



Далее я все цифры буду приводить в часах, т. к. в ценах не интересно, потому что они отличаются по годам и по регионам.
Первый клиент, который запомнится на всю жизнь)))
Итак, в конце 2014 года к нам обратился немаленький клиент с интересной задачей: автоматизировать прикрепление сканов документов к документам в базе УПП. Задача казалась очень интересной и передовой, ведь по опросу никто с таким раньше не сталкивался.
Также заказчик стал просто зарываться в бумажках, оригиналы постоянно где-то терялись, количество запросов от налоговой по встречным проверкам возрастало, приходилось предоставлять сканы оригиналов, а их надо было долго искать в архиве, сканировать, отправлять налоговую. Работницы архива даже иногда чай попить не могли 😊. В общем задача была продиктована самой жизнью.
Предложили для начала сделать обследование, в результате выяснилось:
Исходящие документы (реализации и счета-фактуры)
• Среднее количество пакетов документов в год - 227000 шт.
• Среднее количество листов в пакете документов - 3 листа.
Входящие документы (Поступления товаров и услуг, доп. Расходы)
• Среднее количество пакетов документов в год - 68000 шт.
• Среднее количество листов в пакете документов - 3 листа.
Т. е. получалось, что пользователи вводят порядка 808 документов вдень в каждом по три листа и получается около 2424 листов в день, которые надо будет распознать (была идея поставлять им бумагу 😉).
Причем нагрузка в месяце распределялась неравномерно, естественно все откладывали подписание и возврат документов на конец текущего, начало следующего месяца.
На тот момент распознавание было только в документообороте, поэтому клиенту был навязан предложен документооборот как файловое хранилище с последующей возможностью перенести некоторые процессы предприятия в него. Кажется, тогда это был еще документооборот 1.4
У него уже появилась бесшовная интеграция и уже пару раз довелось ее внедрить у других клиентов, так что проблем с отображением прикрепленных сканов в УПП не было, обо всех подводных камнях было известно.
Единственный минус – ДО распознавал только EAN13, а у клиента печатались ШК в Code128. Поэтому предложили создать свою подсистему генерации и печати уникального ШК.
Долго думали над проблемой генерации уникального номера при параллельной работе, а на тот момент одновременно вводить и печатать могли порядка 50-70 сотрудников. В лучших традициях исторического жанра решение приснилось (да-да именно приснилось, вот что значит интересная задача) и оказалось простым: для генерации уникального ШК был создан новый справочник с числовым номером. Как показала практика – ни одной проблемы с неправильной генерацией за время эксплуатации и сопровождения не было. Я потом эту идею не раз применял на практике для других задач.
ШК представлял из себя ПППНННННННННК, где
ППП – префикс,
ННННННННН – уникальный номер, сгенерированный справочником,
К – контрольный символ
По расчетам должно было хватить номеров лет на 200, что вполне устраивало заказчика.
Получилась красивая и легко настраиваемая подсистема: в регистре сведений для любого типа документов/справочников можно было задать префикс из 3 символов и необходимость печатать на его печатных формах штрихкод.
Далее была проблема с тем, где печатать это ШК и как его печатать. Рассмотрели все возможные варианты, которые были доступны на тот момент и выбрали печать с использованием шрифта EanGnivc.
Далее сделали авто установку этого шрифта при запуске базы и предупреждение, если не удалось установить.
Решено было помещать его в колонтитул, если занят нижний, то в верхний.
Настройка УПП обошлась малой кровью: добавили настройки всего в двух местах и она стала работать для всех документов в УПП.
Далее ШК генрился при записи документа, если для него было включено использование ШК и настроен префикс. Либо при первой печати, если до этого не был сгенерирован ШК, например, для старых документов или документов, настройка печати для которой была включена позднее.
Для внешних печатных форм пришлось прописать печать ШК в их коде, добавив одну строку кода.
Потом выяснилось, что в некоторых печатных формах оба колонтитула заняты, поэтому доработали функцию вывода, которая проверяла занятость колонтитулов и вставилась небольшая область с ШК в начале документа. Ну и пришлось сделать проверку, если документ теперь не помещается на лист на принтере – уменьшить масштаб в цикле на 1 процент, пока не станет помещаться. С колонтитулом проблем не было – он печатался на каждой странице, а с областью пришлось повозится, чтоб также выводить на каждую страницу.
