Эта статья про расширения. Буду описывать не просто какую-то теорию, а именно то, что связано с реальной практикой сотен клиентов РКЛ нашего отдела.
Если не хотите читать МНОГОБУКВ, то можете перейти к краткой выжимке.
Главная проблема HighLoad
-
Узкое технологическое окно
-
Необходимо успеть применить все изменения
Добавление нового реквизита в расширение в заимствованный объект
-
В СУБД:
-
создается новая таблица с тем же именем + «x1» с новым полем
-
-
Также весь объект со всеми табличными частями переносится в новые таблицы ИмяТаблицы+«x1». Происходит реструктуризация базы данных.

Аналогичный перенос всего объекта в новые таблицы ИмяТаблицы+«x1»:
-
Добавление нового реквизита в табличную часть в расширении
-
Добавление абсолютно не связанной табличной части в расширении
Добавление ЕЩЕ нового реквизита в расширение 2, расширение 3 и т.д. в уже заимствованный объект в расширении 1
-
Новое поле добавляется в уже «Расширенную» таблицу «x1»
Обслуживание таблиц СУБД
-
DBA/Администраторы используют скрипты обслуживания со статичными именами таблиц. Например, расчет статистик.
-
Неактуальная статистика приведет к падению производительности по расширенным таблицам.
-
1С-программистам необходимо сообщать про структурные изменения в расширениях DBA/Администраторам:
-
когда релиз
-
какие таблицы изменяются
-
-
Изменить скрипты со статичных имен «на равно» на «СНачала» («x1» не будет мешать)
-
Изменить скрипты со статичных имен на динамическое вычисление - опираться на количество строк, количество измененных строк
Индексы
-
Индексы хранятся на основной пустой таблице и на расширенной таблице «x1»
-
Можно индексировать у НОВОГО реквизита в расширении. Индекс только в «x1»
-
У заимствованных реквизитов свойство «индексировать» нельзя
Дополнительные индексы
-
В расширении нельзя создать дополнительные индексы – нет команды
-
В основной конфигурации нет добавленных реквизитов из расширения
Новые объекты в расширении
Пустая конфигурация
-
Добавляем:
-
Новый непериодический не подчиненный Регистр сведений (+1 таблица)
-
Новый регистр накопления (остатки) с 1 регистратором (+3 таблицы)
-
Новый справочник (+1 таблица)
-
Новый документ (+1 таблица)
-
-
Создает столько таблиц сколько хранится для соответствующего объекта + 4 по Истории данных DataHistory для расширяемых таблиц (кроме регистра накопления)
ERP типовая 2.5.25
-
Добавляем:
-
Новый непериодический не подчиненный Регистр сведений (+1 таблица)
-
Новый регистр накопления (остатки) с 1 регистратором (+3 таблицы)
-
Новый справочник (+135 таблиц!)
-
Новый документ (+257 таблиц!)
-
-
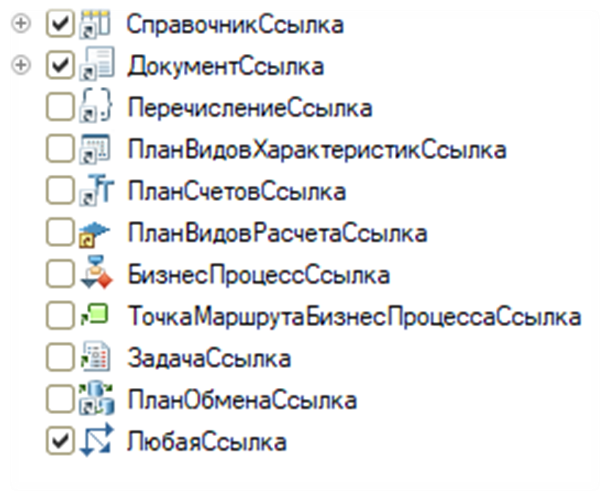
Очень большая реструктуризация для справочников и документов из-за использующихся в типовой конфигурации СправочникСсылка, ДокументСсылка, ЛюбаяСсылка.
Защита от «неожиданной» долгой реструктуризации
-
Непосредственно удалить нельзя
-
Отключить расширение. Потом удаление. Обратная реструктуризация в момент удаления.
-
Права
-
Отдельное право «Администрирование расширений конфигурации» – работает отдельно от «Полные права»
-
Разделение контуров: прода, подготовительного, тестового, разработки https://its.1c.ru/db/metod8dev#content:5905:hdoc
-
Оптимизированный механизм реструктуризации (вер. 2)
-
Важно понимать: применилась реструктуризация по максимально быстрой 2-й версии или 1-й.
-
Условия срабатывания не описаны на ИТС. Однако, можно узнать по итогу на тестовом стенде сработала 2я версия по ТЖ или нет. Для этого Настраиваем ТЖ с настройкой.
-
В ТЖ должны появляться каталоги Java + PID и строки Тех журнала с событиями SYSTEM и компонентом dmf.
-
Если Реструктуризация прошла по версии 2, а время еще не удовлетворяет, то стоит задуматься по подходам разделения изменений или пересмотру архитектуры релиза.
-
По практике крайне мало, когда система реструктуризирует структурные изменения по вер. 2. А значит, надо готовиться к длительной реструктуризации
«Добавленное не расширить»
-
Добавленный новый объект или метод в расширении 1 нельзя расширить в расширении 2.
-
При хотфиксах придется дорабатывать в этом же расширении. Динамическое обновление расширения. Все последствия динамического обновления. Потребуется время ремонта базы или отката на резервную копию.
-
Добавление нового – накладывает необходимость вносить даже хотфиксы в монопольном режиме.
-
Практика исправлений расширения – только в новом расширении. После релиза – перенести. Исправления расширения в новом расширении – нет зарегистрированных проблем, аналогично динамическому обновлению в этом же расширении.
