Меня зовут Александр Кирилюк, я – архитектор проекта ENOTE, который в свое время вытащил нас за уши в облака. Наше облачное решение работает в разных странах.
С 1С я работаю еще с тех махровых годов, когда мы ее называли «клюшкой» или «семеркой». Тогда я еще и подумать не мог, что в мою жизнь придут такие слова как Apache, Linux и прочие ужасы.
О теме доклада
Постараюсь построить доклад следующим образом:
-
Подробно расскажу, как с 1С жить в облаках – что нужно сделать и почему нужно делать именно так.
-
Поделюсь историей наших граблей – она длинная, мы живем в облаках с 2008 года.
-
Поскольку я не являюсь сисадмином, у меня не получится рассказать на уровне bash-скриптов и конкретных действий, как нажимать конкретные кнопки, чтобы получить тот или иной результат, но я дам вам на руки все технологии и, по возможности, версии.
Доклад будет полезен для тех, кто владеет терминологией и может сам понять, о чем речь. Или для тех, кто, как и я, организует такие системы: у кого есть, кому поставить задачу, объяснить, куда копать.
История проекта

Расскажу о том, как мы организовали свой облачный продакшн.
-
В 2008 году, когда был актуален релиз 8.2.9, у нас возникла идея пойти в облака. При этом мы очень быстро поняли, что 1С и Linux – это на словах хорошо, а по факту тихий ужас. По 20-30 падений в день на продакшене – это хороший день.
-
После этого мы стали сотрудничать с «1С». И сейчас очень гордимся, что поучаствовали в том, что появилась платформа 8.3.
-
Сейчас у нас на 8.3 все прекрасно работает – я в конце покажу аптаймы серверов.
-
Но до сих пор у нас присутствует такой анахронизм, как рестарт службы сервера 1С по ночам – исторически так сложилось, что он у нас прописан в cron. Что самое интересное, при рестарте не отпадают пользователи, не прерывается их работа. В этом плане отказоустойчивость у платформы великолепная.
-
Мы используем множество технологий – я подробно о каждой из них расскажу, а вы уже смотрите сами. Возможно, какие-то вещи вам не нужно выстраивать так сложно, как у нас.
-
При этом хочу предостеречь всех, кто создает облака, от обратной ситуации, когда говорят: мы как-нибудь сейчас развернем «на коленке», а потом перестроим. Если на продакшене уже работают клиенты, и их много, работа круглосуточная, как у нас, чем делать что-то сразу плохо – лучше не делать вообще.
Для тех, кто хочет сделать лайт-версию облака – вы можете начать с четырех технологий, которые предоставляет сама фирма «1С». Мы очень жалеем, что в нашем «детстве» таких технологий не было. Они появились сейчас, вы можете использовать их. Люди очень часто путаются в облачных технологиях, поэтому я на слайд специально вынес эти пометки.
-
1С:fresh – это не для технарей, это для ваших руководителей и продажников, чтобы понять, способны ли вы вообще продавать облачные технологии на рынке, приносить клиентов, делать White Label и т.д? Потому что сделать облако – 50% успеха, а уметь продавать облако – 90% успеха. Именно в такой странной пропорции.
-
1С:ГРМ – это когда вы хотите продавать свои нетленки, когда у вас клиенты постоянно что-то переписывают, вам хочется вносить изменения, когда вы хотите всем управлять индивидуально для баз данных, но при этом боитесь сисадминства, боитесь погружаться в Linux и хотите, чтобы у вас в браузере все кнопочками управлялось. Это решение ваше.
-
1С:ОИ (Облачная инфраструктура) – экзотика. Достаточно спорное применение технологии, грубо говоря, дата-центр от 1С. Нужное решение или нет – смотрите сами. Вам выделят достаточно много ресурсов, вы сможете админить эти машины. Но вопрос в том, зачем нам тогда дата-центр 1С.
-
Свой ЦОД – вы строите свой дата-центр, если вы к этому готовы, размещаете машины и работаете там. На больших проектах это может быть интересно с точки зрения рентабельности.
Почему мы выбрали Linux

В «детстве», когда у нас был 8.2, нам казалось, что мы очень сильно сэкономим на том, что перейдем на Linux. Потому что очень дорого работать в облаках на платном софте, где все честно лицензионное – лицензии для Windows, для MS SQL. Если вы помните, у MS SQL еще есть CAL-лицензии, где даже если у вас к SQL подключается одна база 1С, все равно считаются все подключения к серверу. В общем, все крайне дико, дорого и необлачно.
