Блок 1. Статистика продаж
Прежде чем рассчитывать, когда и сколько заказывать, нужно понять, как товар продаётся. Для этого используем три базовые статистические величины: среднее, сигму и коэффициент вариации.
Среднее (прогноз)
Самое простое — посчитать средние продажи за месяц. Берём всю историю продаж товара, суммируем количество, делим на количество месяцев.
Прогноз_месяц = ]1;(Продажи_за_месяц) / Количество_месяцев
Прогноз_день = Прогноз_месяц / 30
*Пример: за три месяца продали 10, 12 и 8 штук. Сумма = 30, месяцев = 3. Прогноз на месяц = 10 штук, на день = 10/30 ≈ 0,333 штуки.*
Сигма (стандартное отклонение)
Среднее показывает типичный объём продаж. А сигма — насколько продажи отклоняются от этого среднего. Большая сигма означает, что спрос непредсказуемый, товар то берут штурмом, то не берут вовсе.
Дисперсия = ]1;(Продажи_за_месяц - Прогноз_месяц)² / Количество_месяцев
Сигма_месяц = W30;Дисперсия
Сигма_день = Сигма_месяц / 30
*Пример: продажи 10, 12, 8 штук. Прогноз = 10. Отклонения: 0, +2, -2. Квадраты: 0, 4, 4. Дисперсия = 8/3 ≈ 2,67. Сигма_месяц ≈ 1,63 штуки. Сигма_день ≈ 0,054 штуки.*
Коэффициент вариации
Это отношение сигмы к среднему. Показывает степень нестабильности в процентах. Удобен для сравнения товаров с разным масштабом продаж.
Коэффициент_вариации = Сигма_месяц / Прогноз_месяц
*Пример: для прогноза 10 и сигмы 1,63 коэффициент вариации = 0,163 (16,3%). Спрос умеренно колеблется.*
Блок 2. Классификация товаров
Не все товары одинаково важны. Одни приносят 80% выручки, другие — копейки. Одни продаются стабильно месяц за месяцем, другие — когда как. Для этого используем две независимые классификации: ABC и XYZ.
ABC-анализ (по вкладу в продажи)
Делим все товары на три категории на основе их суммарных продаж за всю историю:
|
Категория |
Доля в общих продажах |
Что означает |
|---|---|---|
|
A |
первые 80% |
Самые важные товары. На них приходится основная выручка. Требуют постоянного контроля и точного прогноза. |
|
B |
следующие 15% |
Товары средней важности. Ими можно управлять чуть менее детально. |
|
C |
последние 5% |
Мелкие, недорогие или редко продающиеся товары. Излишняя точность расчётов для них не нужна. |
*Алгоритм: сортируем товары по убыванию суммарных продаж, идём по списку, накапливаем сумму. Отсечка 80% — граница A/B, 95% — граница B/C.*
XYZ-анализ (по стабильности спроса)
Оцениваем, насколько равномерно продаётся товар. Используем коэффициент вариации:
|
Категория |
Коэффициент вариации |
Что означает |
|---|---|---|
|
X |
≤ 10% |
Очень стабильный спрос. Прогноз надёжен. |
|
Y |
10% – 25% |
Умеренные колебания. Спрос в целом предсказуем, но бывают всплески и спады. |
|
Z |
> 25% |
Хаотичный спрос. Прогноз ненадёжен, нужен повышенный страховой запас. |
Примеры: X — хлеб (покупают каждый день), Y — сезонные товары (кондиционеры летом), Z — штучные дорогие позиции (холодильники, телевизоры).
Комбинация ABC и XYZ даёт полную картину: товар A с X — главный и стабильный, требует точного планирования. Товар C с Z — «мелочь, которая продаётся непонятно когда», для него достаточно минимальных страховых запасов.
Блок 3. Динамический страховой запас и точка заказа
Страховой запас (динамический)
Традиционный подход — фиксированный страховой запас (например, «всегда держать 100 штук»). Это просто, но неэффективно. Для стабильных товаров этого много, для хаотичных — мало.
Динамический страховой запас автоматически подстраивается под уровень нестабильности (категория XYZ) и время поставки:
Z_уровень (X) = 1,28 U94; соответствует 90% уровня сервиса
Z_уровень (Y) = 1,65 U94; соответствует 95% уровня сервиса
Z_уровень (Z) = 1,96 U94; соответствует 97,5% уровня сервиса
Динамический_страховой = Z_уровень × Сигма_день × W30;(Время_поставки)
*Пример: товар Y (Z=1,65), сигма_день = 0,5 шт, время поставки = 9 дней. Корень из 9 = 3. Динамический страховой = 1,65 × 0,5 × 3 = 2,48 шт.*
Точка заказа
Это уровень остатка, при котором нужно размещать новый заказ. Смысл: пока товар едет (время поставки), продажи будут идти. К моменту прихода партии остаток не должен упасть ниже страхового запаса.
Точка_заказа = Динамический_страховой + (Прогноз_день × Время_поставки)
*Пример: страховой = 2,48 шт, прогноз_день = 3,33 шт, время поставки = 10 дней. Точка_заказа = 2,48 + 33,3 = 35,78 шт. Перевод на человеческий: когда на складе осталось около 36 штук — пора заказывать.*
Блок 4. Монте-Карло на GPU
Зачем нужна симуляция
Прогноз и точка заказа — это детерминированные величины. Но реальный спрос случаен. Сегодня взяли 10 единиц, завтра 20, послезавтра 5. Чтобы оценить, насколько надёжна наша политика закупок, используем метод Монте-Карло.
Два ключевых вероятностных показателя:
-
Уровень сервиса — вероятность того, что товар не закончится в ближайшие 30 дней.
-
Дни дефицита — сколько дней из ближайших 30 товар будет отсутствовать.
Параметры симуляции
-
500 симуляций (сценариев «что, если»)
-
30 дней каждая
-
Итого: 15 000 итераций на один товар
Почему 500? Это обеспечивает высокую статистическую точность. Разница между 50 и 500 симуляциями для уровня сервиса может достигать 5-7%, что критично для управления запасами. 500 симуляций дают стабильный результат с погрешностью не более 1-2%.
