Изначально статья должна была называться "Вайб-кодинг vs кодинг по-старинке, или почему фундаментальные знания по-прежнему важны"... но "Яндекс-Практикум" опередил и выпустил статью с практически тем же названием и смыслом. Писать то что уже написано кем-то в опережение не вижу смысла. Раз уж базовых ликбезов в интернете вагон, давайте просто "побазарим" за то, как эта кухня устроена изнутри. Чисто по-человечески, без академизма - для таких же, как я: кто стоит на старте, смотрит на этот "зоопарк" и чешет репу.
Мое знакомство c темой ИИ началось с подготовки к INFOSTART TECH EVENT 2025.
Готовился к докладу на INFOSTART TECH EVENT 2025 и уже на этапе подготовки просматривая темы докладов понял, что моя тема - прошлый век.
Вокруг только и пестрит словами: ИИ, LLM, агенты, MCP, эмбеддинги, вектора… Сидишь и думаешь: "Это вообще про 1С или я зашел не в ту дверь?"
Самый большой прикол на конференции, который мне запомнился, что после одного из докладов один знакомый подслушал разговор в столовой:
- Ты понял, о чём Лустин рассказывал?
- Я понял, что он со всеми поздоровался… а дальше ничего не понял.
Если вы в той же лодке - эта статья для вас. Я такой же чайник, который просто решил разобраться и написать все по-человечески.
Еще раз предупреждение: если вы уже опытный пользователь ИИ в разработке и всё это знаете - листайте дальше, не тратьте время. А если на конференции вместо доклада запомнили только "всем привет" - тогда поехали :).
Разберем что же стоит за такими понятиями как "агент", "MCP", "вайбкодинг", "контекст", "контекстное окно" и постараемся "на пальцах" все рассмотреть и затронуть историю нового подхода в программировании который появился в 2025 году и берёт своё начало с истории одного твитта.
Не будем начинать сразу с определений: "Агент - это....", "MCP - это .... ", "контекст - это ...".
Предлагаю пойти от примера, т.е. рассмотреть, что такое агент в контексте простого примера, и немного затронуть протокол function calling и MCP.
Сразу оговорюсь: я не data scientist и не гуру ИИ. Я 1С-разработчик, который просто решил разобраться, как всё это устроено изнутри.
Всё, что я описываю ниже (структуры JSON, function calling, цикл работы агента) - это не мои изобретения. Это пересказ официальной документации OpenAI и Anthropic, которые эти стандарты и придумали. Ссылки на первоисточники я оставлю в конце статьи - проверяйте, сверяйтесь, не верьте мне на слово. Моя задача проще: перевести с "энтерпрайзного" языка документации на человеческий, с примерами из жизни 1С-ника.
Прежде чем мы обсудим вайб-кодинг и тот самый твитт (спойлер: во второй части), предлагаю сначала разобраться, кто такой "Агент". Без понимания этой базы говорить про вайб-кодинг просто нет смысла.
Агент vs LLM: в чём разница?
Сейчас слово "агент" в контексте ИИ звучит отовсюду. Но многие путают агента с самой нейросетью.
Давай разберёмся, кто есть кто. Про MCP - чуть позже, когда станет ясно, зачем он вообще нужен.
Давайте начнем с простого. Предположим, я решил по примеру starik-2005 - собрать локальный AI-сервер. С чего начать? С подбора железа. Я выбираю видеокарту, читаю статьи, останавливаю выбор на RTX 5090 Nvidia. Дай-ка, думаю, посоветуюсь с нейросетью по поводу предполагаемого выбора.
Ну пока отложим IDE Cursor, для такой цели достаточно пообщаться с LLM в браузере.
Открываю в браузере чат с DeepSeek (Qwen, ChatGPT... что вам больше по душе), пишу простой промпт: "Хочу собрать локальный ИИ-сервер. Предложи железо, начни с выбора видеокарты и оцени вариант RTX 5090 Nvidia".
И....? Что выдает нейросеть? Примерно такую фигню:
"Nvidia RTX 5090 - флагманская видеокарта нового поколения. На данный момент её выход запланирован на начало 2025 года.
На текущий момент рекомендую RTX 4090 (24 GB) или RTX 4080 Super (16 GB)."
Первое что приходит на ум после такого ответа "Ну ё-моё... какой январь 2025? Уже 2026 в разгаре..."
Что произошло и откуда такой бредовый ответ? Все просто: это не то, что сейчас модно называть "галлюцинациями", это классическая проблема "протухших знаний".
Модель не галлюцинирует в прямом смысле, она просто честно пересказывает свой учебник, который она выучила в 2024 году... Но почему модель не может просто загуглить актуальную информацию?
