RLM (Repository-Level Machine-coding)
Это прямое взаимодействие с файлами репозитория кодовой базы на предмет получения из них точечной и сжатой информации, а также определения целевых мест для планируемых правок/доработок.
У AI-кодера (Cursor, Claude, Codex, Kilo и т.д.) уже есть "глаза и руки": он "из коробки" умеет читать файлы, искать по проекту, писать нужные правки. Проблема начинается там, где проект - не аккуратный web-сервис на двадцать небольших файлов, а выгрузка большой ИБ 1С: ERP, ДО или УТ с тысячами BSL-модулей, XML-описаниями форм, ролями, подписками, расширениями и одинаковыми процедурами ПередЗаписью в сотнях объектов метаданных.
Обычный путь агента по Вашей задаче (без MCP-инструментов) в такой базе выглядит неэффективно: открыть файл, получить две тысячи строк в контекст, найти похожее имя, открыть еще десять файлов, утонуть в совпадениях, порассуждать, запутаться, проверить, снова порассуждать и т.д. Модель вроде бы работает, но быстро начинает платить токенами за воздух. Она тащит в диалог не выводы, а сырые данные.
MCP-сервер rlm-tools-bsl снимает именно эту инженерную боль. Это продукт для анализа больших кодовых BSL-баз 1С. Не "волшебный RAG", не замена архитектору и не очередной grep с красивой оберткой. Это компактная и мощная мастерская рядом с проектом: агент приходит с вопросом, запускает в песочнице короткий Python-код (по подсказкам, которые ему на старте дает сам MCP-сервер), а наружу получает только отфильтрованный результат.
Простая механика
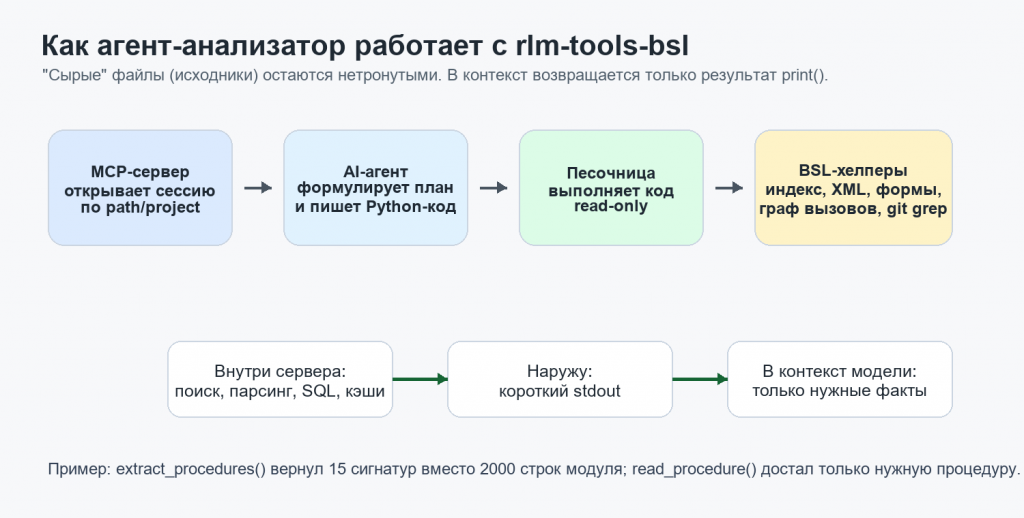
Есть главный принцип: для анализа нужна только стандартная кодовая база (выгрузка исходников формата CF или EDT и она остается на сервере (или на любом хосте, куда выгружена), в контекст агента возвращается только итоговый print().
Агент начинает с rlm_start: указывает путь к исходникам или имя зарегистрированного проекта. Сервер определяет формат выгрузки 1С - CF, EDT (да, поддержаны оба формата исходников), видит соседние CFE-расширения, поднимает сессионные кэши, подключает rlm-индекс (если он построен).