На эту подсистему было потрачено порядка 50 часов.
Далее была настроено бесшовная интеграция с ДО и обмен НСИ с ДО.
Также была проблема с тем, что при сканировании в ДО уже должна быть информация о документе и его ШК, поэтому доработали выгрузку всех новых/изменённых документов из УПП в ДО по правилам интеграции с ДО.
Решили не выгружать старые, только при необходимости, а такая необходимость могла возникнуть при изменении и при регистрации ШК для этого документа, т. е. просто настроили правило: регистрировать к выгрузке все, что изменено или для чего зарегистрирован новый ШК
На настройку интеграции и обмена ушло порядка 90 часов.
Далее начиналось самое интересное
Клиент купил для начала 2 или 3 мощных потоковых сканера с заоблачной производительностью, конкретные цифры не помню. Проблема со скрепками решалась до сканирования, бухгалтера их сами открепляли.
И вот уже был архив с несколькими тысячами сканов исходящих документов для тестов. Попробовали типовую обработку распознавания – справилась с 30%, стали разбираться.
Оказалось качество сканирования не очень, поигрались с настройками сканера, процент распознавания увеличился до 50%.
Стали разбираться дальше, оказалось, что документы в сканер клали произвольным образом и ШК мог быть внизу, вверху, слева или справа, а компонента с этим не очень справлялась. А если еще ШК был под углом, то вообще атас.
Пришлось пожертвовать производительность и, если не распознался ШК – обрезать 50 мм с каждого края, увеличивать немного картинку и на каждом кусочке пытаться распознать ШК с помощью компоненты. Процент распознавания увеличился до 95%, скорость распознавания упала процентов на 30%, но это было не критично, сервер справлялся с нагрузкой с запасом. Даже сканы под небольшим углом тоже начинались нормально распознаваться.
Потом выяснили что криво распознаются ШК, которые начинались с 0, пришлось префикс в регистре задавать с 100, а не 001, но это проблем не вызвало
Стали разбираться с оставшимися - оказалось, что большая часть просто без ШК, пользователи в потоковый сканер клали все подряд: служебные записки, другие документы, на которых не печатался ШК, пусты листы (да и таких было не мало, наверное, хотели сломать систему 😊). Как решили эту проблему – чуть дальше.
Для входящих документов решили клеить ШК на них с помощью этикеток. Купили принтеры этикеток, в документах сделали внешнюю форму для печати этикетки заданного размера и бухгалтера пошли штамповать их на входящие.
Пробовали распознать входящие документы - результат удивил, распозналось около 2-3%.
Стали разбираться – оказалось, что глянцевые этикетки засвечивались при сканировании и линии искажались. Такие сканы с ШК просто ничем не читались. Поменяли этикетки на матовые, бухгалтера переклеили все этикетки, матерясь на программистов. После этого процент распознавания также увеличился до 93-95%. Проблема с оставшимися была в основном такой же: попадались не те документы. Документы с ШК не распознавались в итоге не более 0,5-1% из общей массы, что соответствовало требования заказчика.
Распознавание было сделано часов за 30.
Далее началась опытно промышленная эксплуатация и новые задачи по оптимизации.
Первое с чем столкнулись – новые документы не успевали выгрузится в ДО, причем задание работало 24 часа в сутки.
Стали разбираться, оказалось, что у них часто запускается групповое перепроведение и в итоге много документов повторно регистрируется к выгрузке.
Оптимизировали несколькими способами:
- Перепроведение запускалось обычно под определённом юзером или кто-нибудь из местных программистов его делал, поэтому в юзере добавили настройку, которая исключала регистрацию под ним, этого оказалось достаточно, но решили не останавливаться 😊
- В регистре сведений, где задавались префиксы – сделали доп. Поле «Приоритет выгрузки», т. е. можно было регулировать какие документы выгружать первыми, а какие могут и подождать
- Поменяли программный приоритет выгрузки, ранее выгружались в хронологическом порядке, переделали, чтоб сначала выгружались те, которых еще нет в ДО, а потом все изменения существующих документов
Этого оказалось достаточно.
