В этой статье мы поговорим о ревью в 1С. А точнее – о том, как превратить LLM из просто умного чата в реального ассистента для код-ревью, когда у вас нет доступа к привычному DevOps-стеку.
Подумайте, сколько примерно времени занимает у вас одно ревью. Наверное, вы скажете: «Зависит от задачи», – и будете правы. В среднем от 30 минут до 1 часа. Иногда времени уходит больше, когда код достаточно объемный и сложный.
А если таких ревью за день нужно сделать пять или десять, время складывается в весьма ощутимую величину. И это не анализ архитектуры. Это проверка кода строка за строкой: поиск дублирования, опечаток, проверка транзакций. Это все то, на что архитектор тратит свое самое дорогое время.
Есть еще одна проблема. Когда вы работаете на серверах заказчика, у вас часто нет доступа к Git, EDT, SonarQube. То есть у вас есть только конфигуратор, код и архитектор, который должен все это проверить.
И тут появляется человеческий фактор. После пятого ревью за день глаз уже замыливается и пропускает какие-то базовые ошибки и очевидные вещи.
Здесь возникает вопрос: можно ли отдать рутину машине? Чтобы она выполняла эти базовые действия, а архитектор анализировал сложную логику и архитектурные решения.
Однако если вы просто загрузите код в LLM, она будет давать достаточно поверхностные рекомендации: логичные, аккуратные, но не отвечающие вашим требованиям.
Объем открытого кода и публичной документации 1С слишком мал для обучения модели, а значительная часть реальной экспертизы – архитектурные подходы, паттерны работы с регистрами, транзакциями, запросами – существует в закрытых корпоративных стандартах и практике команд.
И тут у нас родилась гипотеза: а что, если мы дадим этот контекст LLM и превратим ее из умного чата в реального помощника?
Цели проекта и первые практические тесты
Во-первых, мы хотели сократить трудозатраты на ревью. Но не на 5–10%, а кратно: в два-три раза по мере адаптации системы и команды.
Во-вторых, планировалось повысить точность проверок. Чтобы качество нашего ревью не зависело от того, сколько кода разобрал архитектор за день и сколько кофе он уже успел выпить.
Хоть мы и поняли, что у LLM есть ограничения в работе с 1С, но решили проверить это на практике. Мы взяли код из наших реальных практик, отправили его в LLM и сказали: «Проверь код».
Модели вели себя непредсказуемо: результат был нестабильным. В этот момент у нас появилась задача: не просто констатировать ограничения, а системно сравнить модели и понять, какая из них лучше всего подходит для задачи код-ревью.
Методика оценки и влияние контекста
Для качественной оценки нам были необходимы справедливые метрики. За основу мы взяли классические метрики из Information Retrieval: Recall и Precision.
Recall – полнота. Какую долю замечаний, найденных человеком, модель смогла обнаружить.
Precision – это точность. Это доля корректных замечаний среди найденных LLM.
Но этого оказалось недостаточно, потому что LLM может давать ошибочные рекомендации, которые только навредят. Поэтому мы ввели PenaltyRate – штраф за такие инциденты.
При этом модель могла находить и то, что не нашел человек: какие-то новые ошибки, которые не увидел ревьюер. Для этого мы ввели BonusRate – вес новых важных замечаний, которые смогла обнаружить модель.
В итоге мы получили взвешенную модель оценки. Итоговая формула представлена на изображении.

Максимальный вес мы дали Recall. Нам важно, какую долю замечаний модель смогла обнаружить. В нашей задаче пропуск ошибки дороже, чем лишняя проверка.
Precision у нас идет на втором месте. Точность важна, но пропуск критичной ошибки для нас значительно хуже.
Следующим идет Bonus Rate. Мы поощряем систему за найденные проблемы, которые не нашел человек.
И штрафуем модель за нерелевантные замечания.
С этой формулой мы протестировали порядка 10–15 моделей на реальных фрагментах кода наших проектов – примерно на 50 фрагментах кода.

В первом случае модель работала сама по себе: мы просто давали ей код, и она его проверяла. Во втором случае мы подключали контекст: стандарты 1С, документацию, типовые решения. Этот подход называется RAG.
