Кризис классического подхода: почему требования перестают работать
Название моей статьи немного специфичное. Я специально решил накалить обстановку среди всех обычных аналитиков, но на самом деле правда такова: классический бизнес-анализ постепенно уходит на нет. А что приходит ему на смену, мы сейчас узнаем.
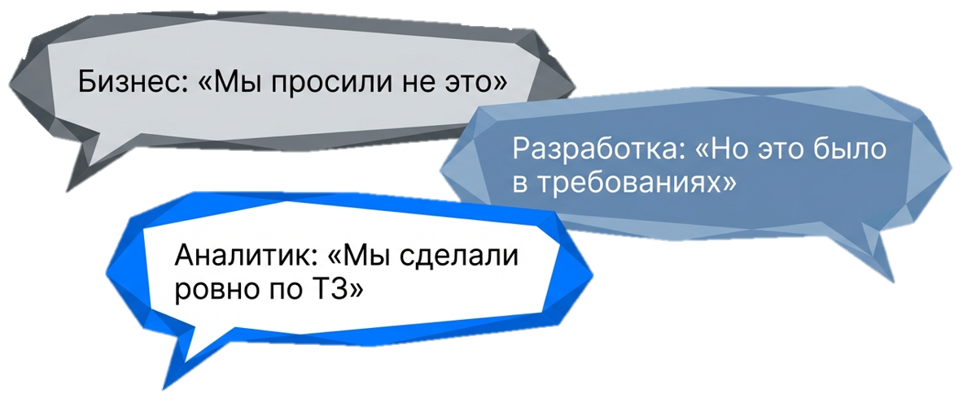
Кто из вас участвовал в проекте, когда вроде бы все требования согласованы, есть четкое ТЗ, есть четкие границы, сроки, понимание? Вы все реализовываете, идете до конца, доходите до финальной точки, а в конце оказывается, что что-то сделано не так?
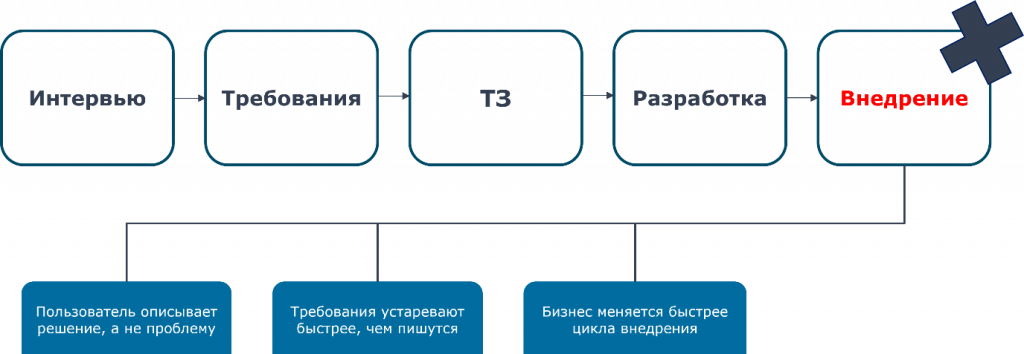
Я думаю, всем знакома эта история. На самом деле мы все привыкли к классическому подходу. У нас есть какое-то изначальное требование, мы идем, собираем интервью, оформляем эти требования, пишем техническое задание, формируем его, отдаем дальше на разработку и в конце сталкиваемся с тем, что пользователь описывал на самом деле не проблему, а решение.
Требования устаревают быстрее, чем они пишутся. И вообще под конец проекта получается так, что требования, которые были изначально, уже не соответствуют реальности. Соответственно, эта цепочка перестает работать.
Что же приходит ей на смену? Как правило, требования – это не факты, чаще всего это гипотезы.
Новая точка опоры: гипотезы и методология HADI
Моя статья о том, что хватит мыслить стандартами. Нужно мыслить немного иначе.
