
{kind=link}
Проблема
В Claude Code инструмент Edit не работает, пока файл не прочитан через Read в текущей сессии. Защита от правки вслепую — разумная, но дорогая. На файле в 2000 строк один Read тянет в контекст ~20 000 токенов. Дальше каждый turn пересчитывает накопленную историю через cache_read — и эта пачка раз за разом умножается на длину сессии. На активной разработке за день набегают сотни тысяч лишних токенов.
При этом самим Edit обычно меняется 1–3 строки. Остальные 1997 строк в контексте — балласт.
Решение
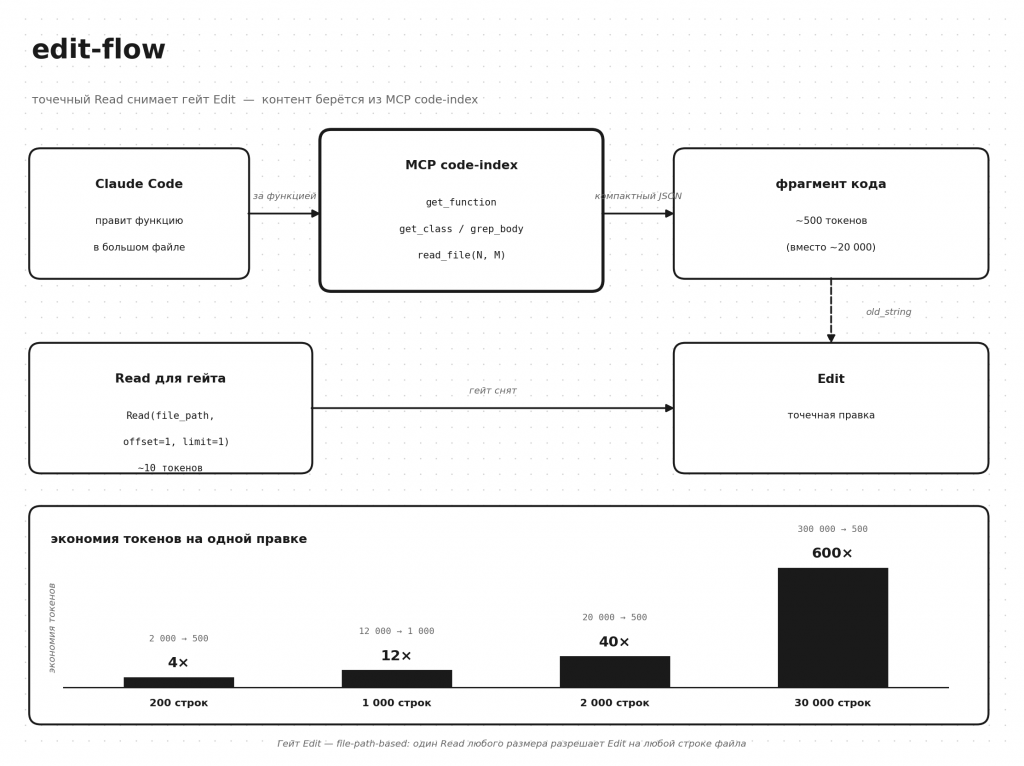
Гейт Edit устроен проще, чем кажется. Эксперимент 24 мая 2026 (Test A/B/D) показал: проверка file-path-based, не range-based. Один Read на путь — и Edit разрешён на любой строке этого файла, независимо от того, сколько строк прочитано.
Значит для снятия гейта достаточно Read(file_path, offset=1, limit=1) — около 30 байт, около 10 токенов. А содержимое для составления old_string берётся через MCP-сервер code-index — компактным JSON только нужной функции, класса или диапазона строк.
Цепочка из трёх шагов:
- 1.
mcp__code-index__get_function(repo, function_name)— тело функции (илиget_class, илиgrep_body/find_symbolдля поиска по содержимому, илиread_file(line_start, line_end)для конкретного диапазона). - 2.
Read(file_path, offset=1, limit=1)— ритуальный, ~10 токенов, снимает гейт. - 3.
Edit(file_path, old_string, new_string)— точечная правка,old_string— из шага 1.
Арифметика
Экономия токенов на одной правке (Read целиком vs MCP-паттерн):
- 200 строк: ~2 000 токенов → ~500 — в 4 раза дешевле
- 1 000 строк: ~12 000 → ~1 000 — в 12 раз
- 2 000 строк: ~20 000 → ~500 — в 40 раз
- 30 000 строк: ~300 000 → ~500 — в 600 раз
Эффект усиливается через cache_read. Каждый turn после правки пересчитывает накопленный контекст. Файл, прочитанный целиком один раз, тянется во все последующие cache_read — на длинных сессиях это умножается на десятки и сотни turn'ов. Точечный Read эту хвостовую нагрузку обнуляет.
Когда применять
Два одновременных условия:
- путь индексирован
code-index(есть вdaemon.toml); - точка правки известна — имя функции/класса из задачи или координаты, найденные через
grep_body/find_symbol.
Когда НЕ применять
- Файлы вне индексированных репо (
~/.claude/**,C:/Temp/, любые ad-hoc) — MCP-контента взять неоткуда. - Нужен обзор файла целиком — начать с
get_file_summary(карта без исходника), дальше точечно. - Бинарные форматы, oversize-файлы — MCP не помогает.
- Файл только что изменён, watcher
code-indexне догнал (несколько секунд) —bodyиз MCP отдаст старый снапшот,Editвернёт «string not found». Лечится повторнымget_functionчерез секунду или обычнымRead.
Замеры
По моим логам — 32 применения паттерна за один день в активной разработке (agents-mcp), около 30 за остальные 13 дней. Суммарно ~150 000 токенов экономии — на тарифах Sonnet это ~$0.45, на Opus ~$2.25. Цифра в долларах скромная.
Реальная польза — качественная: контекстное окно остаётся свободным под рабочую информацию (диффы, ответы тулов, состояния). На длинных сессиях это разница между «модель плывёт под собственной историей» и «модель помнит задачу до конца».
Настройка
Подключение code-index в .mcp.json проекта:
{
"mcpServers": {
"code-index": {
"type": "http",
"url": "http://127.0.0.1:8011/mcp"
}
}
}
Индексируемые репо в daemon.toml:
[[paths]]
path = "C:/MyProject"
alias = "myproject"
language = "rust"
И главное — правило в CLAUDE.md или ~/.claude/rules/. Без явной инструкции модель продолжает Read целиком — это привычка, она тянет к нему:
Перед Edit на индексированном файле:
1) контент берём через MCP code-index (get_function / get_class / grep_body / read_file с диапазоном);
2) Read(file_path, offset=1, limit=1) для снятия гейта;
3) Edit с old_string из шага 1.
Запрещены страничные Read (offset > 1) и Read целиком на индексированных файлах больше 500 строк.
С этим блоком модель применяет паттерн стабильно. Без него — забывает к третьей-четвёртой правке за сессию.
Связь с code-index
В связке с code-index паттерн раскрывается полностью: индекс находит функцию по имени за миллисекунды, отдаёт компактное тело, дальше — ритуальный Read и Edit. Это и есть основной сценарий работы code-index в Claude Code: не «семантический поиск ради поиска», а слой компактного контента для всех операций правки.
Исходники: github.com/Regsorm/code-index-mcp (MIT).
Вступайте в нашу телеграмм-группу Инфостарт