Если упростить, это похоже на работу разработчика. Перед тем как начать выполнять задачу, он читает документацию, смотрит примеры. Здесь происходит то же самое, только это делает модель. Мы ее не дообучаем, мы просто даем ей нужные материалы перед анализом. То есть модель работает не вслепую, у нее есть конкретный контекст.

Сначала код проверял архитектор. Это была наша точка отсчета. После этого тот же самый код мы отправляли модели и считали итоговый счет по формуле выше.
Лидером на момент тестирования оказался Gemini 2.5 Pro с использованием RAG. Но в топе LLM видно одну важную вещь: с использованием RAG и без него модели дают разный результат. То есть качество зависит от того, есть у модели контекст или нет. Не во всех случаях эффект был одинаковым: где-то модели сработали лучше, где-то хуже.
Сразу оговорюсь, что этот рейтинг был актуален на момент старта нашего пилота – в сентябре 2025 года.
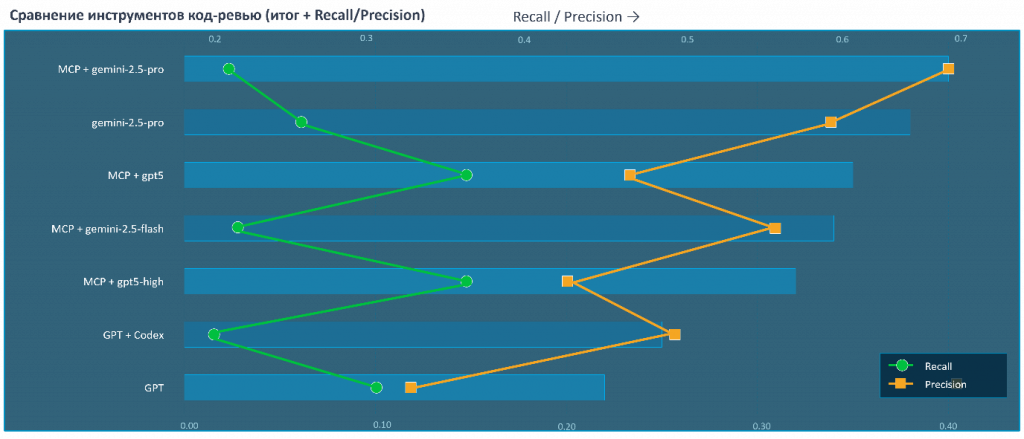
На графике видно сравнение работы модели с контекстом и без него. Разница получается достаточно заметной.
Главный вывод: контекст и инструменты значительно влияют на качество и точность работы модели.
Некоторые модели изначально дают качественный результат, но с дополнительным контекстом он становится стабильным. Именно из этого родилась архитектура нашего решения.
Архитектура решения: RAG вместо дообучения
Мы рассматривали вариант дообучения системы, но в наших условиях это оказалось непрактичным.
Во-первых, это дорого. Нужно собрать большой массив данных, разметить его, сформировать датасеты, настроить pipeline обучения и оплачивать дорогие вычислительные ресурсы. При этом модель приходилось бы постоянно обучать.
Во-вторых, такой подход сложно поддерживать. Меняются наши стандарты, выходят новые версии платформы, меняются требования и механизмы. При любом изменении требуется дообучение системы, иначе рекомендации быстро устаревают.
Фактически модель зашивается в какой-то определенный момент времени и может давать уже устаревшие или ошибочные рекомендации. Ее знания очень сложно прозрачно обновлять, и каждая итерация обучения непредсказуемо меняет поведение модели.
Поэтому мы пошли по пути RAG. Модель получает релевантный контекст прямо перед анализом. Мы меняем не саму модель, а информацию, на основе которой она будет принимать решение.
Что входит в нашу архитектуру?
Первый слой – это LLM. В продакшне у нас стоит Gemini 2.5 Pro, которая в рейтинге заняла самое высокое место.
Второй слой – это инфраструктура. Мы используем OpenRouter. Это, вероятно, самый популярный агрегатор для доступа к разным моделям.