В итоге скажу, что на Linux жить не так уж дешево. Просто развернуть систему на Linux и лицензировать ее – действительно, в разы дешевле, чем на Windows. Но нужны компетенции.
Практически все свое время мы тратим на то, чтобы зарабатывать компетенции в Linux – учитывать новые изменения, настраивать. Это бесконечная работа админов, обязательное наличие в команде эксперта по техплатформе – достаточно много экзотических знаний, которые, самое страшное, не свойственны 1С-никам. Классическим 1С-никам такие технологии ломают голову, поэтому мы в 90% случаев брали на эту технологию новых людей, в первую очередь – «линуксовых» сисадминов.
С точки зрения безопасности – в те годы Linux был гораздо безопаснее Windows. Думаю, все помнят историю с шифровальщиком Petya – клиенты, которые жили на Linux, аплодировали стоя, глядя на своих Windows-коллег.
При этом любой сисадмин знает, что нет плохих операционных систем, есть люди, которые очень криво их готовят. Linux в этом плане гораздо надежнее, но и накосячить там при отсутствии знаний очень легко.
Выбор ЦОД

Немного конкретики. Какие проблемы мы решаем, когда выбираем ЦОД.
-
Есть виртуальные и выделенные сервера. Виртуальные сервера мы как-то попробовали, и с тех пор больше никогда не берем. Это не значит, что они плохие или не работают. Мы сами создаем свою систему виртуализации, и в этом «сами» как раз и лежит ключевое отличие. Потому что системы виртуализации, которые предлагают обычные дата-центры, заточены на решение веб-задач – на то, что вы будете размещать веб-сервисы, сайты и так далее. Балансировщики работают, исходя из параметров, известных только сисадминам дата-центра, и добиться стабильной работы практически невозможно. Вы будете долго все настраивать, смотреть профили баз данных, выводить тонкие настройки, но в какой-то момент все опять неожиданно начнет работать криво, косо. Почему – непонятно. Поэтому только выделенное железо.
-
Если вы используете несколько железных серверов, вам нужна только полноценная локальная сеть. Очень часто дата-центры, особенно финские и немецкие, территориально разнесены. Один может быть в Мюнхене, другой – в Нюрнберге. Они все как один дата-центр, но физически разнесены за 1000 километров с локальной внутренней виртуалкой. Это крайне плохо, и для своего узла вы должны использовать полноценную сеть и контролировать этот момент.
-
Один из моментов, которые обязательно настроить в своих виртуалках – это протокол VRRP для резервирования ip-адресов в Nginx.
Если помните картинку, как устроены облака в 1С – там на первой точке стоит веб-сервер, на ip которого «стучатся» веб-клиенты. Но если по каким-то причинам у вас машинка с веб-сервером падает, упадет весь продакшн – даже при том, что у вас может быть куча центральных серверов, объединенных в отказоустойчивый кластер.
Поэтому у нас на первой точке стоит не Apache, а Nginx, который перераспределяет нагрузку, причем таких Nginx несколько. И идет резервирование ip-адресов так, что если один из них падает, IP-адрес автоматически переназначается на другую машину, которая подхватывает работу. Из-за возможности резервирования первой линии, протокол VRRP – для нас самая лучшая технология. Потому что переключение IP через настройку резолва в hosts – даже при том, что мы используем собственный DNS – это все долго и плохо. А здесь мы можем гасить любую машину ради эксперимента, и пользователи даже не замечают падений – все это делается на ходу. -
Выбирая железо, смотрите, чтобы оно поддерживало виртуализацию на своем уровне. Может оказаться, что Linux-виртуализация системы на конкретной материнке или процессоре не будет работать. Особое внимание при работе с Linux уделяйте драйверам сетевых карт. Сейчас уже, слава Богу, с драйверами в Linux все прекрасно – их легко найти, не так, как раньше. По крайней мере, с теми релизами, про которые я буду говорить, у нас особо проблем нет. Но иногда стандартный пакетный драйвер может приводить к сетевым глюкам – и, хотя для таких проблем есть свои патчи, к таким ухищрениям лучше прибегать как можно реже.
-
Мы используем Software RAID.
Пробовали аппаратный, с ним все хорошо, но если аппаратный RAID разобрался, а дата-центр от тебя за 6 тысяч километров, и ты никак не можешь повлиять на тех людей, которые его обслуживают, – это проблема.
