Когда нужно расшифровать рабочую встречу, переговоры с клиентом или запись судебного заседания, первый вариант обычно очевиден: загрузить файл в облачный сервис и получить текст.
Но не всегда это возможно. В записи могут быть персональные данные, детали работы клиента, финансовая информация, коммерческие условия или просто разговор, который не хочется передавать во внешний сервис. При этом вручную расшифровывать 30–40 минут аудио — это уже отдельная задача на несколько часов.
Я решил проверить, можно ли собрать локальный инструмент расшифровки на обычной Винде: без отправки аудио в облако, с нормальной скоростью и с качеством, достаточным для подготовки рабочего черновика.
Сразу скажу главный вывод: можно. Но Whisper сам по себе не делает готовый протокол встречи. Он хорошо создаёт основу, а дальше начинаются термины, контекст, ошибки распознавания и необходимость проверки человеком.
В моём случае важна была не только скорость. Аудиозаписи могли содержать информацию о процессах клиента, документах, договорённостях и проблемах, которые обсуждаются на встречах. Передавать такие записи во внешний сервис без отдельной договорённости было бы неправильно.
В итоге ТЗ для самого себя получилось спартанским: аудио должно оставаться на локальной машине, на выходе — обычный TXT и JSON с таймкодами. Транскрибация не должна крутиться часами — скорость критична. И всё это должно подниматься на коленке, без разворачивания тяжёлой серверной инфраструктуры.
В качестве основы я выбрал Whisper через библиотеку faster-whisper. В результате получился небольшой Python-проект.
В рабочем варианте сценарий простой:
Берём аудиофайл, запускаем локальную обработку через Whisper, получаем сырой TXT и JSON с сегментами, затем вычищаем критичные ошибки и выделяем решения, задачи и вопросы. Дальше этот черновик становится основой для протокола встречи или постановки задачи.
Сначала проект работал на CPU. Это был рабочий вариант, но ждать приходилось долго. Потом удалось запустить обработку на NVIDIA GPU через CUDA, и разница стала заметна сразу.
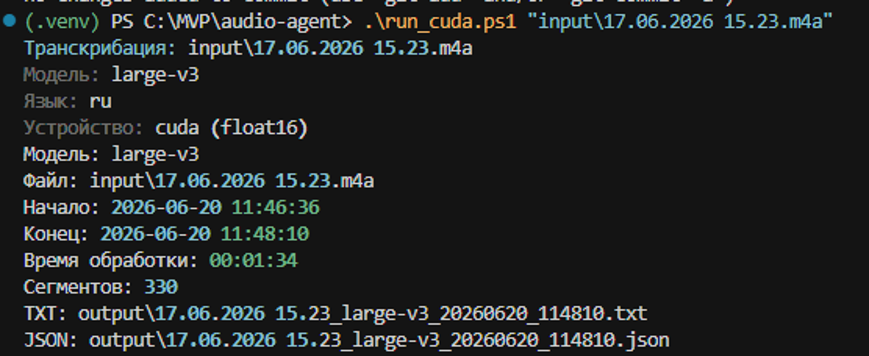
На записи длительностью около 34 минут модель medium на CPU обработала файл примерно за 38 минут. На RTX 5070 модель large-v3 обработала тот же файл за 1 минуту 47 секунд. Это не академически чистый benchmark, потому что модели разные, но практический вывод очевиден: при наличии подходящей видеокарты локальная транскрибация перестаёт быть долгой фоновой задачей.
Обработка аудиофайла на CPU
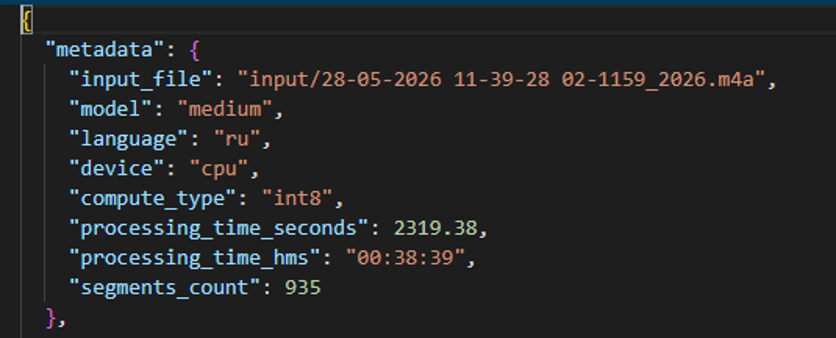
Обработка того же сценария на GPU через CUDA
Важный момент: GPU не делает текст умнее. Он просто даёт короткий цикл «запустил — проверил — поправил prompt — запустил ещё раз», а не ожидание по полчаса после каждой попытки.