Далее возникла проблема с не распознанными, они стали накапливаться
Т.е. все сканы сливались в одну общую папку, ДО анализировал каждый файл этот папки и если распознавал – прикреплял в ДО и удалял файл из папки, если не распознавал, то перемещал его в подпапку «Нераспознанные» и потом после основной работы еще раз анализировал подпапку Нераспознанные, на случай если документ пришел в ДО позже первого сканирования
Решили не выделять для распознавания таких файлов отдельного человека, а переложить это на юзеров, которые сканируют. Т.е. сканы разделил по папкам, каждый юзер сканировал в свою папку, а ДО распознавал и перемещал не распознанные в его подпапку, потом юзер должен был войти в ДО, запустить специальную обработку, которая показывает ему все не распознанные его файлы, открывала выделенный в этом же окне и позволяла
- удалить его, если это файл без ШК, например
- Найти документ по ШК или реквизитам вручную и прикрепить
- Оставить его и разобраться с ним позже
Внешний вид был такой:

Т. е. пользователь работал со сканом из одного окна
В результате пользователи перестали класть в сканер всякую ерунду и стали этикетки на входящие клеить ровно ))), чтоб не увеличивать себе работу.
В результате процент распознавания увеличился практически до 100%, а после разбора не распознанных юзером был равен почти 100% (некоторые по ошибке удаляли нужный файл)
На эту часть ушло около 70 часов.
Завершающей частью было повторное сканирование в архиве, чтобы был зафиксирован факт того, что оригинал документа лежит в архиве. Это нужно было для того, чтобы отследить ситуацию, когда документ терялся в процессе передачи бухгалтером в архив.
Отличие от первого сканирования было только в том, что программное сравнивалось количество отсканированных листов и проставлялся признак в ДО наличия оригинала документа.
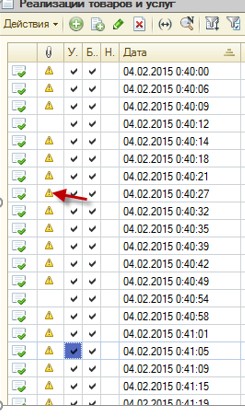
Потом на совещании с главным бухгалтером черт меня дернул сказать, что в УПП можно отображать признак наличия документа. Ей идея так понравилась, что пришлось резать другие мелкие задачи, чтобы это сделать, т. к. стоимость была жестко зафиксирована в ТЗ.
Но зато получилось красиво и наглядно. Была добавлена колонка, в виде скрепки, которая отображала текущее состояние документа:
- Нет в ДО
- Есть в ДО, но без файлов
- Если в ДО с сканами, но без оригинала
- Если в ДО с сканами и оригиналами, т. е. документ в архиве
На эту часть было потрачено около 15 часов
Далее уже без нас заказчик стал расширять перечень сканируемых документов, благо для этого было достаточно включить печать ШК на документе и настроить правила интеграции с ДО в режиме предприятия. Далее система уже работала сама.
Через год где-то возникла проблема с местом, оказалось, что архив стал расти более чем на 3 Тб в год (на сканировали 😊). Но это быстро решили, докупив диски.
После прочтения статьи могло сложиться впечатление, что все делалось на абум и задачи решались по мере поступления, на самом деле это не так, в описании я переплел прошлое и будущее, чтобы выстроить порядок изложения.
Было обследование, составлении и долгое обсуждение ТЗ, сроков, стоимости, архитектуры решения. Вся работа системы была придумана заранее и прописана, от нее практически не отступали в процессе решения задачи. Пришлось загнать себя в жесткие временные рамки, чтобы не потерять заказчика и интересную задачу, но я не жалею, что взял этот риск на себя, ведь в результате времени вполне хватило даже на премии, а полученного опыта и знаний для легкого решения других подобных задач.
В результате заказчик получил
- систему, с помощью которой мог сканировать и автоматически прикреплять сканы, а потом и просматривать их базе, не обращаясь в бумажный архив.
- Процесс ответов на требования налоговой стал быстрее даже не могу сказать во сколько раз. Ранее надо было подать заявку в архив, пару дней или больше подождать пока их найдут и отсканируют и потом отвечать. После внедрения достаточно было зайти в ДО, воспользоваться типовой обработкой поиска файлов, отобрать нужные документы, например, по контрагенту и периоду и одной кнопкой сохранить все сканы.
- Процесс контроля наличия оригиналов значительно упростился
- Процесс возврата оригинала стал подаваться контролю, если оригинала не было долго, то документы повторно печатались и отправлялись + уже можно было прописывать в договоре процесс и сроки возврата и при желании накладывать штрафы, ну или пугать контрагента 😊
- Сократили затраты на содержание архива
Заказчику заранее предлагалось сделать разные ШК для печатных форм, но в целях экономии он отказался, а где-то через год все-таки решился, но это уже было дороже
Пришлось доработать систему, чтобы ШК генерировался для каждой печатной формы.