Как обеспечить безопасность на Software RAID? Мы используем SSD-диски, потому что если вы работаете с высоконагруженными решениями на 1С, без SSD особо не поработаешь. Можно работать на SAS, но такие решения, особенно, в аренде, стоят заоблачных денег, и все равно работают медленнее, чем SSD. Естественно, SSD приходится брать Enterprise Edition или Datacenter Edition.
У нас средненагруженные базы до 60 ГБ, до нескольких тысяч документов в день, мы считаем, что это средненагруженные базы – где-то раз в два-три года нам приходится заменять один из винтов в зеркале. Но, самое интересное, что чаще меняются сами машины. В чем прелесть дата-центров: поработав на мощной машине, через два-три года ты за те же деньги можешь взять более производительную машину, провести переезд, и прекрасно работать дальше.
Мы используем ZFS-сжатие, LZ4 на ZFS RAID. Обычно сжатие не дает никакого эффекта, либо дает большие тормоза, поэтому для меня было достаточно удивительным результатом, что база данных ужимается до 4 раз. Это хороший показатель, которого можно достичь для какой-нибудь классической Бухгалтерии или базы, где много описательной менеджерской информации. В 2 раза ужимается практически любая база. При этом, на результаты теста Гилева такое сжатие влияет на уровне 1-2%, не более. -
Естественно, за SSD надо постоянно смотреть. Ведь основная опасность – не срок его жизни, а частота перезаписи, которая может очень сильно отличаться от машине к машине, и от данных, которые на них расположены.
Чтобы мониторить ошибки, используем SmartCTL. При этом нужно понимать, что с точки зрения предсказания срока жизни все программы такого рода часто врут, поэтому любые сроки сразу делите на два. SSD-диски умирают быстро. Мы так несколько раз диск теряли, его данные приходилось с зеркала восстанавливать. Восстановление делается «на горячую» и особо сложности не вызывает, но программы по сроку жизни ошибаются, помните об этом.
Системы виртуализации

Для виртуализации мы используем Proxmox Virtual Environment. Выбирали мы долго, из множества технологий, в том числе использовали LXC-контейнеры.
Proxmox Virtual Environment показал себя, как прекрасная система, которая позволяет установить 1С-сервер с лицензиями, и в случае переезда «на горячую» не потерять лицензии, потому что они привязаны к серийным номерам, объему памяти и другим параметрам железа. Эта технология позволяет жестко разделить ресурсы и зафиксировать их, они не плавающие.
У этой технологии есть кластер виртуализации – мы используем версии v 5.0 и v 6.0. В 6-й версии есть графическая консоль: если что-то случается, вы можете мышкой перетягиваеть виртуальные машины с одного узла кластера на другой. Юзеры работают, машина мигрирует от 15 минут до часа, и никто не замечает, что у них поменялось железо. После этого проблемная машина останавливается, меняются винты, сервера – вносится новая машина или перезапускается старая на резервном хосте и возвращается таким же образом назад.
Были проблемы с багами сетевых карт. Это не значит, что они глючат или не работают. Но если возникают огромные сетевые нагрузки, сетевая карта может молча падать. В логе Linux вы увидите, что у вас упала сетевуха – вы ее перезапустите и поднимите, но в этот момент ваши клиенты будут рапортовать вам на хотлайн о проблемах. Поэтому контролируйте состояние. Для решения проблем с сетевухами есть очень много разных патчей.
Система виртуализации Proxmox Virtual Environment upgrade-несовместима. Нельзя пятый обновить до шестого и все заработает. Обновить можно, только останавливая машину, пересобирая новую и мигрируя на нее и пересобирая хост вообще. Поэтому старайтесь с версиями определяться заранее.
Что внутри этой железяки, на которой мы все это виртуализируем?
-
На хосте стоит 10 Debian (кое-где у нас еще 9 версия работает), Proxmox 5/6 и Zabbix agent, который все это контролирует и мониторит.
-
Сервер 1С стоит на 9/10-м Debian только x64 версии.
Так как мы сдаем в аренду много, много фишек завязано под КОРП функционал, поэтому у нас стоят КОРП-лицензии, но это для организации облака неважно.
Важно, чтобы система была x64. Если нагрузки высокие, куча народу, куча ресурсов используется… Одна база может быть маленькая, но если их много, то х64 – ваше все. Нет смысла экономить на x32, ничего хорошего не получится.
Естественно, стоит Zabbix agent и Apache 2.4. Напомню, что клиенты не подключаются напрямую к Apache – они идут на Nginx, там стоит маппинг и раскидывает их по серверам. Если виртуальная машина переезжает – она переезжает со своим адресом и всеми потрохами. -
Сервер СУБД стоит на 9/10 Debian
PostgreSQL мы пока что используем 9.6 Pro-1C
И используем Zabbix agent.
