Всем хайушки!
Статья написана вручную, если не считать заголовка - это джимми. Картинку запилил на своем компе, использовал модель "Tongyi-MAI/Z-Image-Turbo" от Алибабы.
О дивный новый мир?
В последнее время я увлекся вайбкодингом, т.к. с помощью этого у разработчика в общем-то пропадает привязанность к конкретному стеку.
Не сказать, что я вот вообще ноль во всем, помимо 1С, но и сказать, что я в чем-то неплохо разбираюсь, помимо опять же 1С, я не могу. И вот начавшаяся эпоха агентов для кодирования это все резко поменяла. Теперь я без особого труда мучу за пару дней игруху на котлине, а за пару часов - домашнюю бухгалтерию с OCR. При этом не заплатив ни цента за платные модели.
Предлагаю обсудить вайбкодинг с локальным инференсом, т.е. с запуском моделей для агента на своем железе. Почему "обсудить"? Потому, что я не хочу предложить одно свое правильное мнение, а хочу узнать у сообщества, как мы все это делаем, что получается, с какими трудностями сталкиваемся и как их преодолеваем. Так что добро пожаловать в комменты. И сами знаете - я никого не помещаю в черные списки, так что можете писать любую дичь, но в пределах правил площадки.
Немного истории
После того, как бум блокчейна несколько сошел и все небезразличные написали свои пару контрактов на Solidity (включая меня), наступила эра нейросетей. Все небезразличные закупились книжками и курсами (в то время они еще не были такой маркетинговой лютой дичью, какой стали сейчас), насмотрелись видосов, попробовали все эти ИИ-чаты и подуспокоились. Потенциал этого всего явно просматривался, поэтому и я закупился книжками и просмотрел все, до чего смог добраться. Коллеги активно разбирались с ML, рисовали все эти градиенты на плоскостях, вычисляли уровни ошибок и прочие метрики, разбирались с переобученностью моделей и прочими унылостями линейной алгебры. Я постоянно проходил мимо, смотрел с лицом, выражавшим понимание и одобрение. До уханьского насморка оставалось каких-то пару лет.
И уже тогда было понятно, что сети будут расти очень стремительно. Количество параметров производило качественные скачки в генерации текста, сети начали отвечать на вопросы куда лучше, чем токсичные разрабы на Stack Overflow. Стало ясно, что это всерьез и на долго.
Но переломный для меня момент начался с появлением агентов. Т.е. программ, которые дают сетке снести годы твоей работы с помощью "rm * -rf". Но это, конечно, крайний случай, ибо остальные команды, используемые сетью, генерируют код, собирают его, тестируют и создают MR в гит. Именно так я написал свой MCP для 1С.
Продолжим...
Почем опиум для народа?
Сеть на 1Т параметров кодит хорошо, но в твой компьютер не влезет. Хотя если взять квантизированную сеть, например в q3, то есть шанс разместить ее в компьютере с большим количеством ОЗУ (300Gb+), которое ныне дорогое (я покупал себе 2х48 DDR5 6400MT на старте почти продаж за 42к, а теперь оно стоит 100к+++, хотя есть 5600МТ и за 80к). Но если заставить это работать на процессоре, то результатов вы скорее всего не дождетесь, т.к. 2-3 токена/сек - это ну о-о-о-о-чень медленно.
И тогда что? Правильно, можно купить какую-нить подписку за какие-то деньги, после чего в твоем агенте будет работать сеть, кушающая электричество западного Китая. Стоит это для такого вот приличного вайбкодинга в районе 1000 юаней (не спрашивайте, сколько это - я не знаю).
Наверное это копейки по сравнению с зарплатой программиста, но мне боженька дал хорошую зарплату, поэтому я не буду прогибаться под систему и запилю свой инференс с блэкджеком и теми, кто не смог освоить джаваскрипт (ну вы ведь помните ту картинку, да? а теперь, заметьте, она утратила актуальность...)
Все свое!
Железо
Для того, чтобы запустить более-менее прилично пишущую код модельку локально, нужно 32 гига. В оперативке и на CPU скорость такая себе. Хотя если у вас стоядерный эпик с 1Тб/с пропускной способностью памяти, то можете и на нем, тем более что туда может влезть пару ведер оперативки. Но это как-то уж слишком дорого даже для меня. Поэтому я за 32 гига видеопамяти. Вот вам варианты поиметь столько:
1. На озонах есть серверные теслы с 32 гигами, переделанные под PCI-E. Стоят от 50к, но с ними гемор, т.к. там кастомный охлад и нужны специальные дрова. Ну и куча дополнительной суеты, если вы хотите на этом поиграть. Инференс уже 50+ т/с, что вполне прилично для вайбкодинга.