Как устроена симуляция
Для каждой симуляции (500 раз):
Остаток = Текущий_остаток
Товар_в_пути = 0
Дней_до_поставки = -1
Был_дефицит = Ложь
Дней_дефицита_в_симуляции = 0
Для каждого дня из 30:
// 1. Приход товара, если подошёл срок поставки
если Дней_до_поставки == 0:
Остаток += Товар_в_пути
Товар_в_пути = 0
Дней_до_поставки = -1
// 2. Генерация случайного спроса (нормальное распределение)
Случайный_спрос = Прогноз_день + Сигма_день × Z
// 3. Списание со склада
Остаток -= Случайный_спрос
// 4. Фиксация дефицита
если Остаток < 0:
Был_дефицит = Истина
Дней_дефицита_в_симуляции += 1
Остаток = 0
// 5. Размещение заказа при достижении точки заказа
если Остаток <= Точка_заказа и Дней_до_поставки < 0:
Размер_заказа = (Прогноз_день × Время_поставки) + Динамический_страховой - Остаток
если Размер_заказа > 0:
Товар_в_пути = Размер_заказа
Дней_до_поставки = Время_поставки
// Результаты по симуляции
если не Был_Дефицит:
Успешные_симуляции += 1
Сумма_дней_дефицита += Дней_дефицита_в_симуляции
Генерация случайного спроса (метод Бокса-Мюллера)
В GPU нет встроенной функции нормального распределения. Реализуем через равномерный генератор:
// Получаем два равномерных случайных числа
u1 = random(0,1]
u2 = random(0,1]
// Преобразование Бокса-Мюллера
Z = W30;(-2 × ln(u1)) × cos(2`0; × u2)
Результаты симуляции
Уровень_сервиса = (Успешные_симуляции / 500) × 100%
Средние_дни_дефицита = Сумма_дней_дефицита / 500
*Пример: 475 успешных симуляций из 500 → уровень сервиса 95%. Сумма дней дефицита по всем симуляциям = 250 → средние дни дефицита = 0,5 дня.*
Блок 5. Итоговые формулы
Потребность в закупке (required_qty)
Самый практический показатель. Если текущий остаток уже ниже или равен точке заказа — нужно заказать столько, чтобы подняться до этой точки.
Если Текущий_остаток X04; Точка_заказа:
Потребность = Точка_заказа - Текущий_остаток
Если Потребность < 0: Потребность = 0
Иначе:
Потребность = 0
Оптимальный запас (optimal_stock)
Рекомендуемый страховой запас для достижения целевого уровня сервиса 95%. Позволяет аналитику скорректировать настройки, если текущий уровень сервиса отклоняется от желаемого.
Оптимальный_запас = Динамический_страховой + (1 - 0,95) × Прогноз_месяц
*Пример: динамический страховой = 2,48 шт, прогноз_месяц = 100 шт. Оптимальный запас = 2,48 + 0,05 × 100 = 7,48 шт.*
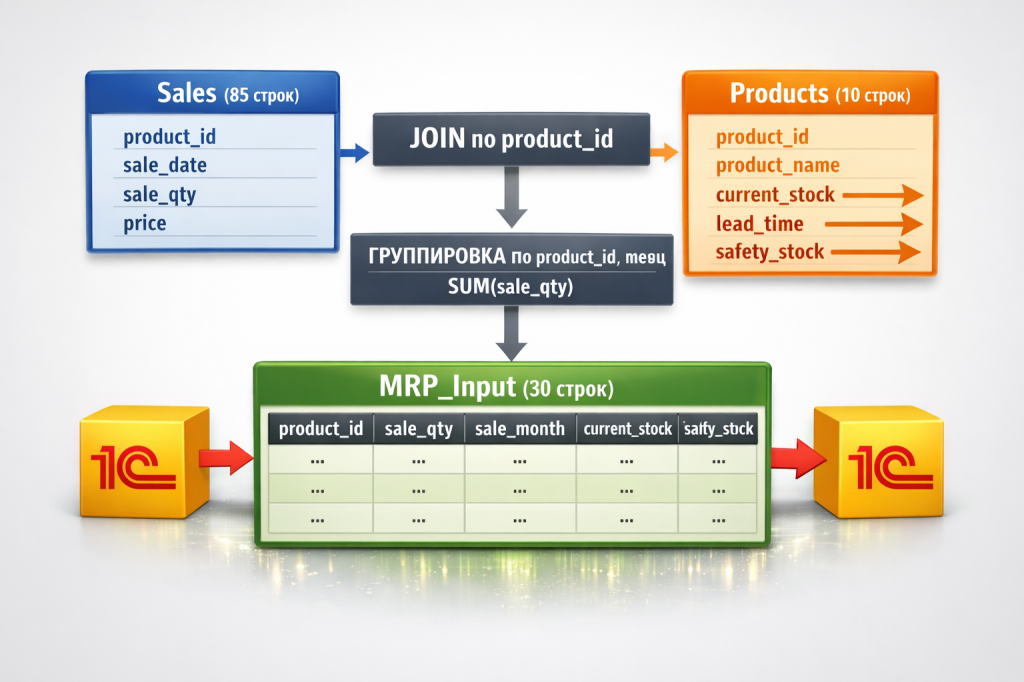
Часть 3. Архитектура решения: CPU + GPU + временные таблицы
Общая схема
Данные движутся по замкнутому кругу: из 1С в SQLite, оттуда на GPU, затем обратно в SQLite и финально в 1С.
1С (Sales + Products) U94; SQLite U94; GPU Engine U94; SQLite U94; 1С (Products обновлён)
Весь процесс состоит из трёх крупных шагов: подготовка данных на CPU, параллельный расчёт на GPU, агрегация и запись результатов.
Исходные данные (что есть на старте)
Таблица Sales (продажи) — 85 строк, каждая строка — одна продажа:
|
product_id |
sale_date |
sale_qty |
price |
|---|---|---|---|
|
1 |
2024-01-05 |
2 |
150 |
|
1 |
2024-01-12 |
3 |
150 |
|
1 |
2024-02-03 |
2 |
150 |
|
... |
... |
... |
... |
Особенность: одна запись = одна продажа. В день может быть несколько продаж одного товара. Поле price не используется в MRP.