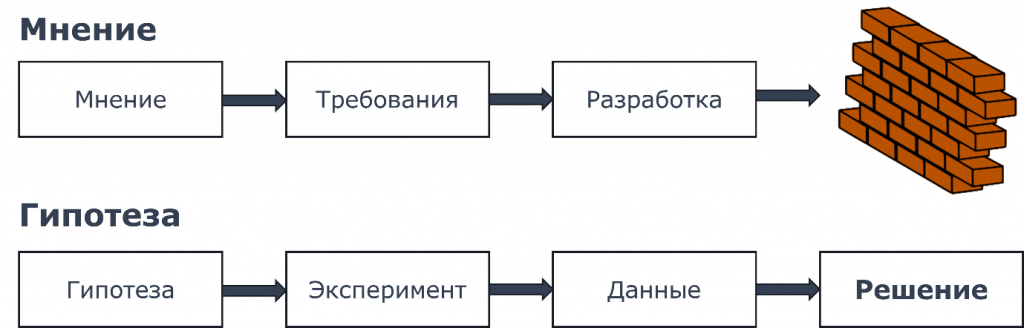
У нас меняется точка опоры. Если раньше у нас было какое-то мнение, требование, разработка, мы вроде шли по этому пути, все было круто, классно, но в какой-то момент упирались в кирпичную стену и не понимали, что будет дальше. Клиент потратил деньги, мы потратили свои ресурсы, силы, время на реализацию, но ничего не получилось.
Что предлагаю я? Вместо требований, мнений и задач у нас есть гипотезы. Мы предполагаем, что нужно заказчику. Мы не спрашиваем: «Какую кнопочку вы хотите?» Мы спрашиваем: «Для чего вам нужна эта кнопочка? Какую функцию она будет выполнять? Какие фактические результаты вы с этого получите?»
Из гипотезы мы формируем эксперимент, на основе этого эксперимента получаем данные, и вся эта цепочка так или иначе в конце превращается в решение.

В чем разница этих подходов на практике? У нас есть требование: «Я хочу новый отчет по остаткам». Казалось бы, оценим отчет, сформируем, сделаем, предоставим количество полей, кнопочек – и вроде все будет круто и классно. Но на самом деле правильнее будет задать вопрос: если менеджер будет быстрее видеть актуальные остатки, время обработки заказа сократится или нет? Как-то улучшится его процесс? Действительно ли что-то круто поменяется в его работе?
И я предлагаю вам пользоваться методикой HADI. Что это такое? Это метод исследования, который включает в себя четыре этапа.

Первый этап – гипотеза, когда мы формулируем гипотезу, а не придумываем решение. Второй – действие: мы проводим эксперименты, чтобы подтвердить эту гипотезу. Третий этап – data, когда мы собираем результаты, фактически оформляем их и видим реальные метрики, по которым можем выбирать и оценивать, насколько верна наша гипотеза и насколько в правильном направлении мы мыслим. И четвертый результат – insight, оценка эффективности.
Данные системы важнее слов: отказ от традиционных интервью

Все привыкли к интервью. Если мы берем любой классический подход, у нас всегда есть такой этап, как интервьюирование пользователей. И нам кажется, что к нам придет тот самый логист или тот самый заведующий складом, который скажет: «А где действительно у меня болит?»
Но чаще всего люди во время интервью не всегда говорят всю правду. И у нас в 1С уже есть данные. Вы просто на них не смотрите. У нас есть логи действий, частота использования функций, ручные обходные сценарии, время операций, ошибки, возвраты, отклонения процессов. Все это может сказать намного больше, чем любой пользователь, который работает с каким-то процессом.
Можно много говорить и очень красиво рассуждать о том, какие крутые вещи я предлагаю. Но давайте перейдем непосредственно к практике и посмотрим реальные кейсы.
Кейс 1: Нам нужен новый отчет
Самый первый кейс – «нам нужен новый отчет». Как оказалось, дело было вовсе не в отчете.