Дальше агент вызывает rlm_execute, пишет и выполняет Python-код в read-only песочнице. В этой песочнице есть 57 готовых хелперов (функциональных узкоспециализированных инструментов поиска) практически на все случаи жизни: поиск модулей, извлечение процедур, чтение конкретной процедуры, граф вызовов, парсинг XML метаданных, формы, роли, подписки, движения регистров, ссылки на объекты метаданных, использования объектов в коде, полнотекстовый git_search по всем файлам через git grep и т.д.
Типичный пример:
modules = find_module("АвансовыйОтчет")
print(modules)
Потом не надо читать весь модуль:
procedures = extract_procedures(modules[0]["path"])
print([p["name"] for p in procedures])
И только когда стало ясно, что нужна ОбработкаПроведения, агент берет ровно ее:
print(read_procedure(modules[0]["path"], "ОбработкаПроведения"))
Разница в результате очень простая. Без rlm-tools-bsl агент мог бы положить в контекст 2000 строк целевого файла. С rlm он сначала увидит 15 сигнатур, затем тело одной нужной процедуры. Экономия контекста и токенов в отдельных случаях может достигать нескольких сот процентов. По моим ощущениям как разработчика - это похоже на работу с нормальным отладчиком: не дамп всего стека вызовов и потом попытки понять что к чему, а сразу точка останова в нужном месте и просмотр в табло ключевых переменных.
Что делает агент-анализатор
Агент, вооруженный rlm-tools-bsl, действует не как читатель папки, а как инженер-механик с набором специализированных приборов.
Сначала он сужает область: ищет объект через find_module, бизнес-имя через search, произвольную строку или GUID через git_search. Если вопрос про форму, берет parse_form. Если про права - find_roles. Если про проведение - смотрит движения, подписки, обработчики и граф вызовов. Если надо понять, где используется объект метаданных, вызывает find_references_to_object и при необходимости find_code_usages.
Важная деталь: MCP-сервер не заставляет модель заранее знать все рецепты применения хелперов. В режиме slim rlm_start (инструмент старта песочницы анализа) отдает компактную маршрутную карту по хелперам, а подробные подсказки по ним агент сам при необходимости дозагружает через rlm_help. Это экономит стартовый контекст: full-стратегия содержит около 20 тысяч символов справки, slim - в 3,5-4 раза меньше.
Получается процесс, при котором не "модель догадалась или не догадалась", а нормальный инструментальный цикл:
1. Найти кандидатов.
2. Прочитать только нужные фрагменты.
3. Проверить связи по индексам или точечным поиском.
4. Сверить вывод с метаданными.
5. Вернуть человеку короткое объяснение с путями, строками и ограничениями.
Это особенно полезно на конфигурациях, где одно имя процедуры ничего не гарантирует. Например, в релизе 1.16.0 встроенный граф вызовов получил точную привязку ребер к методу через callee_key: одноименные ОбработкаПроведения и ПередЗаписью из разных модулей разных объектов метаданных больше не склеиваются в один ложный маршрут, искомый метод можно найти точно. Очевидно, что это уже не косметические отличия, а разница между "нашел цепочку" и "нарисовал красивую неправду".
Что получает агент-кодер
Для разработчика 1С ценность не только в том, что агент-помощник быстрее отвечает на вопросы по коду. Главное - он увереннее готовится к предстоящим правкам кода по Вашему ТЗ.
Перед изменением документа нужно найти его модуль, обработчики элементов формы, подписки, движения, ввод на основании, печатные формы и вызывающих. Перед изменением справочника - посмотреть реквизиты, владельцев, роли, определяемые типы и ссылки из других объектов. Перед чисткой старого механизма - найти не только декларативные ссылки в XML, но и обращения в коде, текстах запросов и строковых типах вроде "ДокументСсылка.X".