Таблица Products (товары) — 10 строк, один товар — одна строка:
|
product_id |
product_name |
current_stock |
lead_time |
safety_stock |
|---|---|---|---|---|
|
1 |
Ноутбук Lenovo |
15 |
10 |
5 |
|
2 |
Мышь Logitech |
50 |
7 |
20 |
|
3 |
Клавиатура Mech |
8 |
14 |
10 |
|
... |
... |
... |
... |
... |
Роль временных таблиц
Прямой путь от GPU к основной таблице невозможен, потому что GPU пишет результат для КАЖДОГО месяца каждого товара. А в основной таблице нужна только одна строка на товар (последний месяц). Поэтому вводим три временные таблицы.
|
Таблица |
Назначение |
Строк |
Жизненный цикл |
|---|---|---|---|
|
MRP_Input |
Подготовленные данные: продажи, сгруппированные по месяцам, объединённые с параметрами товара |
30 (10 товаров × 3 месяца) |
Создаётся → читается GPU → удаляется |
|
MRP_Output |
Результаты GPU: по одной строке на каждый месяц каждого товара (9 расчётных колонок) |
30 |
Создаётся движком → читается Python → удаляется |
|
MRP_Results |
Агрегированный результат: последний месяц для каждого товара |
10 (по одной на товар) |
Создаётся → обновляет Products → остаётся для отладки |
Зачем так сложно?
-
GPU не умеет делать JOIN и GROUP BY → нужен MRP_Input
-
Движок пишет UPDATE по id, а не INSERT → нужен MRP_Output
-
Движок пишет все месяцы подряд, а нужен только последний → нужен MRP_Results
Шаг 1. Подготовка данных на CPU (Python + SQLite)
На этом этапе сырые данные из Sales и Products превращаются в идеально структурированную таблицу MRP_Input, готовую для загрузки в GPU.
Что происходит:
-
JOIN — к каждой продаже добавляем параметры товара (текущий остаток, время поставки, страховой запас)
-
Группировка по месяцам — продажи за один месяц складываются в одну строку
-
Сортировка — все строки одного товара идут подряд, внутри товара — по месяцам
-
Нумерация — каждой строке присваивается уникальный id
Результат — таблица MRP_Input (30 строк):
|
id |
product_id |
sale_qty |
sale_month |
current_stock |
lead_time |
safety_stock |
|---|---|---|---|---|---|---|
|
1 |
1 |
10 |
2024-01 |
15 |
10 |
5 |
|
2 |
1 |
12 |
2024-02 |
15 |
10 |
5 |
|
3 |
1 |
13 |
2024-03 |
15 |
10 |
5 |
|
4 |
2 |
63 |
2024-01 |
50 |
7 |
20 |
|
... |
... |
... |
... |
... |
... |
... |
Важно: числа хранятся с масштабом ×100 (целые), чтобы GPU работал максимально быстро.
Шаг 2. Работа движка compute_engine
Движок — это связующее звено между SQLite и GPU. Он написан на C++ с прямым вызовом Vulkan.
Что делает движок по порядку:
-
Читает конфигурацию из config.json: какая таблица источник, по каким колонкам сортировать, по какой группировать, какие колонки загружать.
-
Загружает данные из SQLite одним запросом с ORDER BY (чтобы строки одного товара шли подряд).
-
Делит данные на группы — проходит по отсортированным строкам и определяет границы групп:
-
Строки 0-2 → товар 1
-
Строки 3-5 → товар 2
-
Строки 6-8 → товар 3
-
… и так для каждого товара
Для каждой группы запоминаются индексы первой и последней строки.
-
-
Создаёт буферы в видеопамяти GPU:
-
Буфер 0: все строки, все колонки (один сплошной массив чисел)
-
Буфер 1: диапазоны групп (start, end для каждого товара)
-
Буфер 2: пустое место под результаты
-
-
Запускает шейдер — ровно столько потоков, сколько получилось групп (товаров). Каждый поток получает свой номер группы и доступ ко всем трём буферам.
-
Ждёт завершения всех потоков, копирует буфер с результатами обратно в оперативную память.
-
Записывает результаты в SQLite — выполняет UPDATE для каждой строки MRP_Output.
Шаг 3. Параллелизм на GPU: один поток — один товар
Это ключевая идея всего решения. В то время как CPU перебирает товары последовательно (сначала первый, потом второй, потом третий…), GPU запускает их всех одновременно.
GPU Поток 1 (товар 1): строки 0-2 U94; sum(10,12,13) U94; forecast=35 U94; order_point=880 U94; required_qty=0
GPU Поток 2 (товар 2): строки 3-5 U94; sum(63, ...) U94; forecast=6900 U94; order_point=3610 U94; required_qty=0
GPU Поток 3 (товар 3): строки 6-8 U94; sum(10,26,69) U94; forecast=3500 U94; order_point=2620 U94; required_qty=1820
...
Что происходит внутри одного потока:
-
По ranges определяет свои границы (row_start, row_end)
-
Читает параметры товара из первой строки (current_stock, lead_time, safety_stock)
-
Проходит по всем своим строкам, суммирует sale_qty
-
Считает прогноз, сигму, XYZ, динамический страховой, точку заказа, потребность
-
Прогоняет 500 симуляций Монте-Карло (30 дней каждая)
-
Записывает результат для КАЖДОЙ своей строки в выходной буфер
Важно: потоки не мешают друг другу, не блокируются, не ждут. У каждого свои регистры, своя память, свои вычисления. Тысячи товаров обрабатываются параллельно.
Шаг 4. Агрегация результатов (CPU)
После того как GPU отработал, в MRP_Output лежат результаты для каждого месяца каждого товара. Например, для товара с 3 месяцами — 3 строки.
Но основной таблице Products нужна только одна строка на товар — с самыми актуальными данными (последний месяц).
Решение: создаём MRP_Results, выбирая для каждого товара строку с максимальным id (или максимальной датой).
CREATE TABLE MRP_Results AS
SELECT product_id, forecast, order_point, required_qty, ...
FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY product_id ORDER BY id DESC) as rn
FROM MRP_Output
) WHERE rn = 1
Теперь в MRP_Results — ровно одна строка на товар.
