
{kind=link}
Введение
Был у меня клиент — небольшая торговая компания, закупают у десяти поставщиков. Каждый присылает прайс в своём Excel. Один — с тремя листами, цены почему-то на третьем. Другой объединяет ячейки в заголовке, отчего колонки "съезжают". Третий примерно раз в квартал добавляет новую колонку, никого не предупреждая.
Открыл я базу, посмотрел, сколько там обработок загрузки накопилось за пару лет. Одиннадцать. На десять поставщиков. Потому что для одного из них обработку переписывали дважды — он сменил формат файла.
Сначала подумал — ну ладно, бывает, ситуация специфическая. Потом посмотрел на пару других проектов у знакомых разработчиков. Та же история. Где-то семь обработок, где-то двенадцать. Похоже, это не исключение, а норма.
Я сам так делал раньше. Прислали файл — сел, написал обработку под него за пару часов, загрузил, забыл. Удобно же. Пока не накопилось одиннадцать таких "удобно".
Проблема, которую обычно недооценивают
Разовая обработка выглядит дешёвой, если смотреть только на момент написания. Два-три часа — и готово. Но это обманчиво простой взгляд.
Реальная стоимость вылезает потом. Поставщик меняет формат — переделывай. Бухгалтер устал ждать программиста и хочет грузить сам — добавляй интерфейс, которого изначально не было. Переходите на другую конфигурацию — а у вас одиннадцать обработок, и каждую нужно протестировать заново, потому что неизвестно, что там сломается.
Я попытался прикинуть цифры по тому проекту с одиннадцатью обработками. Получилось примерно так:
| Этап | Разовая обработка | Универсальный механизм |
|---|---|---|
| Первая разработка | 2–3 часа | 20–40 часов |
| Изменение формата файла | 1–2 часа за раз | 0 часов, настройка |
| Поддержка 10 поставщиков в год | 15–30 часов | 2–4 часа |
| Ввод нового разработчика в курс дела | 5–10 часов | 1–2 часа |
| Переход на другую конфигурацию | 15–20 часов | 3–5 часов |
Цифры приблизительные, у меня нет точной статистики по часам — никто их не считал в моменте, это уже постфактум прикидка. Но порядок величин, думаю, реалистичный для большинства похожих ситуаций.
Какие вообще есть варианты
Разовая специализированная обработка
Под конкретный файл. Знает, с какой строки данные, какой лист, как называются колонки именно у этого поставщика.
Плюсы — пишется быстро, код простой, можно учесть любую дичь в формате файла без особых усилий.
Минусы — не переиспользуется никак, любое изменение формата это правка кода, технический долг растёт незаметно, и в какой-то момент ты обнаруживаешь у себя одиннадцать обработок и не помнишь, что в шестой из них особенного.
Универсальный механизм
Один инструмент под любой Excel или CSV. Пользователь сам настраивает, какая колонка файла куда идёт.
Плюсы — работает с чем угодно без правки кода, можно отдать пользователю, одна кодовая база.
Минусы — дольше делать с нуля, сложнее в реализации, и пользователю всё равно нужно понимать хоть немного, что такое реквизит и справочник, иначе настройка превратится в гадание.
Когда разовая обработка — нормальный выбор
Не буду делать вид, что универсальный механизм нужен всегда. Иногда это просто избыточно.
Если файл загружается один раз при миграции и больше не понадобится — зачем городить универсальность. Если формат настолько специфичный, что универсальный механизм всё равно не справится без доработки напильником — тоже смысла нет. Если сроки горят и думать некогда — да, пишите разовую, это нормально, переживёте потом технический долг.
Чёткой границы тут нет, я для себя определяю так: если файл будет грузиться регулярно — окупится универсальность. Если разово — не парьтесь.
Что происходило, пока я это делал
Первая идея была банальная: читаем файл, показываем таблицу, человек руками тыкает какая колонка куда. Работает. Но для бухгалтера, который грузит прайс от одного и того же поставщика каждую неделю, это превращается в утомительный ритуал — одно и то же сопоставление заново.
