Сегодня я расскажу, из чего состоит статический анализ, и что интересного можно найти с его помощью в проектах на 1С.
Подопытным в данном случае будет выступать плагин для SonarQube от компании «Серебряная пуля». Кроме этого, многие аналогии будут применимы и к плагину для SonarQube от сообщества «1С-syntax».
По каждому модулю я буду показывать примеры ошибок, которые там можно найти.
Что такое статический анализ?

Статический анализ кода – это процесс выявления проблем в исходном коде программы. Процесс во многом похож на код-ревью и, бывает, дополняет его. Но, в отличие от код-ревью, процесс статического анализа полностью автоматизирован.
Многие считают, что статический анализ устроен просто – берем исходный код, применяем какую-то магию, и, вуаля, у нас на выходе список ошибок.
Но это не так, статический анализ устроен более сложно.
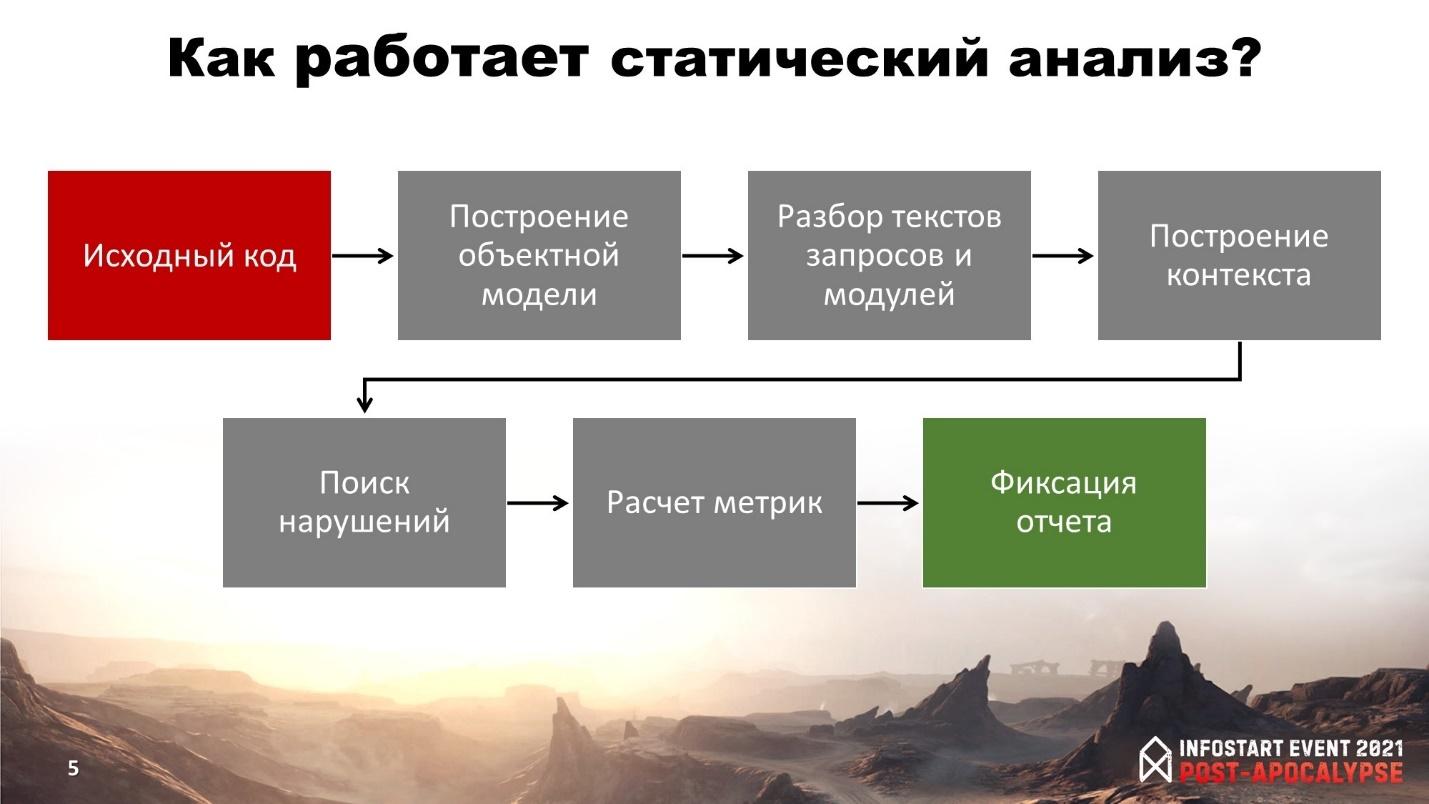
Процесс следующий:
-
Сначала берем исходный код и по нему строим объектную модель метаданных.