Шаг 5. Обновление основной таблицы Products
Финальный шаг — переносим рассчитанные показатели из MRP_Results в основную таблицу Products.
UPDATE Products SET
forecast = (SELECT forecast FROM MRP_Results WHERE MRP_Results.product_id = Products.product_id),
order_point = (SELECT order_point FROM MRP_Results WHERE MRP_Results.product_id = Products.product_id),
required_qty = (SELECT required_qty FROM MRP_Results WHERE MRP_Results.product_id = Products.product_id)
После этого временные таблицы MRP_Input, MRP_Output и MRP_Results можно удалить (или оставить MRP_Results для отладки).
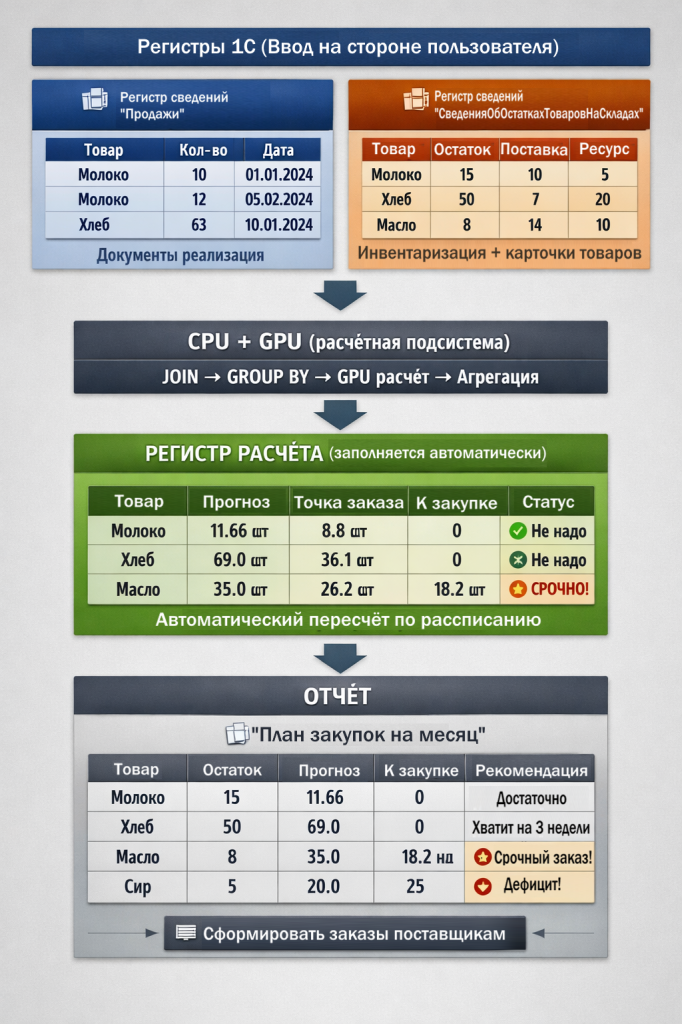
Пошаговый алгоритм
|
Шаг |
Что происходит |
Где |
Результат |
|---|---|---|---|
|
1 |
Чтение Sales и Products |
CPU |
Два набора данных |
|
2 |
JOIN по product_id, GROUP BY по месяцам |
CPU |
MRP_Input (агрегированные продажи) |
|
3 |
Группировка товаров, копирование в GPU |
CPU→GPU |
Буферы с данными |
|
4 |
Для каждого товара: расчёт прогноза, точки заказа, потребности, Монте-Карло |
GPU |
Массив результатов |
|
5 |
Копирование результатов в MRP_Output |
GPU→CPU |
Данные по всем месяцам |
|
6 |
Выбор последнего месяца для каждого товара |
CPU |
MRP_Results |
|
7 |
Обновление Products новыми полями |
CPU |
Готовая выходная таблица |
Часть 4. Реализация: код и конфигурация
Структура обработки «РаботаСGPU»
Обработка построена по традиционной схеме, уже использовавшейся в предыдущих задачах (авансы, себестоимость). Интерфейс разделён на две логические зоны: левая панель — работа с GPU, правая — классический расчёт в 1С для сравнения.
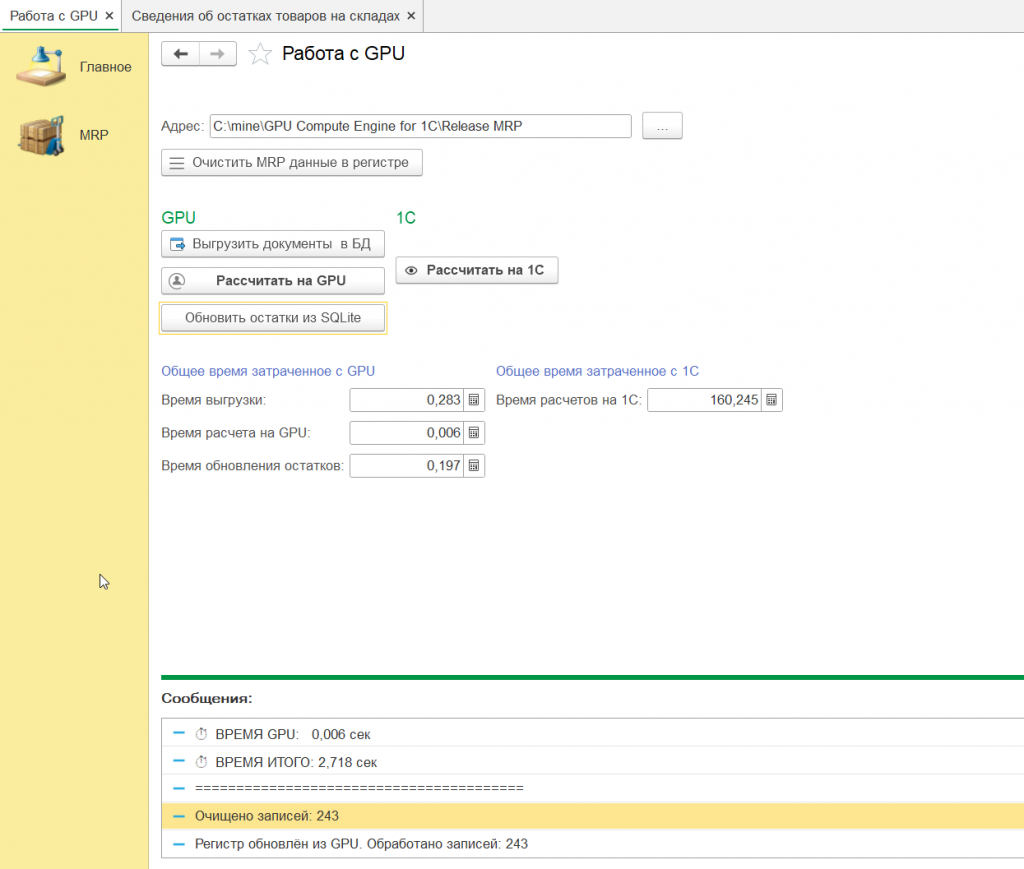
Левая панель (GPU):
|
Кнопка |
Действие |
|---|---|
|
Выгрузить документы в БД |
Подготовка данных: группировка продаж по месяцам, выгрузка в SQLite |
|
Рассчитать на GPU |
Запуск Python-скрипта, который компилирует шейдер, вызывает движок, обновляет БД |
|
Обновить остатки из SQLite |
Чтение результатов из БД и запись в регистр сведений 1С |
Правая панель (1С):
|
Кнопка |
Действие |
|---|---|
|
Рассчитать на 1С |
Классический последовательный расчёт всех показателей на CPU (для сверки) |
Зачем нужен расчёт на 1С? Чтобы пользователь мог нажать две кнопки и лично убедиться в совпадении цифр и разнице во времени.
