Это не история про «ИИ сам обновил 1С». Так не работает. История скорее про то, как переложить на модель черновую рутинную работу, а человеку оставить то, где действительно нужна экспертиза: решения, ревью и ответственность за результат.
Почему обновление доработанной 1С начинается с инвентаризации
Когда мы начинаем большое обновление, первый вопрос обычно очень простой: что у нас в базе вообще доработано? Что изменено относительно типовой конфигурации?
Сразу появляется второй вопрос: что из этого еще актуально и что нужно перенести в новую конфигурацию?
Типичная ситуация выглядит так: документации нет. Есть набор внешних обработок, расширений, правок типовых объектов и общее ощущение, что все это когда-то было нужно. Но кому, зачем и нужно ли сейчас — уже не очень понятно.

Немного контекста из проекта, о котором дальше пойдет речь. Мы обновляли УТ 11 до актуального релиза УТ 11.5. Конфигурацию не обновляли около восьми лет. За это время накопилось много доработок, в том числе 72 внешние обработки.
Перед нами стояли вполне практические вопросы: что переносить, что можно выбросить и каких проблем ждать при обновлении.
Если делать инвентаризацию вручную, по каждому объекту нужно открыть конфигуратор, изучить код, понять назначение и хотя бы кратко это зафиксировать. В простом случае уйдет пять минут. В сложном — час. Если умножить это на все объекты, получится примерно неделя работы только на то, чтобы разобраться, что когда-то было сделано. И это еще до начала самого обновления.
Поэтому инвентаризацией часто никто не занимается. Команда ввязывается в проект обновления, а дальше, как говорится, по ходу разберемся. В итоге успех обновления во многом зависит от опыта того, кто его выполняет, и, не побоюсь этого слова, от героизма отдельных участников.
Почему нельзя просто отдать все модели
Конечно, хотелось бы поставить модели задачу в стиле «делай хорошо, не делай плохо» и через какое-то время получить готовый результат. Но так это не работает.
Первая причина — у модели недостаточно знаний, чтобы выполнить такую работу полностью самостоятельно. И дело даже не в знании платформы 1С или встроенного языка. Модель не погружена в бизнес-контекст: она не знает, что это за доработки, для чего они нужны, чем занимается компания и как устроен ее бизнес. Здесь в любом случае нужен человек.
Вторая причина — техническая. У моделей есть ограничение контекстного окна. Нельзя просто загрузить большой набор доработок вместе со старой и новой конфигурацией и попросить выполнить весь комплекс работ по обновлению. Современные модели на такое пока не способны.
Значит, задачу нужно декомпозировать.
Мы делим ее в двух направлениях.
Первое — по объектам и функциональным блокам. Каждую доработку анализируем и обновляем отдельно.
Второе — по этапам. В нашем случае получилось пять этапов:
-
документирование;
-
анализ и классификация;
-
поиск проблем;
-
исправление;
-
тестирование.
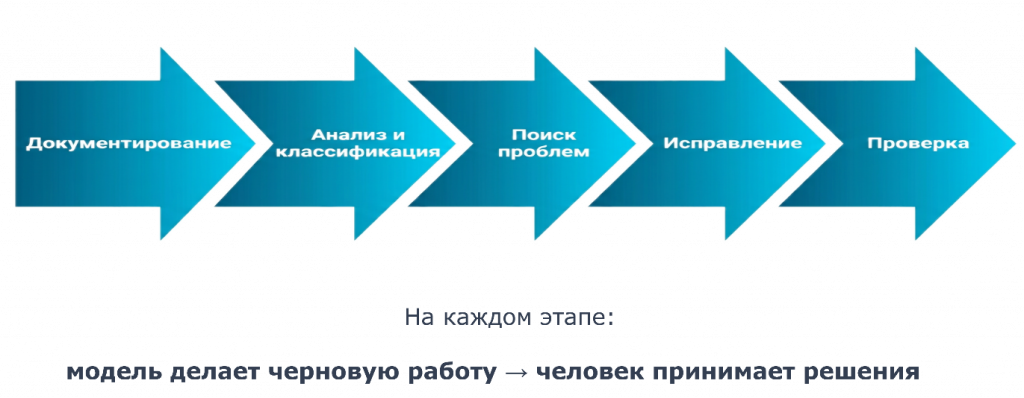
На каждом этапе модель делает черновую работу, а человек проверяет результат и принимает решения в сложных случаях. Эта схема одинаково подходит и для обработок, и для документов, и для других объектов.
Что понадобится для такого подхода
Коротко об инструментах.
-
Кодовый агент. В моем случае это был Claude Code, но подойдет Cursor или другой агент, который умеет работать с файлами проекта. Важно, чтобы он мог подключать MCP-серверы: так мы расширяем набор инструментов модели и даем ей доступ к нужным операциям.