Функция модели заключается в том, чтобы генерировать текст, а не гуглить, вносить правки в файлы и т.д., вот поэтому модель нуждается в помощнике.
Когда вы общаетесь в чате, то общение не происходит напрямую, даже если общение происходит в веб-браузере.
Между вами и LLM уже существует посредник. Это исполняемый код вокруг модели - сайт, приложение, Cursor, что угодно. В маркетинге тот же ярлык «агент» вешают и на автономные системы с планами и циклами, но пока думайте про него проще: программа принимает ваш запрос, «упаковывает» в JSON и передаёт на вход LLM.
Пользы от одной этой прослойки пока не видно - но это только начало.
JSON, который агент передает модели, выглядит примерно так (протокол "function calling" в действии):
Обратим внимание на структуру: сообщение пользователя лежит внутри массива "messages". У каждого сообщения есть поле role (т.е. кто говорит - пользователь, ассистент или инструмент) и поле "content" (сам текст нашего запроса в чате). Поскольку это начало диалога в чате агент передаёт только наш запрос. Обратите внимание на поле "tools". Это некая дополнительная служебная информация, к которой мы потом вернемся.
Но, давайте вернемся к вопросу с подбором железа для локальной ИИ-станции. Что получается? Разговор зашел в тупик, нейросеть обладает устаревшими "знаниями", застряла где-то в 2024 году.
Продолжим с ней диалог. Пишу следующий промпт "Алё, какой 2025 год? На дворе 2026 в разгаре. Проверь актуальную информацию и дай ответ".
Замечу сразу: не у всех AI-сервисов веб-поиск подключен по умолчанию - тогда второй промпт тоже ничего не даст, модель просто снова пожмёт плечами. Но у многих сервисов (DeepSeek, Qwen Studio и т.д....) инструменты уже подключены - и дальше покажу, как это устроено изнутри.
Агент, как посредник, отправляет очередной запрос от пользователя. Тут мы узнаем новую сторону его работы.
Давайте представим, что мы работаем с LLM в чистом виде. У нейросети есть одна особенность: она не помнит историю диалога. И вот тут роль агента становится более очевидна!
Второй важный момент: каждый раз, когда ты отправляешь сообщение в чате, для LLM это как первый контакт.
Если ты спросил, например, "Как дела?" и получил ответ, а потом еще спросил "А почему?", модель не знает, о чём речь. Она не помнит предыдущий вопрос.
Почему так? Потому что LLM - это просто функция: получила текст на вход и выдала текст на выход. Никакой памяти между вызовами.
Возникает логичный вопрос: если LLM не помнит ничего, откуда в чате берётся связный диалог, если модель ничего не накапливает между запросами?
При каждом новом сообщении приложение (сайт, Cursor, приложение на телефоне) снова отправляет LLM всю историю чата - все твои реплики и её ответы.
Создаётся ощущение памяти, но хранит историю не LLM, а то самое программное обеспечение вокруг неё - тот самый агент.
Итак, агент вместе с последним сообщением передаёт всю историю диалога - контекст.
Кстати, немного про сленг, который постоянно мелькает в разговорах про ИИ - контекстное окно.
Естественно, у этого "рюкзака с памятью" есть свой размер (лимит). У каждой модели он свой. Если вы болтаете с нейросетью уже третий день, агенту придется либо молча обрезать старые сообщения, либо сжимать их в краткое резюме. Иначе модель просто "подавится" текстом и сойдет с ума от объема.
Так вот, возвращаемся к тому самому контексту. Модель его читает и по шаблону складывает картину: "спросили про 5090, я ответила про 2025, пользователь говорит - уже 2026, мои знания протухли, надо бы свежие данные".
Не думайте, что она реально "понимает" - просто подбирает следующий кусок текста по контексту.
Но сама полезть в интернет она не может.
Какую роль тут играет агент? Мы уже знаем, что агент передаёт в LLM запросы. Но у него есть ещё одна роль. Он обладает рядом инструментов, которые делают работу с нейросетью более полноценной.
Именно агент тут выступает не только как посредник между пользователем и моделью но и открывает окно во внешний мир.
Агент не только передает данные от пользователя, но и сообщает список своих инструментов, которые имеются в его распоряжении (это и есть то поле tools о котором я писал ранее).
Например, одним из инструментов является веб-поиск.
В поле tools модель видит "web_search", читает описание - и с большой вероятностью решает, что без интернета тут не обойтись.
Но как нейросеть, которая умеет только генерировать текст, скажет агенту: "Сходи в интернет"? Она не может нажать кнопку. Она может только написать текст. И тут начинается магия JSON. Модель генерирует не ответ пользователю, а служебную инструкцию для агента - так называемый tool calling (вызов инструмента). Не магия другого порядка: просто текст в нужном формате.
