Зачем говорить о юнит-тестировании в 1С
Эта тема в первую очередь близка разработчикам – тем, кто постоянно пишет код. При этом юнит-тесты на регулярной основе пишут далеко не все. Речь пойдет именно о юнит-тестировании в 1С.
Статья техническая, но большого внутреннего технического «жирка» здесь не будет. Я расскажу о теории юнит-тестирования и о том, как его правильно применять, а не про конкретные инструменты. Тем не менее все примеры будут построены в рамках фреймворка YAxUnit. Это, наверное, сейчас лучший фреймворк, который есть на рынке 1С для юнит-тестирования.
Вся статья основана на личном опыте. Опыт у меня большой: уже лет пять-семь я покрываю весь свой код тестами. Но начать нужно, конечно, с теории, чтобы освежить память: что вообще такое юнит-тестирование.
Теория
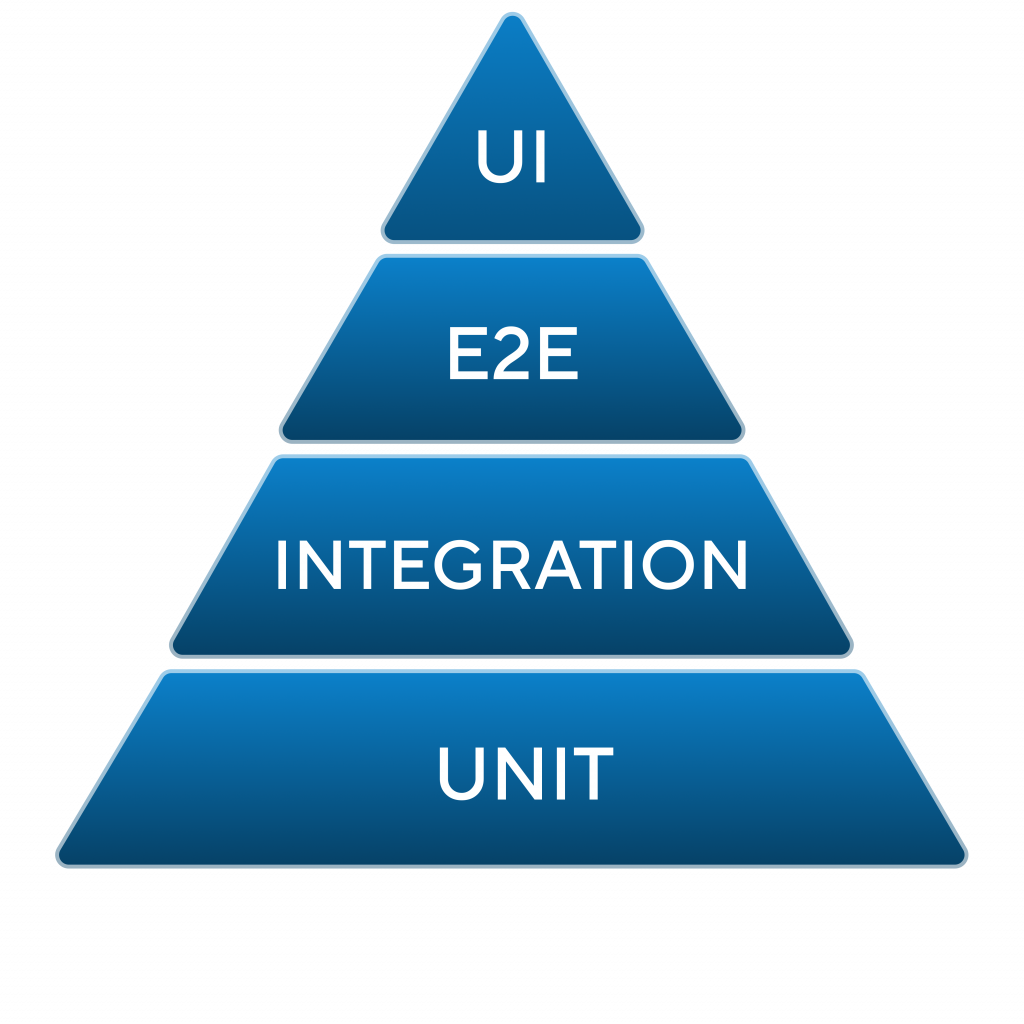
Если мы посмотрим на классическую пирамиду тестирования, как во всех учебниках, у нас есть нижний уровень – юнит-тесты, дальше интеграционные, end-to-end и UI-тесты. Эта пирамида встречается в разных ипостасях: слоев может быть больше или меньше, но основное, что нам нужно понимать, – чем выше уровень в пирамиде, тем тестов становится меньше, каждый тест становится дороже, его поддержка становится дороже, и цена ошибки в таком случае становится выше.