Назначения
-
Порядок применения нескольких расширений https://its.1c.ru/db/v8327doc#bookmark:dev:TI000001843
-
Хотфикс. Дополнение с аннотацией ВМЕСТО закроет все аннотации Перед, После, ИзменениеИКонтроль, Вместо. Писать конечную исправленную версию кода.
Механизм копий базы данных
-
Копия БД не работает https://its.1c.ru/db/v8327doc#bookmark:dev:TI000002115
-
Механизм копий базы данных не поддерживает расширения конфигурации, расширяющие данные. В случае добавления в состав копии объектов, которые расширены таким образом, таблицы этих объектов будут проигнорированы механизмом. Запросы, использующие таблицы с расширением данных, не могут быть выполнены на копии базы данных.

Главная проблема всего Highload – это узкое технологическое окно, когда бизнес не дает возможности неделями обновляться, применять релизы, обслуживать наши базы или накатывать какие-то патчи. То есть, у нас всегда ограниченное время - все нужно делать быстро.
Понятно, что, когда база огромная, любое изменение может занять много времени. Но такая же беда бывает и с небольшими базами. Базы могут быть меньше, но бизнес дает СУПЕРмаленькое технологическое окно – например, минута. И за эту минуту как хочешь, так и выкручивайся, применяйся.
Поэтому вся статья будет полностью пронизана проблемой Highload – узким технологическим окном, которое дает нам бизнес для применения изменений и обслуживания нашей базы.
Механизм структурных изменений в СУБД
Перейдем к расширениям. Сейчас все больше и больше встречается не просто использование расширений, а даже корпоративные сборки с корпоративной платформой 1С, где структурные изменения внутри расширения, используют как стандарт. То есть изменяются и добавляются новые объекты внутри расширений.
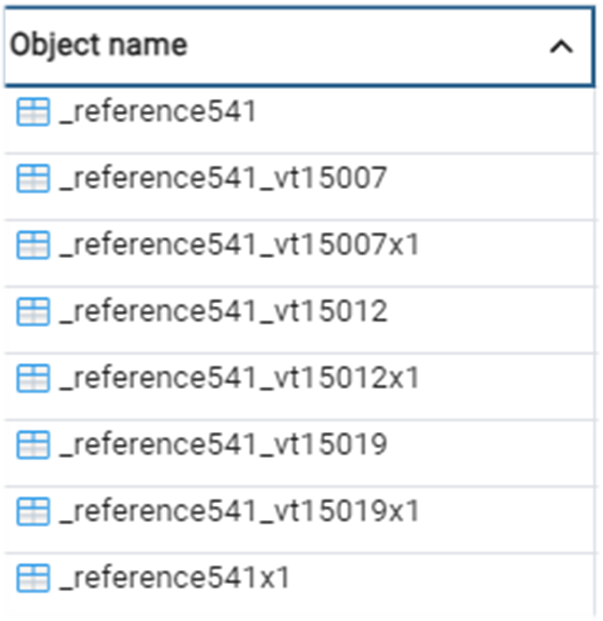
Давайте вспомним, как это вообще происходит на стороне СУБД, когда мы добавляем структурные изменения. Для этого берем какой-нибудь типовой справочник. Допустим, номенклатуру. Заимствуем наш объект в расширение и добавляем новый реквизит.
Мы обсуждали это и опрашивали коллег сообщества – но большинство отвечают неправильно, хотя ответ простой. Поэтому давайте окончательно зафиксируем, как будут храниться все наши изменения при добавленном реквизите в расширение у заимствованного объекта.

Создается новая табличка, где добавляются структурные изменения нашего нового поля, и после этого переносятся все данные из старой таблички в новую.
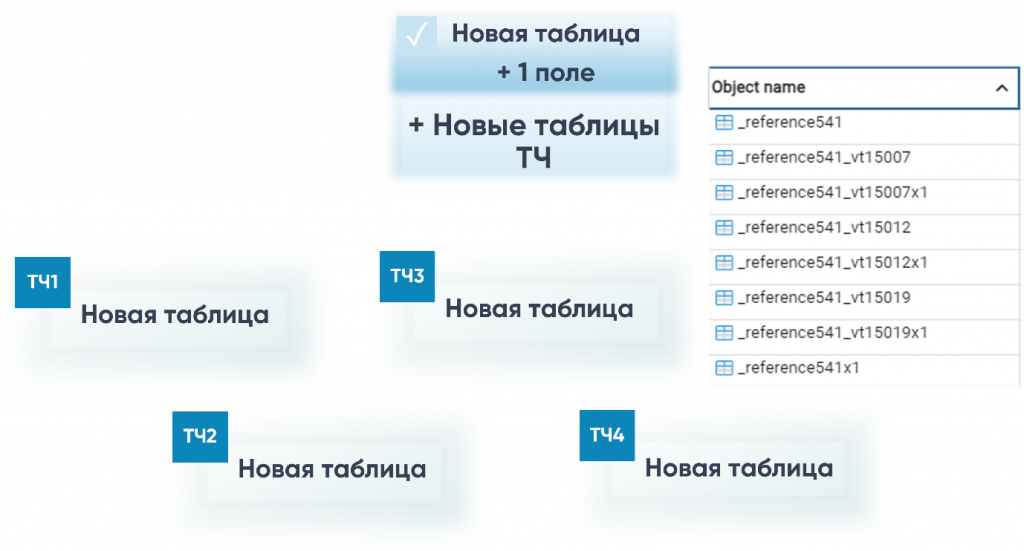
Третий вариант правильный: у нас создается новая табличка, и все структурные изменения на СУБД переходят в нашу новую табличку. Но есть некоторые особенности. Если вдруг у нашего объекта есть свои табличные части, они тоже переедут. Для справочника это могут быть какие-нибудь стандартные дополнительные реквизиты. И все те данные, которые хранились в основной конфигурации, будут переезжать в новые таблички.