-
Затем запускаем разбор текстов модулей и текстов запросов и превращаем их в синтаксические деревья.
-
После этого мы строим контекст (контекст проекта, модуля и т.д.)
-
Только после этого запускается поиск нарушений, который на выходе как раз имеет список ошибок.
-
Дополнительный шаг – это расчет метрик. Например, для SonarQube это – когнитивная сложность или количество строк кода
-
И последний этап – это фиксация отчета в какой-то внешний файл или в базу данных. SonarQube пишет информацию в базу данных, а оперативные данные у него крутятся в Elastic Search.
Синтаксическое дерево (AST) кода 1С
Исходный код 1С-модулей хранится в файлах с расширением bsl.
Чтобы текст модулей можно было разбирать с точки зрения статического анализа, его нужно преобразовать в синтаксическое дерево. А если быть точнее, в абстрактное синтаксическое дерево.
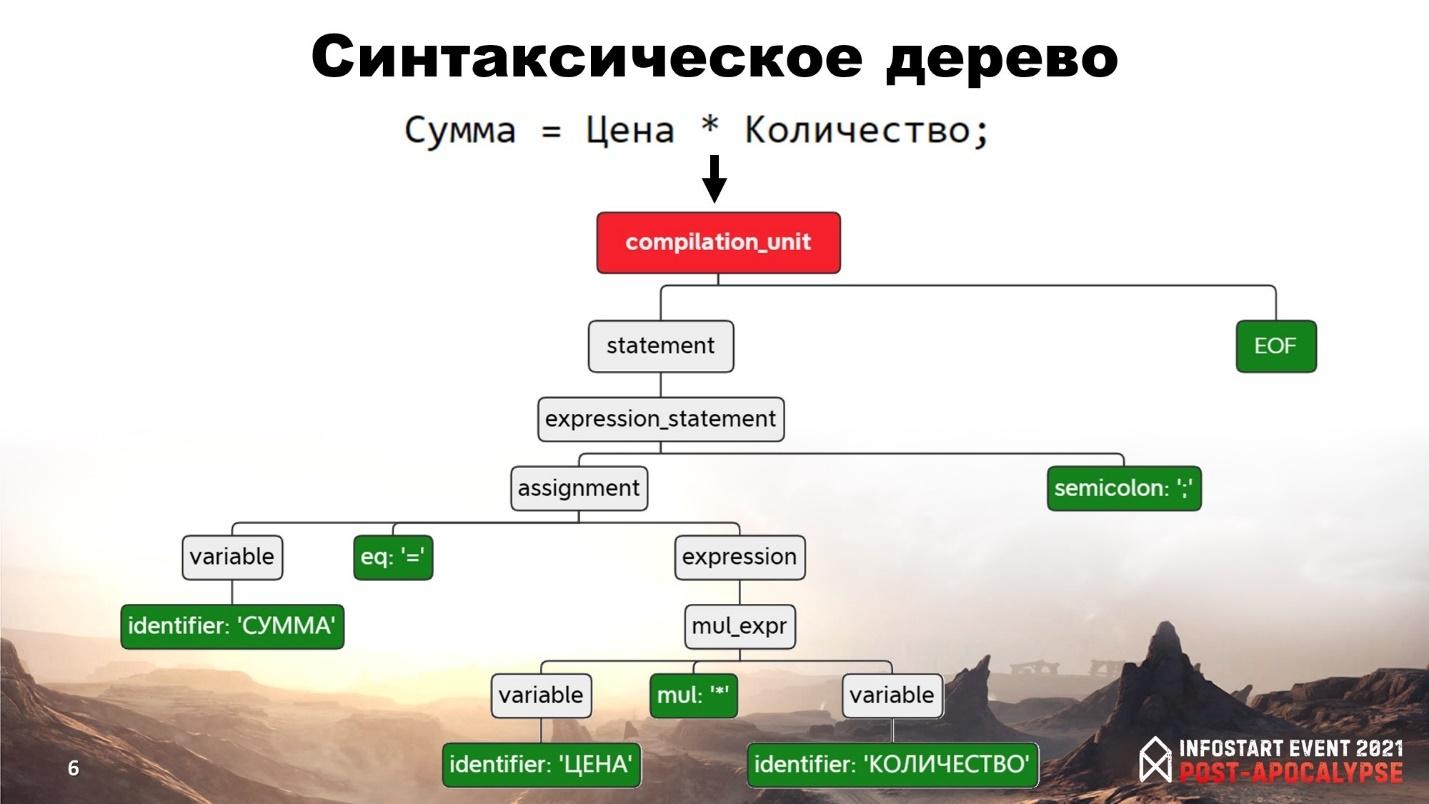
Посмотрим пример – берем простое выражение:
Сумма = Цена * Количество
Это выражение в виде синтаксического дерева выглядит следующим образом:
Дерево состоит из узлов AST. Вершина – это единица компиляции. Я специально выделил конечные узлы цветом, чтобы было понятно. В итоге выражение состоит из конечных узлов:
-
Переменная с идентификатором «Сумма»
-
Знак «=»
-
Переменная с идентификатором «Цена»
-
Знак «*»
-
Переменная с идентификатором «Количество»
-
Символ «;»
А еще синтаксическое дерево – это конечное ориентированное дерево, в котором:
-
вершины сопоставлены операторам языка;
-
листья сопоставлены операндам.
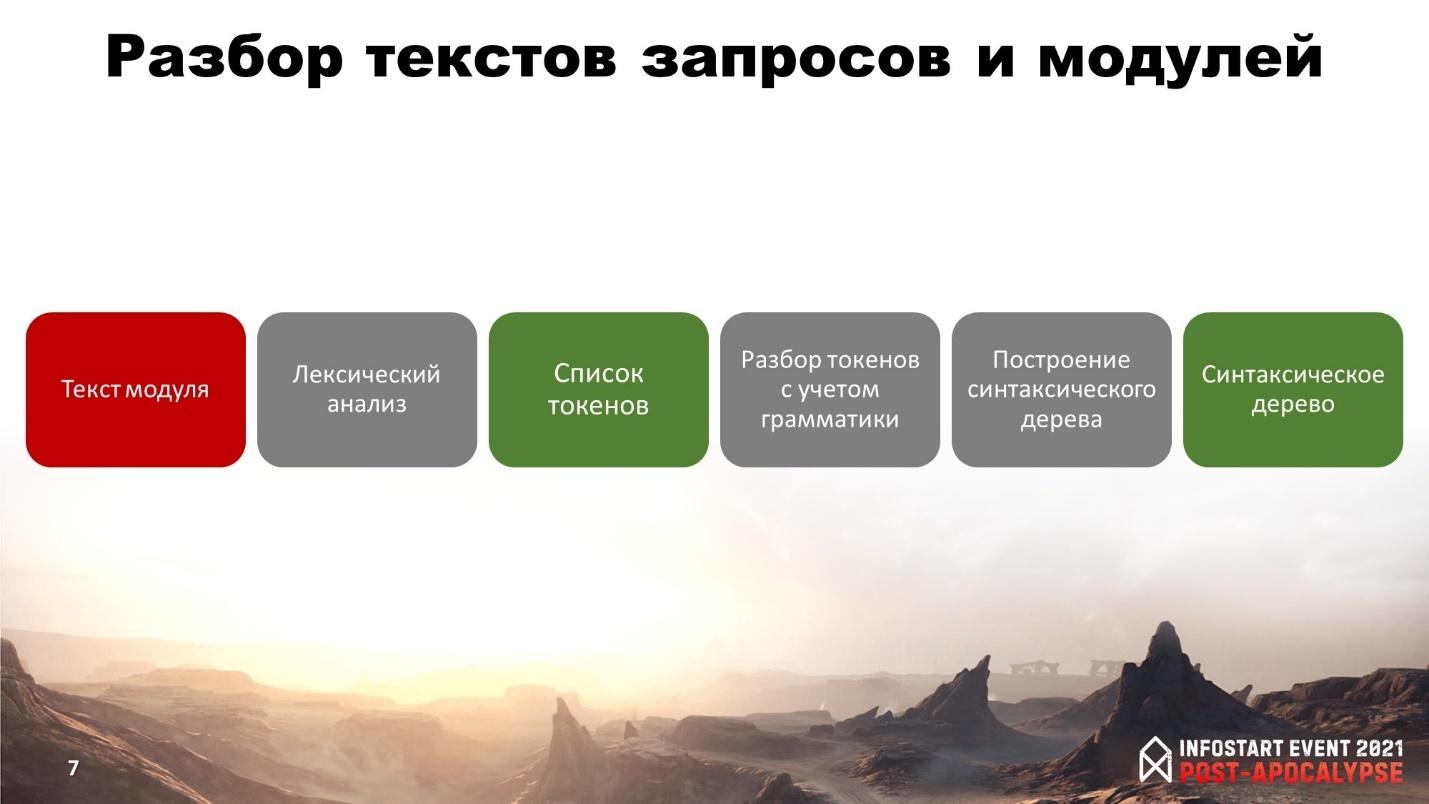
Для того, чтобы получить синтаксическое дерево, нужно сделать следующее:
-