На нижнем уровне у нас идут юнит-тесты и интеграционные тесты.
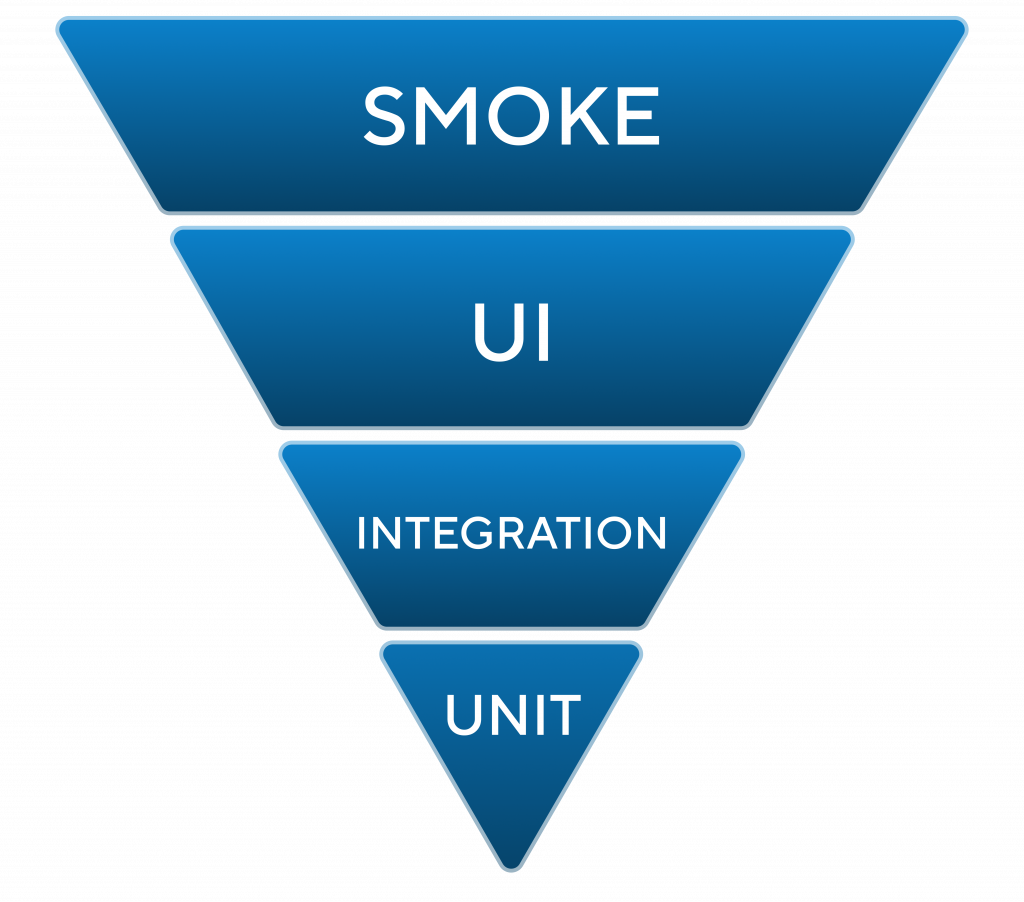
Давайте посмотрим, как эта пирамида выглядит в 1С. А выглядит она немного наоборот. На нижнем уровне у нас юнит-тесты – самый маленький слой, на верхнем – дымовые тесты. Дымовые тесты в разработке самые дешевые: написать небольшой скрипт, небольшой конфиг – и все, у нас 10 000 тестов сделано, которые открывают формы. Тем не менее они не показывают никакой реальности. Они показывают, что платформа открывает формы, и все.