Вернее не так, в регистре, где задавались настройки печати ШК добавили поле, в котором выбиралась печатная форма и тип этой печатной формы из специального справочника, потому что у заказчика было около 8 различных печатных форм счетов-фактур для разных крупных клиентов, 6 видов ТОРГ12 и т.п., а по сути это все были счета-фактуры и ТОРГ12. Для всех остальных печатался ШК заданный для документа в целом, т. е. с пустым именем печатной формы. Пришлось доработать передачу вида печатной формы в ДО, но зато при сканировании теперь программа понимала, что это за печатная форма и проставляла ей соответствующий признак.
В результате, например, для налоговой можно было быстро отобрать только счета-фактуры и бухгалтера сразу видели, где какая печатная форма и им не приходилось больше просматривать все файлы. Правда количество уникальных ШК сократилось, теперь их хватит лет на 15-20, но заказчика эта устроило.
На эту настройку ушло около 30 часов.
Смотрю на эту статью думаю, что очень дешево заказчик отделался. Хоть я и не показал здесь затраты на обследование, составление ТЗ, другие мелкие настройки, управление проектом, обучение и т. п.
В итоге получилась классная легко переносимая подсистема. Потом мы ее внедрили у себя, хоть и объем документов раз в 10 меньше, но все равно удобно. Ну и еще один раз внедряли ее у других клиентов + отдавал другим программистам тоже внедрять.
Второй заказчик
Одновременно с первым заказчиком довелось переводить на БП 3.0 другого моего любимого клиента.
У них не было такого большого документооборота, да и отдел бухгалтерии у них был раза в 2 больше.
Однако тогда пугала всех новость о том, что ФНС будет сверять декларации НДС. Было мало информации как это будет происходить и какие последствия. Было четкое понимание, что реквизиты на бумаге должны соответствовать реквизитам в базе на 100%, чтобы можно было оправдаться перед налоговой. В месяц у них было около 1000 входящих счетов-факту, т. е. ручная проверка слишком долго, да и опять же не исключает операторские ошибки при проверке.
Я им предложил попробовать сделать сверку реквизитов на скане и в базе, сканы у них уже давно прикреплялись в базе и процесс входящих документов был построен так, что у любого поступления, счета-фактуры полученного и прочего был его скан.
На тот момент уже внедрил распознавание у первого заказчика и знаний было достаточно. Хотя здесь задача немного отличалась, в первом случае достаточно было распознать ШК на скане, а здесь надо было распознать текст, найти в нем реквизиты и сравнить их с реквизитами в базе.
Сразу не стали делать автораспознавание в фоне, решили сначала попробовать на клиенте.
В итоге родилась обработка, которая выполняла распознавание сканов входящих счетов-фактур и сверяла с реквизитами в базе. Сверялись реквизиты Номер, дата, ИНН, КПП, Сумма, Сумма НДС
Вся работа по сравнению происходила из одного окна:
Отбирались счета-фактуры, запускалось распознавание и анализ текста. Искались и сверялись реквизиты в распознанном тексте. Выводился результат в виде отчета.