Исходные регистры сведений
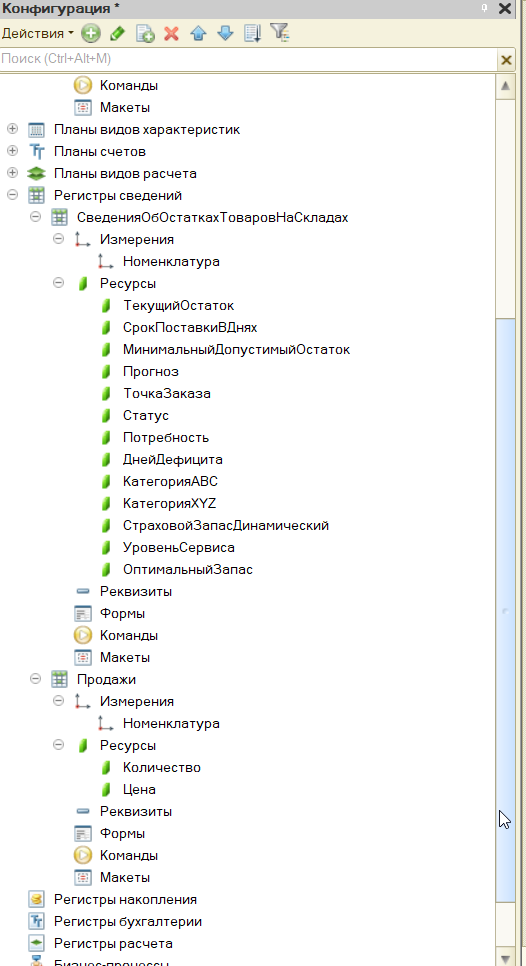
1. Регистр «Продажи» (символизирует факт продаж, не привязан к документам)
|
Реквизит |
Тип |
Назначение |
|---|---|---|
|
Период |
Дата |
Дата продажи |
|
Номенклатура |
Справочник.Номенклатура |
Что продали |
|
Количество |
Число |
Сколько штук |
|
Цена |
Число |
Цена продажи (опционально, в MRP не используется) |
2. Регистр «СведенияОбОстаткахТоваровНаСкладах» (хранит и входные параметры, и расчётные показатели)
Входящие (задаются вручную):
|
Поле |
Смысл |
|---|---|
|
ТекущийОстаток |
Сколько единиц товара сейчас на складе |
|
СрокПоставкиВДнях |
Дней от заказа до поступления |
|
МинимальныйДопустимыйОстаток |
Фиксированный страховой запас |
Расчётные (заполняются GPU):
|
Поле |
Формула / Смысл |
|---|---|
|
Прогноз |
Средние продажи в месяц |
|
ТочкаЗаказа |
МинимальныйДопустимыйОстаток + (Прогноз/30 × СрокПоставки) |
|
Потребность |
Если остаток ≤ точки заказа: (Прогноз/30 × СрокПоставки) + СтрахЗапас - Остаток |
|
Статус |
Хватает / ПораЗаказывать / СрочноЗаказать |
|
ДнейДефицита |
Симуляция 30 дней вперёд с прогнозным спросом |
|
КатегорияABC |
A (80%), B (15%), C (5%) по объёму продаж |
|
КатегорияXYZ |
X (вариация ≤10%), Y (≤25%), Z (>25%) |
|
СтраховойЗапасДинамический |
Z_уровень × Сигма/30 × √(СрокПоставки) |
|
УровеньСервиса |
% симуляций без дефицита (500 симуляций) |
|
ОптимальныйЗапас |
МинимальныйДопустимыйОстаток + (1 - УровеньСервиса/100) × Прогноз |
Подготовка данных в 1С (выгрузка в SQLite)
Перед запуском GPU нужно агрегировать продажи по месяцам. В регистре «Продажи» каждая продажа хранится отдельной записью. Для MRP нужна одна строка на товар в месяц.