Дальше идут UI-тесты, написанные, например, на Vanessa Automation. Зачастую это как раз самые важные кейсы, которые необходимы компании. В принципе, этот слой находится на том уровне, где и должен быть.
А вот интеграционные и юнит-тесты – это самый маленький слой, практически диковина. В крупных бигтех-компаниях, конечно, юнит-тесты есть, но в большинстве случаев этот слой отсутствует либо он микромаленький.
Почему пирамида выглядит именно так? Коротко можно сказать: так исторически сложилось. Но можно немного разобрать, почему происходит именно таким образом.
В первую очередь у нас нет поддержки от вендора. Нет поддержки в плане инструментов. Компания «1С» уже давно говорит, что выпустит инструмент для сбора покрытия юнит-тестами, но какого-то инструмента для запуска юнит-тестов нет.
Помимо технической поддержки, у нас нет информационной поддержки. Вендор не пропагандирует написание юнит-тестов и покрытие кода юнит-тестами. Сообщество, конечно, этим занимается: разрабатывает инструменты, выступает на конференциях, пропагандирует. Но на самом деле этого недостаточно. Нужно более сильное влияние, чтобы повлиять на огромные массы людей.
И сама платформа диктует архитектуру, которая идеологически не очень совместима с юнит-тестированием. Но с этим можно работать.
Интеграционные и юнит-тесты
Еще немного теории про интеграционные и юнит-тесты. Нас как раз в пирамиде интересуют эти два слоя.
Юнит-тест – это тест, который проверяет конкретное поведение конкретного метода в изоляции. То есть без обращения к базе данных, без обращения к окружению. Максимальная изоляция от всего. Если что-то нужно извне, мы это либо отрезаем какими-то способами, либо мокируем. Это очень быстро и очень дешево.
Интеграционные тесты – это анализ поведения нескольких методов, компонентов в связке. Здесь мы уже работаем с реальной базой данных, с реальными зависимостями, с реальным окружением и так далее. Это чуть медленнее, чем юнит-тесты, но тем не менее все ближе к реальности и более правдиво показывает состояние вашего программного обеспечения.
Если посмотреть на это в рамках 1С, мы сталкиваемся с тем, что в 1С нет изоляции. Мы не можем отделить базу данных как таковую – это часть платформы. Мы не можем отделить бизнес-логику от метаданных. Есть люди, которые пишут чистые функции, но в большинстве случаев чистые функции не связаны с бизнес-логикой как таковой, потому что это какие-то элементарные простые вещи. Нельзя сделать чистую функцию, которая делает проводку документа или чтение данных из базы данных. Это не подходит под архитектуру.
Тем не менее с этим можно жить и с этим нужно жить, потому что такие у нас реалии платформы.
Важный момент. Юнит-тесты и интеграционные тесты – это разные типы тестирования. Но если посмотреть в контексте 1С, то тех вещей, которые должны быть в юнит-тестировании, платформа не позволяет создать. Поэтому в рамках статьи я буду произносить термин «юнит-тесты», но в большинстве случаев подразумеваю либо юнит-тесты, либо интеграционные тесты, либо их смесь, которая у нас есть в реалиях 1С.
Практика
От теории перейдем к практике.

Предположим, что вы решили внедрить юнит-тесты, начать их писать и ожидаете, что ошибок в коде больше не будет. По факту получается, что ошибки есть и в коде, и в тестах. Это, конечно, шутка, преувеличение и сделано больше для того, чтобы вставить мой любимый мем.
Но тем не менее в любом инструменте всегда есть и плюсы, и минусы. Есть места, где стоит применять этот инструмент, а где не стоит. Как говорится, не стоит забивать гвозди микроскопом. Поэтому давайте разберемся, где стоит применять юнит-тестирование в 1С, а где не стоит.