Open Web UI – это веб-интерфейс, в котором происходит загрузка кода, хранится история чатов и запросов, через него подключаются LLM и инструменты анализа. Также через него происходит регистрация MCP-серверов.
Мы рассматривали и AnythingLLM, но Open Web UI показался нам более удобным для подключения инструментов и работы с разными моделями.
Третий слой – это специализированные анализаторы, то есть MCP-серверы.
Анализ BSL-кода – это проверка синтаксических ошибок и базовых проблем через BSL Language Server.
Поиск по шаблонам и стандартам – это поиск аналогичных фрагментов кода и сопоставление их со стандартами разработки.
Также мы подключили «Напарник 1С» как дополнительное экспертное мнение, как второй источник проверки.
И поиск по БСП – это проверка использования типовых механизмов и возможностей библиотеки стандартных подсистем.
Взаимодействие, системный промпт и пример отчета
Вот как выглядит взаимодействие.
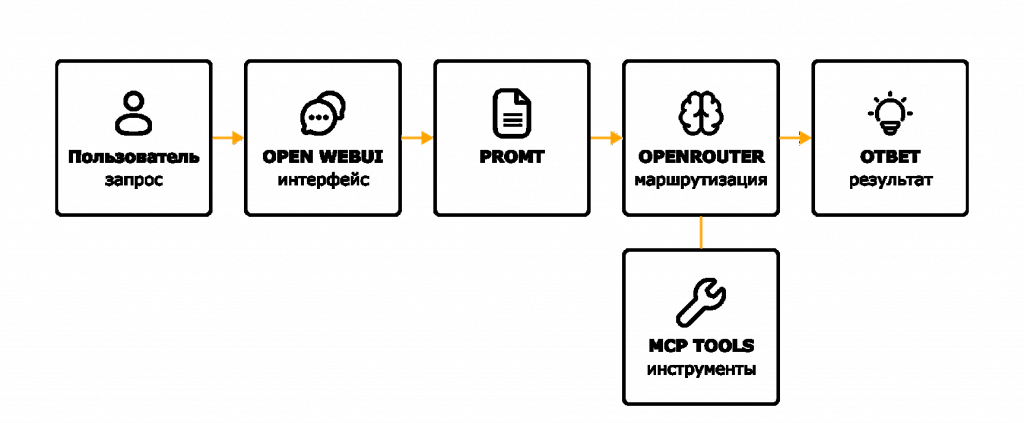
Разработчик загружает свой код в чат с LLM. Интерфейс работает через Open Web UI, модель подключается через OpenRouter. При этом модель работает в рамках системного промпта.
Важно прописать строгий регламент. Без жестких рамок LLM начинает «помогать»: дает советы вне задачи, предлагает переписать полмодуля, начинает фантазировать там, где нет уверенности. А нам нужен был предсказуемый инженерный инструмент, где зафиксирован порядок действий: сначала план анализа, затем проверка, потом вывод. Обязательный запуск инструментов, запрет на придумывание замечаний, если их нет, и в конце – краткий чек-лист по степени критичности замечаний и рекомендации о том, как эти замечания можно исправить.
То есть модель не просто пишет мнение. Она обязана учитывать результаты конкретных инструментов.
Почему мы выбрали режим чата? Во-первых, это универсально: он не зависит от среды разработки, в которой вы работаете. Во-вторых, это единая точка входа для всей команды: один инструмент, один интерфейс, единый процесс.