-
MCP-сервер для 1С-разработки. Он дает доступ к базе: можно получать метаданные и данные, валидировать запросы, читать журнал регистрации.
-
Субагенты. Это способ масштабировать работу. Мы отлаживаем подход на одном объекте, а потом запускаем похожую обработку сразу по десяткам объектов.
-
Навыки. Они помогают модели выполнять технические действия: разобрать обработку в XML, собрать ее обратно, запустить предприятие и т. д.
-
База знаний. Набор Markdown-файлов с типовыми проблемами, решениями и проектными договоренностями. К ней еще вернемся.
Без такого набора инструментов модель упирается в ограничения: ей не хватает доступа к данным, технических знаний и понятных правил работы.
Этап 1. Документирование
Прежде чем что-то обновлять, нужно понять, что в системе доработано. Что актуально, что устарело, а что вообще непонятно зачем существует.
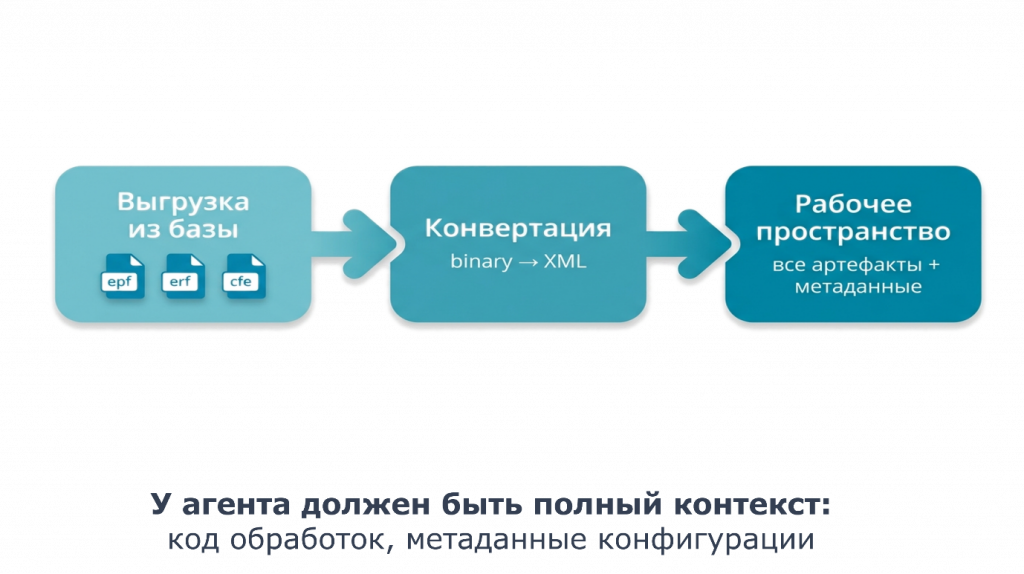
Сначала готовим рабочее пространство. Кодовый агент не умеет работать с бинарными файлами 1С — ему нужны текстовые файлы. Платформа позволяет выгружать в XML конфигурацию, расширения, внешние обработки и отчеты.
Это и делаем в первую очередь: выгружаем доработки в рабочее пространство проекта, в одну понятную структуру папок, чтобы агент мог читать их как текстовые файлы и находить связанные объекты конфигурации.
Делать это вручную необязательно. Уже на этом этапе можно привлечь модель: попросить написать скрипт для пакетной выгрузки или подключить готовый навык и дать задачу: «В этой папке лежат обработки. Выгрузи все в XML и разложи по отдельным папкам».
Зачем нужна такая глобальная выгрузка? Для эффективной работы модели с кодом ей нужен полноценный контекст. Если она изучает обработку и видит вызов метода из общего модуля основной конфигурации, у нее должна быть возможность найти этот общий модуль, посмотреть метод, чтобы понять функционал обработки.

Когда рабочее пространство готово, начинается основная работа.
Универсальные промпты
Для документирования мы используем универсальные промпты. По сути, это шаблон анализа: что агент должен сделать, чтобы понять назначение доработки, какие данные изучить и в каком формате вернуть результат.
На вход такому промпту передается объект 1С: обработка, отчет, документ или другая сущность. На выходе мы получаем карточку с одинаковой структурой.
В карточке, например, есть:
-
назначение доработки;
-
какие данные она читает;
-
какие данные меняет;
-
с какими объектами 1С связана;
-
что может быть важно при переносе на новую конфигурацию.
Единая структура здесь очень важна. Если прогнать один такой промпт по 72 обработкам, мы получим 72 карточки, которые можно свести в одну таблицу. Пользователю будет проще проанализировать ее и принять решения по объектам.