В чем блеск юнит-тестирования? Нужно писать код по-другому. Когда мы применяем юнит-тесты, код становится чище, читабельнее, понятнее.
Также юнит-тесты избавляют нас от глубокой ручной проверки логики, которая зашита где-то глубоко в общих модулях. Мы можем проверять только эту логику, а не всю систему в целом.
Причем многие из вас на самом деле очень часто пишут юнит-тесты, просто не подразумевают этого. Например, какая-то маленькая внешняя обработка, которая вызывает какой-то метод, и вы в отладке смотрите, что он действительно возвращает то, что нужно. Это по сути юнит-тест, только не автоматизированный.
Спорный момент, с которым многие из вас, наверное, не согласятся: юнит-тестирование ускоряет разработку. Казалось бы, нам нужно написать код, а еще написать код, который проверяет этот код. Кажется, что кода надо написать в два раза больше. Но в разработке больше времени тратится не на написание кода, а на проверку и архитектурные моменты.
Поэтому, сокращая саму проверку, перекладывая ее на более дешевый способ тестирования – автоматизированный, – мы ускоряем разработку.
Конечно, поначалу, когда вы только начнете применять юнит-тестирование, вы будете тратить плюс 100%, плюс 200% к написанию кода и вообще к выполнению задачи. Но со временем, когда освоите тот или иной инструмент, это все сократится, и разработка действительно будет идти быстрее.
Это быстрый и дешевый способ проверки всей логики вашей системы. Для примера: у меня есть библиотека, в которой больше тысячи юнит-тестов, и все это прогоняется примерно за 2,5 минуты. Я могу прогонять эту логику на каждый pull request, а не только перед релизом, как дымовые тесты. Потому что дымовые тесты на крупных проектах обычно прогоняются 2–3–4 часа. При этом реальной пользы они, на самом деле, приносят не очень много.
Где стоит применять юнит-тестирование
Юнит-тестирование стоит применять, как я уже говорил, в библиотеке. Если вы делаете какую-то внутреннюю библиотеку, обязательно покройте ее юнит-тестами. Туда они идеально подходят.
Любые интеграции с внешними системами тоже прекрасно покрываются юнит-тестами. А сама внешняя система обычно подменяется каким-то моком, и не нужно разворачивать полное окружение.
Весь программный интерфейс, который вы предоставляете, тоже прекрасно покрывается юнит-тестами. В том числе юнит-тест здесь может выступать дополнительной документацией. Когда разработчик не понимает, что делает этот метод, он может посмотреть юнит-тест и понять логику его работы.
Различные универсальные методы, хелперы, методы общего назначения – все это тоже прекрасно покрывается юнит-тестами. Это идеальные кандидаты для покрытия.
Регламентные задания тоже можно покрывать, но только при одном условии: если регламентное задание довольно атомарное. Если ваше регламентное задание за пять часов перелопачивает половину базы, понятное дело, такое лучше не трогать.
Вообще практически любая серверная логика так или иначе может быть покрыта юнит-тестами.
Дополнительным пунктом я добавил инцидент-менеджмент. Если в компании вы применяете инцидент-менеджмент, то есть если у вас произошел какой-то сбой, какой-то баг, и это оказалось на проде, вы заводите инцидент, дальше идет расследование, post-mortem. В конце должен остаться какой-то артефакт по итогам разбора этого инцидента и его исправления. Здесь юнит-тест идеально подходит. Мы покрыли эту ошибку тестом и точно уверены, что она больше не повторится. Другие ошибки возможны, но конкретно этой не будет.
Нищета юнит-тестирования
Плюсов много, применять юнит-тесты можно во многих местах. Но давайте поговорим о минусах.
Первый пункт точно такой же: нужно писать код «по-другому». Далеко не все разработчики готовы менять свой стиль кода. Все привыкли писать огромные функции. С этим много борется сообщество, с этим борются различные линтеры, стандарты и так далее. Тем не менее такое все еще применяется.