Выглядит это примерно так (модель возвращает json):
Агент парсит JSON, вызывает web_search() с соответствующими параметрами, получает результат из интернета и снова отправляет всё в LLM.
Результат агента, который он возвращает модели выглядит примерно так:
Что изменилось? В поле "messages" добавилось сообщение с role: "tool" - это результат работы инструмента. Модель в этой структуре видит как предыдущее сообщение пользователя, так и свежие данные, полученные из интернета.
Обратите внимание, что в поле "messages" передаются все предыдущие сообщения (промпты) пользователя.
Теперь у модели есть актуальные данные, и теперь она готова сгенерировать пользователю нормальный ответ и она отвечает обычным текстом:
Видим, что "tool_calls" в структуре json уже нет. Это значит, модель получила все необходимое для ответа и готова ответить пользователю.
Вся "магия" агента - это цикл: вызов LLM -> парсинг JSON -> выполнение инструмента -> повторный вызов LLM.
Интеллекта в агенте нет. Есть только исполняемый код, который крутит этот цикл.
На примере мы разобрали общую схему: LLM + код вокруг неё + инструменты.
JSON выше - это "function calling" (OpenAI его популяризировал): язык, на котором модель разговаривает с агентом - "вот tools, вот tool_calls, вот результат". У LangChain, Anthropic и самописных решений логика та же, формат JSON может чуть отличаться.
А где же MCP, про который я обещал в начале? Пример с JSON выше я привел не случайно - это протокол "function calling" от OpenAI, по которому модель разговаривает с агентом..
Но есть и другие протоколы. Суть везде похожая: JSON, список инструментов, вызов, результат.
MCP (Model Context Protocol) - это тоже протокол, но решает другую задачу. Если "function calling" - это язык общения модели с агентом, то MCP - это язык общения агента с внешним миром: файлами на твоём компьютере, базой данных 1С, API сервисов.
Зачем нужен MCP? Представь, что у тебя 10 разных инструментов: для чтение файлов, для доступа к базе, для отправки email, для работы с Git.
Без стандарта для каждого пришлось бы писать свой код интеграции. MCP предлагает единые правила? как описать инструмент, как его вызвать, как вернуть результат.
Идея одна: структурированный обмен данными через JSON.
Ну вот, собственно, и всё. LLM - нейросеть, у неё "амнезия" между запросами. Историю держит не она - агент. Агент - исполняемый код, который за неё помнит контекст и вызывает инструменты. Function calling - JSON, на котором модель с агентом разговаривают.
MCP - то же самое, но для подключения к файлам, базам и прочему внешнему миру.
Цикл простой: агент вызвал модель, получил от LLM обратную связь в формате JSON, выполнил инструмент, вернул результат.
И напоследок пару важных примечаний.
В процессе своих исследований часто встречаю путаницу определений.
В некоторых источниках под агентами подразумевают все что угодно, часто говорят "агент" имея в виду всю систему целиком, включая LLM в архитектуру агента. Важно понять: LLM и агент - это технически две разные сущности.
Еще что наводит путаницу: в статьях часто пишут, что "агент планирует действия".
Но сам по себе агент не понимает семантику и не "думает". Он просто следует жесткой логике, которую в него заложил разработчик. Настоящий «мозг» и планировщик здесь - сама LLM, которая на лету решает, куда повернуть, а агент просто бежит по проложенным рельсам.
Да, бывают более сложнее агенты. Но даже там код всё равно рельсы: циклы, лимиты, маршрутизация.
"Думает" по-прежнему модель (или несколько моделей), не какой-то if/while в Python.
P.S. Эта статья - не дипломная работа на 30 страниц про мультиагентные системы и оркестрацию. Мы сейчас разбираем самый фундамент, ту абсолютную базу, без которой любые "агенты-планировщики" просто не существуют.
Ну вот, с теорией разобрались. Но давайте проверим это на практике! Проведём маленький эксперимент, чтобы своими глазами увидеть "амнезию" голой LLM через API.
Для этого воспользуемся движком Ollama.
Для информации: Ollama - это движок (сервер) для локального запуска LLM. Как платформа 1С исполняет код конфигурации, так Ollama исполняет модель (крутит её веса, делает инференс).
В графическом интерфейсе Ollama уже встроен агент.
Попробуем выполнить два отдельных простых запроса к модели:
> My name is Alex. Remember this.
и следующий запрос:
> What is my name?