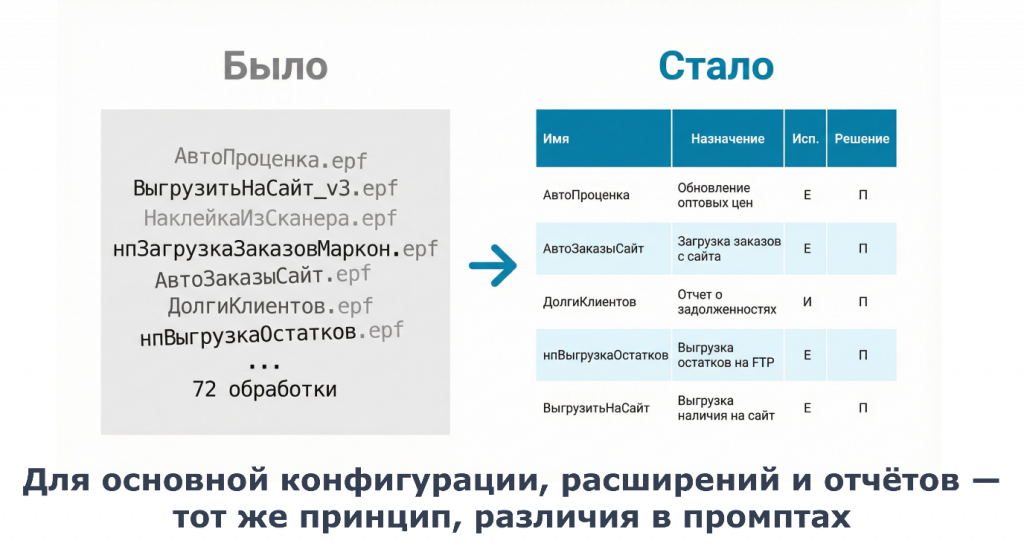
Так из набора непонятных файлов получается уже не идеальная, но вполне обозримая картина.
А если меняли типовые объекты?
С добавленными объектами все относительно понятно. Сложнее с изменениями типовых объектов.
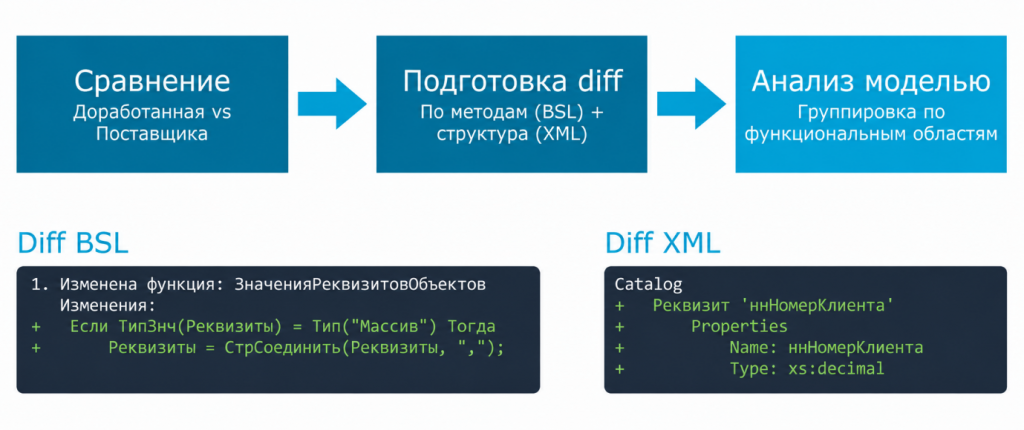
Передать модели общий модуль на три тысячи строк со словами «разбирайся, что тут доработано» — нерационально. Возможно, там изменено всего пять строк. Зачем засорять контекстное окно остальным кодом? И еще не факт, что модель поймет, какие именно строки наши, а какие типовые.
Поэтому для типовых объектов нужна предварительная обработка. Мы не передаем модели весь модуль. Мы находим измененные методы и выгружаем только изменения в формате git diff.
Это компактно и понятно: добавленные строки помечены плюсом, удаленные — минусом. Языковые модели хорошо знают этот формат, поэтому им обычно хватает такого представления, чтобы понять, что именно поменял разработчик.
Если агенту понадобятся дополнительные данные, он сам найдет нужные методы в XML-выгрузке. В этом и смысл кодового агента: мы не обязаны складывать все материалы в один огромный промпт.
Со структурой объектов подход похожий. Вместо больших XML-файлов лучше дать компактный структурный diff: какие реквизиты добавлены, какие элементы формы изменены, какие команды появились.
Модель анализирует не весь объект целиком, а только изменения. Так меньше шума, а результат точнее привязан к тому, что действительно менял разработчик.