Как я не потерял проект между клиентами, поездкой и аварией в квартире
Я работаю в достаточно плотном режиме: несколько клиентов, постоянные звонки, письма, срочные и несрочные задачи. В течение дня меня регулярно отвлекают, и иногда очередь задач становится довольно большой.
Поэтому ещё до первой строчки кода я решил опереться на MD-файлы. Идея простая: открыть проект после любого перерыва и сразу понять, в какой точке ты находишься, что уже сделано, какие проблемы всплыли и что делать дальше.
На практике двумя главными файлами стали README.md — чтобы быстро вспомнить, как проект запускать, — и PROGRESS.md — чтобы видеть текущее состояние, принятые решения, результаты тестов и следующие шаги.
Разработку я вёл в Cursor, а отдельные вопросы обсуждал с другим онлайн-ИИ. После каждого заметного изменения в коде, настройках или результатах тестирования я просил обновить PROGRESS.md.
В начале в этом файле было буквально три-четыре пункта. Когда MVP завёлся, в нём уже оказалось больше двадцати: подключение faster-whisper, запуск на CPU, переход на CUDA, настройки моделей, фиксы для CUDA DLL под Windows, замеры производительности, эксперименты с юридическими терминами и подготовка следующего этапа с постобработкой текста.
На словах всё это выглядит как обычная документация. Пока жизнь не вмешалась.
Я начал проект перед поездкой на дачу: создал структуру, подготовил MD-файлы и отправил проект в Git. На даче продолжил работу уже на ноутбуке без GPU, поэтому первые эксперименты запускал на CPU.
В этот же период позвонили из квартиры: мы заливали соседей. Пришлось срочно ехать, искать место подключения коммуникаций, вскрывать стену, чтобы сантехник из управляющей компании получил доступ к стояку и смог запаять трубу.
Пока ждали сантехника, созванивались с диспетчером и решали бытовые вопросы, я периодически возвращался к проекту.
Короче, полная бытовая каша. Но проект я не бросил.
Открываю PROGRESS.md — и сразу вижу, где остановился.
Не нужно заново собирать в голове, что именно я настраивал вчера, где остановился и почему принял то или иное решение. Для меня это стало подтверждением: документация в небольшом AI-проекте нужна не только «для порядка». Она помогает не потерять контекст, когда разработка идёт рывками, на разных устройствах и между десятком других рабочих и личных задач.
Для тестов я использовал аудиозапись судебного заседания. В этом процессе я защищал свои интересы самостоятельно, без юриста.
К заседанию я готовился с помощью NotebookLM: использовал его как инструмент для изучения материалов и подготовки аргументов. Аудиозапись самого заседания стала хорошим тестом для локальной транскрибации: в ней есть юридические термины, формальные формулировки, несколько участников разговора и не всегда идеальное качество звука.
Именно на таком материале хорошо видно, что результат зависит не только от выбранной модели. Нужны настройка языка, словарь терминов, дальнейшая постобработка и обязательная проверка человеком.
От протоколов встреч — к PROGRESS.md
Вообще я раньше не вёл подробные протоколы обсуждений с клиентами. Максимум — отдельные заметки, письма в почте или переписка в мессенджере.
Но мой друг Владимир Гусев, опытный разработчик 1С с большим практическим опытом, уже много лет продвигает другой подход. Именно он предложил мне написать эту статью для Инфостарта — так что за идею отдельное спасибо и привет Владимиру.
Честно говоря, раньше я относился к этому довольно спокойно и не всегда видел необходимость тратить на это время. Но по мере работы с проектами всё чаще сталкивался с ситуациями, когда к старому вопросу возвращались через полгода или год, а детали обсуждения уже никто толком не помнил.