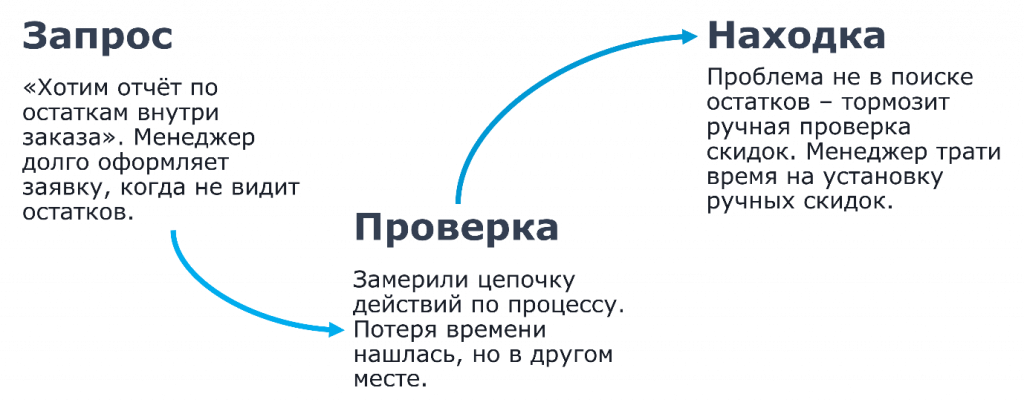
Изначально запрос был следующий: «Мы хотим отчет по остаткам внутри заказа. Менеджер долго оформляет заявку, когда не видит остатков». Что мы делаем? Мы идем по нашей методике. Мы замерили цепочку действий по процессу и нашли потерю времени.
Как оказалось, процесс действительно шел дольше, чем нужно. Но проблема была вовсе не в отчете и вовсе не в остатках. Проблема была в том, что менеджер тратил огромное количество времени на то, чтобы сверить ручную скидку, проверить за системой, действительно ли она правильно выбрала, действительно ли тот контрагент был указан.
И именно такой подход позволил понять, что зачастую те проблемы, которые озвучивает пользователь, не являются проблемами. Проблемы – в этапах, в процессах, в привычных действиях, в том, что вам кажется рутинным.
Что мы получили по факту? Наш фактический результат: мы внедрили автоматическую проверку отклонений и сократили время обработки заказа на 25%. Представьте эти цифры не в разрезе работы аналитика, а в разрезе бизнеса. На 25% мы оформляем заказы быстрее. Это значит, что в целом потенциально мы можем брать сверху еще один дополнительный заказ, как минимум.
Кейс 2: Кладбище ненужных функций
Следующий кейс – это кладбище ненужных функций. К сожалению, это очень часто встречающийся кейс в любых проектах, будь то 1С или что-то с ней связанное. Вроде бы клевое ТЗ, куча классных требований, есть абсолютно все, но по факту это кладбище.
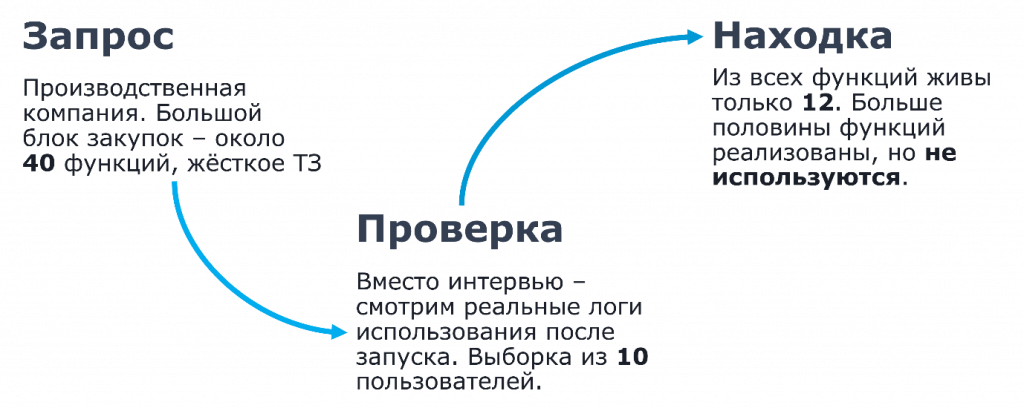
Запрос следующий: производственная компания, большой блок закупок, порядка 40 функций, очень жесткие ТЗ, очень жесткие правила и регламенты, которых нужно придерживаться.