Почему две машины? Как показала практика, это прекрасная рекомендация – не ставить сервер СУБД и сервер 1С на одну машину. Но первое время, когда мы ставили две железяки, между ними 100-мегабитный шнурок, тест Гилева нам говорил, что мы в легкой форме идиоты. А когда разделение производится в виртуализированной среде, падения по производительности нет.
А что есть хорошего? СУБД и 1С конфликтуют за ресурс. Когда они вместе, у вас то 1С зависнет, то СУБД начинает подтупливать непонятно из-а чего. Но когда ты им четко нарезаешь – вот это твои ядра, твои потоки, твоя память – им легче работать.
Условный средний сервер – 6 ядер, 12 потоков, 64 ГБ ОЗУ – делится пополам между 1С и СУБД. Никто никому не мешает, они не дерутся за ресурсы и работают в разы стабильнее. Когда все по отдельности, мониторить техжурнал и настраивать логи производительности PostgreSQL проще. И мы видим там реальную картину – что происходит на стороне СУБД и что происходит на стороне 1С. Поэтому делить – хорошее решение.
Примеры хостов на 200-500 юзеров

На слайде два примера абсолютно разных машин, которые используются на продакшене: профессиональное серверное железо и условный подстольный ящик.
Вы видите, какой тест-результат.
-
На левой машине в этот момент 326 юзеров в середине дня работают с предельной интенсивностью.
-
На правой машине – 194 юзера.
При этом тест Гилева дает результаты: справа – чуть ниже, чем плохо, а слева – чуть выше, чем удовлетворительно.
В пиковые моменты левая машина без проблем тянет 400-450 пользователей, а правая – 200-250. Поэтому железо может быть любое, но такие машины вполне способны обеспечить продакшн.
С левой стороны, условно, крутится УНФ, в среднем на 15 пользователей на базу. А справа – Бухгалтерия, в среднем на 5 пользователей на базу. При этом и справа и слева – куча баз, которые, имея в среднем по 5 пользователей, суммарно набирают 450 юзеров слева и 200 юзеров справа.
На слайде показано, какие показатели для них будут – средний отчет строится достаточно быстро, без затыков и заморочек.
Выбор релиза ОС и СУБД

Почему мы используем Debian?
-
Как говорят мои админы, Debian – это самый консервативный релиз, потому что в нем от релиза к релизу все примерно одинаково работает.
-
Та же Ubuntu может при обновлении мажорного релиза может неадекватно себя повести, поэтому для графики она интересна – ставится легко и прекрасно, но в продакшене мы перестали её использовать. Отслеживать ее изменения сложно.
-
RedHat – платный.
-
CentOS мы пробовали, но какие-то вещи в логах, журналах из опыта и сравнения для нас тяжелые. Если у Linux что-то сломалось, то там либо починить просто, доли секунды. Либо, если там остановилась служба и при перезапуске сервера не стартует – найти и отследить взаимосвязи, что и где упало, из-за чего не стартует что-то другое, сложно. Это квест для сисадмина, но на продакшене его нужно решать за минуты. Потому что час висящий сервер на продакшене никому радости не доставляет. Моим коллегам проще отслеживать это в Debian, а не в CentOS.
Остальные релизы мы не пробовали или глубоко не знакомились.
В релизе 9.6 PostgreSQL появился контроль целостности базы данных на уровне самой СУБД. Мы за нашу длительную историю работы в облаках и работы с PostgreSQL пару раз столкнулись с тем, что клиентские программисты напрограммировали в клиентской базе какие-то сложные задачи в 1С, и в СУБД под нагрузкой начались проблемы с таблицами – это были неслабые базы в несколько терабайт. Поэтому мы за то, чтобы это включить, чтобы сама СУБД эту проблему решала.
Таких ошибок гораздо меньше, если использовать сервера ECC с контролем четности. На огромных массивах данных и большой нагрузке это дает какую-то пользу.
На старте можно пользоваться обычной 9.6 PostgreSQL.
Меньше 9.6 желательно не использовать – если использовать 8.3, то требуется очень много доработок, которые влияют на производительность. Версия 9.4 могла раз в месяц тихонько полечь. Да, мы простыми шаманскими действиями ее легко поднимали, но это не о радости работы.