Сначала из исходного кода мы извлекаем тексты.
-
Затем прогоняем все это через лексический анализ.
-
На выходе получаем список токенов. Токен или лексема – это абстрактная единица морфологического анализа (например, переменная с идентификатором «Сумма»).
-
Дальше нам нужно прогнать все это через грамматический анализ.
-
В результате мы получаем построенное синтаксическое дерево. Либо не построенное дерево, если в коде модуля есть какие-то ошибки, которые не позволяют его построить – грамматика нарушена, либо что-то еще.
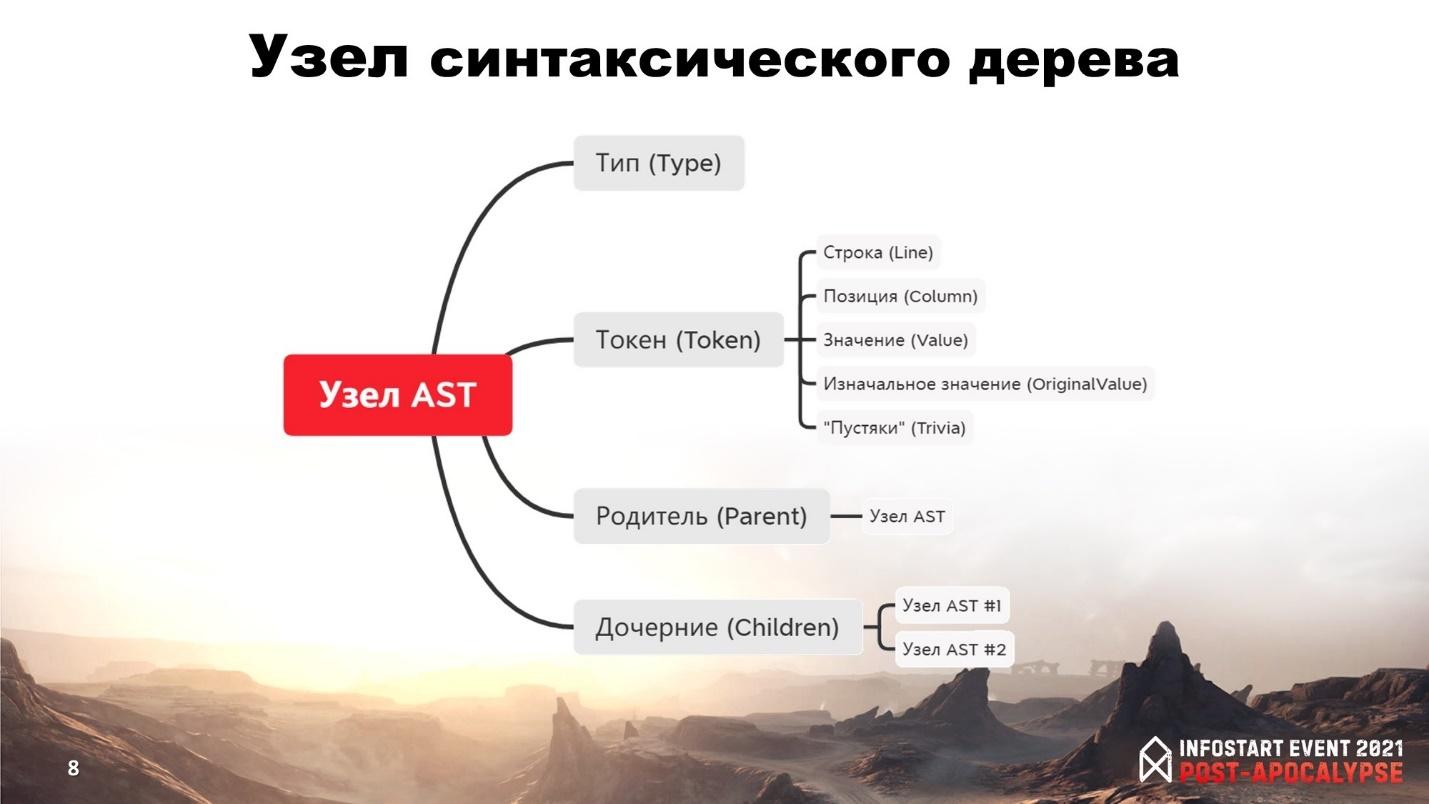
На примере переменной «Сумма» рассмотрим, что из себя представляет узел синтаксического дерева:
-
У него есть тип – в данном случае, это переменная (BSLGrammar.Variable).
-
У него есть родитель – это присвоение (assignment).
-