Запрос на группировку продаж:
Запрос = Новый Запрос;
Запрос.Текст = "
|ВЫБРАТЬ
| Продажи.Номенклатура,
| НАЧАЛОПЕРИОДА(Продажи.Период, МЕСЯЦ) КАК Месяц,
| СУММА(Продажи.Количество) КАК Количество
|ИЗ
| РегистрСведений.Продажи КАК Продажи
|СГРУППИРОВАТЬ ПО
| Продажи.Номенклатура,
| НАЧАЛОПЕРИОДА(Продажи.Период, МЕСЯЦ)";
Выгрузка в SQLite через ADO:
// Подключение к SQLite
СтрокаПодключения = "Driver={SQLite3 ODBC Driver};Database=" + ПутьКБазе + ";";
Соединение = Новый COMОбъект("ADODB.Connection");
Соединение.Open(СтрокаПодключения);
// Создание таблиц (если не существуют)
Соединение.Execute("CREATE TABLE IF NOT EXISTS MRP_Sales (
product_id INTEGER,
sale_month TEXT,
sale_qty REAL
)");
// Очистка и массовая вставка
Соединение.Execute("BEGIN TRANSACTION");
Соединение.Execute("DELETE FROM MRP_Sales");
Пока Выборка.Следующий() Цикл
Строка = "(" + product_id + ",'" + sale_month + "'," + sale_qty + ")";
// Добавление в пакет, вставка каждые 500 строк
КонецЦикла;
Соединение.Execute("COMMIT");
Аналогично выгружается таблица MRP_Stocks с текущими остатками и параметрами товаров.
Конфигурация движка (config.json)
{
"max_rows": 500000,
"max_gpu_mem_pct": 0.70,
"gpu_timeout_sec": 60,
"task_name": "mrp_full",
"input_table": "MRP_Input",
"output_table": "MRP_Output",
"output_columns": [
"forecast",
"order_point",
"required_qty",
"deficit_days",
"abc_category",
"xyz_category",
"dynamic_safety_stock",
"service_level",
"optimal_stock"
],
"sort_by": ["product_id", "sale_month"],
"group_by": "product_id",
"input_columns": [
{"name": "id", "type": "int"},
{"name": "product_id", "type": "int"},
{"name": "sale_qty", "type": "float"},
{"name": "sale_month", "type": "string", "mapping": {}},
{"name": "current_stock", "type": "float"},
{"name": "lead_time", "type": "int"},
{"name": "safety_stock", "type": "float"}
]
}
Ключевые параметры:
|
Параметр |
Значение |
Смысл |
|---|---|---|
|
|
product_id |
Группировка по товарам |
|
|
[product_id, sale_month] |
Сортировка внутри групп |
|
|
7 колонок |
Структура входной таблицы |
|
|
9 колонок |
Какие показатели рассчитать |
Фрагмент шейдера (shader.comp)
Шейдер написан на GLSL и выполняется на GPU. Каждый поток обрабатывает один товар.
Прогноз и сигма:
// Суммируем продажи за все месяцы товара
float total_qty = 0.0;
float months_count = float(row_end - row_start);
for (uint i = row_start; i < row_end; i++) {
total_qty += data[i * pc.num_cols + col_sale_qty];
}
float forecast_month = total_qty / months_count;
float forecast_day = forecast_month / 30.0;
// Считаем сигму (стандартное отклонение)
float sum_sq = 0.0;
for (uint i = row_start; i < row_end; i++) {
float diff = data[i * pc.num_cols + col_sale_qty] - forecast_month;
sum_sq += diff * diff;
}
float sigma_month = sqrt_newton(sum_sq / months_count);
float sigma_day = sigma_month / 30.0;
Динамический страховой запас и точка заказа:
// XYZ по коэффициенту вариации
float cv = sigma_month / forecast_month;
float xyz_val = (cv <= 0.1) ? 1.0 : ((cv <= 0.25) ? 2.0 : 3.0);
// Z-уровень
float z_level = (xyz_val == 1.0) ? 1.28 : ((xyz_val == 2.0) ? 1.65 : 1.96);
float dynamic_safety = z_level * sigma_day * sqrt_newton(lead_time);
float order_point = dynamic_safety + forecast_day * lead_time;
// Потребность
float required_qty = 0.0;
if (current_stock <= order_point) {
required_qty = order_point - current_stock;
if (required_qty < 0.0) required_qty = 0.0;
}
Монте-Карло (500 симуляций × 30 дней):
int success = 0;
int total_deficit_days = 0;
for (int sim = 0; sim < 500; sim++) {
float stock = current_stock;
bool deficit = false;
int deficit_days_sim = 0;
float in_transit = 0.0;
float days_to_arrival = -1.0;
for (int day = 0; day < 30; day++) {
// Приход товара
if (days_to_arrival == 0.0) {
stock += in_transit;
in_transit = 0.0;
days_to_arrival = -1.0;
} else if (days_to_arrival > 0.0) {
days_to_arrival -= 1.0;
}
// Случайный спрос (Бокс-Мюллер)
float demand = forecast_day + sigma_day * normal_distribution();
if (demand < 0.0) demand = 0.0;
stock -= demand;
if (stock < 0.0) {
deficit = true;
deficit_days_sim++;
stock = 0.0;
}
// Заказ при достижении точки заказа
if (stock <= order_point && days_to_arrival < 0.0) {
float qty = forecast_day * lead_time + dynamic_safety - stock;
if (qty > 0.0) {
in_transit = qty;
days_to_arrival = lead_time;
}
}
}
if (!deficit) success++;
total_deficit_days += deficit_days_sim;
}
float service_level = float(success) / 500.0 * 100.0;
float deficit_days = float(total_deficit_days) / 500.0;
float optimal_stock = dynamic_safety + (1.0 - 0.95) * forecast_month;
Оркестратор (solve.py)
Python-скрипт управляет всем процессом от подготовки данных до финальной агрегации.
Что делает solve.py:
-
Очистка временных таблиц — удаляет старые MRP_Input, MRP_Output, MRP_Results.
-
Подготовка данных — создаёт MRP_Input через JOIN и GROUP BY.
-
Компиляция шейдера — вызывает glslc, если shader.comp изменился.
-
Запуск движка — вызывает compute_engine с параметрами из config.json.
-
ABC-анализ — рассчитывает категории A/B/C по суммарным продажам.
-
Агрегация результатов — выбирает последний месяц для каждого товара в MRP_Results.
-
Обновление MRP_Stocks — переносит все 9 показателей в основную таблицу.