В 11 версии у СУБД появилась параллельность запросов на несколько ядер. Но это как раз спорный вопрос при тестировании – очень сильно зависит от способа работы. Если у вас много разных мелких запросов, то это может и не дать пользы, а если один огромный – может дать пользу. Будет ли эта параллельность выполнения запроса? Тут я рекомендую пробовать на тестах, но весь прикол в том, что пробовать нужно под большой нагрузкой. Это либо целые технологии, либо – эксперименты на живых людях.
Мы для себя ответа не нашли, поэтому пользуемся и для безопасного старта советуем версию Postgre 9.6.
PostgreSQL из коробки и реальность
PostgreSQL можно поставить из коробки – он будет работать. Но, как показывает практика, чуть-чуть больше нагрузки, и это уже не работа.
В 2010 году у нас был интересный опыт соревнования Microsoft SQL и PostgreSQL – вплоть до того, «1С» нам дала посотрудничать с куратором, который ведет PostgreSQL. На тот момент PostgreSQL отставал от Microsoft SQL примерно на 30% – если на одинаковом железе просто в разных средах запускаешь две одинаковые системы.
Где-то к 8.3 PostgreSQL и MS SQL практически выровнялись по производительности. Но это не PostgreSQL догнала MS SQL – PostgreSQL на 10-15% выросла, но не больше. Очень сильно почему-то просел MS SQL.
Если смотреть на тест Гилева – он записывает 10 тысяч документов определенного вида и считает время. Берем классическую УТ-шку и строим отчет за год по какой-нибудь виртуальной базе. Нажимаем кнопочку, и он строится в Microsoft SQL 4 минуты, а в PostgreSQL он построится за 2. Получение отчетов в PostgreSQL – в разы лучше, а запись в СУБД – явно уступает.
Еще в PostgreSQL требуется гораздо меньше действий с точки зрения сисадминского обслуживания – не нужно делать shrink базы, у PostgreSQL есть autovacuum, он эти задачи решает.

Но чтобы все это прекрасно и хорошо работало, на слайде показано девять переменных среды, которые в конфиге PostgreSQL нужно настроить изначально. Сохраняйте себе этот слайд в качестве чек-листа.
-
max_connections = 100
-
shared_buffers = 4GB – по теории должен быть равен 1/4 ОЗУ. У нас у стандартной виртуальной машины 16 ГБ оперативки, на СУБД мы выделяем 1/4.
-
effective_cache_size = 12GB – обычно указывают весь размер ОЗУ. У нас полный размер ОЗУ 16ГБ, мы берем чуть меньше, из опыта.
-
work_mem = 41943KB – опытным путем определили, что для наших баз хватает, чтобы коэффициент использования временных файлов был менее 0.2. 1С советует этот параметр задавать 256МБ, но это – объем памяти, которая съедается каждым соединением с базой, поэтому в теории все соединения могут сожрать max_connections*work_mem.
-
maintenance_work_mem = 1GB – это тот же work_mem, но для автовакуума. Мы его задаем больше, чем у обычного соединения, потому что чем больше таблицы в базе, тем больше нужно задавать этот параметр, тем быстрее отрабатывает автовакуум (большую часть таблицы или индекса может в память затащить).
-
max_wal_size = 1024MB – это выделенное место на диске, влияет на частоту контрольных точек. Чем больше этот параметр, тем реже контрольные точки, тем меньше нагрузка на диск, но тем дольше восстановление базы после сбоя (рестарта Postgres). Обычно контрольные точки в постгрес происходят каждые 5 мин и при этом ВСЕ измененные данные в кеше (shared_buffers) записываются на диск.
-
checkpoint_completion_target = 0.9 – это значит, что запись измененных страниц растянута во времени на 90% до след. контрольной точки
-
random_page_cost = 1.1 – значение для дисков SSD (соотношение рандомного и последовательного доступа). Для обычных дисков random_page_cost = 4
-
Для лучшей работы оптимизатора запросов устанавливают default_statistics_target = 1000, но тогда увеличивается время сбора статистики и размер таблиц, в которой статистика хранится.
Работать в продакшене с чужими данными и не иметь хорошую систему восстановления из бэкапов – это рискованное занятие, особенно, если у вас SSD-диски, а не Software RAID. Поэтому мы используем систему бэкапов Barman. На слайде приведены настройки Barman, которые мы используем, и они немного расшифрованы.
-
wal_level = replica – уровень журнала (какой объем писать в журнал). Для реплики или возможности восстановления базы нужен уровень replica. minimal не подходит.
