Оглавление
Постановка задачи и интуитивный метод проектирования
Новая структура регистра сведений
Материалы, использованные при подготовке статьи
«Что может быть проще?» — это первое, что приходит в голову. И действительно, регистры сведений — одни из самых простых объектов конфигурации. За одним известным исключением, это обычные плоские таблицы в своем классическом виде. И если эта таблица содержит относительно небольшое количество записей, то ни с проектированием, ни с использованием проблем не будет. Но что, если это не так? В этой статье мы попробуем затронуть некоторые вопросы, которые могут возникнуть при проектировании больших регистров.
Постановка задачи и интуитивный метод проектирования
Давайте начнем с постановки задачи. Допустим, есть некая складская подсистема. Из разговора с заказчиком получаем следующее видение:
- Необходимо создать объект, который хранил бы соответствие между подразделением, складом и номенклатурой.
- Подразделение находится в организации.
- Склад имеет адресное хранение.
- Номенклатура учитывается вместе с характеристикой.
Анализируем, получаем набор атрибутов, которые должны быть в нашем регистре:
- Организация
- Подразделение организации
- Склад
- Стеллаж
- Полка
- Секция
- Ячейка склада
- Номенклатура
- Характеристика номенклатуры
Несложно заметить, что все атрибуты — ключевые, поэтому они полным списком попадают в ветку измерений, а ресурсов и реквизитов в этом случае не будет вообще.
В результате получаем следующую структуру:
- Измерения
- Организация
- Подразделение организации
- Склад
- Стеллаж
- Полка
- Секция
- Ячейка склада
- Номенклатура
- Характеристика номенклатуры
- Ресурсы
Теперь самое время задать себе вопрос: то, что мы спроектировали, оптимально или нет? Для того, чтобы ответить на него, необходимо выбрать некоторый набор критериев и применить их к нашей структуре. Таким путем можно обоснованно сделать вывод об оптимальности.
Ниже будут рассмотрены:
- Нормальные формы БД
- Проектирование запросов к РС
- Индексы РС
В действительности, конечно, этих критериев намного больше. Но, как покажет дальнейшее изложение, даже они способны улучшить структуру регистра.
Не ограничивая общности рассуждения, заметим, что:
- Нормальные формы дадут минимальную таблицу по количеству столбцов.
- Проектирование запросов приблизит это минимальное количество к оптимальному.
- Проектирование индексов в дальнейшем поможет разрабатывать оптимальные запросы.
Нормализация таблиц
Нам потребуется привести таблицу ко 2-й нормальной форме. И в этом нам поможет определение функциональной зависимости (ФЗ).
Пусть дано отношение r со схемой (заголовком) R, A и B — некоторые подмножества множества атрибутов отношения r. Множество B функционально зависит от A тогда и только тогда, когда каждое значение множества A связано в точности с одним значением множества B. Обозначается A -> B.
Говоря простым языком, ФЗ — это связь типа «многие-к-одному» между двумя полями одной или двух таблиц. В любой конфигурации такие связи встречаются буквально на каждом шагу. Вот несколько примеров:
- Подчиненный элемент функционально определяет своего владельца
- Подчиненный элемент функционально определяет своего родителя
- Справочник, реквизитом которого является ссылка на другой справочник, например, ЕдиницаИзмерения в Номенклатуре (СправочникСсылка.КлассификаторЕдиницИзмерения) и так далее.
Вспомним определения первой и второй нормальных форм.
Переменная отношения находится в первой нормальной форме (1НФ) тогда и только тогда, когда в любом допустимом значении отношения каждый его кортеж содержит только одно значение для каждого из атрибутов.
Переменная отношения находится во второй нормальной форме (2НФ) тогда и только тогда, когда она находится в первой нормальной форме и каждый неключевой атрибут неприводимо (функционально полно) зависит от ее потенциального ключа. Функционально полная зависимость означает, что если потенциальный ключ является составным, то атрибут зависит от всего ключа и не зависит от его частей.
В переводе с высокого научного на обыденный программистский 1НФ требует отсутствие порядка строк, порядка столбцов, уникальности строк, атомарности значений измерений и единообразность обработки всех значений. Все это обеспечивает движок 1С по умолчанию.