2. Можно купить 2 x AMD 9060XT - те же 32 гига, низкое энергопотребление, но занимают 2 слота, и для хорошей скорости требует хорошую материнку. По деньгам уложитесь в 70к и получите свои 60-80 т/с без геморроя. Вместо 9060XT можно взять 5060ti 16Gb - это будет на 20к дороже, но работать должно на 20-30% быстрее.
3. AMD 9700 AI PRO. Это уже цена двух 5070ti, но вся память на одном девайсе, и при аналогичном TDP карточек одна будет в 2 раза менее прожорлива. Не знаю, какая скорость инференса, но у меня как раз 2x5070ti, что дает 150+ т/с, а это уже уровень хорошей подписки.
4. Если есть денежка, то нет ничего лучше 5090. Да, в 2 раза дороже, но и скорость примерно в 2 раза быстрее. Получите 250-300 т/с, а может быть и быстрее, т.к. все в одной карте.
5. Дальше идет 4090 48Gb. Слышал я, что не новую можно взять за 150к, но уверенности нет.
Да, этот чертов нумерованный список - это моя идея, иногда нумерация хороша, ни одна нервосеть не пострадала )))
Софт
Лично я запускаю модели на собранной вручную с кучей оптимизаций llama.cpp. Но для обычных людей на первое время подойдет и lm studio, в котором вы будете ставить модели одним кликом. Вообще, для запуска моделей есть куча софта, так что гуглите.
В качестве агента я использую opencode. В конфиге можно прописать использование локального провайдера. Но есть куча других - claude code, cursor, ... Погуглите - они каждый обновляются. Есть openclaw.ai - это твой домашний робот для компа.
Модели
Добрались до самого важного. Все эти агенты и студии не будут работать без моделей, а модели все очень разные. Давайте разберемся.
Параметры
Итак, у моделей есть основной параметр - количество параметров. Параметры - это веса в матрице. Входящие "токены" преобразуются в большие и красивые вектора, умножаются на матрицу слоев - на параметры, выбирается путь в определенных пределах, т.е. совокупность "сработавших" параметров на входящую последовательность. Получается новый вектор, и дальше он идет по слоям, превращаясь в ответ. Вся магия в том, что на основании входящих слов генерируется продолжение, т.е. то, что должно следовать за твоими словами из промпта. И чем больше этих параметров, тем шире поле возможностей нейросети. "Осмысленную" генерацию продолжений получили уже на нескольких лярдах, а сейчас триллионы параметров, при том математика тоже из простого перемножения и сигмойда несколько усложнилась - можете почитать что-то про трансформеры, которые в настоящее время вроде как лидируют по уровню осмысленности ответов.
Слои
Помимо параметров есть слои. Фактически они разделяются на несколько групп - слои внимания и слои связанности. Сначала идут слои синтаксиса и грамматики, все они пытаются определить первичные связи между словами. Дальше идут блоки семантики, которые улавливают смысл сказанного в том объеме, на которое способна сеть, дальше слои финальных определений и поиска следующих слов, которые нужно сгенерировать. Т.е. нейросеть продолжает то, что ты сказал, ну или то, что агент выдал ему из командной строки после запуска команды.
Ну и чем больше параметров, тем больше слоев, а чем больше слоев, тем более правильные слова подберет сеть для продолжения диалога. Ну или кода.
Токены
Токены - это преобразованные несколько букв/цифр/... - знаков - в числа. У модели есть хранилища токенов - большие json-файлы (или вообще txt), в них совокупность символов связана с токеном. Библиотека ИИ открывает этот файл и сопоставляет твои "блаблабла" с токеном(ами), возвращая какое-нить ["1234567", "6155241", .....]. В итоге в ходе некой дополнительной магии у тебя появляется вектор, который можно умножить на матрицы в модели. И слово превращается не просто в вектор токенов, а в большой красивый вектор с кучей пространств, отмечая свой вес в каждом из них. Т.е. вектор определяет положение слова в множестве пространств (живое/неживое, форма, цвет, ... - как игра в угадайку с да/нет, только "да" и "нет" тут размазаны в пространстве [0..1.0]. Типа цвет немного зеленый и синий, чуть фиолетового, ....)
В общем, размерность этих пространств легко переваливает за 10к, т.е. на каждое слово может получиться массив из 10к+ циферок. Вот они и будут в итоге умножаться на матрицы слоев.
Точность
Модели хранят веса с определенной точностью. Есть точность FP32, где FP - это float point, т.е. числа с плавающей запятой, 32 - это биты. Т.е. на 1Т параметров нужно 4Тб памяти. Есть FB16 - это почти FP16, но количество бит мантиссы и экспоненты отличается от FP16. Гугл это придумала для весов сетей. Но все еще для 1Т сетки нужны нереальные 2Тб памяти.