Для документов эта особенность на Highload еще более актуальна, потому что у документов стереотипно встречаются большие табличные части. А в новых платформах разработчикам дали возможность увеличивать табличные части: максимум уже не 99 999 строк в таблице, а миллиард минус одна строка. Тем самым все табличные части документа с миллиардом строк будут переезжать из старой таблички в новую. Это необходимо учитывать.
При этом, старый нейминг таблицы останется. На примере справочника (reference) на слайде показан пример: в имя таблиц просто добавится постфикс «x1» (ИмяТаблицы+«x1»).
Вы можете сейчас у себя через pgAdmin или Management Studio сделать запрос и посмотреть расширенные таблички. Ввести параметры поиска «x1» и увидеть, сколько у вас переехало на данный момент таблиц, если вы меняли структурные изменения в расширении.
Влияние нескольких расширений на один объект и проблема статического имени таблицы для администраторов БД

Какие можно сделать выводы? Если мы берем и добавляем новый реквизит в табличную часть нашей основной конфигурации, весь объект тоже переедет со всеми табличными частями и шапкой основной конфигурации, создавая все новые «x1»-таблички.
А также, если мы просто создадим независимую табличную часть в расширении для каких-то целей хранения дополнительных данных, тоже переедет весь объект. Соответственно, будет реструктуризация всего объекта с переносом всех данных из старой версии таблички в новую версию.
Это надо закладывать - на тестах замерять непосредственно этот переезд, соизмерять на тех же аппаратных компьютерах, серверах, чтобы мы влезали в наше технологическое окно.
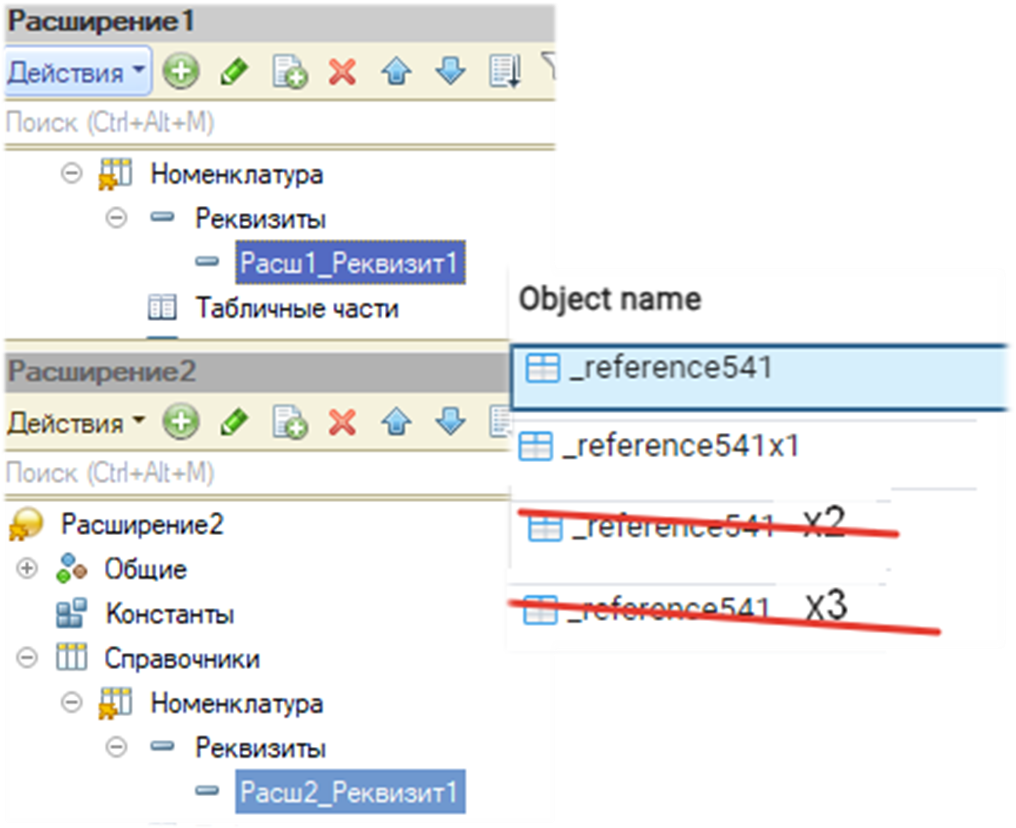
А что будет, если мы будем добавлять во второе, в третье расширение при наличии первого расширения, которое изменяет наш справочник? Мы добавляем второе расширение и там добавляем еще один реквизит номенклатуры.

Или в той же табличке, в которую мы уже переехали, будут создаваться новые структурные изменения.
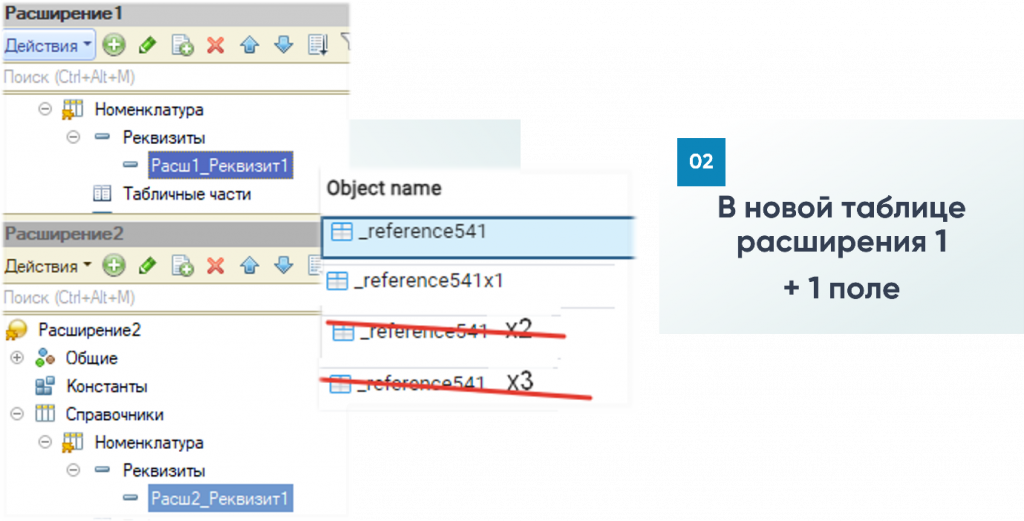
Правильный вариант тоже последний. Не будет создаваться никаких x2, x3 и тому подобного. Всегда будет x1 и один переезд. Если мы меняем тот объект, который уже структурно изменили - будет один переезд. Поэтому, сколько бы мы расширений ни создавали, новых табличек дополнительно создаваться не будет, если мы расширяем тот же самый объект, который уже структурно изменяли.