И далее пользователь мог визуально сравнить те реквизиты счет-фактуры в базе и в скане
Внешний вид обработки такой:
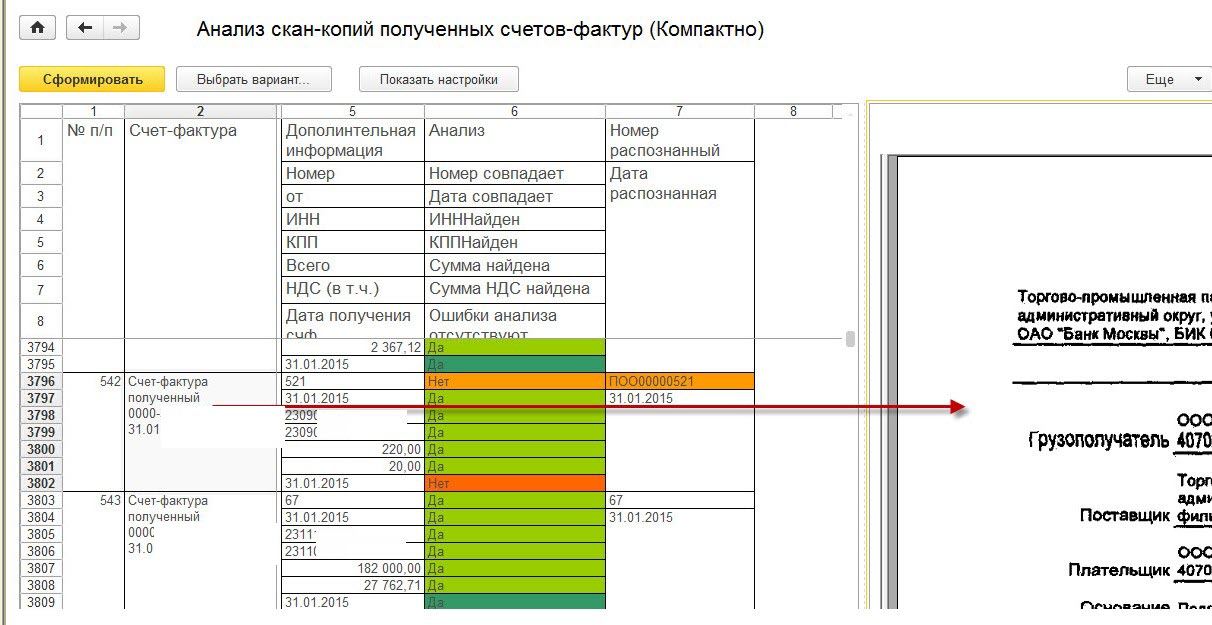
Результат распознавания – 50-80% т. е. в этих счета-фактурах все реквизиты соответствуют их можно не проверять, а в остальных можно провеять реквизиты сразу из обработки, сверить со сканом и при необходимости исправить. Успешность сопоставления реквизитов, конечно, очень сильно зависит от качества распознавания текста, которое в свою очередь сильно зависит от качества сканирования, причем увеличение разрешения сканирования наоборот ухудшает распознавание. Оптимальным оказалось 300 dpi и размерами не более 2500*4000, а то при преобразовании из пдф в картинку потом плохо все распознавалось или не распознавалось вообще.
Распознавание текста оказался процессом не быстрым, на один скан уходило 15-30 сек, поэтому пользователи всегда оставляли распознавание на ночь, а утром проверяли реквизиты. Время на проверку думаю сильно сократилось, сравнивать не с чем, потому что до этого еще никто не сверял сканы или оригиналы вручную 😊. Сейчас на проверку остатка не полностью распознанных обычно уходит 2-3 часа.
Обработка до сих пор помогает сверять и находить ошибки в реквизитах, а бухгалтерам позволяет быть спокойными и уверенными что у них все в порядке с документами.
Периодически звонят и просят проконсультировать как она работает, когда меняется бухгалтер, который этим занимается. Хоть в справке к этой обработке все написано подробно со скринами, но кто же ее читает 😊
Внедрял ее же еще у нескольких клиентов.
Время на эту обработку составило 20 часов.
Распознавание табличных частей со сканов
Далее у этого же клиента возникла задача распознавания содержимого скана.
Т. е. процесс документооборота был построен так:
Документ поступал секретарям, они регистрировали его в журнале входящих, создавали пустое не проведённое поступление и прикрепляли к нему скан.
Далее бухгалтера по скану заполняли документ.
Для заполнения больших документов требовалось много времени, поэтому решили сделать распознавание и заполнение товаров
Получилась вот такая обработка, которая распознавала товары на скане и заполняла ТЧ.