Квантизация
Хитрые людишки осознали, что 16 бит на вес - это очень много и можно ужаться. В принципе, при большом количестве параметров точность веса нивелируется объемом сети. Поэтому веса начали ужимать до 8 бит, а потом и до одного - до того самого да/нет. Скажем так, при восьми битах теряются доли процента, при шести все еще доли, но уже ощутимые, а при четырех уже единицы. Модель может начать ошибаться в похоже написанных словах (похожие переменные путать, например). Как защититься? Ну не называйте переменные похоже )))
Где искать модели?
Есть Hugging Face - сайт с моделями, датасетами и прочим. Ищите там. Читайте описания, пробуйте. Но перед этим прокачайте железяги.
Что и как удалось сделать с помощью локального ИИ
Итак, переходим к самому важному, иначе зачем эта статья вообще была бы нужна.
Но начну с самого важного вывода: любой человек, который может хорошо сформулировать - поставить - задачу, теперь программист на любом стеке. Да, неплохо было бы понимать, что и как работает под капотом хотя бы в общих чертах, ибо модель начнет предлагать тебе постгрес и редис для домашней бухгалтерии, докер и кучу всего того, что тебе вообще ни разу не нужно, но если понимание есть, то добро пожаловать в любой стек!
Как я делал игру на котлине
На начало работы у меня была только одна карточка 5070ti, поэтому я юзал Qwen 3.5 9b q6 - она с горем пополам влезала в память моей видеокарты и давала стабильные 120 т/с, т.к. это плотная сетка без MOE-слоев. И она с привеликим трудом смогла собрать мне приложение с пустым активити.
Я скачал "Qwen 3.6 35B A3E Q3" - сеть на 35 лярдов параметров с MOE, т.е. со слоями экспертов. Q3 - это квантизация до 3 бит, что позволило большую часть сетки засунуть в видеопамять. И вот тут произошел качественный сдвиг - сетка быстро и достаточно легко собрала мне первую активити с картинками.

Картинки, кстати, скачала с какого-то сайта со свободными картинками.
Дальше я начал думать, что с ними делать. Сначала придумал раскраску, но быстро понял, что картинки не те. В итоге пришла в голову идея пятнашек - я любил в нее в детстве играть.
Поняв, что частичный инференс на видеокарте и CPU - это 20 т/с, которое мне показалось сильно медленным (после 120 на плотной модели, которая влезла в память видеокарты целиком), я решил купить вторую карту. Ну и до кучи к ней мать и корпус. Даже не спрашивайте, сколько это стоило - много. Сижу на гречке. Зато счастливый )))
Если вернуться к смой игре и именно процессу разработки, то дело было так (и да, опять нумерованный список):
1. Основной промпт - создать приложение с пустой активити. Начала делать 9b, у нее это получилось с большим трудом. Но она нашла или скачала мне нужные пакеты для сборки. Т.е. сама все нашла, скачала и описала, где брать и куда класть. На выходе приложуха с белым экраном. Ну может быт ьтам был хеллоу ворлд - не помню уже.
2. Добавить на нее картинки в сетке 2х8. Это уже 35b q3 на видеокарте + CPU с 20-ю токенами в секунду.
3. Добавить кнопку закрытия. С этим прям борьба была, пока она не сделала мне красивую оранжевую кнопочку с закругленными углами.
4. Добавить активити с паззлом. Тут уламывать пришлось несколько сессий. Но в итоге подвезли вторую карту и работа пошла веселее. Если вы умеете уламывать сговорчивых дамочек с поверхностным знанием js - точно справитесь )))
5. Убрать рамки, сделать приложение полноэкранным. Мгновенно без вообще проблем.
6. Добавить кнопку закрытия на активити паззла. Очень долго объяснял, что мне нужна ровно такая же кнопка, как на основной.
7. Несколько сессий рефакторинга с переработкой на MVC. Пару раз все сломалось, но модель все починила.
8. Добавил музыку. При том и промпт, и музыку нагенерили локально запускаемые нервосети. Промпт для музыки сделал прямо не выходя из кода, а музыка сгенерирована моделью ACE Step. И добавление в приложение этой музыки заняло минуту.
Ну и для каждого шага просил реализовать, собрать, установить на устройство и остановиться. Дальше тестил, сообщал о проблемах, если были, просил продолжить, если проблем нет или они были решены.

Дальше было несколько сессий для фич: звук кнопок, счетчик ходов, секундомер. В итоге выложил на рустор. Напишите в комментах, работает ли оно у вас на девайсе. А то приятель один написал, что на его хоноре паззл не тапается. Для этого в последней версии я попросил ИИ написать отображение состояния. В него можно переключиться при долгом тапе на любом участке паззла.
В итоге собранное приложение с 16-ю картинками и музыкой получилось уместить в APK меньше 5 Мб.