Что делать с расширениями
С расширениями есть отдельная сложность — механизм заимствования кода.
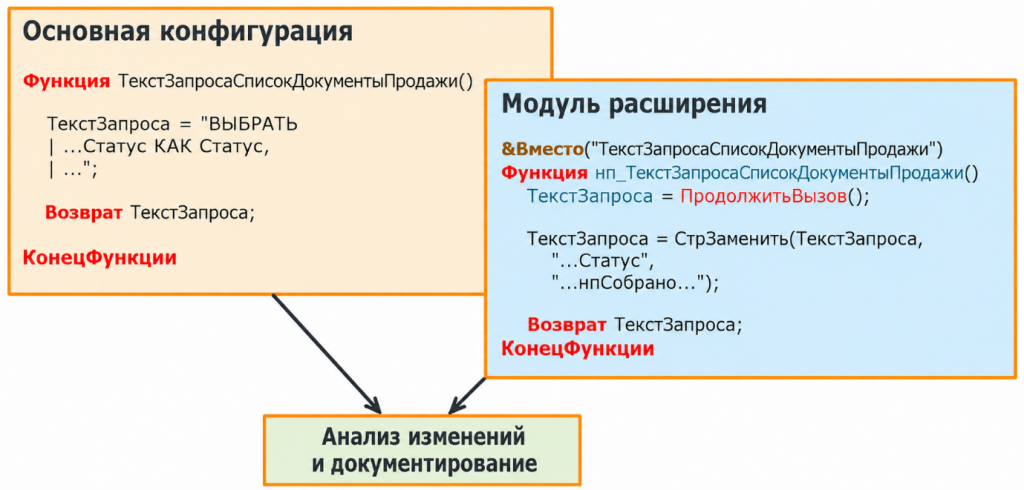
Методы можно дорабатывать через аннотации «перед», «после», «вместо». Если передать модели только метод из расширения, ей будет трудно разобраться, что именно изменили. Нужен оригинальный метод из основной конфигурации: тогда модель сможет сопоставить его с расширением и понять, что мы хотели доработать.
Здесь есть еще один практический момент: современные модели пока не очень хорошо знают механизм расширений 1С. Поэтому в промпте лучше явно описывать, что делают аннотации, директивы вставки и удаления, что такое «продолжить вызов». Без этого модель может путаться.
В итоге для разных видов изменений нужны немного разные универсальные промпты: один для добавленных объектов, другой для правок типовых объектов, третий для расширений.
Этап 2. Анализ и классификация
После документирования у нас появляется куча карточек. Казалось бы, можно отдавать пользователю: пусть смотрит.
Но рано.
Пока это снова свалка. Была свалка файлов, стала свалка карточек. Да, уже лучше, но работать с этим все еще неудобно.
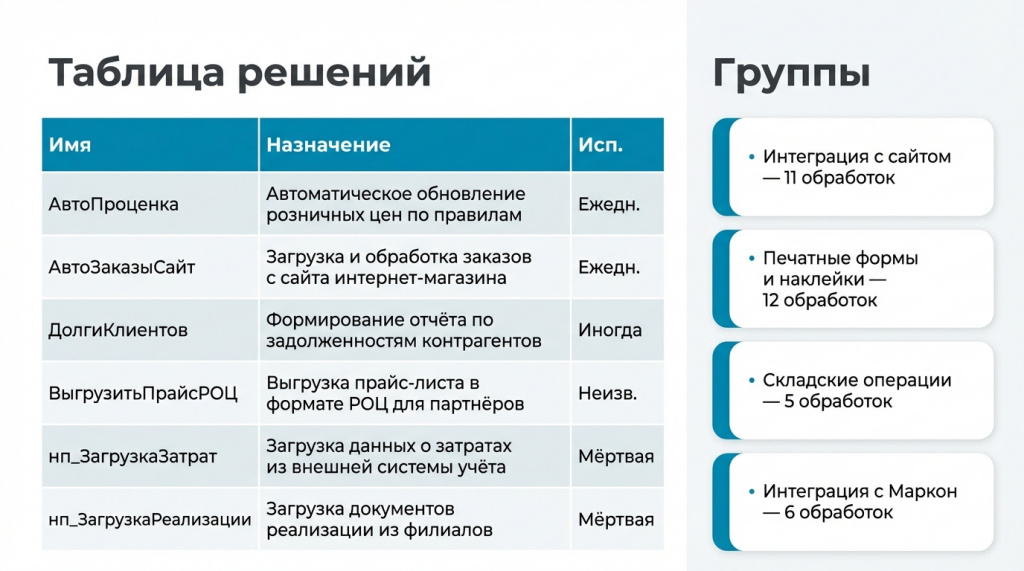
Следующий шаг — передать карточки модели и попросить сгруппировать функционал. Например: эти обработки относятся к обмену с сайтом, эти — к складским операциям, и так далее.