Давайте зафиксируем всю информацию. Если были таблички (наш справочник) и мы добавляем структурные изменения, они переезжают в новые таблички. При этом в старой табличке будет пустое количество строк – ноль строк. А в новой табличке будут все те строки, которые мы непосредственно закодили в наших расширениях, сколько бы их ни было. С одним только постфиксом x1. То есть нейминг тот же плюс x1.
Это означает, что, кроме того, что после реструктуризации мы должны влезть в наше технологическое окно, дополнительно у нас меняется нейминг самой таблицы -изменяется наименование таблицы с данными. А у нас в Highload ДБАшники, админы на больших сборках уже не используют и не работают с конкретными простыми расчетами статистики. У нас уже особенные скрипты, где выделяются отдельные таблички. А тут табличка меняется, и мы будем рассчитывать скрипты по пустой табличке. Это может понизить производительность нашей системы. Если есть метрики, мы это заметим, но не сразу. И при этом, будут страдать непосредственно пользователи нашей системы.
Что делать? Первый, самый простой вариант: 1Сникам начать разговаривать с ДБАшниками, с админами и говорить, что в этом релизе мы будем менять. Нужно понимать, какие таблички будут переезжать, и передавать им новые имена таблиц, которые будут использоваться после переезда при структурном изменении.
Второй вариант – не использовать статичные имена таблиц в скриптах, а использовать, допустим, начало имени. Так как начало у нас не меняется, а x1 просто добавляется, ничего не поменяется. Можно просто в скриптах поменять логику на поиск по началу имени.
И третий вариант – вообще не использовать статичные нейминги в наших скриптах, а опираться на другие параметры: не имя таблиц, а, например, количество строк в этой таблице либо количество измененных строк.
Особенности работы с индексами и дополнительные индексы в расширениях конфигурации
Теперь поговорим про следующий важный инструмент, который точно в статье надо упомянуть. Это индексы.

При структурных изменениях в расширении в таблицах будут храниться индексы как на старой табличке, так и на новой. И в обычной, и в x1-таблице будут индексы, которые непосредственно созданы самой платформой.
Также, если мы в расширение добавляем новый реквизит, у нас есть возможность его индексировать стандартным методом: поставить у этого реквизита, «Индексировать» или «Индексировать с ДопУпорядочиванием».
Но при этом, мы не можем просто взять, заимствовать какой-то реквизит номенклатуры в расширение и проиндексировать его стандартным методом. То есть нет возможности поменять это свойство. Соответственно, мы можем индексировать стандартным методом только новые поля, добавленные в расширение. При этом индекс создастся только на табличке x1 того расширения, в котором мы внесли изменения.

Следующий этап индексов – это уже дополнительные индексы. Для корпоративных платформ у нас есть возможность создавать дополнительные индексы. Это крутое нововведение. Надеюсь, уже все начали использовать, потому что, думаю, за этим большое будущее.
Мы разработчики можем сами определять все те поля, которые будут индексироваться, а также включаться в кортеж нашего индекса. Не по правилам, которые нам заложила платформа 1С, а именно прикладной разработчик решает какие поля индексировать и включать в индекс.
Что с доп индексами у нас в расширении? А такой команды по дополнительным индексам в расширении вообще нет. То есть на данный момент, на данной версии платформы, нет возможности в расширении проиндексировать через дополнительные индексы наши поля внутри расширения – ни заимствованные реквизиты, ни наши новые. Доступно индексировать только стандартным методом.
При этом, конечно же, в основной конфигурации у нас никто не отобрал видимость команды по дополнительному индексированию нашего объекта. Но все те реквизиты, которые мы добавили в расширение, видны не будут. Их нельзя будет добавить в поля кортежа нашего дополнительного индекса.
То есть, если мы добавили в расширении в номенклатуру, например, новый реквизит «категория маркетплейса», эта «категория маркетплейса» не будет видна, и не будет возможности проиндексировать в дополнительных индексах основной конфигурации по данному полю. Подобные реквизитыы невидимы для дополнительных индексов.
Соответственно, все структурные изменения в расширении в дополнительных индексах не участвуют. Такое ограничение есть, и это надо понимать.
Создание новых объектов в расширении: неожиданный рост количества таблиц в типовых конфигурациях
Теперь посмотрим на ситуацию, когда мы создаем абсолютно новые объекты в расширении. Это частый случай - ЭДОшки, маркетплейсы и другие поставляемые продукты очень часто добавляют новые справочники и др. метаданные.