Владимир приучил себя фиксировать ключевую моменты: кто был на встрече, какие жёсткие требования зафиксировали, к каким выводам пришли и, самое важное, почему отказались от альтернативных вариантов. Именно этот контекст — почему решили делать именно так, а не иначе — через полгода обычно вымывается из памяти.
Через полгода или год к вопросу возвращаются — и начинаются знакомые вопросы: почему выбрали именно этот вариант, кто предложил решение, что не устроило в альтернативе и о чём вообще договорились. А еще это может затрагивать вновь поставленные задачи.
Нормальный протокол или хотя бы структурированные тезисы позволяют быстро восстановить ограничения, логику решения и учтённые риски. Он нужен не для того, чтобы потом «доказывать, кто прав», а чтобы не спорить на базе разъехавшихся воспоминаний.
PROGRESS.md стал для меня прямым переносом этой практики в разработку. В нём остаётся история технических решений: что уже сделано, какие настройки проверены, что не сработало, какие результаты получены и что делать дальше.
Когда разработка постоянно прерывается звонками, другими задачами, поездками и бытовыми вопросами, такой файл избавляет от попыток вспомнить всё с нуля.
Важный телефонный разговор быстро теряет ценность, если его результат нигде не зафиксирован — хотя бы коротким письмом, задачей или протоколом.
В PROGRESS.md я руками поправил только несколько фраз. Остальное Cursor вносил по моей просьбе после очередной доработки или теста.
Проблема с CUDA под Windows
После переход на GPU появилась проблема. После установки CUDA-зависимостей faster-whisper не всегда видел нужные DLL-библиотеки из виртуального окружения. Обычный запуск Python мог завершиться ошибкой вида:
cublas64_12.dll is not found
То есть CUDA-библиотеки были установлены, но Windows не находила их при запуске.
Я не стал вручную копировать DLL-файлы по папкам. Вместо этого сделал отдельный PowerShell-скрипт запуска: он добавляет каталоги cublas и cudnn из .venv в переменную окружения PATH, а затем запускает проект. Дополнительно добавил обработку путей к DLL в коде, но на практике launcher оказался надёжнее.
Для меня здесь был важен сам подход. Я описал ошибку и структуру проекта AI-помощнику, получил варианты причин, последовательно проверил их и закрепил рабочее решение в проекте. Не нужно было быть специалистом по CUDA или неделями искать ответ на форумах.
Конечно, AI не «починил всё сам»: нужно было запускать команды, смотреть ошибки и проверять результат. Но он сильно сократил путь от непонятного сообщения cublas64_12.dll is not found до рабочего запуска на GPU.
Проверка на реальной рабочей встрече
После того как основной пайплайн заработал, я проверил его на обычной рабочей записи.
У меня была запись встречи с клиентом продолжительностью около 26 минут. Запись обсуждения я записал на обычный диктофон в смартфоне. Обсуждали работу с маркировкой в «Честном Знаке»: получение кодов, приёмку товара, сверку нескольких тысяч кодов, Excel-файлы, коробки, импорт, ГТД, возможную интеграцию с 1С и ЭДО.
Это была обычная живая, не студийная запись, вовремя беседы мы перемещались из офиса на склад. Собеседники перебивали друг друга, использовали сокращения и профессиональные термины, иногда уходили в детали, а потом возвращались к основной теме. Именно на таких записях и становится понятно, пригодна ли транскрибация в реальной работе.
По практической оценке, сохранность общего смысла составила примерно 88–90%, а без прослушивания исходника читается около 80% фраз. Это не классический WER (коэффициент ошибок в словах): для него нужна эталонная ручная расшифровка. Здесь я оцениваю не каждую букву, а то, можно ли по тексту восстановить ход обсуждения и принятые решения.
Именно инженерная боль в расшифровке была видна сразу:
— нужно сверить несколько тысяч кодов маркировки и не утонуть в ручной проверке;
— нужно быстро найти конкретный код среди реестров и понять, в какой коробке он лежит;
— нужно автоматизировать поиск в Excel, а не копировать куски длинного кода руками.
Из того же текста понятен и контекст: почему для приёмки используется Excel, какие сложности создают ГТД и импортный товар и почему пока решили остаться в личном кабинете «Честного Знака», а не тащить процесс в 1С и ЭДО.