На этом же этапе модель может искать дубли. Такое в проектах встречается регулярно: существующую обработку выгрузили, доработали, но старую версию удалять не стали. Переименовали, подключили рядом «на всякий случай», чтобы при проблемах пользователь мог вернуться к старой. Со временем про это забывают, и в базе копится мусор.
Еще один признак актуальности — частота использования. Здесь агент может посмотреть журнал регистрации и оценить, запускалась ли обработка вообще и как часто.
После анализа и классификации пользователь получает не набор непонятных изменений, а понятную картину:
-
какие функциональные блоки дорабатывались;
-
какие объекты относятся к каждому блоку;
-
где возможны дубли;
-
чем давно никто не пользовался.
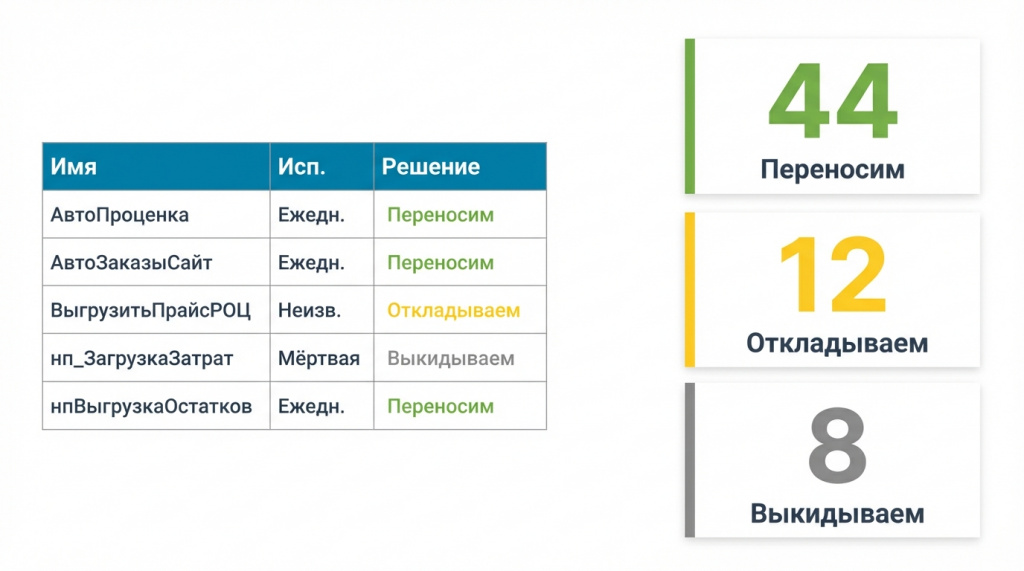
Дальше уже можно принимать решения: эти объекты переносим, эти откладываем — если кто-то спохватится, вернемся и обновим, а эти выбрасываем, потому что ими точно уже никто не пользуется.
После этого можно попросить модель разложить объекты по папкам. Так появляется структурированный план миграции, по которому можно работать дальше.
Этап 3. Ищем, что сломается после обновления
Документирование сделали, план миграции собрали. Теперь нужно понять, что из этого заработает в новой конфигурации, а где нас ждут проблемы.
Здесь важно перейти от старой конфигурации к новой. Документирование выполнялось по старой конфигурации. Поиск проблем нужно делать уже по новой: выгрузить черновым образом обновленную конфигурацию, перенести туда собранные материалы и подготовить рабочее пространство для задачи обновления.

Что проверяем:
-
Обращения к метаданным. Есть ли нужные объекты и реквизиты в новой базе.
-
Вызовы методов. Существует ли вызываемый метод, не изменилась ли его сигнатура.
-
Запросы. Разбираются ли они в новой конфигурации, не ссылаются ли на удаленные поля и таблицы.
Поиск метаданных, реквизитов и валидацию запросов удобно делать через MCP-сервер. Анализ кода и поиск методов обычно выполняют штатные инструменты кодового агента: он ищет по XML-выгрузке и BSL-файлам.
Отдельная история — макеты СКД. Это большие XML-файлы, и модели тяжело разбирать их без дополнительной подготовки. Поэтому иногда лучше заранее вытащить из них запросы в отдельные файлы и проверять уже их.