Это меняет Ваш стиль работы с LLM. Агент-кодер меньше "шаманит по названиям" и уверенно отвечает на нормальные инженерные вопросы:
- где реально используется объект;
- какие расширения перехватывают типовой метод (да, rlm-tools-bsl поддерживает и перехваты любых расширений, главное чтобы исходники расширений лежали рядом с исходниками основной конфигурации - src/cf, src/cfe);
- кто вызывает процедуру и насколько точен граф;
- что лежит в форме, а что в модуле формы;
- какие места надо проверить после правки;
- где поиск неполный и нужен индекс или уточнение;
- какие сигнатуры у методов, планируемых к доработке и т.д.
При этом rlm не требует от агента тащить всю кодовую базу в LLM. Большая часть тяжелой работы остается на файловой системе: SQLite-индекс, git grep, XML-парсинг, кэши сессии. Модель получает уже выжатую фактуру.
RLM - не замена технологии RAG, а дополнение
RAG (Retrieval-Augmented Generation) - подход, при котором перед генерацией ответа LLM сначала ищет релевантные фрагменты из заранее проиндексированной базы знаний (эмбеддинги, граф зависимостей, полнотекстовый поиск). Требует предварительной векторизации/индексации, инфраструктуры и обслуживания.
RLM (Repository-Level Machine-coding) — подход, при котором AI-агент исследует репозиторий напрямую: выполняет поисковые запросы, читает файлы, анализирует структуру — всё в реальном времени, без предварительной векторной индексации.
RLM не конкурирует с RAG. Это разные инструменты для разных ситуаций.
RAG - огромный дилерский центр: склад на тысячи квадратных метров, штат мастеров в одинаковой форме, найдут или привезут любую запчасть. Но пока запишут, пока примут, пока проведут регламентную диагностику - день (или больше) ушёл. И счёт в конце за работы впечатляет.
RLM - специализированный автосервис у дома: заехал без записи, мастер сразу под капот, разобрался именно с вашей проблемой и отпустил. Без редких запчастей с другого континента - но для повседневных задач быстрее, дешевле и точнее.
Фактически, rlm-tools-bsl - это специализированная автомастерская с целым набором разнообразного инструментария для анализа исходников 1С. Агент заходит в нее, ваша кодовая база уже "стоит на подъемнике", вокруг аккуратные стеллажи со всеми нужными инструментами и инструкция к каждому из них. И первым делом агент видит список всех инструментов и краткое описание каждого - для чего он и в каких случаях применять. После чего, отталкиваясь от той задачи, которую Вы ему дали, начинает "раскручивать и ковырять" ваши 1С-ные исходники (писать и выполнять внутри rlm-песочницы Python-скрипты).
Индексы и командная работа
У rlm-tools-bsl есть не только CLI rlm-bsl-index для индексов, но и удобный MCP-слой управления ими: тул rlm_projects регистрирует проекты по именам, тул rlm_index строит, обновляет, показывает статус и удаляет индексы. Это сделано не для красоты интерфейса, а для командной эксплуатации.
Тимлид может поднять один rlm-mcp-сервер (например, на том хосте, где хранятся или доступны все каталоги всех исходников всех проектов 1С), зарегистрировать на нем несколько конфигураций, построить индексы по каждой из них и выдать команде короткие имена проектов вместо абсолютных путей к самим исходникам. Чтение и анализ доступны без пароля, а мутирующие операции защищены: удаление, переименование и изменение проекта требуют пароль; build/update/drop rlm-индексов через MCP тоже требуют подтверждение паролем зарегистрированного проекта. То есть разработчик может попросить агента "проанализируй ERP", но не сможет случайно снести чужой индекс или перепривязать проект без знания явного секрета. Таким образом, rlm-сервер один, а пользователей - много.
На сильно измененной 1С:ERP 2.5 полная сборка rlm-индекса обычно занимает около 12-15 минут. Реальная цифра зависит от дисковой подсистемы, CPU и формата выгрузки. Зато дальше индекс живет как рабочий инструмент: если исходники 1С лежат под Git - инкрементальное обновление использует git-детект изменений и обычно занимает секунды или десятки секунд, а не повторяет полный обход всей конфигурации.