Смысл 2НФ в том, чтобы из ключа отношения нельзя было удалить какое-либо поле без потери функциональности. К примеру, у нас есть некая исходная таблица, которая содержит в себе организацию и подразделение организации. При условии, что подразделение организации функционально определяет организацию, если мы удалим подразделение организации из таблицы, то потеряем функциональность. А вот если мы удалим организацию, то с помощью запроса всегда сможем восстановить исходную таблицу.
Применим это к нашему регистру. Вот список ФЗ:
- Подразделение организации -> Организация
- Склад -> Подразделение организации
- Ячейка склада -> Секция -> Полка -> Стеллаж -> Склад
- Характеристика номенклатуры -> Номенклатура
Удалив все «лишние» поля из регистра, получим структуру:
- Измерения
- Ячейка склада
- Характеристика номенклатуры
- Ресурсы
Думаем, Антон Павлович бы это одобрил. Однако платой за такую лаконичность является запрос, который восстанавливает исходную таблицу:
ВЫБРАТЬ
Организация.Ссылка КАК Организация,
ПодразделениеОрганизации.Ссылка КАК ПодразделениеОрганизации,
Склад.Ссылка КАК Склад,
Стеллаж.Ссылка КАК Стеллаж,
Полка.Ссылка КАК Полка,
Секция.Ссылка КАК Секция,
РезервыНаСкладе.ЯчейкаСклада КАК ЯчейкаСклада,
Номенклатура.Ссылка КАК Номенклатура,
РезервыНаСкладе.ХарактеристикаНоменклатуры КАК ХарактеристикаНоменклатуры
ИЗ
РегистрСведений.РезервыНаСкладе КАК РезервыНаСкладе
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.ЯчейкаСклада КАК ЯчейкаСкладаСпр
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.Секция КАК Секция
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.Полка КАК Полка
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.Стеллаж КАК Стеллаж
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.Склад КАК Склад
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.ПодразделениеОрганизации КАК ПодразделениеОрганизации
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.Организация КАК Организация
ПО ПодразделениеОрганизации.Владелец = Организация.Ссылка
ПО Склад.Владелец = ПодразделениеОрганизации.Ссылка
ПО Стеллаж.Владелец = Склад.Ссылка
ПО Полка.Владелец = Стеллаж.Ссылка
ПО Секция.Владелец = Полка.Ссылка
ПО ЯчейкаСкладаСпр.Владелец = Секция.Ссылка
ПО РезервыНаСкладе.ЯчейкаСклада = ЯчейкаСкладаСпр.Ссылка
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.ХарактеристикаНоменклатуры КАК ХарактеристикаНоменклатурыСпр
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.Номенклатура КАК Номенклатура
ПО ХарактеристикаНоменклатурыСпр.Владелец = Номенклатура.Ссылка
ПО РезервыНаСкладе.ХарактеристикаНоменклатуры = ХарактеристикаНоменклатурыСпр.Ссылка
Определенно, в этом подходе что-то есть, но назвать результат оптимальным затруднительно.
Наиболее важные запросы
И тогда мы снова идем к нашему дорогому заказчику. И спрашиваем, какие выборки для него будут наиболее актуальны. Если он говорит, что все, мы не верим и снова спрашиваем. В конечном итоге выясняется, что таких запросов, наиболее вероятно, будет три.
Первый запрос
Есть некий документ, какое-то резервирование, которое соединяется с нашим регистром сведений по подразделению организации.
ВЫБРАТЬ
Резервирование.Ссылка КАК Ссылка,
Резервирование.ПодразделениеОрганизации КАК ПодразделениеОрганизации,
ПодразделенияСкладыНоменклатура.Склад КАК Склад,
ПодразделенияСкладыНоменклатура.ЯчейкаСклада КАК ЯчейкаСклада,
ПодразделенияСкладыНоменклатура.Номенклатура КАК Номенклатура,
ПодразделенияСкладыНоменклатура.ХарактеристикаНоменклатуры КАК ХарактеристикаНоменклатуры
ИЗ
Документ.Резервирование КАК Резервирование
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ПодразделенияСкладыНоменклатура КАК ПодразделенияСкладыНоменклатура
ПО (Резервирование.ПодразделениеОрганизации = ПодразделенияСкладыНоменклатура.ПодразделениеОрганизации)
ГДЕ
Резервирование.Ссылка = &Ссылка
Второй запрос
Соединение по складу некого документа и регистра сведений.