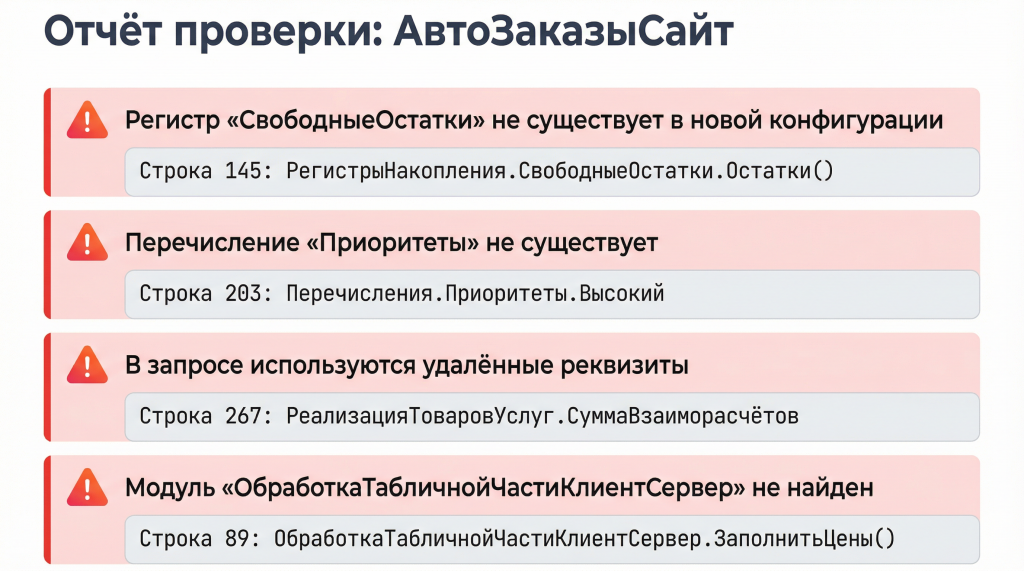
На выходе получаем отчеты по каждому объекту. Например: здесь используется регистр, которого больше нет; здесь удаленный реквизит; здесь вызов метода со старой сигнатурой.
Такие отчеты показывают сложность предстоящего обновления: сколько проблем по каждому объекту придется решить.
База знаний
Сразу бросаться исправлять код не стоит. Сначала лучше собрать базу знаний.
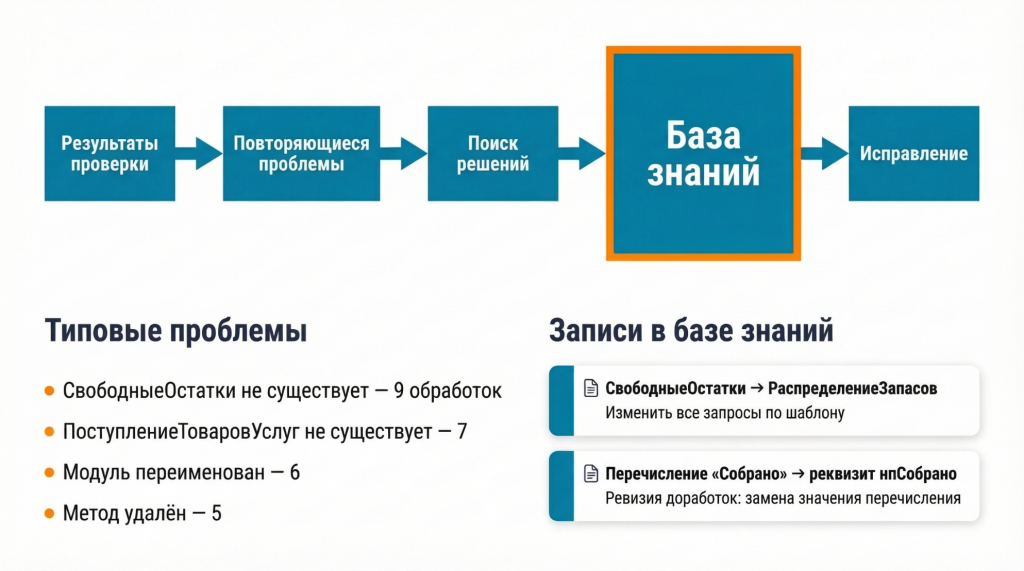
При обновлениях часто повторяются одни и те же проблемы. Если модель каждый раз будет решать их заново, она может каждый раз придумывать другой вариант решения. Поэтому результат будет менее предсказуемым.
Поэтому мы просим агента проанализировать не код, а уже найденные проблемы: сгруппировать их и посмотреть, в скольких объектах какая проблема встречается. Затем модель может поискать в интернете, как такие проблемы миграции обычно решают.
Идея в том, что модель не придумывает решение с нуля. Сначала она пытается найти, как такие проблемы миграции уже решали в похожих случаях, а потом фиксирует предложенный вариант в файле базы знаний.