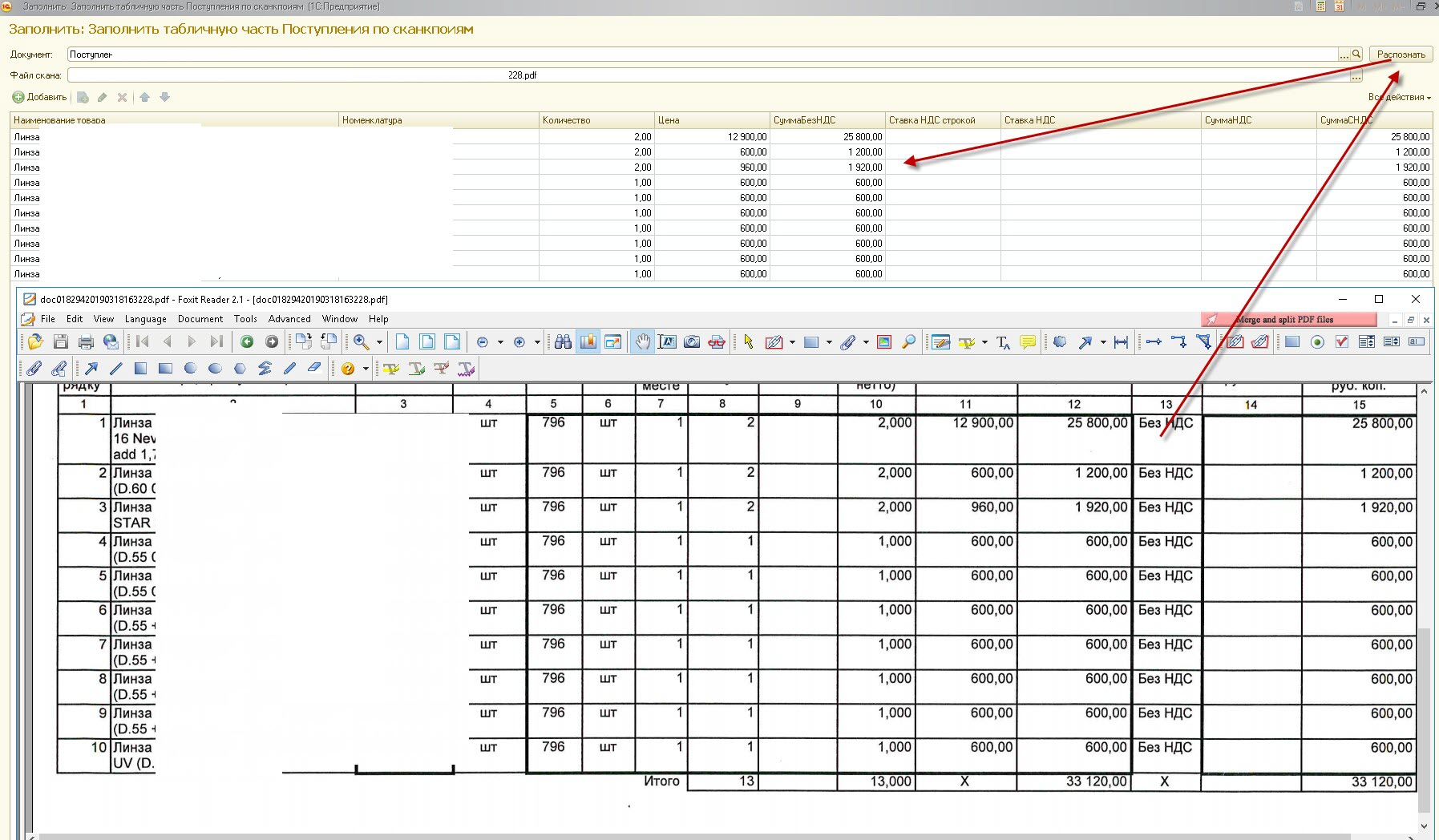
При хорошем качестве сканирования – распознавала все достаточно успешно
Проблема была с номенклатурой – много корявых символов распознавалось, да и это было наименовании поставщика. Номенклатуру в итоге если не нашли – не заполняли, просто потом выбирали в ТЧ.
Большим плюсом было то, что все остальные цифры заполнялись из скана и это облегчало работу
Время на реализацию ушло 15 часов
После этой задачи чуть больше года был РП на одном проекте и не было времени на другие задачи.
Распознавание анкет
В 2017 была еще задача распознавания заполненных на бумаге анкет, но там было распознавание в основном с помощью специального софта ABBYY FlexiCapture, и от 1с требовалось корректно распарсить результат.
Как-то плохо помню эту задачу, наверное, ничего интересного там не было.
Разбивка и распознавание пдф
Следующая задача пришла уже в конце 2017 года:
У одной компании поставщики услуг предоставляли в многостраничном пдф подписанные платежки, распорядительные письма и документы по убытку.
Один документ – одна страница, в пдф могло быть от 30 до нескольких сотен страниц.
Требовалось разбить эти пдф постранично в новые пдф, содержащую только одну струнцу из этого файла и в названии файла указать номер, дату документа, номер убытка, рег. Номер и сумму.