-
max_wal_senders = 5 – сколько будет процессов, к которым могут подключиться реплики базы или Barman.
-
max_wal_size – кольцевой буфер, выделенное место на диске (выше описан). Голова может захавать хвост, который еще на реплику не ушел, тогда репликация прервется.
-
wal_keep_segments = 256 – задает, сколько сегментов (файлы по 16 МБ) будут сохранены дополнительно, чтобы репликация не прервалась.
-
max_replication_slots = 1 – а это для 100% гарантии что голова не сожрет хвост, пока хвост не уйдет на реплику. Barman включает слот сам. На больших клиентах слоты лучше не использовать – потому что журнал может забить весь диск, если репликация отпадет на длительное время (сутки). Barman включает и использует ОДИН слот.
Есть такая штука, как калькулятор этих параметров PG – http://pgconfigurator.cybertec.at/. Когда-то все приходилось делать руками с тонкой настройкой журнала. Сейчас есть отличные калькуляторы, их уже много развелось. Вносите параметры своего железа, и получаете настройки, конкретно под вас посчитанные.
Простым мониторингом техжурнала и анализом планов запроса PostgreSQL иногда можно делать чудесные вещи – можно разобрать запросы и в разы поменять производительность рекомендациями либо конкретными настройками под их специфику нагрузки на сервер.
Используя рекомендации теста Гилева, теоретически можно заточить продакшн так, что он покажет прекрасный результат, но не факт, что потом будут хорошо строится отчеты, потому что тест Гилева – это тест на запись.
Поэтому, прежде чем крутить эти настройки, кроме базовых настроек потом нужно смотреть в профайлер и в техжурнал. Но для этого нужно иметь какую-то экспертность. Поэтому 1С:Эксперт в вашей команде крайне желателен.
Бэкапы

Для создания бэкапов мы используем Barman 2.11 (расшифровывается Backup and Recovery Manager). Он позволяет настраивать хост бэкапов, юзеров для бэкапов, указывать, как долго хранить бэкапы.
Кроме обычных бэкапов Barman поддерживает восстановление на момент времени через снятие транзакционного лога – Point-in-time. Поэтому поверх бэкапов, которые я делаю на ходу каждую ночь, я могу накатить транзакционный лог – восстановить до последней зафиксированной транзакции. Очень прикольная вещь.
Раньше мы использовали систему Master/Slave. Можно даже настроить autofailover, когда у вас в системе есть база master и база slave, которые сами друг между другом переключаются. Но в этом механизме есть ложные срабатывания, а переключение – с проблемами. Поэтому мы от этого отказались.
Если случается какая-то беда – поднимаем ночной бэкап. Зеркало развалить сложно, но можно. Если такое случается – можем докатить до любой точки. Например, для случаев: «Ой, мы сделали перепроведение и удалили документы, но ночной бэкап не подходит, потому что мы с утра загрузили 8000 накладных от менеджеров. Можно нам состояние базы данных на 12 часов дня?» Пожалуйста, без проблем. Поэтому рекомендую Point-in-time для облаков 1С – прекрасная штука.
Zabbix

На слайде – кратко о Zabbix. Долго выводили отличные вещи, показатели с формулами, как их вытащить, с нормами, как работает PostgreSQL. Если что-то здесь идет не так – это повод настраивать техжурнал или смотреть уже в PostgreSQL.
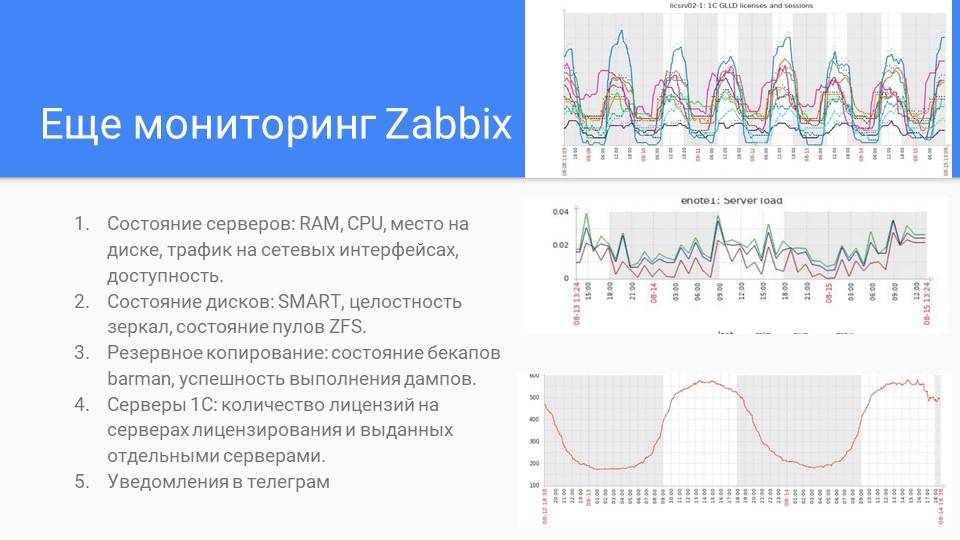
Кратко о том, что мы мониторим на серверах.