Вместо интервью мы решили посмотреть, какое количество функций реально используют пользователи в системе. Какие кнопочки они тыкают, по каким страницам переходят, какие документы используют. И по факту оказалось, что среди всех этих функций, которые были описаны в ТЗ, на постоянной основе реально используется только двенадцать.
Представьте: 28 функций, которые можно взять и просто выкинуть из системы. Мы оптимизировали систему, оптимизировали работу самого предприятия, процессы сократились, время отклика системы увеличилось. Не проводя ни интервью, ни кучи обследований, ни аудитов производительности, а просто посмотрев логи системы.
По факту мы пересобрали интерфейс, убрали визуальный шум, убили все лишнее. Пользователь почти никогда не знает, что ему нужно. Он знает только то, что ему удобно. И это ключевой посыл, ключевой месседж моей статьи: зачастую мы пытаемся найти проблему и добавить функцию там, где решение находится совершенно под носом.

Я думаю, изображение максимально грамотно все это показывает.
Кейс 3: Когда ML оказался лучшим аналитиком
Последний кейс, который я хочу показать, как раз связан с тем, что в названии моей статьи есть два таких слова – «машинное обучение». Это кейс о том, когда машинное обучение оказалось лучшим аналитиком.
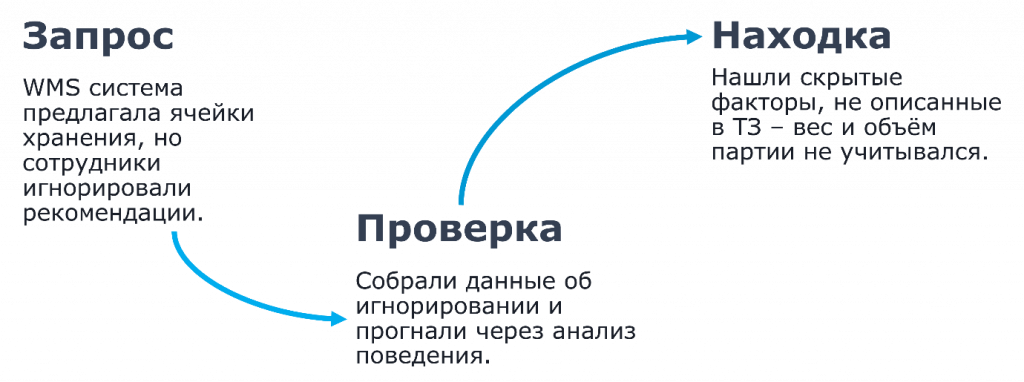
Изначальный запрос: WMS-система предлагала ячейки хранения, но сотрудники игнорировали эти рекомендации.
К нам пришел клиент с запросом: «Наши сотрудники игнорируют рекомендации системы». А WMS, по сути, только и делает, что рекомендует пользователю, по каким шагам ему нужно двигаться, куда и что нужно определить. То есть ты следуешь рекомендациям системы, но пользователи почему-то этого не делали.
Мы решили собрать данные об игнорировании, прогнали их через анализ. Естественно, в 2026 году никто не будет делать это руками. У нас есть искусственный интеллект, и все об этом прекрасно знают. Наш самый главный и идеальный помощник, который подскажет нам абсолютно все, всегда и самые верные способы.
Что мы и сделали? Мы прогнали через искусственный интеллект все полученные данные и, как оказалось, нашли скрытые факторы, которые не были описаны ни в ТЗ, ни сказаны на интервью. Ни один из пользователей, который ежедневно выполнял одну и ту же рутинную работу, об этом не сказал.
По факту вся проблема крылась в том, что вес и объем партии не учитывались при распределении ячеек.
Что же мы получили в результате? Мы просто-напросто обновили алгоритм. Изменение позволило пользователю просто следовать указаниям системы, и система заработала: быстро, так, как должна работать. При этом мы не потратили очень много времени, не было ни гигантских обследований, ни интервью. Просто зашли, собрали данные, посмотрели, проанализировали, сделали выборку и получили фактический результат.
Мы обновили алгоритм, и точность рекомендаций повысилась до 90%.