Естественно, эти реквизиты были на каждой странице в тексте.
В итоге была написана обработка, которая разбивала пдф, распознавала текст и вставляла в наименование реквизиты.
Точного процента распознавания нигде не сохранилось, но помню, что он был близким или равным 100%. А все дело в том, что в пдф не было сканированных страниц и он очень хорошо распознавался.
Затраченное время на обработку 9 часов
Распознавание по номеру и дате
Затем в начале 2018 года пришла задача распознавания сканов по номеру и дате, у клиентов была куча сканов документов без ШК и был специально обученный человек (естественно с высшим образованием 😉), которые эти сканы прикреплял к документам.
Так вот он перестал успевать, т. к. объем документов рос, наверное, в арифметической прогрессии.
Встала задача автоматизировать распознавание по номеру и дате, пусть хоть и не 100%, но существенно снизить нагрузку на человека. Ну и требование, чтоб программа по рег. Заданию распознавала сканы из папки, а что не смогла распознавать – обрабатывал человек.
Тут возникли трудности: компонента распознавания была COM, а на сервере проблемы с ее запуском.
Поэтому рег. Задание запускало на сервере клиент, открывало в нем обработку, обработка выполняла распознавание и закрывала сеанс.
Принципы распознавания были те же самые, распознавался текст на скане и потом в тексте искались определенные теги.
По началу распознавалось порядка 30-40%, стали оптимизировать распознавание. Часто встречались ошибки распознавания в виде:
ноль заменялся на О
в годе даты пробел
вместо точки запятая.
Такие ситуации обрабатывались программно и в результате количество распознавания сканов удалось довести до 60-80%
Также в 2018 распознавание по номеру и дате внедрял еще у одного клиента.
Время на разработку и внедрение ушло 22 часа
Распознавание по ШК и по номеру и дате
Ну и последняя задача пришла уже в начале 2019 года
Есть УТ, из нее печатаются документы с ШК, ШК типовыми средствами, т. е. в нем закодирован УИД документа в Code128, нужно было распознать документ по ШК, а если не удалось, то по номеру и дате в скане.
Как было сказано в начале – компонента ДО работала только с EAN13 клиент не соглашался переделывать печать ШК, да и настраивать типовую очень не хотелось.
Стал копаться и нашел программу zbar, которая через командную строку просто и быстро могла распознать любые ШК, в том числе и QR
Прилепил ее к обработке распознавание – отлично распознались 100% тестовых документов.
Отключил временно распознавание ШК, доработал распознавание по тексту, т. к. здесь были другие печатные формы. Распозналось 90%.
Ну и требовалось, чтоб распознавалось автоматически, поэтому прикрутил запуск этой обработки через рег. Задание.
Время на эту работу ушло 12 часов
На этом все!
Я уже давно убедился, что нет не решаемых задач, так что дерзайте, не бойтесь браться за что-то новое.
Как говорил Великий поэт:
О сколько нам открытий чудных
Готовят просвещенья дух
И Опыт, сын ошибок трудных,
И Гений, парадоксов друг,
И Случай, бог изобретатель
© Пушкин
Вот, например, в 2011-2012 году довелось делать базу поиска описаний и картинок для товаров через поисковики, гугл, яндекс, бинг и другие. Программа разбирала первые 10 страниц поисковика, сканировала каждую страницу, если находила на ней товар, запоминала для парсинга и потом обрабатывала. Там же были задачи по сравнению похожести изображений, оптимизации поиска, парсинга и т. п. База анализировала миллионы страниц и находила большой поток нужных данных. Но это уже другая история. Тогда я очень плотно познакомился с HTML, PHP, Java и немного CSS (а до этого слышал только название) и эти знания меня уже не раз выручали. 😊
Для распознавания всегда использовал Ghostscript и ImageMagick для конвертации пдф в картинку и разбивку по страницам
И CuneiForm для распознавания текста.

Распознавание и загрузка сканов в 1С
Решение «Распознавание и загрузка сканов в 1С» — интеллектуальный инструмент, превращающий сканы накладных, счетов, УПД или Excel-файлов в готовые документы 1С. Без ручного ввода и ошибок — с распознаванием даже нечетких фото. Оптимизируйте документооборот и автоматизируйте рутину с помощью ИИ-распознавания.
Вступайте в нашу телеграмм-группу Инфостарт