После этого снова подключается пользователь. Он открывает базу знаний, проверяет, что нашла модель и какие решения она предлагает. Если нужно, вносит правки: что-то уточняет, что-то меняет.
Например, в старой базе в типовое перечисление добавили нетиповой элемент. При обновлении он создает много проблем, и команда решает от него избавиться. Это решение можно записать в базу знаний: если встречаем отсутствие этого значения перечисления, используем вместо него булев реквизит в документе.
Дальше, встречая такую проблему, модель уже знает, что с ней делать и как ее обрабатывать.
Этап 4. Исправление
Когда база знаний готова, можно переходить к исправлению.
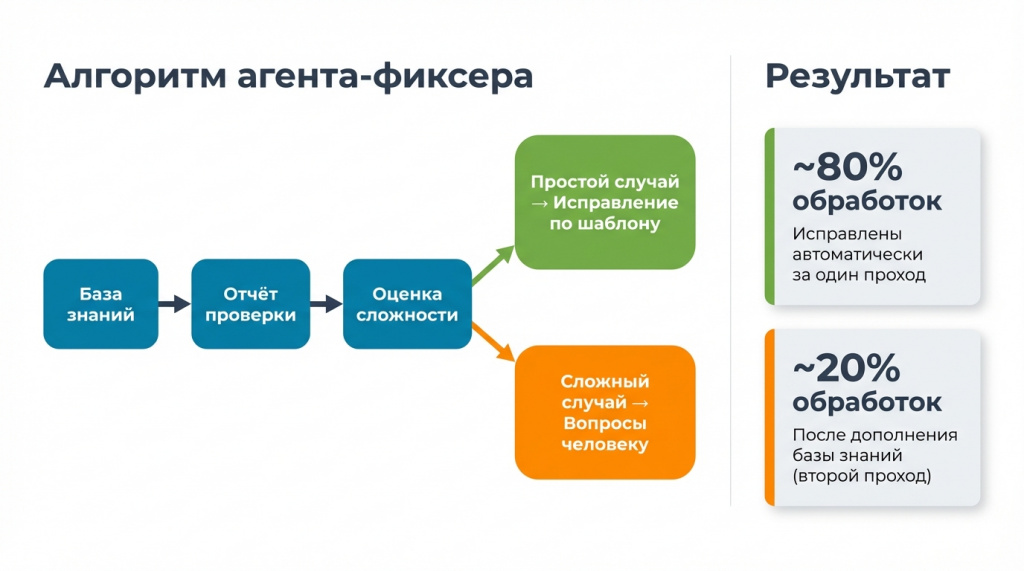
На этом этапе работает агент-фиксер. На вход он получает:
-
объект, который нужно исправить;
-
отчет о найденных проблемах;
-
базу знаний с типовыми решениями.
Агент анализирует проблемы и решает, может ли исправить их самостоятельно: есть ли в базе знаний вся необходимая информация или можно ли решить совсем тривиальные случаи.
Если проблема нетривиальная, правило простое: ничего не выдумывать. Агент фиксирует вопрос для пользователя и откладывает объект.
В нашем проекте около 80% доработок обновились автоматически. Там все было достаточно просто. Оставшиеся 20% остановились на вопросах к пользователю.
Дальше процесс итерационный. Пользователь отвечает на вопросы прямо в файле и запускает фиксер снова. По полученной информации агент еще раз пытается внести исправления, а если нужно — формулирует дополнительные вопросы. Так проблема закрывается.
Этап 5. Тестирование
Объекты исправлены. Теперь нужно проверить, что они действительно работают.
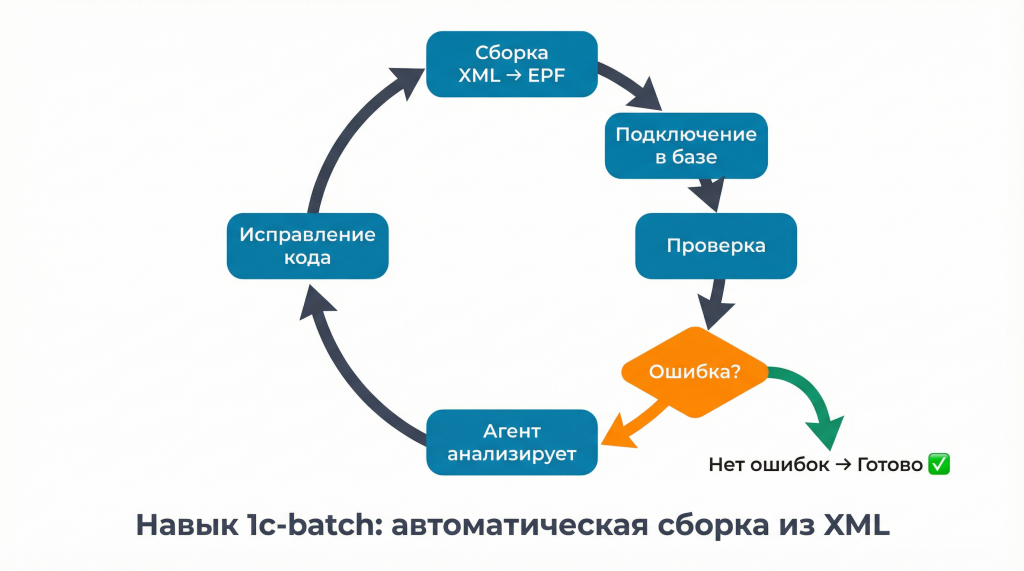
Кодовый агент собирает каждый объект из XML обратно в бинарный формат, например в EPF. Для этого можно использовать отдельный навык. Потом объект подключается к 1С, запускается и проверяется.