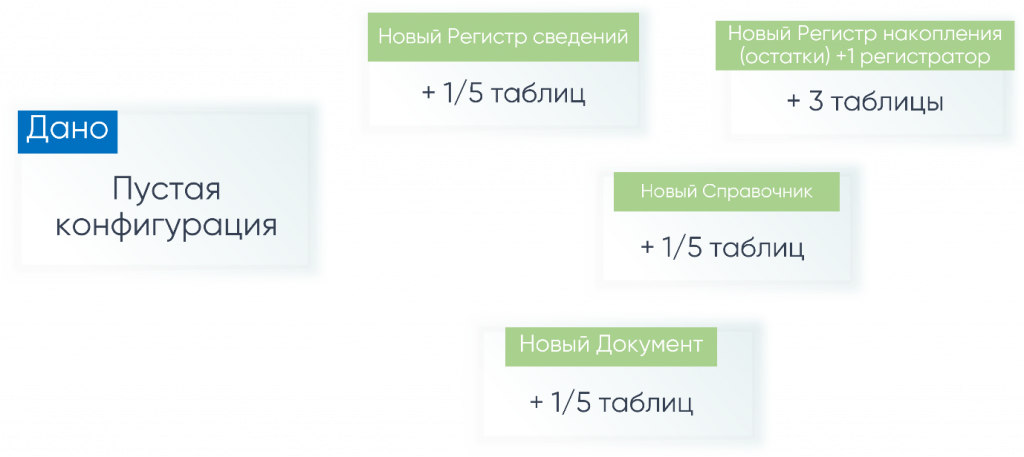
Что же там происходит? Для простоты рассмотрим вырожденный пример. Берем абсолютно пустую конфигурацию. В этой абсолютно пустой конфигурации через расширение добавляем регистр сведений - неподчиненный, непериодический, максимально простой. Добавляем его именно в расширение.
При применении внутри расширения данного изменения создастся одна табличка. На картинке написано еще пять, чуть ниже про это расскажу. Создается одна табличка самого регистра – то, как хранится регистр с x1.
Создаем регистр накопления с одним регистратором, остатковый. Создастся три таблички – так же, как у нас платформа обычно хранит регистры накопления в основной конфигурации.
Создаем справочник – тоже одна табличка.
Создаем документ – одна табличка.
То есть все, что бы мы ни создавали в расширении, ожидаемо, как и в обычной основной конфигурации, будут создаваться те же самые таблички с тем же самым началом нейминга для типа, который мы создаем. Все шикарно, все отлично.
Вернемся к «5» таблицам. При первом применении структурного изменения объекта – допустим, в данном случае регистра, справочника или документа – создается четыре дополнительных таблички по истории изменений данных, где будет храниться вся история наших расширяемых структурных изменений. Создастся только при первых структурных изменениях в расширении.
Если мы первым делом добавили справочник - добавятся пять таблиц. Добавили потом документ – только одна табличка добавилась.
Но никто на пустой конфигурации специально не программирует, это крайне редкий случай. Поэтому берем, конечно же, типовую флагманскую конфигурацию. Свежайшую ERP 2.5.25.
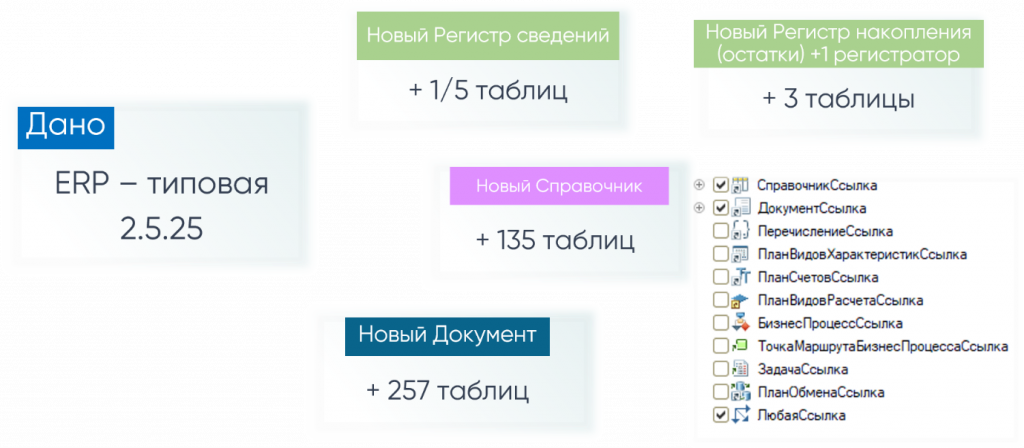
Добавляем регистр сведений – то же самое, одна или пять новых таблиц (далее не повторяемся). Добавляем наш регистр накоплений – тоже три штуки. То есть все так, как ожидали в пустой конфигурации.
Добавляем справочник – плюс 135 таблиц! Плюс 135 таблиц!
Добавляем документ в типовую конфигурацию ERP через расширение – плюс 257 таблиц.
То есть при добавлении нового справочника или документа мы получаем плюс сотни новых таблиц в нашей СУБД. Абсолютно неожидаемое поведение. Кому ни рассказывал – никто не ожидает. Как будто бы этот момент в эксплуатации не анализируют.
Причем это не только создание таблица - Это реструктуризация и перенос 257 таблиц при применении этого расширения: из нашей основной конфигурации в наши новые таблички x1. Сотни таблиц. То есть длительность реструктуризации очень сильно увеличивается.
А почему это происходит? В типовых конфигурациях очень много объектов со ссылками на справочники, с обобщенными типами по справочнику, по документу и «любая ссылка». Именно из-за особенностей хранения у нас необходимо будет создавать в расширении новые таблички и делать перенос всех этих таблиц.
Поэтому надо супераккуратно добавлять расширение. Нельзя очень быстро взять, добавить какое-нибудь ЭДО и применить первое структурное изменение на конфигурации в микро техокно. Удачно это сделать просто не получится. Надо обязательно замерять и соизмерять с вашим технологическим окном.
Безопасность, удаление расширений и разделение контуров разработки

Даже на больших сборках у нас очень часто бывает полный доступ до прода. И что нам не дали возможности как-то защититься от того, чтобы у нас были большие структурные изменения? Или чтобы все таблицы, которые добавляются, могли просто так в один момент взять и исчезнуть?
Нет, конечно – есть механизмы.