Натурное сравнение с RAG и графовыми MCP
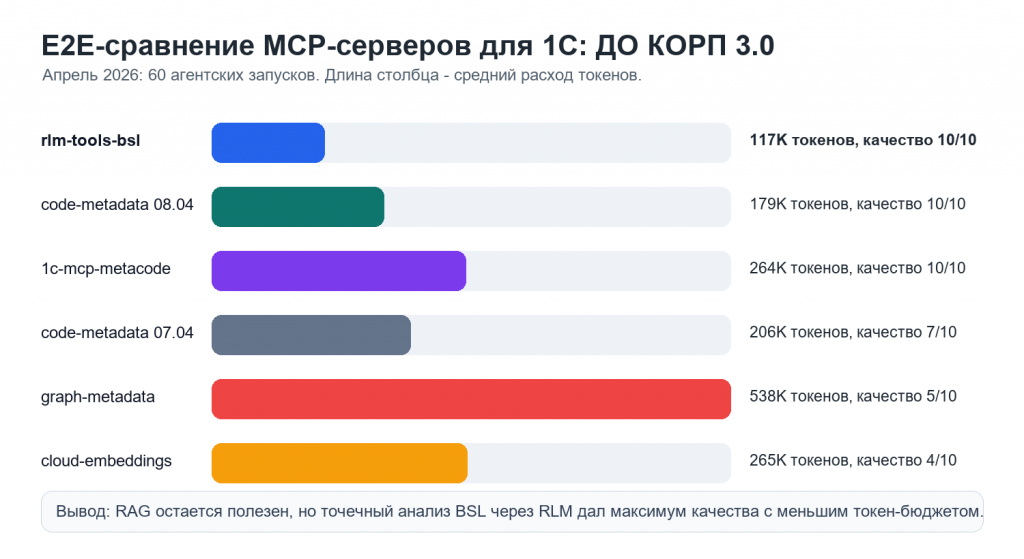
Фактическое e2e-сравнение, проведенное в апреле 2026: 6 MCP-серверов на конфигурации 1С:Документооборот КОРП 3.0, 10 бизнес-задач на каждый сервер, всего 60 агентских запусков. Методология, промпты и результаты опубликованы тут: perform_comparison_1c_rag_mcp.
Выводы: rlm-tools-bsl не заменяет технологию RAG. В описанном тесте три сервера набрали максимум качества. Но rlm дал этот максимум с минимальным средним расходом токенов и без отдельной инфраструктуры уровня "Docker + векторная БД + LM Studio". Еще интереснее, что версия платного векторного mcp code-metadata (от 08.04) поднялась по оценке с 7/10 до 10/10 в том числе после добавления парсера кода и механизмов полнотекстового поиска, заимствованных из rlm-tools-bsl.
При этом апрельские тесты уже немного устарели. После них проект заметно прокачался: v1.10 добавила агрегирующие хелперы get_object_full_structure и find_call_hierarchy; v1.11 принесла slim-стратегию и rlm_help, чтобы агент не таскал всю справку сразу при старте; v1.12 улучшила работу с соседними CFE-расширениями и многострочными сигнатурами; v1.13 усилила инкрементальное обновление индексов через Git; v1.14 добавила поиск использований объектов метаданных прямо в коде; v1.15 включила полнотекстовый git_search по всем файлам; v1.16 сделала граф вызовов точнее за счет привязки ребер к конкретному методу. То есть, опубликованное сравнение показывает картину вида не "лучший сервер на сегодня", а нижнюю планку относительно текущей версии.