Поменять правила разработки в компании очень сложно. Но без изменения техники написания кода нам будет тяжело покрыть этот код тестами. Юнит-тесты всегда очень связаны с чистым кодом.
Тесты также нужно поддерживать в актуальном состоянии. Если у вас где-то тест упал, его нужно проверить, посмотреть. Возможно, тест упал не потому, что вы сломали код, а потому что изменилась логика работы, и правильно, так и должно быть. Тогда тест нужно поправить. За этим нужно постоянно следить.
Еще один минус – избыточное мокирование, создание изоляции для метода, чтобы максимально отвязать какую-то зависимость в методе. Это очень круто, но зачастую создает много проблем и артефактов, о которых я чуть позже расскажу.
Где не стоит применять юнит-тесты
Не стоит покрывать тестами типовые механизмы. Просто смиритесь: они работают, за вас их уже протестировали.
Также не стоит покрывать тестами легаси код, если вы не собираетесь его перелопачивать, делать рефакторинг. Не трогайте, забетонируйте, оставьте. Если собираетесь – тогда это отдельная история.
Если ваш функционал активно развивается, если вы переписываете какой-то общий модуль или подсистему несколько раз за неделю, тоже не трогайте, не покрывайте пока тестами. Стабилизируйте функционал, потом покройте тестами. Иначе вы будете тратить очень много времени на переписывание тестов.
Отчеты, права доступа, функциональные опции и прочие такие штуки – вообще не лезьте, пусть они живут своей жизнью. Это не связано с юнит-тестированием.
Если вы занимаетесь программной доработкой форм, в принципе, можно покрыть это юнит-тестами. Но лучше не стоит. Возьмите Vanessa Automation и проверьте, как это действительно работает на форме, а не кодом. Потому что кодом может быть все хорошо, а на форме ничего нет.
Приватные методы, если очень хочется, конечно, можно найти способы сделать приватный метод публичным и покрыть его юнит-тестом. Но это очень глупая вещь. Приватный метод на то и приватный: он может меняться сколько угодно. Тестируйте уровнем выше.
Типичные ошибки и антипаттерны
Перейдем к типичным ошибкам, которые совершают многие. И, будем честны, я сам половину из этих ошибок совершал при написании юнит-тестов.
Первая ошибка – тестирование платформы, а не бизнес-логики. Логика в платформе такая, какая есть. Она описана в Syntax-помощнике. Может быть, где-то она ему не соответствует, но тем не менее не надо проверять, что метод платформы действительно работает именно так, а не иначе. Просто смиритесь: он такой и есть.
В тестах нельзя использовать другие методы конфигурации, кроме того, который вы тестируете. Если у вас есть метод, который записывает данные в регистр, а вы тестируете метод, который читает из этого регистра, не надо создавать тестовые данные первым методом. Изолируйтесь. Иначе у вас будет зависимость одного метода от другого, одного теста от другого. Когда что-то сломается, вы не поймете, где на самом деле проблема.
Также не нужно, чтобы тесты зависели друг от друга, от данных в базе данных, которые уже есть или которых нет, от какого-то окружения. Максимально изолируйтесь. Всегда создавайте тестовые данные под конкретный тест и используйте только их.
Отсутствие негативных кейсов.
В тестах не должно быть сложной логики. Если в тестах у вас есть какое-то условие if – это уже звоночек, что что-то вы делаете не так. Такого быть не должно. Нужен простой линейный код: создали тестовые данные, вызвали тестовый метод, проверили результат. Никаких условий. Иначе вы усложняете. Один кейс – один тест.
И еще одна ошибка – избыточное мокирование, о котором я уже говорил. Чуть позже приведу примеры.
Пример №1. Работа с тестовыми данными
Чтобы это было понятнее, немного посмотрим на код.

Первый пример – простейший код: запись в регистр и чтение из регистра. Ничего сложного. Давайте попробуем его протестировать.

Тест может выглядеть следующим образом. Вроде все нормально, все хорошо. Но давайте посмотрим повнимательнее, что здесь плохого.