ВЫБРАТЬ
Резервирование.Ссылка КАК Ссылка,
Резервирование.Склад КАК Склад,
ПодразделенияСкладыНоменклатура.Номенклатура КАК Номенклатура,
ПодразделенияСкладыНоменклатура.ХарактеристикаНоменклатуры КАК ХарактеристикаНоменклатуры,
ПодразделенияСкладыНоменклатура.ПодразделениеОрганизации КАК ПодразделениеОрганизации,
ПодразделенияСкладыНоменклатура.ЯчейкаСклада КАК ЯчейкаСклада
ИЗ
Документ.Резервирование КАК Резервирование
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ПодразделенияСкладыНоменклатура КАК ПодразделенияСкладыНоменклатура
ПО (Резервирование.Склад = ПодразделенияСкладыНоменклатура.Склад)
ГДЕ
Резервирование.Ссылка = &Ссылка
Третий запрос
У документа резервирования есть табличная часть товары, которая будет соединяться с нашим регистром сведений по номенклатуре и характеристике номенклатуры.
ВЫБРАТЬ
РезервированиеТовары.Номенклатура КАК Номенклатура,
РезервированиеТовары.ХарактеристикаНоменклатуры КАК ХарактеристикаНоменклатуры,
РезервированиеТовары.Количество КАК Количество,
ПодразделенияСкладыНоменклатура.ПодразделениеОрганизации КАК ПодразделениеОрганизации,
ПодразделенияСкладыНоменклатура.Склад КАК Склад,
ПодразделенияСкладыНоменклатура.ЯчейкаСклада КАК ЯчейкаСклада
ИЗ
Документ.Резервирование.Товары КАК РезервированиеТовары
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ПодразделенияСкладыНоменклатура КАК ПодразделенияСкладыНоменклатура
ПО (РезервированиеТовары.Номенклатура = ПодразделенияСкладыНоменклатура.Номенклатура
И РезервированиеТовары.ХарактеристикаНоменклатуры = ПодразделенияСкладыНоменклатура.ХарактеристикаНоменклатуры)
ГДЕ
РезервированиеТовары.Ссылка = &Ссылка
Новая структура регистра сведений
Наша цель состоит в том, чтобы избежать в запросах лишних соединений. Очевидно, что для этого необходимо включить в структуру регистра все поля, которые упоминаются в любой из частей запросов. Несложные манипуляции приводят нас к следующей структуре:
- Измерения
- Подразделение организации
- Склад
- Ячейка склада
- Номенклатура
- Характеристика номенклатуры
- Ресурсы
Использование индексов
Одной из типичных причин неоптимальной работы запросов считается несоответствие индексов и условий запроса. В известной статье на ИТС предлагается изменить условия таким образом, чтобы оптимизатор запросов сервера SQL мог использовать индексы. В нашем случае надо пройти обратной дорогой — от условий к индексам. Это не такая очевидная задача из-за особенностей создания индексов сервером приложений 1С.
Проектирование индексов. Попытка 1
Попробуем решить задачу «в лоб» и просто добавим индексирование тем полям, которые участвуют в условиях запроса.
- Измерения
- Подразделение организации (cluster index)
- Склад (index)
- Ячейка склада
- Номенклатура (index)
- Характеристика номенклатуры (index)
- Ресурсы
Первый запрос будет использовать кластерный индекс, второй — индекс по полю Склад. А третий, скорее всего — сканирование кластерного индекса с предикатом WHERE:(), потому что не найдет такого индекса, где бы участвовала и номенклатура, и ее характеристика.
Проектирование индексов. Попытка 2
Немного изменим порядок полей:
- Измерения
- Номенклатура (cluster index)
- Характеристика номенклатуры (cluster index)
- Подразделение организации (index)
- Склад (index)
- Ячейка склада
- Ресурсы
В этом случае есть шанс, что все три запроса найдут каждый свой эффективный индекс.