У него есть дочерний элемент – идентификатор (identifier).
-
И есть токен. По токену мы можем узнать:
-
номер строки;
-
позицию в тексте;
-
длину;
-
оригинальное значение и приведенное к верхнему регистру для удобной работы с ним;
-
а также коллекцию с «пустяками», где содержится комментарий, инструкции препроцессора и т.п.
-

Аналогично тексту модулей строится и дерево для текстов запросов.
Рассмотрим простой пример запроса. У нас происходит выборка значений поля «Наименование» из справочника «Номенклатура».
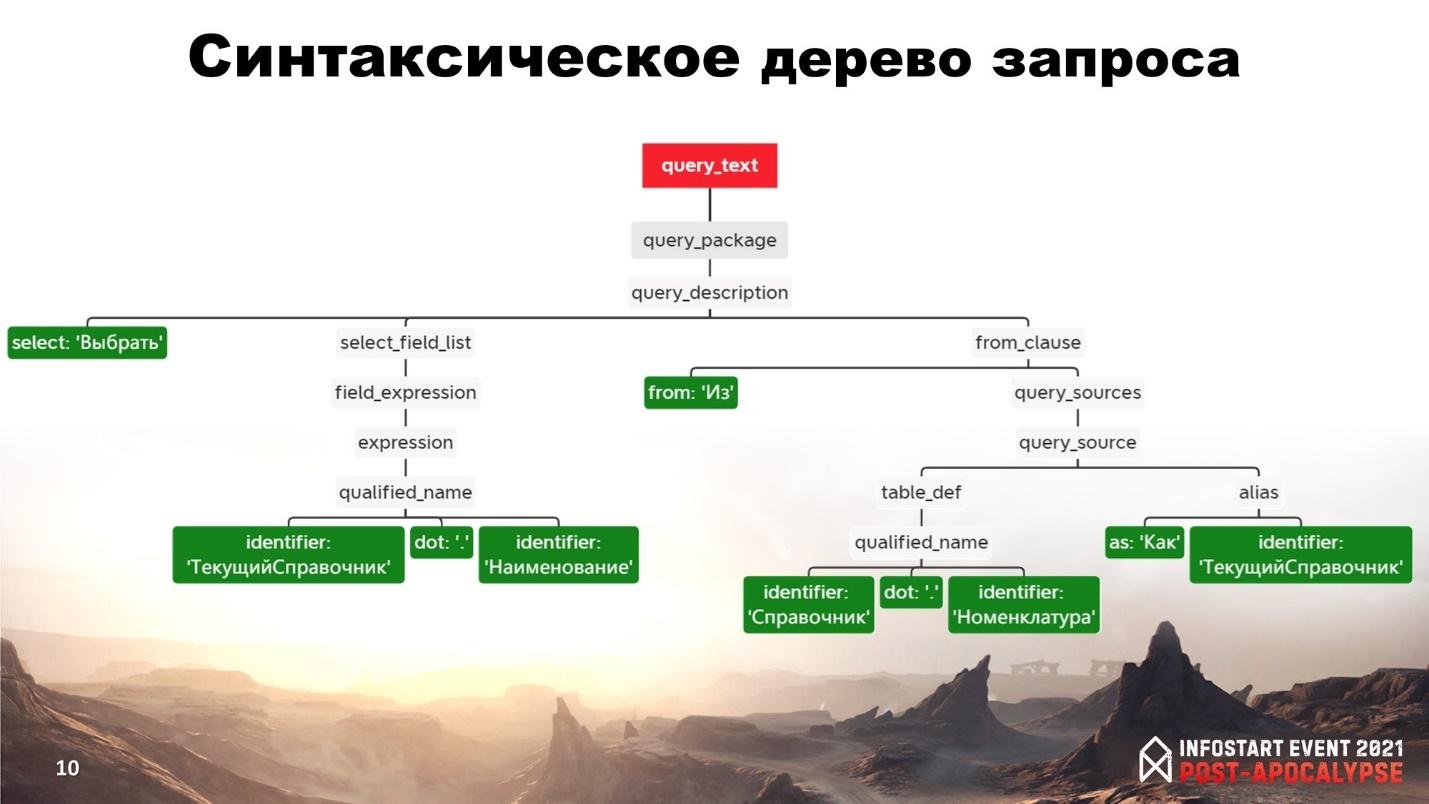
Синтаксическое дерево запроса у нас выглядит следующим образом:
-
Вершина дерева – узел текста запроса.
-
Далее можно проследить типы узлов: пакет запроса, описание запроса, описание полей выборки и т.д.
-
Я снова выделил зеленым конечные узлы. В итоге мы можем текст запроса представить из следующих конечных узлов:
-
Ключевое слово «Выбрать»
-
Описание полей выборки, которое состоит из идентификатора «ТекущийСправочник», точки и идентификатора «Наименование».
-
Ключевое слово «Из»
-
Описание таблицы, из которой мы выбираем – оно стоит из идентификатора «Справочник», точки и идентификатора «Номенклатура»
-
И заканчивается это все алиасом, который состоит из ключевого слова «Как» и идентификатора «ТекущийСправочник».
-
Хорошо, у нас в распоряжении есть синтаксическое дерево. Что нам нужно сделать, чтобы выявить по нему какие-то ошибки?
Модуль «Правила проверок»
Для этого существует модуль «Checks» – в переводе на русский это «Правила проверок». Эти правила описывают, на какие типы узлов нам нужно подписаться в этом дереве, и описывают алгоритмы – каким образом мы будем все это проверять.