Если ошибок нет, агент отмечает работу с объектом как завершенную.
Если ошибка есть, пользователь пишет агенту: «При таком-то сценарии возникла проблема, надо поправить». Сообщение об ошибке и другие данные агент может не запрашивать у пользователя, а забрать из журнала регистрации.
Дальше цикл повторяется: агент исправляет код, пересобирает обработку, пользователь проверяет результат и дает обратную связь.
Что получилось в итоге
На старте был хаос: база с непонятными доработками, без нормальной документации и без ясного понимания, что еще используется.
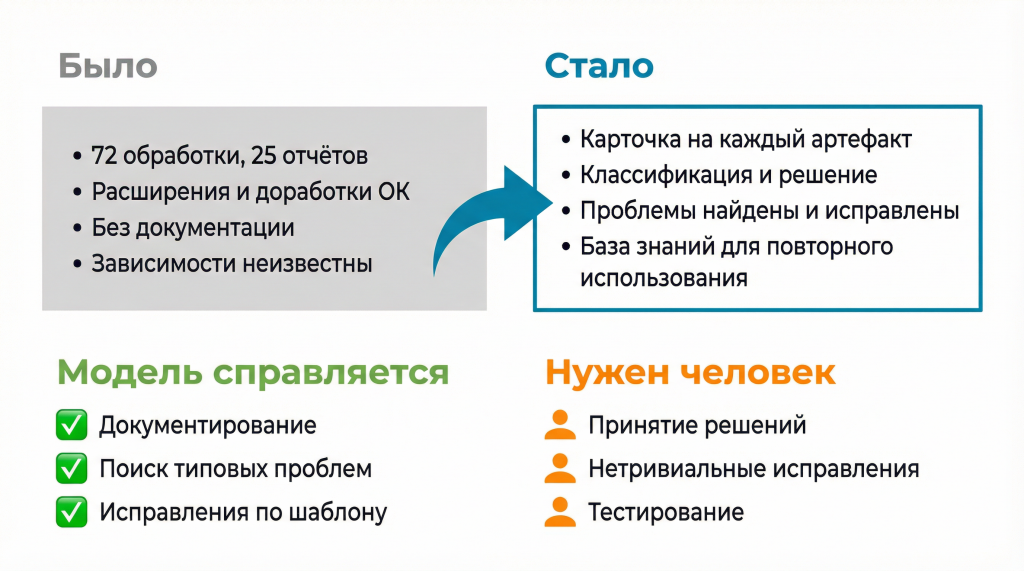
В итоге мы получили полную инвентаризацию этих доработок. Получили исправленный код, который работает в новой базе. И получили положительные отзывы от пользователей: после обновления у них возникло не так много проблем.
Кроме того, у нас появилась база знаний, которую можно переиспользовать на следующих похожих проектах.
Что делает модель, а что остается человеку
Модель выполняет документирование, помогает находить типовые проблемы и вносит шаблонные исправления.
Человек принимает решения на каждом этапе, проводит ревью результатов модели, помогает с нетривиальными проблемами и выполняет тестирование.
Самое важное здесь не в том, что модель пишет код. Этап генерации кода — самый небольшой во всем комплексе работ. Основная польза раньше: модель помогает превратить хаос в набор понятных текстовых артефактов, которые можно проверить и использовать как план работ.
Это сильно отличается от подхода «vibe coding», где мы просим модель что-нибудь сделать и сразу ждем готовый код. В продуктовой разработке такой подход работает плохо.
Поначалу такой процесс может показаться сложным. Но на деле это навык работы с текстом: правильно поставить задачу, получить понятный артефакт, проверить его и перейти к следующему шагу. При подходе «модель сразу генерирует код» с кодом вы провозитесь гораздо дольше.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TEAM EVENT.
Вступайте в нашу телеграмм-группу Инфостарт