Подтверждение результатов проектирования
Индексы
До сих пор мы использовали исключительно теоретические рассуждения. Они достаточны в случае нормализации таблиц и оптимизации структуры регистра под запросы. Но проверить использование индексов при исполнении запросов можно, только создав структуру. Для этого был реализован демонстрационный пример на платформе 8.3.18 и MS SQL Server. Со стороны 1С индексы выглядят следующим образом:
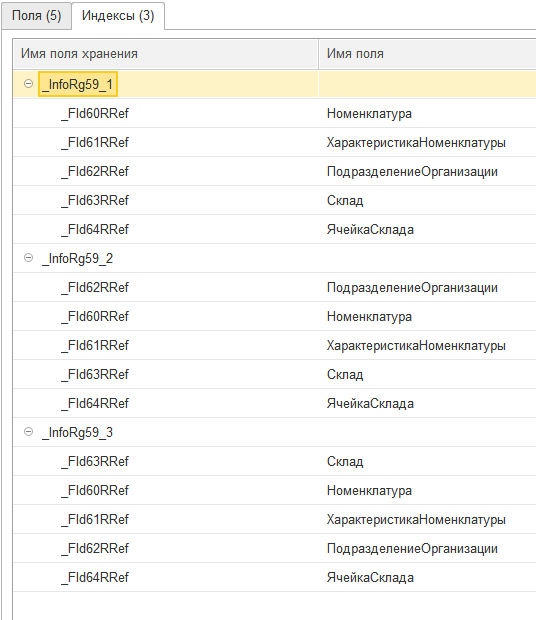
Очень похоже на нужный нам результат, но хотелось бы окончательных доказательств. Фактических. Настоящих. Брони!
Предыдущий рисунок показывает наименования полей и индексов так, как они выглядят на стороне сервера баз данных. Это сильно облегчит чтение следующего рисунка:
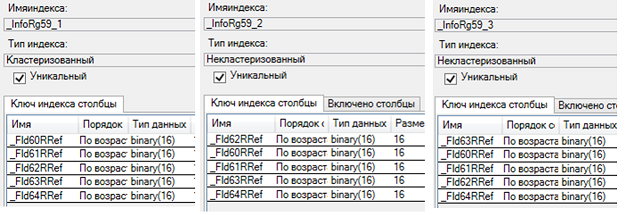
Из него абсолютно точно понятно, что первый индекс — кластерный, остальные — уникальные, а на ИТС пишут правду и ничего кроме.
Но настоящей проверкой индексов должно стать получение плана запросов. Это связано с алгоритмом работы оптимизатора запросов. В общем случае предугадать его результат непросто.
Для получения планов запросов была использована известная обработка:
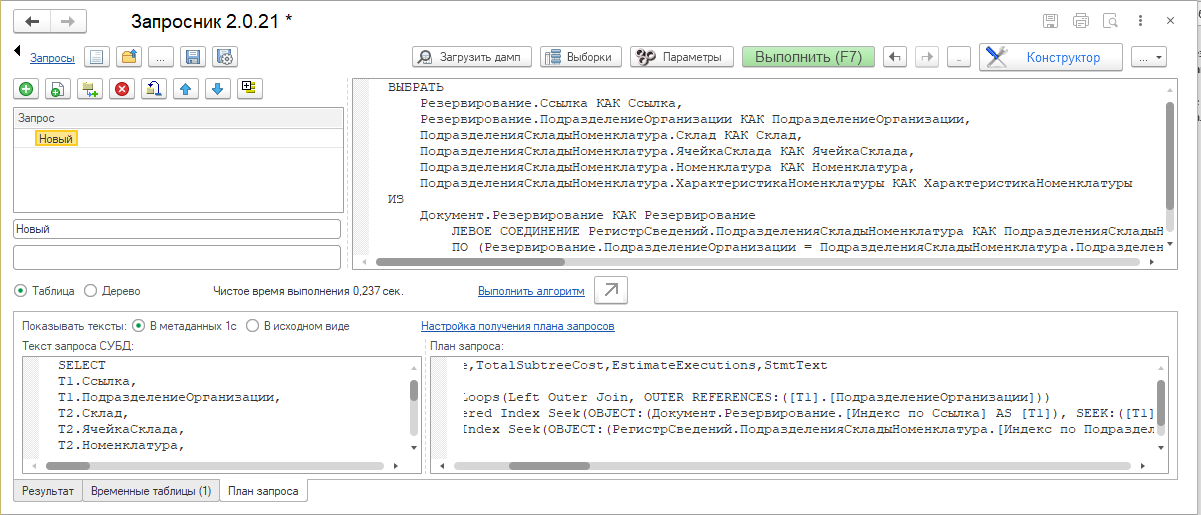
Основное ее достоинство в отношении запросов и их планов состоит в том, что обработка производит частичную их трансляцию в термины метаданных. Эта функция добавляет комфорта и позволяет тратить меньше времени на интерпретацию полученной информации. Вот какой результат был получен.