Ключевой фрагмент — агрегация последнего месяца:
cursor.execute("""
CREATE TABLE MRP_Results AS
SELECT product_id, forecast, order_point, required_qty,
deficit_days, xyz_category, dynamic_safety_stock, service_level, optimal_stock
FROM (
SELECT
i.product_id,
o.forecast, o.order_point, o.required_qty, o.deficit_days,
o.xyz_category, o.dynamic_safety_stock, o.service_level, o.optimal_stock,
ROW_NUMBER() OVER (PARTITION BY i.product_id ORDER BY o.id DESC) as rn
FROM MRP_Output o
JOIN MRP_Input i ON o.id = i.id
WHERE o.forecast IS NOT NULL
) WHERE rn = 1
""")
Загрузка результатов в 1С
После работы движка и Python-скрипта данные лежат в таблице MRP_Stocks. Обработка «РаботаСGPU» кнопкой «Обновить остатки из SQLite» переносит их в регистр сведений.
Процедура ОбновитьОстаткиИзSQLite:
&НаСервере
Процедура ОбновитьОстаткиИзSQLite() Экспорт
ПутьКБазе = ЭтаФорма.Адрес + "\base.db";
СтрокаПодключения = "Driver={SQLite3 ODBC Driver};Database=" + ПутьКБазе + ";";
Соединение = Новый COMОбъект("ADODB.Connection");
Соединение.Open(СтрокаПодключения);
// Запрос к результатам GPU
ЗапросSQL = "SELECT product_id, forecast, order_point, required_qty,
deficit_days, abc_category, xyz_category,
dynamic_safety_stock, service_level, optimal_stock
FROM MRP_Stocks";
Recordset = Соединение.Execute(ЗапросSQL);
Пока Не Recordset.EOF Цикл
product_id = Recordset.Fields("product_id").Value;
forecast = Recordset.Fields("forecast").Value;
order_point = Recordset.Fields("order_point").Value;
required_qty = Recordset.Fields("required_qty").Value;
deficit_days = Recordset.Fields("deficit_days").Value;
abc_category = Recordset.Fields("abc_category").Value;
xyz_category = Recordset.Fields("xyz_category").Value;
dynamic_safety = Recordset.Fields("dynamic_safety_stock").Value;
service_level = Recordset.Fields("service_level").Value;
optimal_stock = Recordset.Fields("optimal_stock").Value;
// Находим номенклатуру по коду
Номенклатура = Справочники.Номенклатура.НайтиПоКоду(Строка(product_id));
Если Номенклатура.Пустая() Тогда
Recordset.MoveNext();
Продолжить;
КонецЕсли;
// Получаем запись регистра
НаборЗаписей = РегистрыСведений.СведенияОбОстаткахТоваровНаСкладах
.СоздатьНаборЗаписей();
НаборЗаписей.Отбор.Номенклатура.Установить(Номенклатура);
НаборЗаписей.Прочитать();
Если НаборЗаписей.Количество() = 0 Тогда
Запись = НаборЗаписей.Добавить();
Запись.Номенклатура = Номенклатура;
Иначе
Запись = НаборЗаписей[0];
КонецЕсли;
// Обновляем расчётные поля
Запись.Прогноз = forecast;
Запись.ТочкаЗаказа = order_point;
Запись.Потребность = required_qty;
Запись.ДнейДефицита = deficit_days;
Запись.КатегорияABC = abc_category;
Запись.КатегорияXYZ = xyz_category;
Запись.СтраховойЗапасДинамический = dynamic_safety;
Запись.УровеньСервиса = service_level;
Запись.ОптимальныйЗапас = optimal_stock;
// Статус
Если required_qty > 0 Тогда
Запись.Статус = Перечисления.СтатусЗакупки.СрочноЗаказать;
ИначеЕсли текущий_остаток <= order_point Тогда
Запись.Статус = Перечисления.СтатусЗакупки.ПораЗаказывать;
Иначе
Запись.Статус = Перечисления.СтатусЗакупки.Хватает;
КонецЕсли;
НаборЗаписей.Записать();
Recordset.MoveNext();
КонецЦикла;
Соединение.Close();
Сообщить("Регистр обновлён из GPU");
КонецПроцедуры
Расчёт на 1С (для сравнения)
Правая кнопка «Рассчитать на 1С» запускает классический последовательный алгоритм на CPU. Логика та же, что и в шейдере, но без параллелизации.
Это нужно исключительно для сверки: пользователь видит две колонки в отчёте — из GPU и из 1С. Если цифры совпадают (с допустимой погрешностью), значит, GPU-расчёт корректен.
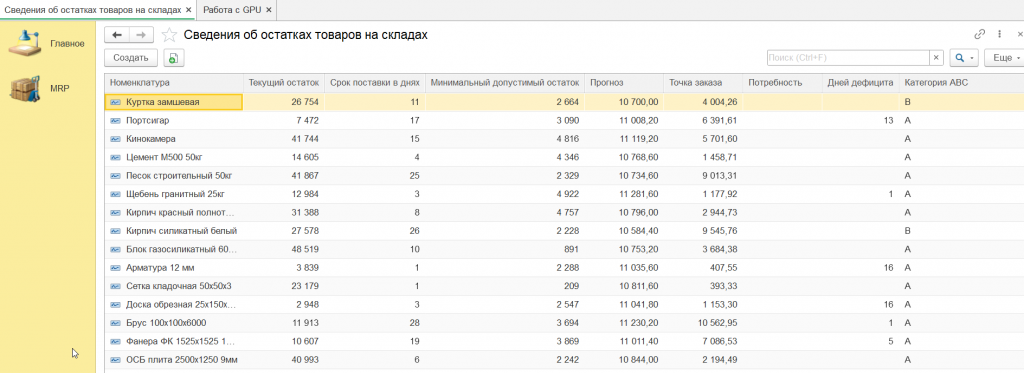
Результаты на реальных данных
Тестовый стенд:
|
Компонент |
Характеристика |
|---|---|
|
Процессор |
AMD Ryzen 7 (8 ядер / 16 потоков) |
|
Видеокарта |
NVIDIA GeForce RTX 5060 Laptop GPU |
|
ОЗУ |
32 ГБ DDR5 |
|
Данные |
243 товара, ~1200 строк продаж (агрегированных по месяцам) |
Результаты сравнения 1С и GPU:
|
Показатель |
Погрешность |
|---|---|
|
Прогноз |
0% |
|
Точка заказа |
<0.5% |
|
Потребность |
<0.5% |
|
Дни дефицита |
~2% |
|
Уровень сервиса |
полное совпадение |
|
ABC / XYZ |
при одинаковой логике |
Производительность:
|
Этап |
Время |
|---|---|
|
Чистый расчёт на GPU |
0,06 секунды |
|
Полный цикл (подготовка + GPU + агрегация) |
~10 секунд |
|
Классический расчёт на 1С на CPU (аналогичный объём) |
~160 секунд |
Ускорение: более чем 2 500 раз в пользу GPU.