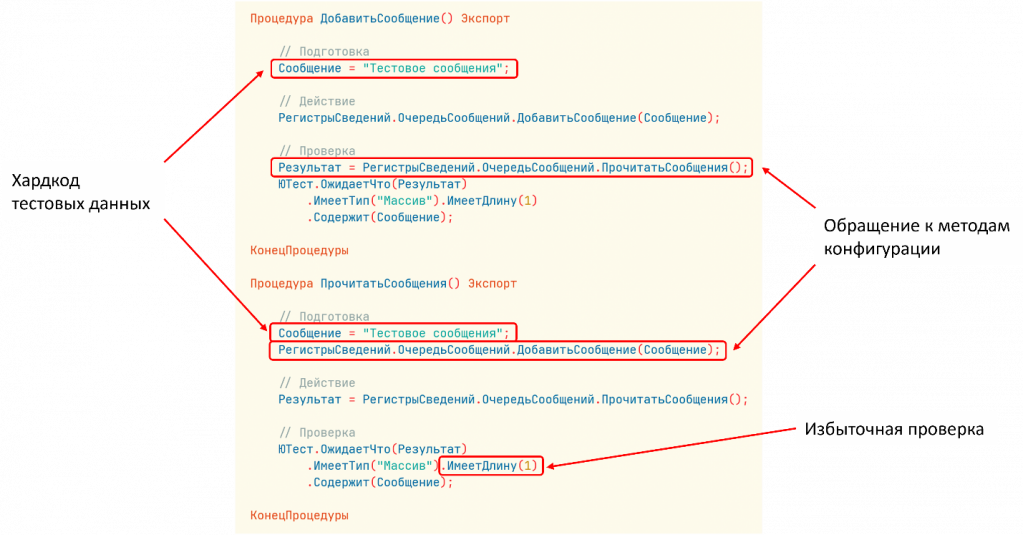
Во-первых, у нас есть хардкод тестовых данных. А что, если эти тестовые данные уже есть в базе данных? Тогда как это будет выглядеть? Конкретно наш метод – ничего, но другой метод может быть сломан. Поэтому нужно всегда генерировать тестовые данные под каждый тест.
Дальше – обращение к методам. Как раз то, о чем я говорил: чтение, запись. Два теста зависят друг от друга, и два метода зависят друг от друга.
Помимо этого, здесь есть избыточная проверка. Мы ожидаем, что у нас есть данные, которые получим: массив из одного элемента, который мы записали. Но в базе данных данные уже могут быть, следовательно, там будет больше данных. Поэтому такая избыточность добавляет тестам хрупкость.

Можно переписать тест следующим образом. Мы генерируем случайные данные под каждый тест. Записываем напрямую в базу данных и читаем из базы данных. В данном случае я использую фреймворк, но можно просто напрямую сделать запись в регистр и прочитать запросом. Инструмент здесь не так важен.
Так тест становится более надежным.
Пример №2. Мокирование
Второй пример связан с мокированием.
На прошлом примере у нас был служебный программный интерфейс в модуле менеджера регистра. Давайте вытащим его в программный интерфейс, в общий модуль, чтобы отвязаться от какой-то имплементации.

Мы сделаем такие методы: в одном просто добавим проверку на пустое сообщение, а в другом просто пробросим этот метод. Все замечательно, вот такой у нас программный интерфейс.

Покрываем его тестами. Кажется, что все хорошо: сторонние методы, которые у нас уже протестированы, мы замокировали. Но мы же их логику уже проверили. Зачем проверять один и тот же код два раза?

На самом деле в этом есть ошибка. Это и есть избыточное мокирование. Если поведение внутреннего метода изменится, а это внутренний метод – хоть он не приватный, но все-таки внутренний, – тест будет зеленым. Потому что мы проверяем только моковые данные.
Помимо этого, в этом тесте у нас нет отрицательного кейса.

Можно все немного переписать. Мы переносим логику нашего тестирования: здесь записываем и читаем данные. Избавляемся от мокирования, по сути поднимаемся на уровень выше тестирования. И предыдущие тесты из первого примера можно удалить. У нас не будет избыточного тестирования.