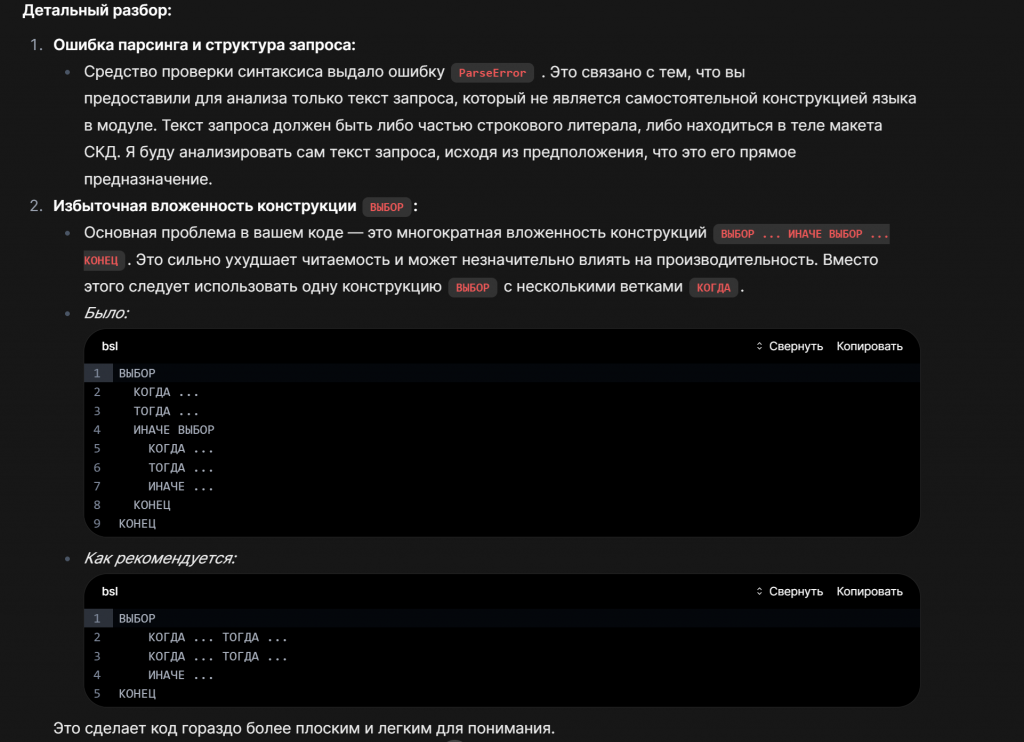
Это пример ответа системы на запрос «провести код-ревью». Благодаря системному промпту ответ получился достаточно структурированным.
Сначала идет подробный разбор: что именно обнаружено в коде, почему это ошибка и как ее можно исправить. В примере видно проблему сложной конструкции «выбор, когда». Модель объясняет, почему это ухудшает читаемость, и предлагает более плоскую структуру.

Далее идут замечания. Они ранжируются по критичности: критичные, средние и низкие. Так ревьюер сразу видит, какие замечания нужно исправить в первую очередь.
Как специалист работает с таким отчетом? Часть категорий можно принять почти автоматически. Это синтаксические ошибки, плохой нейминг процедур, функций, переменных, опечатки. Но логические ошибки в больших языковых конструкциях и сложных ветвлениях архитектор проверяет сам.
То есть система становится первым фильтром, а финальная проверка все еще остается за человеком.
Этапы внедрения: от пилота до стандарта
Первым шагом было локальное тестирование. У нас была небольшая группа из нескольких человек, которые работали с этой системой на своих реальных задачах. Они смотрели, где шум, где ошибки, как справляется инструмент, все ли их устраивает и все ли удобно.
На этом этапе мы готовили рабочее место для ревью в 1С. Фактически мы собрали АРМ, где фиксируем найденные замечания, их типы и время, потраченное на ревью. Мы не хотели, чтобы это превратилось в историю «попробовали, понравилось и забыли». Нам нужна была измеримость и управляемость.
Следующим этапом было пилотное внедрение. Здесь мы подключили первых архитекторов – порядка пяти человек. Они проводили ревью через систему, давали нам обратную связь и фиксировали свои результаты. На этом этапе архитекторы проверяли каждое замечание. Изначально они были настроены достаточно скептически, потому что у всех уже был опыт работы с LLM, и чаще всего на тот момент он был неудачным.
Следующим этапом стало расширение охвата. Здесь мы уже подключили ведущих и старших разработчиков, и система перестала быть только инструментом архитекторов. Разработчики стали использовать ее еще и для саморевью.
Зачем нужен такой подход? Во-первых, снимается часть нагрузки с архитектора. К архитектору приходит более чистый код: разработчики видят свои часто повторяющиеся ошибки и исправляют их до ревью.