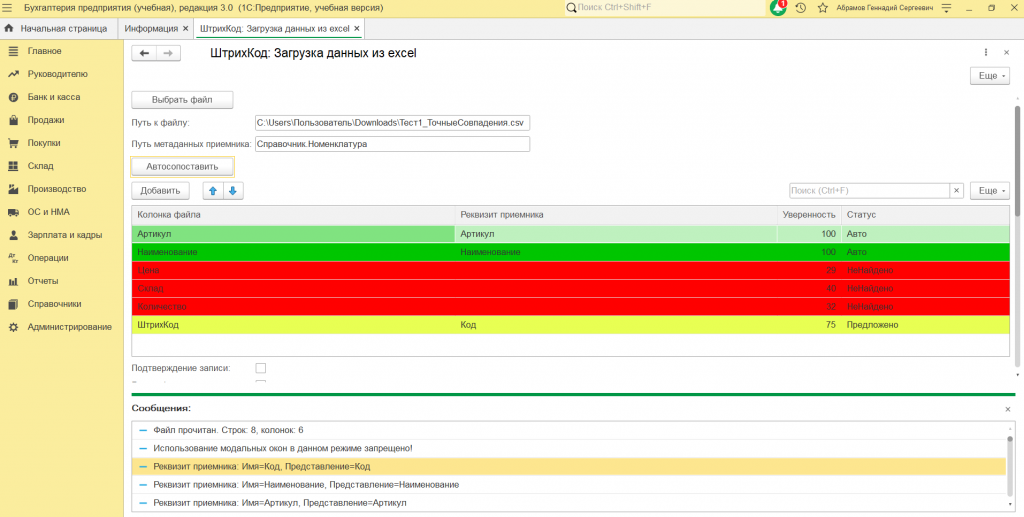
Попробовал автоматику через точное совпадение названий. Колонка "Наименование" в файле, реквизит "Наименование" в 1С — сопоставляем. Сработало процентов на тридцать-сорок, не больше. Потому что в реальности колонки называются как угодно — "Название товара", "Name", "Товар", иногда вообще "Колонка3" без всякого смысла.
Добавил словарь синонимов — список соответствий "как может называться" → "что это в 1С". Процент пополз вверх.
Потом добавил нечёткое сравнение строк, для случаев когда точного совпадения нет, но слова похожи. И тут словил неприятный сюрприз — колонка "ШтрихКод" начала автоматически сопоставляться с реквизитом "Код". Алгоритм увидел общую подстроку "код" и решил что это отличное совпадение. Пришлось городить штраф за разницу в длине строк, чтобы такого не было. Не самое элегантное решение, если честно, но рабочее.
В итоге три уровня сравнения вместе — точное совпадение, словарь, нечёткое сравнение — дали приемлемый результат. Не идеальный, кстати. Пользователь всё равно иногда корректирует руками. Но это секунды, а не пять минут перетыкивания всех колонок заново.
Что я для себя вынес архитектурно
DRY применительно к загрузке данных. Чтение файла, сопоставление полей и запись в 1С — это три разные вещи, и если они слиплись в один кусок кода под конкретный файл, замена любой из них требует переписать всё. Когда разделены — можно менять отдельно.
Механизм загрузки не должен знать, что грузит. Звучит очевидно, но на практике легко скатиться в обратное — начать зашивать в код знание о конкретном файле. Знание о структуре конкретного прайса должно жить отдельно, в виде настройки, а не в коде обработки.
Сохранение шаблонов — это форма памяти о решённой задаче. Человек один раз настроил сопоставление — и это не должно теряться. Иначе каждый понедельник он заново объясняет программе то же самое.
Dry Run — не опциональная фича, а часть архитектуры безопасности. Без режима проверки без записи в базу вы каждый раз играете в рулетку — а вдруг там пустое обязательное поле, а вдруг формат даты не такой. Лучше увидеть это на экране, чем в базе после записи.
Как я сейчас решаю, что выбрать
Себе задаю примерно такие вопросы. Файл будет грузиться больше одного раза? Формат может поменяться? Загружать должен не программист? Похожих файлов несколько, от разных источников? Проект на годы, не на один раз?
Если ответ "да" на большинство — универсальный механизм окупится, можно не сомневаться.
Грубая прикидка стоимости: считаете часы на одну разовую обработку, умножаете на то, сколько раз формат поменяется за год, умножаете на ставку — и сравниваете с тем, сколько стоит сделать один раз универсально. При трёх-пяти регулярно грузящихся файлах универсальный вариант обычно окупается в первый же год. У меня по крайней мере так выходило.
Вместо вывода
Загрузка Excel в 1С — задача, которую обычно решают на бегу, не задумываясь, что будет через год. Я сам так делал, не один раз.
Не скажу, что универсальная загрузка лучше всегда — это было бы нечестно. Бывают ситуации, где разовая обработка правильнее. Но мне кажется, многие недооценивают, во что выливается сопровождение десятка разных обработок, и переоценивают, насколько сложно сделать один универсальный инструмент.
Хорошая архитектура — это не про красивый код. Это про то, чтобы через год не пришлось всё переписывать.
Кстати, про практику
Реализовав этот подход на практике, я собрал его в виде обработки для Infostart. Если тема интересна — вот она: infostart.ru/1c/tools/2715613. Буду рад обратной связи от тех, кто тоже устал плодить сущности.
Вступайте в нашу телеграмм-группу Инфостарт