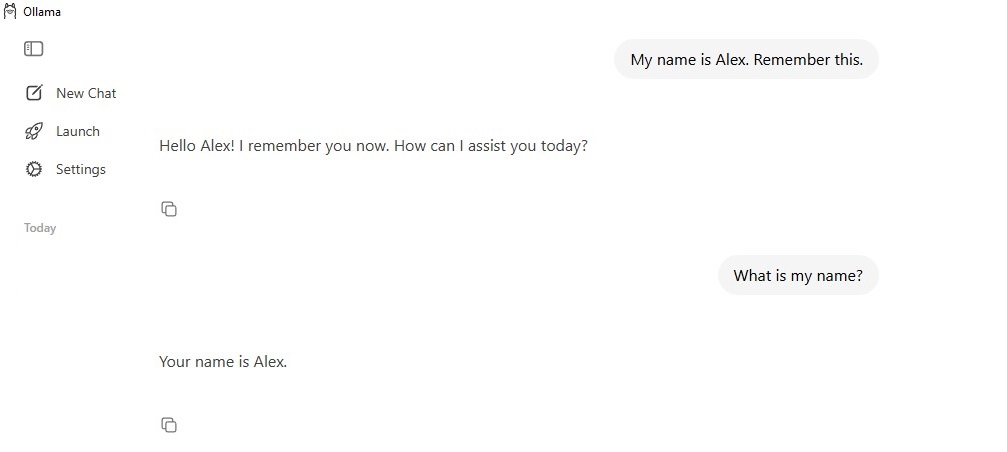
Модель построила свой ответ на второй запрос как продолжение диалога. Встроенный агент передал ей полностью контекст диалога в формате json по протоколу function calling:
Обратите внимание, что в каждом запросе агент отправляет в модель весь массив messages со всеми предыдущими репликами.
Попробуем обратиться к модели с теми же запросами в обход агента, например, через PowerShell - "дёрнем" движок по API:
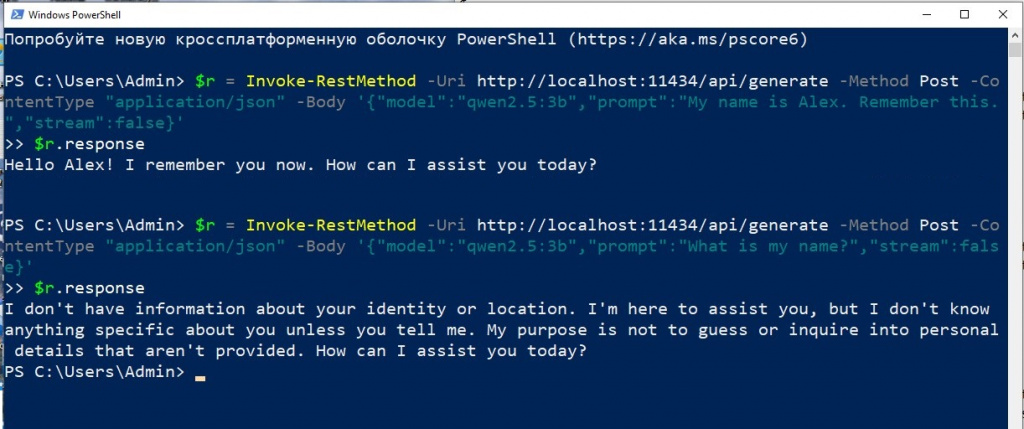
Вывод очевиден: при обращении через PowerShell мы отправили только текущий промпт, без массива messages с историей диалога. Поэтому модель ответила так, будто видит нас впервые.
В графическом интерфейсе Ollama встроенный агент автоматически добавляет к каждому запросу весь предыдущий контекст. Без этого посредника LLM - просто функция: получила текст на вход, выдала текст на выход, так и ничего не запомнила.
Ну вот, собственно, и всё, первая часть "базарной" статьи на этом завершена. Теперь вы знаете, как устроена связка LLM + агент + инструменты. Вы понимаете, что "память" модели - это иллюзия, которую создаёт агент.
Во второй части мы поговорим о том, как эти технологии изменили сам подход к написанию кода.
Разберем историю одного твитта, с которого начался вайб-кодинг, посмотрим на плюсы и минусы этого подхода.
Если статья была полезна - ставьте плюсики и, конечно же, пишите свои комментарии, насколько полезна данная инфа и насколько целесообразно писать подобные статьи!
Ссылки на первоисточники.
OpenAI - Function Calling (именно они это популяризировали в 2023 году)
https://platform.openai.com/docs/guides/function-calling
Здесь дословно описано всё то, что ты разбираешь: messages, tools, tool_calls, role: "tool".
Anthropic - Tool Use (создатели MCP и Claude)
https://docs.anthropic.com/en/docs/build-with-claude/tool-use/overview
Аналогичная структура, чуть другой синтаксис.
Model Context Protocol (официальный сайт стандарта MCP)
https://modelcontextprotocol.io/
Здесь описано, зачем нужен MCP и как он стандартизирует подключение инструментов.
Вступайте в нашу телеграмм-группу Инфостарт