Второй момент – это обучающий эффект. Когда разработчики видят свои ошибки, они со временем перестают их допускать.
На этом этапе мы также ввели в компании обмен знаниями по часто встречающимся ошибкам. То есть мы обучали других разработчиков на чужих ошибках. Так мы хотели прийти к тому, чтобы люди начали писать код чище и лучше.
Последним шагом было полное внедрение. Когда стало понятно, что система в целом работает и дает эффект, мы перевели ее в полноценную инфраструктуру.
Изначально система работала на игровом компьютере в офисе. Ребята-коллеги вообще не обрадовались, когда им запретили играть в Mortal Kombat на работе. Так что пришлось переехать с локальной LLM на облачный сервер.
И это стало нашим стандартом. Сейчас 100% задач в компании проходит через ревью. Благодаря АРМ мы фиксируем все ошибки, вся разработка находится под контролем. До внедрения ИИ мы просто не успевали проверять все задачи.
Поэтапная стратегия позволила минимизировать риски и адаптировать систему под реальные задачи. У нас не было финансовых потерь, не было сложного привыкания команды и тяжелой адаптации. Это позволяет нам довольно быстро и легко вводить новых ревьюеров.
Мониторинг, обратная связь и ограничения ИИ
Сейчас система работает на всех проектах. Но при этом мы продолжаем ее регулярно измерять и дорабатывать.
Во-первых, статистика собирается регулярно. Мы фиксируем время на ревью, количество выявленных проблем, долю замечаний, подтвержденных ревьюерами. Все ошибки у нас разбиты по типам, есть ранжирование.
Во-вторых, мы регулярно получаем обратную связь. Проводим опросы ревьюеров по специальным анкетам. На статусах разбираем кейсы, где ИИ ошибся, дал ошибочную рекомендацию. Смотрим, где система дает лишнюю нагрузку. Мы реагируем на обратную связь, потому что без доверия инструмент работать не будет.
В-третьих, мы проводим итеративные улучшения: уточняем промпты, настраиваем контекст, дополняем его и оптимизируем интеграции с внутренними инструментами.
Однако важно понимать, что ИИ – это инструмент, и у него есть свои ограничения.
Например, отсутствие полного архитектурного анализа. Модель работает с фрагментом кода. Она не видит всю систему целиком, не видит подписки, регламентные задания, расширения. Она может оценить локальную логику, но не всегда понимает глобальные архитектурные связи.
Второе – риск «галлюцинаций». Даже при строгом промпте и инструментах модель иногда дает ошибочные замечания. Именно поэтому финальное решение остается за архитектором.
Третье – пропуск критичных для 1С ошибок производительности. Особенно если это сложные сценарии с косвенными вызовами или сценарии, завязанные на большой объем данных. LLM не знает, сколько записей будет в вашем регистре через год.
Четвертое – модель не видит платформенные антипаттерны. Есть вещи, которые понимает только человек с опытом работы в конкретной конфигурации.
И самое опасное – иллюзия автоматизации. Когда создается ощущение: раз ИИ проверил, значит, все хорошо, ревью сделано. Это не так. ИИ может помочь, но без процесса и ответственности человека он качество проверки не вырастет.
Оценка эффективности, парадокс адаптации и итоги
Мы ввели формальную методику оценки. До внедрения ИИ мы используем архивные данные традиционного ревью, то есть берем статистику, как было до. После внедрения ИИ уже фиксируем статистику с момента запуска пилота.
Отслеживаем фактическое время разработки и время, затраченное на ревью. И считаем основной показатель – коэффициент ревью. Формула такая: время на ревью минус 15 минут, в знаменателе – общие затраты на разработку.
Почему минус 15 минут? Это техническая константа, которую мы приняли за базовую. Она включает загрузку кода, запуск анализа и действия, которые никуда не уйдут даже при автоматизации. А нам нужно было понять именно долю ревью в общей трудоемкости. Этот коэффициент позволяет нам видеть динамику. На момент старта он был 2,5.