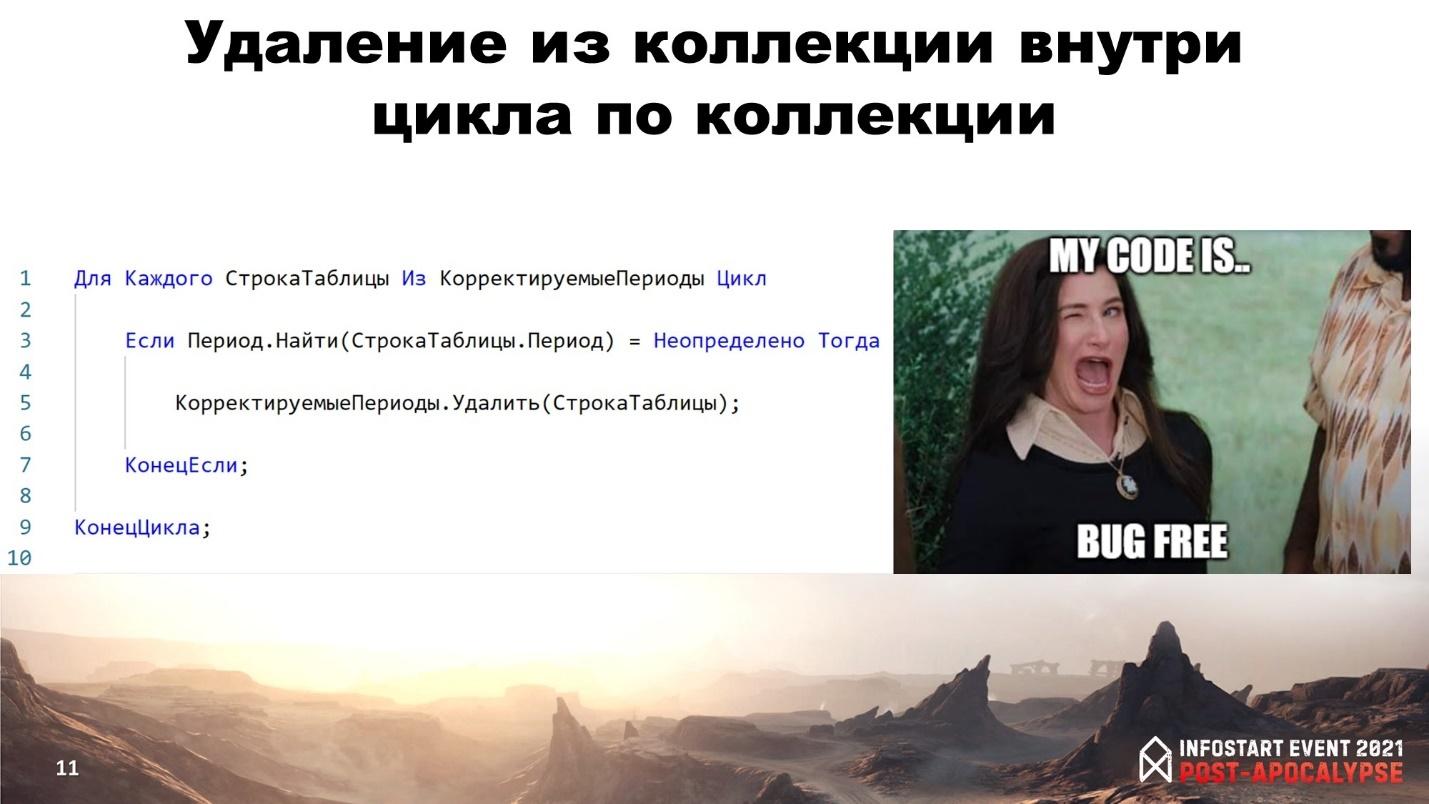
Давайте посмотрим на примере. На слайде – небезопасное удаление из коллекции (из таблицы значений). Согласно этому условию у нас могут быть удалены не все значения, которые нам нужно будет удалить, и это – неправильно. Получается небезопасный, некорректный алгоритм. Описание правила проверки выглядит следующим образом – мы сначала в правиле подписываемся на тип узла «Для Каждого». Затем в этом блоке «Для Каждого» мы извлекаем имя коллекции. Дальше это имя коллекции мы ищем в блоке внутри. Затем ищем вызовы методов Удалить() или Очистить().
Если мы нашли такой вызов, то фиксируем замечание и идем дальше.