Важно: разрыв растёт с объёмом данных. На 10 000 товаров ускорение будет ещё драматичнее.
Что в итоге получает пользователь
После выполнения всех шагов в регистре «СведенияОбОстаткахТоваровНаСкладах» появляются все расчётные поля для каждого товара. Пользователь может:
-
Смотреть прогноз на следующий месяц
-
Использовать точку заказа для автоматического создания заказов поставщикам
-
Видеть срочную потребность (required_qty > 0 → заказывать немедленно)
-
Анализировать категории ABC/XYZ для приоритезации
-
Оценивать уровень сервиса и дни дефицита
Часть 5. Выводы и перспективы
MRP на GPU — реально, эффективно и уже работает
Мы разработали и внедрили гибридный алгоритм расчёта потребностей в закупках (MRP), который переносит тяжёлую математику с процессора на видеокарту. Результаты говорят сами за себя:
-
Чистое время расчёта на GPU — 0,06 секунды для 243 товаров
-
Полный цикл (подготовка + расчёт + агрегация) — около 10 секунд
-
Ускорение относительно классического расчёта в 1С — более чем 2 500 раз
При этом точность расчётов сохраняется:
-
Прогноз, точка заказа и потребность совпадают с 1С с погрешностью до 0,5%
-
Уровень сервиса совпадает полностью
-
ABC/XYZ категории совпадают при одинаковой логике
Что это значит на практике?
Расчёт, который в 1С занимал минуты и часы (особенно при большом ассортименте), теперь выполняется за секунды или даже миллисекунды. Менеджер перестаёт ждать отчёт и начинает планировать закупки.

Что нужно для запуска
Требования минимальны:
-
ПК с видеокартой, поддерживающей Vulkan Compute (все современные карты NVIDIA, AMD, Intel Arc)
-
Windows 10 / 11 (достаточно минимальной установки Vulkan Runtime — одна программа)
-
Утилита для связки 1С с SQLite — программа-драйвер, поставляется в комплекте
-
После установки драйверов — возможно, потребуется перезагрузка
Никакого дорогостоящего серверного железа. Подходит обычная рабочая станция с офисной или игровой видеокартой. Не нужны специальные серверные GPU, выделенные стойки или облачные мощности. Всё работает локально, данные никуда не уходят.
Для кого это решение
Решение актуально для организаций, у которых:
-
В регистрах накопления миллионы и десятки миллионов строк
-
Расчёт прогнозов, точки заказа, потребностей или себестоимости — узкое место в бизнес-процессе
-
Есть штатный 1С-программист или команда, которая может развивать и адаптировать решение под свои задачи
Технология открытая. Шейдер и конфигурация написаны так, чтобы их можно было переписать под другой алгоритм без глубокого погружения в C++ или Vulkan. Если будете разбираться и возникнут вопросы по архитектуре, настройке или адаптации под конкретную задачу — пишите в комментарии, отвечу.
Всё это тысячи и десятки тысяч параллельных потоков на видеокарте. И всё это уже возможно.
Приложение. Состав архива
При скачивании решения вы получаете полный комплект для запуска и экспериментов:
|
Компонент |
Назначение |
|---|---|
|
Обработка для 1С |
Выгрузка данных из регистров, запуск GPU, загрузка результатов |
|
config.json |
Конфигурация движка (входные/выходные колонки, group_by, лимиты) |
|
shader.comp |
Исходный код шейдера на GLSL (весь математический аппарат) |
|
shader.spv |
Скомпилированный шейдер |
|
solve.py |
Скрипт-оркестратор на Python (подготовка данных, запуск движка, агрегация) |
|
compute_engine |
Исполняемый файл движка (C++ / Vulkan) |
|
base.db |
Тестовая SQLite-база с примерами данных |
|
Инструкция по запуску |
Пошаговое руководство для быстрого старта |
Ссылки и исходный код
🔗 GitHub репозиторий: GPU-Compute-Engine-1C
Что в репозитории:
-
src/main_public.cpp— исходный код движка (C++/Vulkan) -
examples/demo_mrp/— готовый пример MRP-расчёта -
CMakeLists.txt— сборка под Linux/Windows -
Полная документация по конфигурации и запуску
Другие статьи цикла:
-
GPU Compute Engine for 1C: Ускоряем массовые расчёты авансов в сотни раз— расчёт себестоимости тремя методами одновременно
-
GPU Compute Engine для 1С: FIFO, LIFO, средняя себестоимость — расчёт себестоимости тремя методами одновременно
🔗 Статья на Хабр: GPU Compute Engine для 1С: как перестать ждать часами и начать считать на видеокарте
Параметры системы, на которой проводились расчеты:
🧠 Процессор (CPU)
AMD Ryzen 7 260 (Zen 4, 2024 год)
8 ядер / 16 потоков
Частота: до 5.1 ГГц
🎮 Видеокарта (GPU)
Дискретная: NVIDIA GeForce RTX 5060 Laptop GPU (драйвер 580)
🧬 Оперативная память (RAM)
32 ГБ DDR5 (две планки по 16 ГБ от A-DATA)
Частота: 5600 МГц
Тест был на 1С:Предприятие 8.3 (8.3.25.1394)
💼 Есть вопросы?
Если в вашей системе есть тяжёлые расчёты, которые тормозят бизнес:
-
Расчёт себестоимости занимает часы
-
Закрытие месяца не укладывается в ночь
-
Авансы, остатки или прогнозы считаются слишком долго
Напишите в комментарии. Технология готова, инструменты есть, примеры работают.
Добро пожаловать в будущее параллельных расчётов в 1С.
Вступайте в нашу телеграмм-группу Инфостарт