При удалении у нас нет возможности сразу удалить расширение. Есть некоторая дополнительная защита: мы должны обязательно отключить расширение, а только после отключения – удалять. При этом, когда мы отключаем расширение, получается некоторая коллизия. Данные как бы есть, но к ним обращаться нельзя. То есть несколько этапов осознанности удаления всех тех изменений, которые структурно вы решили сделать. Допустим, даже временно.
При этом, когда мы удаляем расширение, и оно единственное, которое изменяло текущий объект, соответственно, будет обратная реструктуризация: из x1-таблички обратно в обычную табличку. Если мы только что добавляли документ через расширение, там будет 257 таблиц, и обратно они будут переезжать в обычные таблички. Это еще один сценарий потенциально долгой реструктуризации.
А как защититься? Для этого фирма 1С дала дополнительное право администрирования расширений конфигурации. Оно не дает возможности даже при полных правах в пользовательском режиме изменять, добавлять, удалять и вообще что-то делать с расширением. У пользователя просто нет доступа использовать стандартную обработку.
То есть надо отбирать даже у полноправных пользователей данную роль, если вы захотите защититься от случайного добавления расширения. И даже такие ситуации бывают на больших корпоративных сборках, к сожалению. Просто надо эту роль учитывать и использовать в ваших системах.
И, конечно же, есть момент, связанный с разделением контуров. Есть крутая статья https://its.1c.ru/db/metod8dev#content:5905:hdoc, она очень сложная, но по-настоящему в нее надо вчитаться и когда-то решиться «идти туда». Там расписаны все разделения контуров: продуктив, предпродуктив, тестовый контур и контур разработки с разделением ролей, где разработчик, который разрабатывает, не имеет доступа к проду и тому подобное. То есть полностью разделены контуры.
Не всегда это можно быстро и просто реализовать, но надо стремиться к такой организации инфраструктуры на больших сборках нашей информационной структуры.
Оптимизированная реструктуризация (версия 2): принципы работы и способы проверки через Технологический журнал
Когда мы говорим про реструктуризацию 1С, конечно же, сразу хочется обсудить про наш оптимизированный механизм реструктуризации.
Кратко про 1ю и 2ю версию реструктуризации.
Первая версия (v1) реструктуризации – это когда сама платформа непосредственно делает реструктуризацию данных, то есть переезд: создает новую табличку, переносит все данные и удаляет старую табличку.
А новая версия (v2) оптимизированная реструктуризация - это умный рефакторинг «без переезда». Управление отдано Java, а СУБД теперь работает как искусный хирург: меняет только то, что нужно, прямо на месте, используя гибкие команды Alter. Также она задействует как можно меньше изменений в таблицах, допустим, только ту табличную часть, которую мы изменили. Это дает кратный прирост скорости и исключает тяжелый переезд данных.
Очень важно на тестовом контуре определить, сработала ли вообще вторая версия с расширением или нет. Если не сработала, мы можем попытаться изменить что-то в наших доработках - дробить изменения объектов на порционные итерации и попытаться сделать так, чтобы она все-таки сработала.
Если вторая версия сработала, то мы получаем максимум скорости реструктуризации. Однако если мы все равно не вписываемся в технологическое окно, это сигнал, что мы уперлись в потолок текущей архитектуры. В таком случае нужно менять саму стратегию релиза: например, задействовать стороннюю базу с интеграциями, теплыми/холодными данными или снова дробить изменения на части чтобы скорость переезда была гораздо быстрее и укладывалась в ту возможность изменений, которую нам закладывает бизнес.
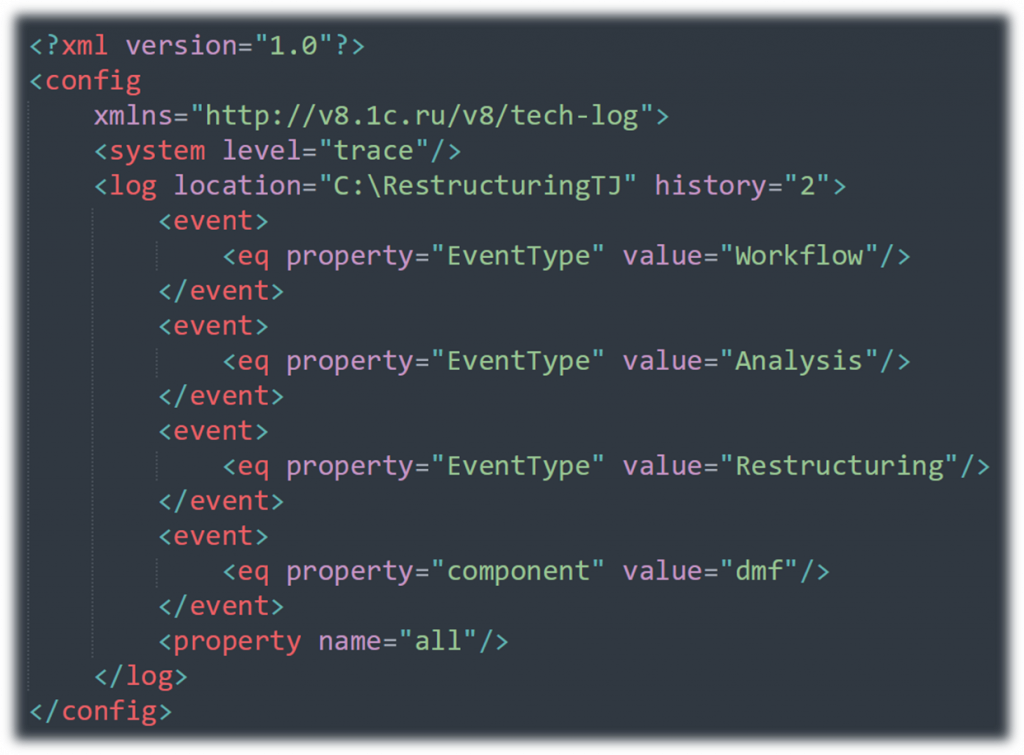
А как определить, сработала или не сработала вторая версия оптимизированной реструктуризации? Оценка производится постфактум на тестовом контуре. Для этого необходимо заранее активировать Технологический журнал и настроить фильтр на отслеживание нашего конкретного события.