И самая важная мысль, на которую стоит обратить внимание: искусственный интеллект и машинное обучение никогда не заменят аналитика. Весь мой посыл в том, что аналитики, которые хотят двигаться дальше и развиваться в этом направлении, должны трансформироваться. Они должны идти в ногу со временем, понимать, какие инструменты и способы есть сейчас, куда стоит развиваться и что стоит использовать.
Искусственный интеллект – просто хороший помощник, который экономит нам кучу времени.
Эволюция роли: от переводчика к исследователю
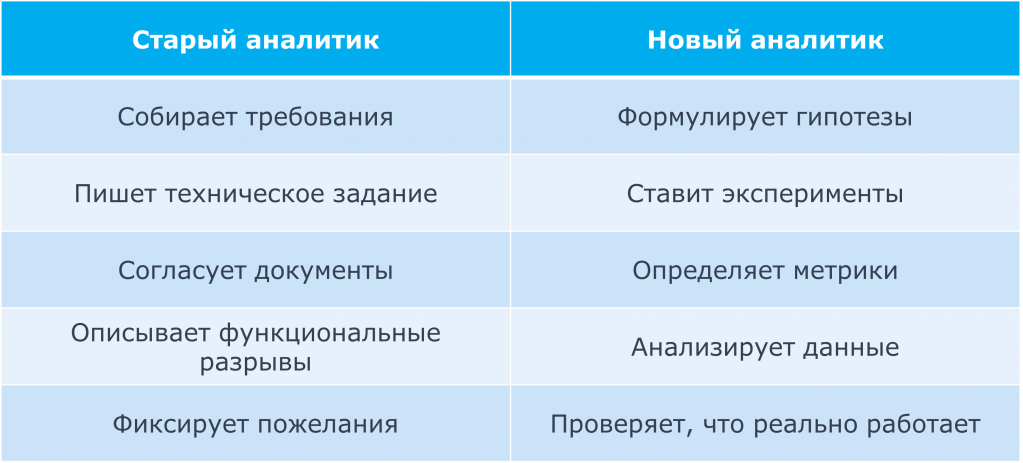
У меня есть таблица, которую я составил. У нас есть старый аналитик и новый. Чем они друг от друга отличаются?
Если старый аналитик собирает требования, то новый, современный, крутой, классный аналитик формулирует гипотезы. Он уже не мыслит категориями: «А давайте добавим вот эту кнопочку» или «Давайте сделаем такой-то отчетик». Он в первую очередь задается вопросом: «А как качественно повлияет на процесс та или иная хотелка от заказчика?»
Старый аналитик пишет техническое задание, новый аналитик ставит эксперименты. Старый аналитик согласует документы, новый определяет метрики, находит фактические результаты, за которые может зацепиться и от которых может отталкиваться.
Старый аналитик описывает функциональные разрывы, а новый анализирует данные. Собирает всю ту информацию, которая, казалось бы, недоступна или требует огромного количества часов обследования, интервьюирования, поиска в интернете, чтения статей на нашем всеми любимом ИТС. Но нет, оказывается, все можно получить из системы и на основе этого уже делать выводы, делать системы более реальными, более работоспособными.
И последнее: старый аналитик фиксирует пожелания, а новый проверяет, что реально работает.
Конкретные шаги: что внедрить в работу уже сегодня
Что вы можете начать делать уже сегодня? Это реально рабочие алгоритмы, которые вы можете прямо сейчас взять, открыть ноутбук, открыть блокнот со своими заметками и начать по ним двигаться.