Надо отдавать себе отчет, что граница применимости данного MCP-сервера - относительно детерминированный поиск/анализ (но именно таких ситуаций 90% при разработке). Если вопрос нечеткий - что-то вроде "как вообще работает бюджетирование в ERP", то семантический поиск RAG может быть полезнее. Но за предварительную векторизацию и построение RAG - Вы заплатите большим количеством времени и необходимостью поднимать либо локальную эмбеддинговую модель, либо использовать облачную. У rlm другой подход: "вот исходники, индексы построены за 10 минут - поехали анализировать". Но если нужен полный граф зависимостей всех объектов - графовый подход естественнее. Для детерминированных задач по BSL: найти объект, прочитать процедуру, построить вызывающих, проверить ссылки, разобрать форму, найти строку в XML - RLM хорошо попадает в ежедневные рабочие задачи 1С-разработчика. В целом, если в разработке используется мощная LLM, то часть семантического анализа она уже берет на себя и вопрос "бюджетирование в ERP" сама разбивает на детерминированные подзапросы в процессе анализа, так что и в этой ситуации от rlm-подхода будет много пользы.
Как начать использовать
Сам проект: https://github.com/Dach-Coin/rlm-tools-bsl
FAQ: FAQ
Быстрый старт: QUICKSTART
Полный подробный мануал по установке: INSTALL
Windows-служба, установка одной командой из PyPI (нужны права администратора):
irm https://raw.githubusercontent.com/Dach-Coin/rlm-tools-bsl/master/simple-install-from-pip.ps1 -OutFile simple-install-from-pip.ps1
PowerShell -ExecutionPolicy Bypass -File .\simple-install-from-pip.ps1
Linux + systemd-служба:
curl -LO https://raw.githubusercontent.com/Dach-Coin/rlm-tools-bsl/master/simple-install-from-pip.sh
chmod +x simple-install-from-pip.sh && ./simple-install-from-pip.sh
Docker-контейнер:
cp docker-compose.example.yml docker-compose.yml
# отредактируйте REPOS_ROOT и другие переменные
docker compose up -d
Для Windows Docker Desktop однозначно не лучший вариант: файловый I/O через WSL2/Virtiofs очень медленный (проверено на практике), особенно для индексации и live-поиска. На Windows практичнее ставить пакет на хост (можно собрать его даже без прав администратора) или запускать как службу. Docker оптимален на Linux.
Если развернете сервер в Docker - получите еще оно преимущество. Каждый новый релиз я публикую пакет в PyPI (пакетных хаб Python). Внутри docker-контейнера есть логика проверки версии установленного пакета и версии пакета в PyPI. Если в PyPI версия выше - идет автоматическое обновление. Но повторюсь - не используйте в Docker Desktop, либо будьте готовы что rlm-индексы будут строиться 60 минут вместо 10 (и вырастут таймауты для поиска). Если это делается один раз и дальше будет только их инкрементное обновление (по коммитам git внутри каталога исходников) - можно смириться.
После запуска сервер подключается к AI-клиенту как HTTP MCP:
{
"mcpServers": {
"rlm-tools-bsl": {
"type": "http",
"url": "http://127.0.0.1:9000/mcp"
}
}
}
Далее можно говорить агенту в чате обычным языком: "проанализируй мой проект Тест ERP через rlm-tools-bsl, найди все ссылки на Документ.ЗаказКлиента, построй граф вызывающих для метода РассчитатьСкидкиНаценки". MCP в этом не заменяет Ваше мышление разработчика (чем качественнее постановка - тем лучше результат). Он просто убирает из работы дорогой и лишний шум: бесконечный и неэффективный анализ файлов инструментами агента "из коробки".
Работа поискового ядра в том числе оптимизирована и проверена на слабых моделях, а именно:
- Cursor и Kilo в режиме Auto;
- MiniMax m2.7
- Grok Fast
Даже слабые модели, вооруженные rlm-tools-bsl - показывают неплохое качество анализа и итоговых отчетов.
Проект под лицензией MIT, если переиспользуете идеи/код - не забывайте указывать авторство. Дальнейшее развитие также планируется, буду рад Вашим PR и ишью.
UPD (05.06.26)
В репо сравнительного анализа mcp-серверов добавлен новый батл-тест
rlm-tools-bsl-v1170-vs-bsl-indexer-v0150
Результаты хорошие для обоих участников батла, подробности по ссылке
Вступайте в нашу телеграмм-группу Инфостарт