Итог встречи читается достаточно ясно: основная проблема — поиск и сверка кодов среди тысяч позиций, а первым кандидатом на автоматизацию является поиск кода в Excel и его привязка к конкретной коробке.
Для меня это важный вывод. Расшифровка не заменила полноценный протокол встречи, но позволила быстро восстановить ход обсуждения и не потерять важные решения. А дальше из такого черновика уже можно собрать нормальный итог встречи, задачу в 1С или техническое задание.
Разделение по собеседникам
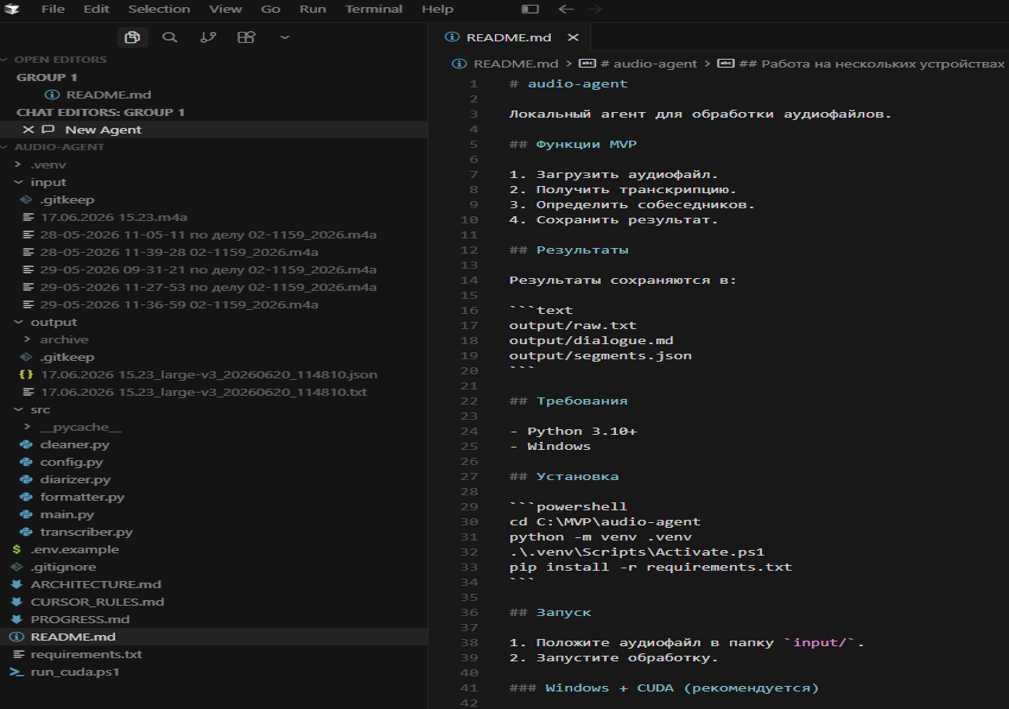
На скриншоте структуры проекта можно увидеть файл diarizer.py. Пока это заготовка для следующего этапа — в текущий MVP разделение по голосам не вошло.
Сейчас Whisper формирует текст и JSON-сегменты с таймкодами, но без указания участников разговора. Для восстановления смысла встречи этого достаточно, но для полноценного протокола хотелось бы получать диалог в формате:
Клиент: ...
Разработчик: ...
Следующий этап проекта — подключить диаризацию и сопоставить её результаты с сегментами Whisper. Рассматриваю готовые решения, например pyannote.audio.
Пока эту функцию реализованной не считаю: её ещё нужно проверить на реальных записях с перебиваниями, разным качеством звука и несколькими участниками разговора.
Исходный код проекта
Код, инструкция по запуску и текущий PROGRESS.md опубликованы в GitVerse:
https://gitverse.ru/sarus/audio-agent
В репозитории лежит рабочий MVP локальной транскрибации: запуск Whisper через faster-whisper, работа на CPU и CUDA, сохранение результатов в TXT и JSON, а также заготовки для следующих этапов — постобработки текста и разделения собеседников.
Вступайте в нашу телеграмм-группу Инфостарт