Однако, когда мы стали считать этот коэффициент, на первом этапе использования ИИ время на ревью у нас значительно выросло. Мы выявили для себя несколько ключевых причин:
-
Адаптация инструментов. Не сразу все было налажено, не сразу все корректно собиралось и учитывалось.
-
Низкий уровень доверия к ИИ. Архитекторы перепроверяли каждое замечание. Иногда они тратили гораздо больше времени, чем когда проводили ревью сами.
-
Эффект масштаба. Когда инструмент начинает работать, он выдает больше замечаний. И все эти замечания тоже надо проверить.
-
Этап донастройки системы. Мы все еще уточняли промпты, корректировали контекст, оптимизировали интеграции.
-
Человеческий фактор. Людям все еще нужно было привыкнуть к процессу, пройти стадию отрицания работы с ИИ и прийти к принятию.
Это нормальная фаза адаптации. Если измерять эффект в первую неделю, он всегда пойдет в минус. А дальше, по мере стабилизации системы, показатель будет улучшаться.
На изображениях представлены реальные примеры замечаний ИИ. Также видны комментарии нашего эксперта: он проанализировал эти замечания и оценил, насколько они корректны.

В первом примере мы видим неявные запросы в цикле. Модель достраивает недостающий контекст по смыслу и формулирует опасения.

Во втором примере модель демонстрирует понимание архитектуры платформы.
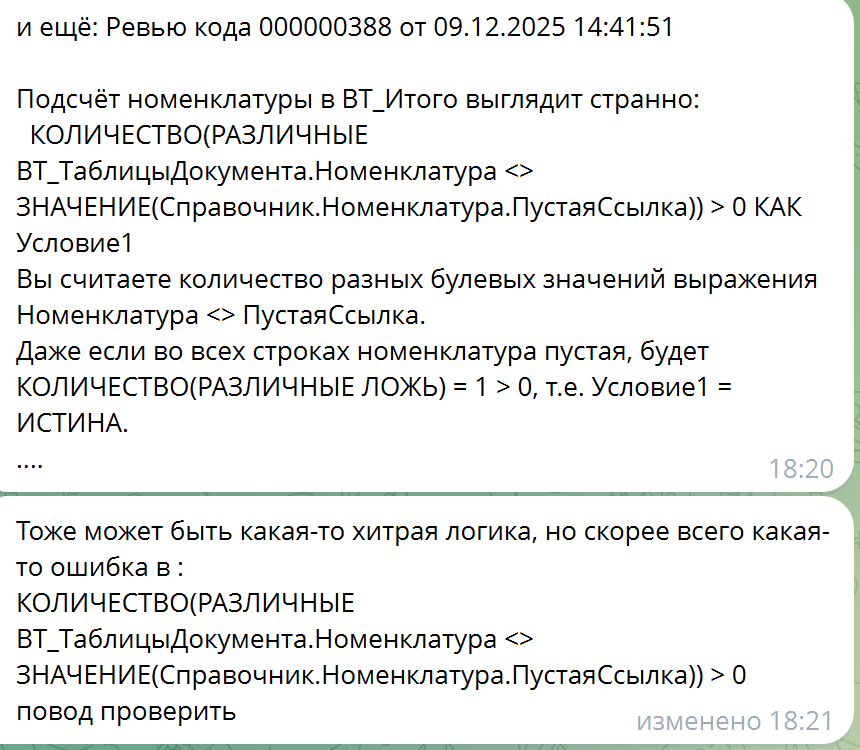
Третий пример показывает, что модель гораздо лучше выполняет анализ больших языковых конструкций, чем это мог бы сделать человек.

В четвертом примере у нас некорректное условное ветвление и инициализация переменной. Человек очень легко может пропустить такую ошибку.

В пятом примере, помимо найденной ошибки, ИИ описал полноценный сценарий ее воспроизведения. То есть рассказал, как эту ошибку можно обнаружить.

И последний пример – некорректное соединение таблиц, которое может быть неочевидно на тестовых данных.
Какие общие итоги пилота?
Среднее время проведения ревью сократилось на 40–50%.