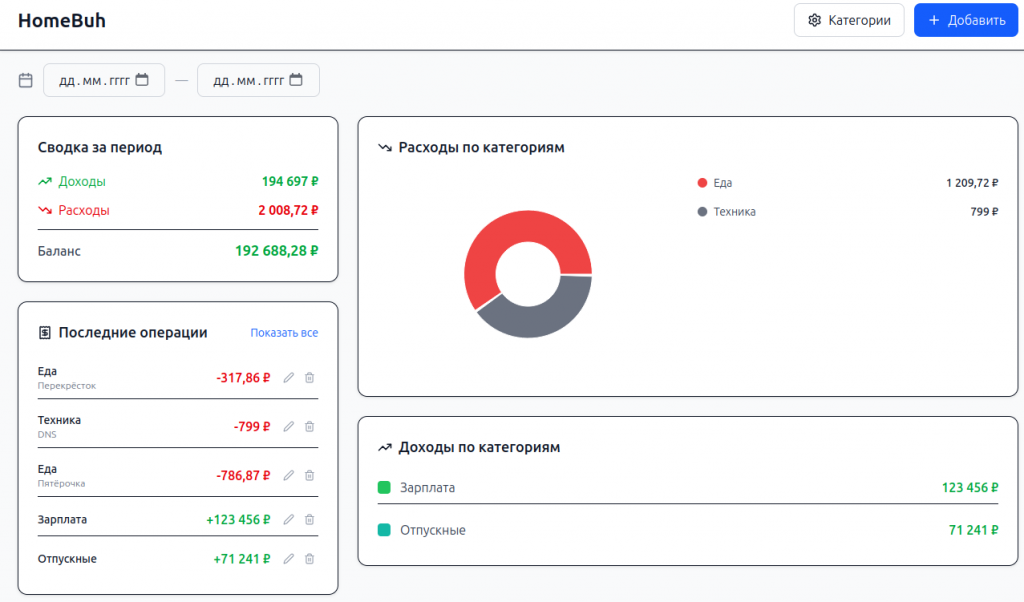
Домашняя бухгалтерия
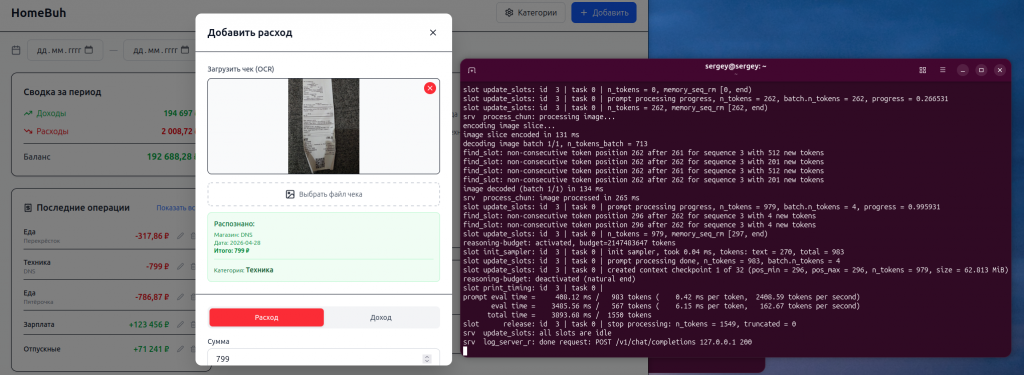
Ну ладно, игры на котлине - это хорошо, но у нас тут бухалтерский сайт. А у меня давно была задумка сделать систему, которая просто с отправленных ей в телеге (или чем там ща отправляют) фоток чеков зафиксирует расходы. Для этого пришлось разобраться, как заставить модель видеть фотки. Оказалось, что нужна еще одна модель - проектор. В llama.cpp есть соответствующий параметр для запуска такого вот проектора.
И здесь модель запилила приложение за две сесии. В первой сессии она сделала фронт и бэк, во второй сессии добавила правку категорий и транзакций, написала промпт для нейросети на распознавание чека и заполнение полей транзакции из чека. Планирую добавить загрузку чеков из галереи смартфона. Осталось заставить себя фоткать чеки.
Заключение
Да, мир изменился. И да, даже на локальном компе, доступном с зарплатой современного программиста, можно вайбкодить, при том достаточно интересные штуки.
И, к сожалению для 1С, похоже подходит ее время, т.к. модели уже в состоянии переписать весь этот код всяких там ЕРП и УХ на более производительный стек. Да, программист тут нужен, но не как писатель кода, а как контроллер процесса. И сдается мне, что займет процесс переноса ЕРП в части используемых в организации модулей условную неделю. Может быть я тут излишне оптимистичен, но лет через 10 это будет происходить вообще за минуты.
Вступайте в нашу телеграмм-группу Инфостарт