На нижнем графике видно, как у нас выдаются лицензии на сервер – ночью расход лицензий падает.
На верхнем графике видно, что пару дней назад было падение – федеральный Мегафон упал, и половина клиентов по региону отвалилась.
На среднем графике видно мониторинг нагрузок.

На слайде показан uptime с двух серверов, чтобы показать, сколько времени это у нас работает.
Вопросы
Proxmox Virtual Environment у вас платный?
Нет, у нас все используется бесплатное.
У вас на проде стоят отдельные базы, вы не используете технологию 1С:fresh?
Где-то используем. Но мы однажды обожглись на том, что когда с продовской базой что-то случается, оно случается с объемом всей базы. Кто из клиентов начинает что-то в базе хранить, какие-то свои заморочки – и от этого все может обвалиться. А когда у нас все поделено на отдельные базы, это лучше.
Еще у 1С:fresh есть прекрасная функция – нажал кнопку и обновил 100 баз. А утром 100 клиентов оторвали тебе сердце, потому что одновременное обновление большого количества баз данных бывает нужно, только если ты – админ на одном предприятии и это все – твое хозяйство. А если у тебя на проде Марья Ивановна пришла утром, и, не ожидая, увидела обновленную Бухгалтерию, ты не сделал ей хорошо.
Поэтому они все равно пишут: «Мы хотим обновиться» и дальше админ ручками или кнопочкой обновляет конкретную базу в конкретное время. Есть очередь, тикеты, задачи.
У нас есть клиенты в 12 часовых поясах, поэтому админы работают круглосуточно, по часовым поясам разбросаны. И мы не видим ничего зазорного в том, чтобы обновить только одну базу. Нам так как-то спокойнее.
Последний 1C:fresh уже гораздо лучше, но мы для себя решили, что отдельные базы – лучше.
С какой целью перезапускаете каждую ночь сервер 1С?
Это, скорее, ритуал из тех времен, когда ты, если не перезагрузишь, у тебя все пропало, потому что начальная 8.3 сжирала память. Сейчас 8.3 не сжирает память, особенно, когда вышла платформа с функциональностью КОРП. Самый кайфовый релиз, на котором мы стали спокойно спать – это 8.3.10. Мы на нем очень долго отработали. Сейчас на 8.3.15 перешли. Но такой момент, что если ты его месяц не перезапускаешь, и он тебе где-то сожрет память, или где-то что-то начнет подтупливать, присутствует. И поэтому, как ритуал, оно стоит.
С учетом того, что в платформе КОРП есть контроль расхода памяти на один вызов и контроль объема памяти рабочих процессов – скорее всего, это ритуал. Но он никак не мешает работе пользователей.
При перезапуске мы снимаем еще и ночные дампы. У нас в определенное время рестартует сервер 1С и после этого начинают сниматься дампы. Так исторически сложилось.
Если не секрет, какова точка окупаемости по количеству пользователей, клиентов?
Точка окупаемости по железу – это 300-330 пользователей. Мы на нее и рассчитывали, пока не знали, что такое Linux, и сколько стоит эксперт по техвопросам, сколько стоит круглосуточная техподдержка и т.д.
Поэтому, если по-настоящему все строить огромным, большим, то где-то за 1000 пользователей когда перевалили, тогда мы начали понимать, что месяц прожит не зря.
А по времени – это сколько получилось?
Поэтому я и говорю, что есть прекрасный ГРМ, есть прекрасный 1С:fresh. Если вы это умеете продавать, если вы научились работать с возражениями: «Вы что, будете смотреть наши данные в облаках?» – а вы говорите – «Лучше посмотрим мы, чем придет налоговая инспекция или конкуренты сделают рейдовый захват».