Запрос 1: соединение по подразделению
ВЫБРАТЬ
…
ИЗ
Документ.Резервирование КАК Резервирование
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ПодразделенияСкладыНоменклатура КАК
ПодразделенияСкладыНоменклатура
ПО (Резервирование.ПодразделениеОрганизации =
ПодразделенияСкладыНоменклатура.ПодразделениеОрганизации)
|--Index Seek (OBJECT:(РегистрСведений.ПодразделенияСкладыНоменклатура.
[Индекс по ПодразделениеОрганизации, Номенклатура,
ХарактеристикаНоменклатуры, Склад, ЯчейкаСклада]
AS [T2]), SEEK:([T2].[ПодразделениеОрганизации]=Документ.Резервирование.
[ПодразделениеОрганизации]
as [T1].[ПодразделениеОрганизации]) ORDERED FORWARD)
Запрос 2: соединение по складу
ВЫБРАТЬ
...
ИЗ
Документ.Резервирование КАК Резервирование
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ПодразделенияСкладыНоменклатура КАК
ПодразделенияСкладыНоменклатура
ПО (Резервирование.Склад = ПодразделенияСкладыНоменклатура.Склад)
|--Index Seek (OBJECT:(РегистрСведений.ПодразделенияСкладыНоменклатура.[Индекс
по Склад, Номенклатура, ХарактеристикаНоменклатуры,
ПодразделениеОрганизации, ЯчейкаСклада] AS [T2]), SEEK:([T2].
[Склад]=Документ.Резервирование.[Склад] as [T1].[Склад]) ORDERED FORWARD)
Запрос 3: соединение по номенклатуре и характеристике номенклатуры
ВЫБРАТЬ
...
ИЗ
Документ.Резервирование.Товары КАК РезервированиеТовары
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ПодразделенияСкладыНоменклатура КАК
ПодразделенияСкладыНоменклатура
ПО (РезервированиеТовары.Номенклатура =
ПодразделенияСкладыНоменклатура.Номенклатура
И РезервированиеТовары.ХарактеристикаНоменклатуры =
ПодразделенияСкладыНоменклатура.ХарактеристикаНоменклатуры)
План запроса:
|--Clustered Index Seek (OBJECT:(РегистрСведений.ПодразделенияСкладыНоменклатура.
[Индекс по Номенклатура, ХарактеристикаНоменклатуры,
ПодразделениеОрганизации, Склад, ЯчейкаСклада] AS [T2]), SEEK:([T2].
[Номенклатура]=Документ.Резервирование.Товары.[Номенклатура] as [T1].[Номенклатура]
AND [T2].[ХарактеристикаНоменклатуры]=Документ.Резервирование.Товары.
[ХарактеристикаНоменклатуры] as [T1].[ХарактеристикаНоменклатуры]) ORDERED
FORWARD)
Как можно видеть, во всех трех случаях оптимизатор использовал операторы Index Seek без предиката WHERE. Это именно тот результат, который планировался изначально.
Заключение
В этой статье удалось показать лишь небольшую часть работы, которую проделывает системный архитектор при проектировании структур данных для новой системы. На практике этот путь намного длиннее. Например, рассмотренные запросы должны быть получены из случаев использования системы, а при проектировании индексов желательно учитывать их избирательность и т.д. и т.п.
Полученный результат нетривиален, но закономерен. В этом можно убедиться, если посмотреть, например, УТ 11. Вот несколько регистров из нее:
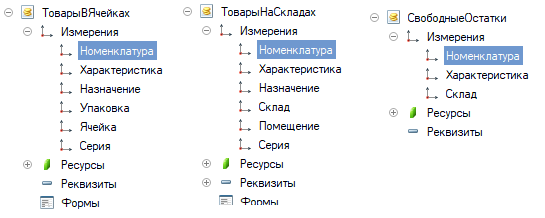
Материалы, использованные при подготовке статьи
- Материалы ИТС:
- Регистры сведений 1С. Как это устроено
- Справочник по логическим и физическим операторам Showplan
Вступайте в нашу телеграмм-группу Инфостарт