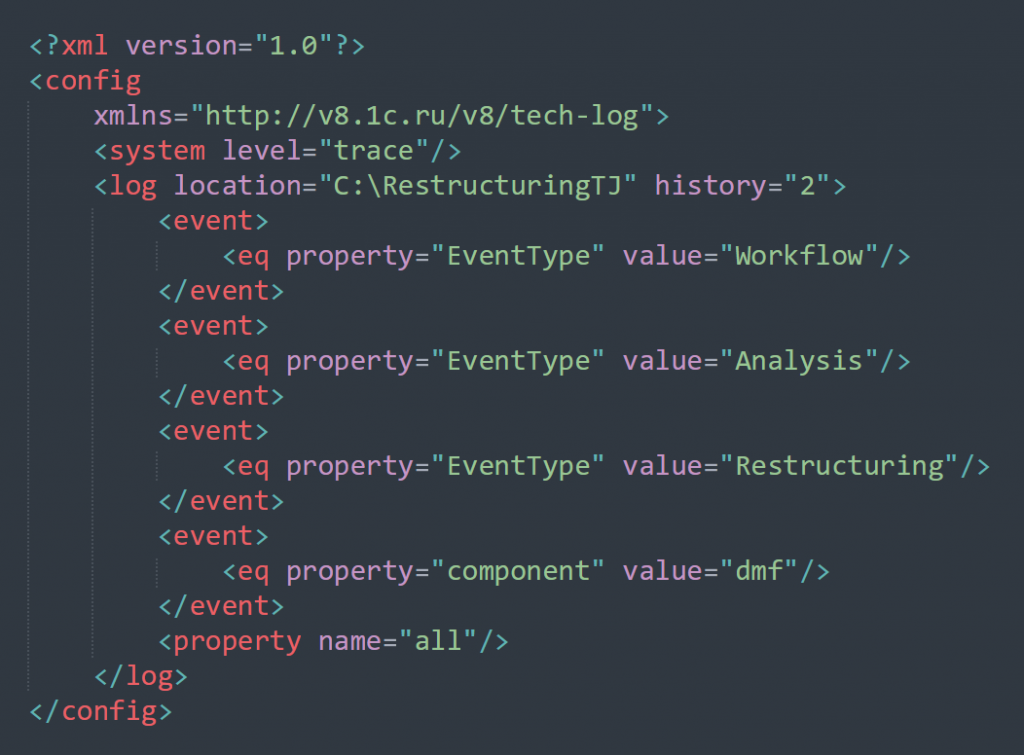
Событие, которое мы анализируем будет System с компонентом DMF.
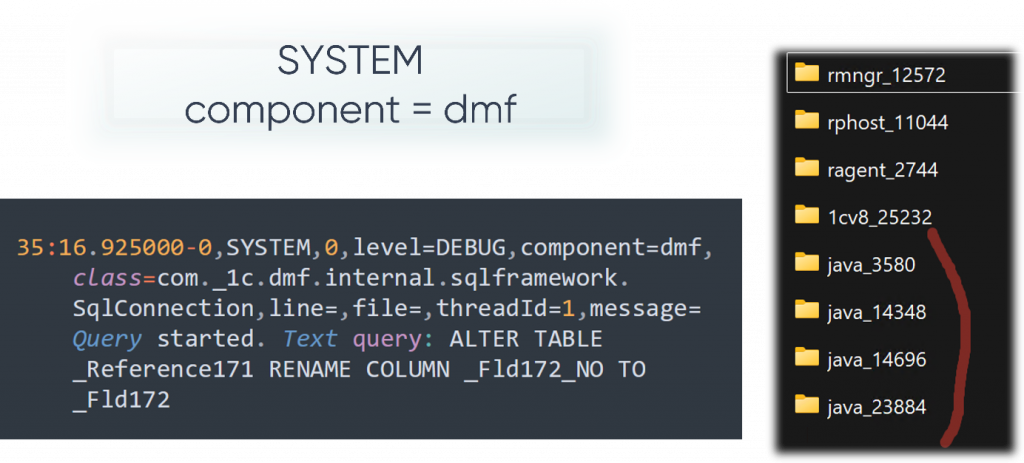
В нашей папке хранения ТЖ появится Java-каталоги с PID того процесса, который занимался реструктуризацией. Таких папок может быть несколько – сколько процессов занималось реструктуризацией. Внутри файлов с результатами мы увидим событие с Event «System» с нашим компонентом DMF. Там будут лежать разные запросы, а платформа распишет, что именно она проверила, какую таблицу поменяла, и покажет сами SQL-команды. Я, например, вывел на слайде данные по Alter Table: видно, что именно правилось и в какой таблице.
Если получили схожие данные, соответственно, вторая версия реструктуризации сработала. Если не произошло, надо пытаться менять подход к тому, что именно вы изменяете в конфигурации.
По нашей практике, к сожалению, именно у расширений оптимизированная версия реструктуризации крайне редко срабатывает. Информация на текущей релизной версии платформы. Сами условия срабатывания второй версии нигде не описаны на ИТС, но фирма 1С обещает все больше и больше расширять возможность применения второй версии, чтобы наши реструктуризации проводились все чаще в версиях платформы 8.5+.
Парадигма разработки: исправление ошибок (Hotfix) и управление приоритетом кода через аннотации
Перейдем к достаточно простой, осязаемой и понятной парадигме, которую можно вывести из работы с расширениями. Но почему-то этих выводов часто не делают.