Также мы добавляем негативный кейс. Если у нас есть ветка с проверкой, в тесте мы тоже должны проверить, что исключение действительно выбрасывается.
Пример №3. Зависимости и чистый код
Третий пример – про зависимости и чистоту кода. Как это связано?

Предположим, у нас есть метод «ОстаткиОсновногоСклада». Есть предопределенный элемент «ОсновнойСклад», мы его получаем и получаем остатки. Ничего сложного, какая-то базовая штука.

Что плохого в этом коде? У нас есть зависимость. Мы зависим от этого предопределенного элемента. И если в базе есть данные по этому предопределенному элементу, мы всегда будем их получать. Очищать их мы тоже не всегда можем. Да и зачем это делать? Нам нужно эту зависимость развязать.
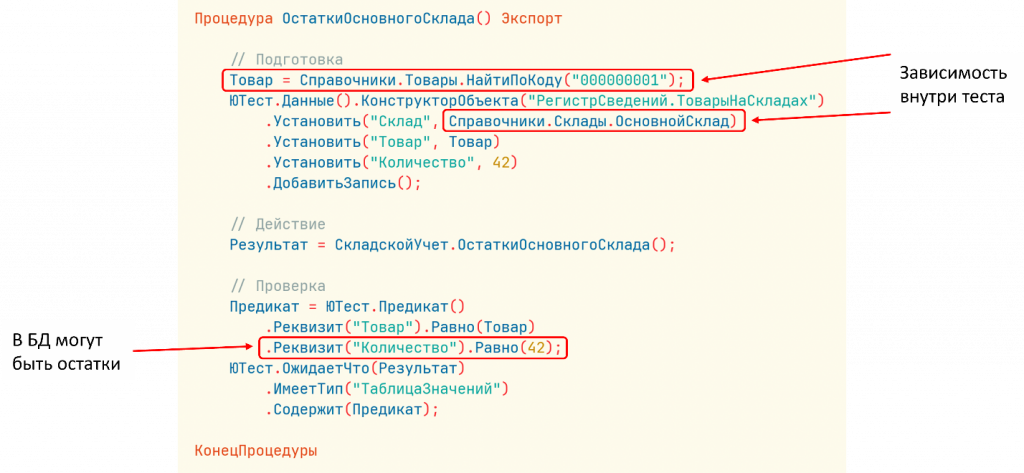
Тест, построенный на таком плохом коде, будет выглядеть не очень. Я дополнительно добавил еще зависимость: просто по коду найдем какой-то товар. Мы знаем, что в базе есть товар с таким кодом. Но плохо привязываться к тем данным, которые есть. Мы не можем гарантировать, что они там действительно есть. Либо, если мы их создаем, вдруг что-то поменяется, вдруг какой-то другой тест их удалит или еще что-то. Это создает дополнительную хрупкость и зависимость тестов.
Помимо этого, мы считаем, что количество равно такому-то значению. А если на этом складе уже есть такой товар? Это создает проблему. Тест упал, хотя, казалось бы, все работает нормально. Код работает правильно, просто тест работает неправильно.

Давайте все перепишем. Я сохранил сигнатуру программного интерфейса, но вынес нашу зависимость. То есть мы декомпозируем бизнес-логику на два метода и выносим зависимость в отдельный метод. Конечно, эти методы можно также сделать экспортными и как-то переиспользовать дополнительно, но для нашего примера достаточно такого подхода.