Тот момент, когда мы продали наш проект сети строительных супермаркетов и у них кассы в онлайне у нас работают 5 лет. И за эти 5 лет у них было всего два часа простоя. Притом, что мы SLA подписываем 99%, а клиент на тот момент уже и кучу серверов поменял, и кучу админов, и он понимает, сколько он нам абонентной платы платит и сколько стоит мальчик, который картриджи меняет и кассы подключает по сравнению с тем, чтобы весь этот пароход содержать. То он, по большому счету, счастлив.
Как только на смене есть дежурные сисадмины, которые всегда есть, директор может спать спокойно. Но до этого момента самая страшная вещь – это звонящий ночью телефон. Поэтому я говорю – если вы серьезно идете в облака, стройте все правильно. Если нет – ГРМ, Облачная инфраструктура, 1С:fresh. Начните с этого, там у других людей будет болеть голова. Когда будете готовы – пробуйте.
Почему Barman, а не pg_probackup?
Может быть, мы про него не знаем. Мы пробовали очень много систем, но по удобству работы Barman – самый лучший. У него есть только один недостаток – если вам нужно вытащить ровно одну базу из него в определенный момент, он так не умеет, он восстановит весь кластер. Но с учетом того, что на продакшене всегде есть один или несколько резервных серверов, мы восстанавливаем кластер на нужном сервере, поднимаем до нужного момента, выхватываем базу, отдаем клиенту.
Barman простой, легкий, удобный.
У вас все на виртуалках или на хостах?
Везде только виртуалки, потому что не дай Бог что-то с хостом – все пропало. А когда у вас виртуалка, вы что-то можете с этим еще сделать и узнать о проблеме раньше. Поэтому – нет, только на виртуалках.
Когда-то в детстве, когда мы шли, мы наступили на все возможные грабли, перепробовали кучу систем виртуализации. Но сейчас – только виртуалки.
Точнее, триада: стоит хост, на нем виртуалка с 1С и виртуалка с СУБД. Больше ничего нет.
Потери производительности мы когда-то мерили, но если тест Гилева вам показывает разницу 2-3 попугая на 20-30 попугаях, то с точки зрения работы юзеров это не замечается. Поверьте, кассовый ордер проводится 0,3 секунды или 0,4 секунды – разницы вы не увидите.
У нас в облаках тупит не производительность сервера, а пинг. Если у вас пинг больше, чем 120, юзеры вас проклянут. Если 60 и меньше – они будут комфортно работать. Если пинг – 20, они будут работать, как в локальной сети. А если у вас серьезный прод, вы его все равно будете затачивать, скорее, переписыванием запросов и тонкими настройками, чем выбирать между виртуалкой и невиртуалкой.
Тем более, несколько виртуалок держать выгоднее – даже если у вас упадет виртуалка с сервером 1С, у вас останется живая виртуалка с СУБД – это практично.
KVM или LXC?
Я же говорил, что мы пробовали LXC-контейнеры, но у них геморрой, что там при перетаскивании контейнера может смениться состав и – «садись, активируй лицензии».
А так как мы начинали, как и все маленькие, с покупки комплектов лицензий на 20 пользователей (вы же знаете, сколько все это стоит), то сейчас у нас есть сервера, где может валяться 15-20 лицензий на 20 пользователей и еще несколько на 10 пользователей. И, когда это все упало, их все нужно ручками переактивировать.
Наши любимые коллеги из 1С до сих пор же не сделали такой сервис, когда в 3 часа ночи упало и ты можешь заказать лицензию, чтобы у тебя новый пинкод пришел. Поэтому мы заранее заказываем резервные пинкоды, но их потом все равно еще надо кому-то сесть и ввести.
И, кстати, да – в последние полгода мы уже отказались от активации локальных лицензий, мы наконец-то добились устойчивой классной работы сервера лицензирования. И вообще стало прекрасно жить.
У нас несколько серверов лицензирования – они больше заточены на перераспределение лицензий по нагрузке, чтобы комбинировать пользователей по кластерам, чтобы проворачивать большее количество пользователей в онлайне с одним и тем же пулом лицензий.
Но сервер лицензирования тоже лежит в контейнере и ее машина тоже может упасть, поэтому это тоже может мгновенно мигрировать куда-то там. С одной стороны, все прекрасно, они редко падают – у нас таких случаев не было. Но я себе представляю, что будет, если он упадет со своими 1500 лицензий в одном пуле – и потом еще не дай Бог нам их переактивировать придется. Поэтому все максимально зафиксировано в двигающемся контейнере, не меняющим свои свойства при миграции.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "1С и Linux".
Вступайте в нашу телеграмм-группу Инфостарт