Парадигма простая: если мы добавляем новый объект или новые функции внутри расширения, мы закрываем для себя возможность расширять их в других расширениях. Соответственно, все изменения, которые мы делаем, мы не можем заимствовать в других расширениях. И в случае каких-то Hotfix, то есть каких-нибудь изменений, патчей (ошибки делают все) придется делать их именно в том же расширении, в котором мы добавили новый объект.
А что такого? Будем в том же расширении делать, какая разница? А это, по сути, динамическое обновление. Да, оно немного по-другому ведет себя в логах в расширениях и работает на других таблицах, но по-настоящему это все равно динамическое обновление.
На ИТС написано, что такое динамическое обновление. Это обновление, если есть хотя бы какие-то работающие активные сеансы. То есть, в итоге изменение того же расширение - это динамика.
Я думаю, все знают последствия динамики для работоспособности базы, к которым она может привести. Как минимум – нет возможности зайти в конфигуратор. Как максимум – восстановление базы или переключение на реплику. Регламентные действия по восстановлению могут занять достаточно большое время, и в итоге у нас будет неожиданная для нас работа, а не кайф пользователей от тех изменений, которые мы хотели поставить в релизе.
Если мы все-таки добавили изменения в само расширение, чтобы у нас не было динамики, придется останавливать базу и монопольно применять изменения в техокно.
Допустим, мы правим не старое расширение, а все хотфиксы делаем в новом. За все время работы с самыми разными компаниями – и с корпами, и с крупными, и со средними, и с маленькими – мы еще ни разу не видели, чтобы такой подход привел к проблемам с базой, как это бывает при динамических обновлениях.
Надо что-то поправить – добавили новое расширение с изменениями этой процедуры. Еще что-то поправить – опять новое расширение этой процедуры. Сейчас мы говорим именно про Hotfix, поэтому это алгоритм для временных срочных решений – надежная заплатка, которую исправим в следующем релизе.
Однако, как всегда, существуют определенные гюансы. Когда расширений становится много, встает вопрос: какой именно код в итоге будет задействован и выполнен? Разъяснение этому дает статья на портале ИТС. В ней подробно рассказано, как на выбор исполняемого кода влияют аннотации, дата добавления каждого расширения и его назначение (исправление, адаптация или дополнение). Фактически, там описан четкий порядок, определяющий, какой код будет применяться в каждом конкретном случае.
Если мы используем частую и любимую разработчиками аннотацию «Изменение и контроль», то применить ее второй раз подряд не выйдет – она срабатывает только единожды. Чтобы задействовать ее снова, придется сначала отключить это расширение или сделать что-то другое.
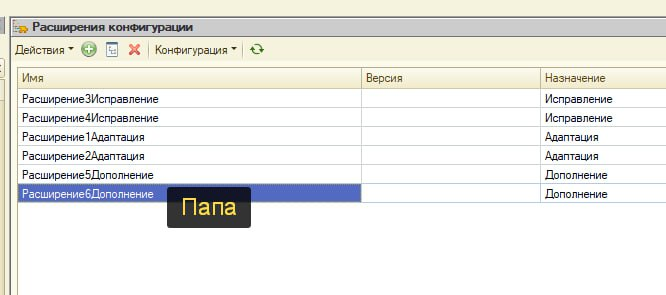
Главная беда хотфикса – время. Нет возможности выстраивать умные цепочки, тестировать все пересечения аннотаций. Нужен простой, но рабочий инструмент: «применил – и оно заработало».
Я предлагаю сделать расширение, которое всегда будет снизу (самое последнее в общем списке). Такое будет всегда как на схеме новое расширение с назначением «Дополнение» с последней версией кода и аннотацией «Вместо». Оно перебивает абсолютно все – любые «Перед», «После», «Изменение/контроль» и прочие «Вместо» сверху. Результат – разработчик может за секунду применить правку, не вникая в сложные пересечения. Быстро, надежно, без лишней головной боли.
Влияние структурных изменений в расширениях на BI-системы и аналитику
В крупных корпоративных сборках накопление данных не является самоцелью – вся собранная информация в конечном счете предназначена для предоставления другим участникам нашей инфраструктуры.
Для этого у нас используются BI-системы, механизмы копии базы данных, дата-акселераторы, 1С:Аналитика и тому подобное.
При этом следует учитывать важное ограничение: если мы структурно изменяем наши объекты в расширении, запросы к копии тех структурных объектов, которые мы структурно изменили, работать не будут https://its.1c.ru/db/v8327doc#bookmark:dev:TI000002115. И это не ошибка платформы: с момента разработки механизма копп баз данных и по сегодняшний день такая функциональность просто не поддерживается.
Надо это учитывать в инфраструктуре и применять эти знания непосредственно на практике.
Заключение
Может сложиться некоторое понимание, как будто бы: а давайте вообще не использовать никакие расширения, это какой-то непонятный, мутный механизм.
Нет, такого совета 100% нет. Расширение – суперклассный механизм, очень удобный инструмент для особенных задач. Однако мы ввели четкое ограничение в наших стандартах разработки: использование расширений запрещено для реализации структурных изменений в новых проектах и задачах по внедрению. Это правило закреплено на уровне стандартов разработки.
Но при этом, конечно же, есть случаи, когда этого избежать не получится. Сейчас куча поставщиков поставляют свои крутые модули, реально крутые, и они используют именно расширения. И на практике вам придется использовать расширения и структурные изменения в них.
Мы, как разработчики продуктового решения, благодарны механизму расширений: он значительно упростил и ускорил доставку изменений и патчей нашего модуля тысячам клиентов. Благодаря расширениям продукты можно эффективно развивать и супербыстро распространять.
Все те особенности, о которых я рассказал, коротко и емко собраны по ссылке https://github.com/gshatrov/InfostartExtensionBD.git. Можете с ними ознакомиться.
И желаю вам, чтобы ваши расширения действительно помогали и улучшали ваш бизнес.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TEAM EVENT.


Вступайте в нашу телеграмм-группу Инфостарт