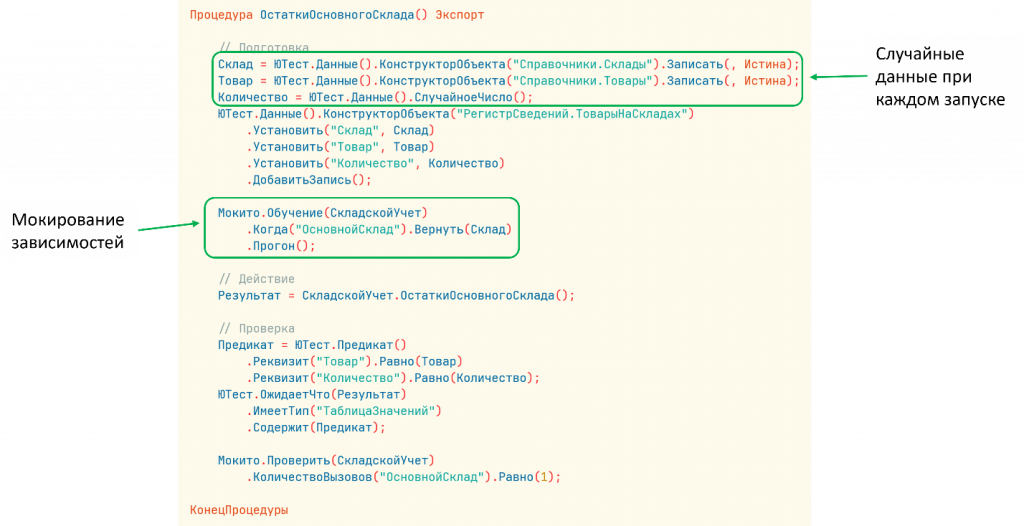
Тогда тест будет следующим. Мы создаем отдельный склад, создаем отдельный товар. Мокируем зависимость именно того простого метода, который возвращает нам один предопределенный элемент, и он возвращает нужный нам склад. Мы заполняем нужные данные, генерируем случайные данные так, как положено, и все это проверяем.
Хорошие практики
Немного о хороших практиках.
Стандартизируйте именование тестов, тестовых наборов, общих модулей. На сайте YAxUnit в документации есть хорошие примеры, как это можно делать. Вы можете использовать те примеры, которые предлагает YAxUnit, можете придумать свои внутри компании. Главное, чтобы это было одинаково внутри вашей компании, чтобы разработчики не думали о том, как правильно называть имена.
Группируйте тесты по тестовым наборам, по тегам и по подсистемам. Выносите их в отдельные подсистемы, чтобы можно было отфильтровать ваши тесты и ваш код по одной подсистеме и видеть, к какой подсистеме эти тесты относятся.
Всегда тестируйте на фейковых данных, как я показывал в примерах.
Для фейковых данных создавайте только те данные, которые вам нужны для теста. Если вам нужна просто номенклатура, а ее артикул, наименование и еще миллион обязательных и необязательных реквизитов не нужны, не заполняйте их. Вам они не нужны. Создайте только одну номенклатуру. Если в дальнейшем зависимость развяжется и нужно будет что-то поправить, тест у вас упадет, и вы его поправите.
Удаляйте тестовые данные за собой, чтобы они не копились. В YAxUnit это делается очень просто. В других фреймворках, может быть, нужно делать вручную, может быть, есть какие-то другие механизмы – я не изучал. Но всегда соблюдайте чистоту: в вашей базе после вас должно быть чище.
Не используйте транзакции без необходимости. Если вы дополнительно используете транзакцию в тесте, например, для того чтобы удалить тестовые данные, могут получиться артефакты: в самом тестируемом методе тоже есть транзакция, где-то выбрасывается исключение, и у вас получится, что в данной транзакции уже происходили ошибки. И ничего не сработает.
Прогоняйте тесты рандомно и несколько раз. Рандомно прогонять тесты нужно для того, чтобы выявлять неявную зависимость между теми или иными тестами. Например, один тест создал тестовые данные, а другой пытается их переиспользовать. Когда вы поменяете их местами, эта зависимость выявится, потому что у первого теста не будет тестовых данных.
Несколько раз тесты нужно прогонять для того, чтобы проверять, не создают ли тестовые данные какие-то артефакты, которые влияют на повторный запуск. Иногда первый раз прогоняешь тесты – все нормально, второй раз выполняешь этот же тест – остатки изменились, ты не удалил данные за собой, и тест упал. Или остаются еще какие-то артефакты.
На этом все. Писать юнит-тесты не больно. Пробуйте.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TEAM EVENT.


Вступайте в нашу телеграмм-группу Инфостарт