Коэффициент эффективности – 1,6. Иногда бывает чуть больше, иногда чуть меньше, но в среднем цифра такая. Стартовый показатель был 2,5.
Количество пострелизных дефектов снизилось на 25–30%. Это результат общих усилий: и проведения ревью, и использования ИИ.
За счет использования ИИ у нас полноценно проверяются все задачи. А в продакшен уходит более качественный код – ошибок стало на 25–30% меньше.
При этом 70% замечаний, которые выдает система, ревьюеры подтверждают, как корректные и полезные. Для инструмента, который работает около полугода, это достаточно хороший базовый результат.
Стандартизация: каждый фрагмент кода теперь проходит через один и тот же регламент проверки. Неважно, кто делает ревью и в какое время: процесс и порядок анализа всегда одинаковые. Это снижает субъективность и делает процесс более стабильным.
Статистика и выводы
На следующем изображении мы представили немного цифр.
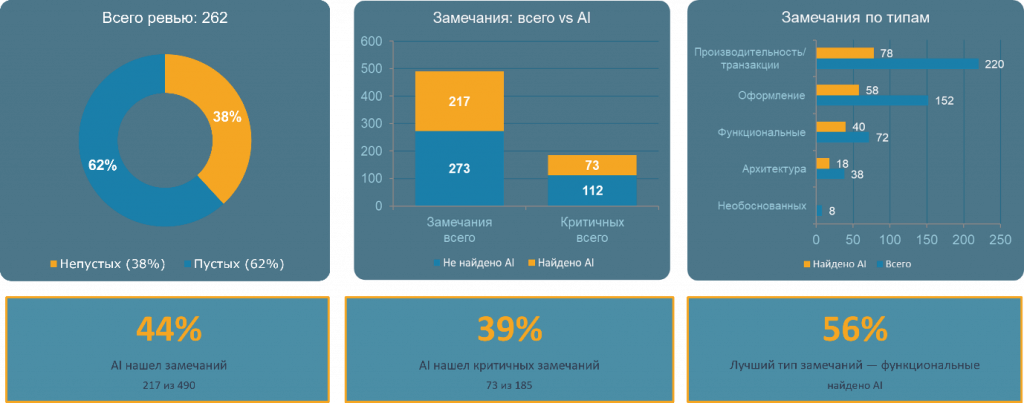
Всего мы проанализировали 262 ревью. Из них 100 были непустыми, то есть содержали замечания. 162 ревью прошли без замечаний, при этом их количество увеличивалось по мере работы пилота. Сейчас все больше ревью проходят без замечаний. Это косвенный признак того, что разработчики допускают меньше ошибок.
Всего было выявлено 490 замечаний. Из них 217 нашел ИИ, то есть 44%. Система уже берет на себя значительную часть работы по поиску проблем в коде.
Всего было найдено 185 критичных замечаний, из них 73 обнаружил ИИ – это примерно 39% всех критичных замечаний. То есть система уже участвует в выявлении значимой части серьезных дефектов.
Также замечания разбиты по типам, и самый большой процент – 56% – составляют функциональные ошибки.
При этом всего восемь замечаний оказались недостаточно обоснованными. Это значит, что уровень шума у системы в итоге оказался достаточно низким.
ИИ в код-ревью работает, но только если его правильно настроить. Просто вставить код в чат недостаточно. Моделям нужен контекст: ваши стандарты, ваши практики, ваш накопленный опыт. RAG – это способ дать этот контекст без дорогого дообучения.
Мы прошли путь от «просто попробуем» до полноценного стандарта на всех проектах. На это ушло около полугода. Потребовались итерации, честная обратная связь, которая не всегда была приятной, особенно на начальных этапах, и готовность признать, что сначала стало хуже, чтобы потом стало лучше.
Три вывода, которые можно забрать с собой:
-
Выбор модели важен, но без контекста даже хорошая модель дает поверхностный результат.
-
Не измеряйте эффект в начальный период работы пилота. Адаптация требует времени.
-
ИИ берет на себя рутину, но ответственность все еще остается за человеком.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TEAM EVENT.


Вступайте в нашу телеграмм-группу Инфостарт