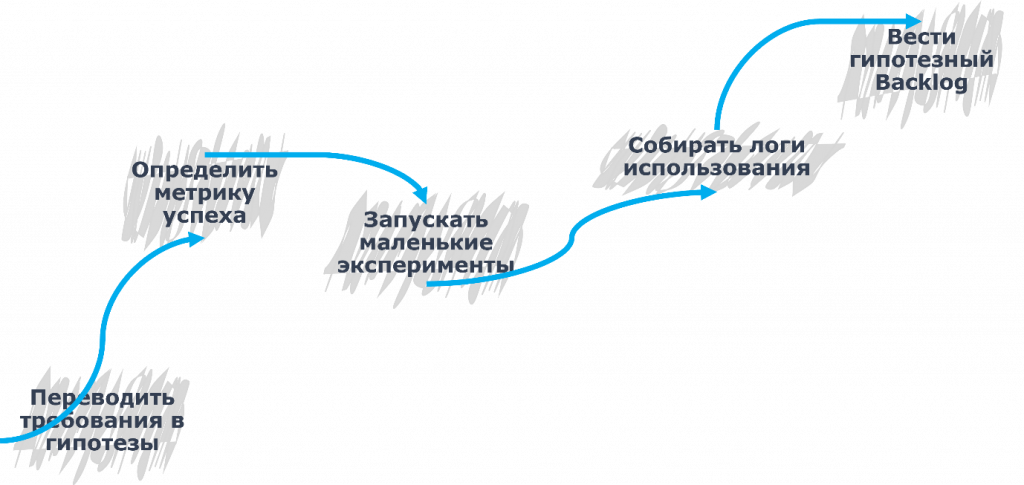
Первое – нужно постараться переводить любые требования в гипотезы. Мы должны задаваться вопросом: как это действительно скажется на результате, как это скажется на системе, как это скажется на пользователях?
Дальше, для того чтобы мы могли мыслить и развивать нашу цепочку, необходимо определить метрику успеха. То есть берем какой-то показатель: насколько сократится процесс? Насколько быстрее пользователь начнет заполнять тот или иной документ? Насколько быстрее он начнет находить тот или иной отчет?
Необязательно ставить большие, крупные эксперименты, работать с большими объемами и массивами данных. Нет, это не нужно. Можно делить, дробить, запускать маленькие эксперименты и на их основе получать уже реально крутые данные, с которыми можно оперировать, которыми можно изменять и трансформировать систему.
Дальше очень крутая практика – собирать логи использования. Смотреть, какие кнопки действительно нажимают пользователи, какие функции они используют в системе. Потому что можно говорить много о чем. И поверьте, за мой относительно небольшой опыт работы в сфере 1С я кучу раз слышал, как пользователь говорит: «Да нет, нам нужна именно эта кнопка» или «Нам нужен именно вот этот отчет».
Ты тратишь время, тратишь ресурсы, реализуешь, ходишь на защиты, показываешь, переделываешь. А по факту, когда спустя полгода-год заходишь в систему, оказывается, что пользователь три раза воспользовался этим отчетом, за который они заплатили, на который ты потратил время, который реализовал и защищал. Это самый распространенный кейс.
И последнее – вести гипотезный бэклог. Что это такое? Каждый раз, когда мы обращаемся к системе, особенно если это касается долгосрочных проектов, у нас есть такая история: вроде бы изначально было одно требование, мы превратили его в какой-то реально достижимый результат, определили метрики, поняли, как нам взаимодействовать с этой системой и что она дает пользователю. А потом возвращаемся спустя время и понимаем, что весь контекст забыли. Мы уже не помним, с чего начинали, от каких функций отталкивались, с каким запросом пришел клиент.
По сути, переводя все требования в гипотезы, дробя их на маленькие задачи и ставя эксперименты, мы можем выстраивать картину мира для себя. Но тут уже можно поговорить с точки зрения архитектуры: это масштабирование систем в ближайшем будущем.
Соответственно, гипотезный бэклог очень сильно нам в этом помогает. Мы можем в любой момент вернуться в любую исходную точку проекта, понять, что там было, что нам необходимо сделать, и превратить это, например, в новый сценарий развития, предложить пользователю альтернативные варианты того, как он может работать с системой. Может быть, есть какие-то иные вещи, которые пользователь не видит, но благодаря нашим гипотезам, нашему бэклогу мы можем просто показать ему картину работы с его системой.
Заключение
Мы перестаем быть авторами требований. Мы становимся исследователями реальности. В этих словах действительно очень большой смысл.
Перестаньте думать о том, что, добавив эту кнопочку или этот отчет в систему, вы сделаете жизнь пользователя лучше, а клиент скажет: «Спасибо». Нет, поверьте, спустя время он вернется и скажет: «Блин, что вы наделали? Раньше было намного круче. Меньше функций, меньше действий, и все работало и так». Поэтому становитесь исследователями, развивайтесь.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TEAM EVENT.