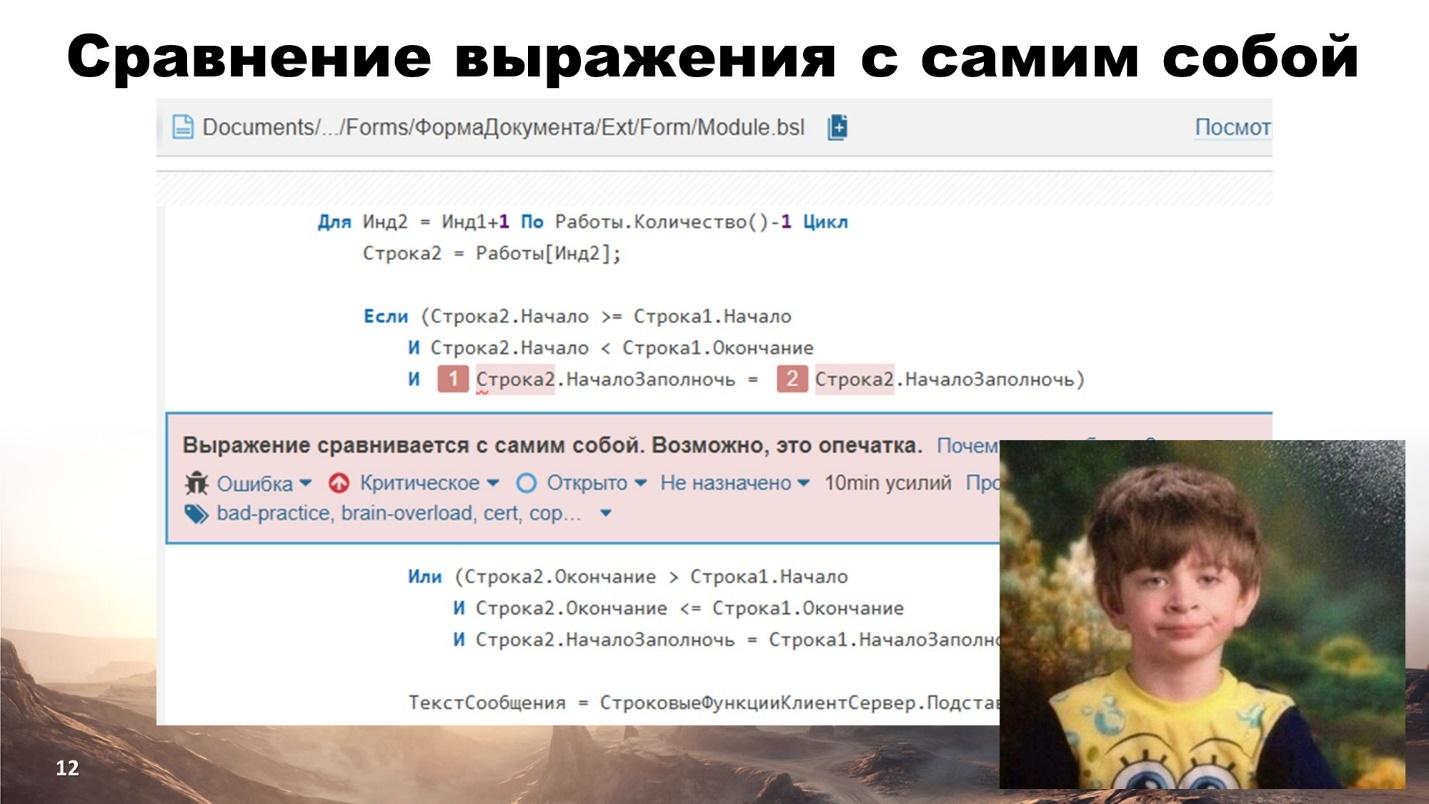
Следующий пример.
Что самое трудное в программировании? Конечно же дать осмысленное правильное понятное название именам переменных и методов. В данном случае полет фантазии «иногда» далеко не уводит и рождаются переменные с именами «Строка1», «Строка2» и т.д.
При таком именовании часто появляются простые ошибки, которые трудно выявить «замыленным» взглядом.
Эту проблему можно было избежать как минимум двумя способами:
-
Запустить тесты. Ручные, автоматизированные – не важно. Но редкие кейсы обычно тестами не покрываются, поэтому здесь все равно могут быть проблемы.
-
Дать осмысленное имя переменной. Это дешево, сердито и быстро.
Идем дальше.

В тексте запроса на слайде трудно без контекста дать точный вердикт, какие именно есть проблемы. Одно точно сказать можно – здесь есть проблемы с отборами в блоке «ГДЕ». Потому что использование «НЕ» с «И» – не слишком хорошая идея. Кроме этого, здесь выражения НачалоПериода() и КонецПериода() нужно вынести в параметры запроса &НачалоПериода и &КонецПериода.
А в таком виде запрос в продакшене очень сильно тормозил, и люди его потом переписывали.
Не пишите таких запросов, и ваши «маневры» не будут вам стоить «51 год».
Модуль анализа метаданных – MDClasses
Вернемся к компонентам статического анализа.
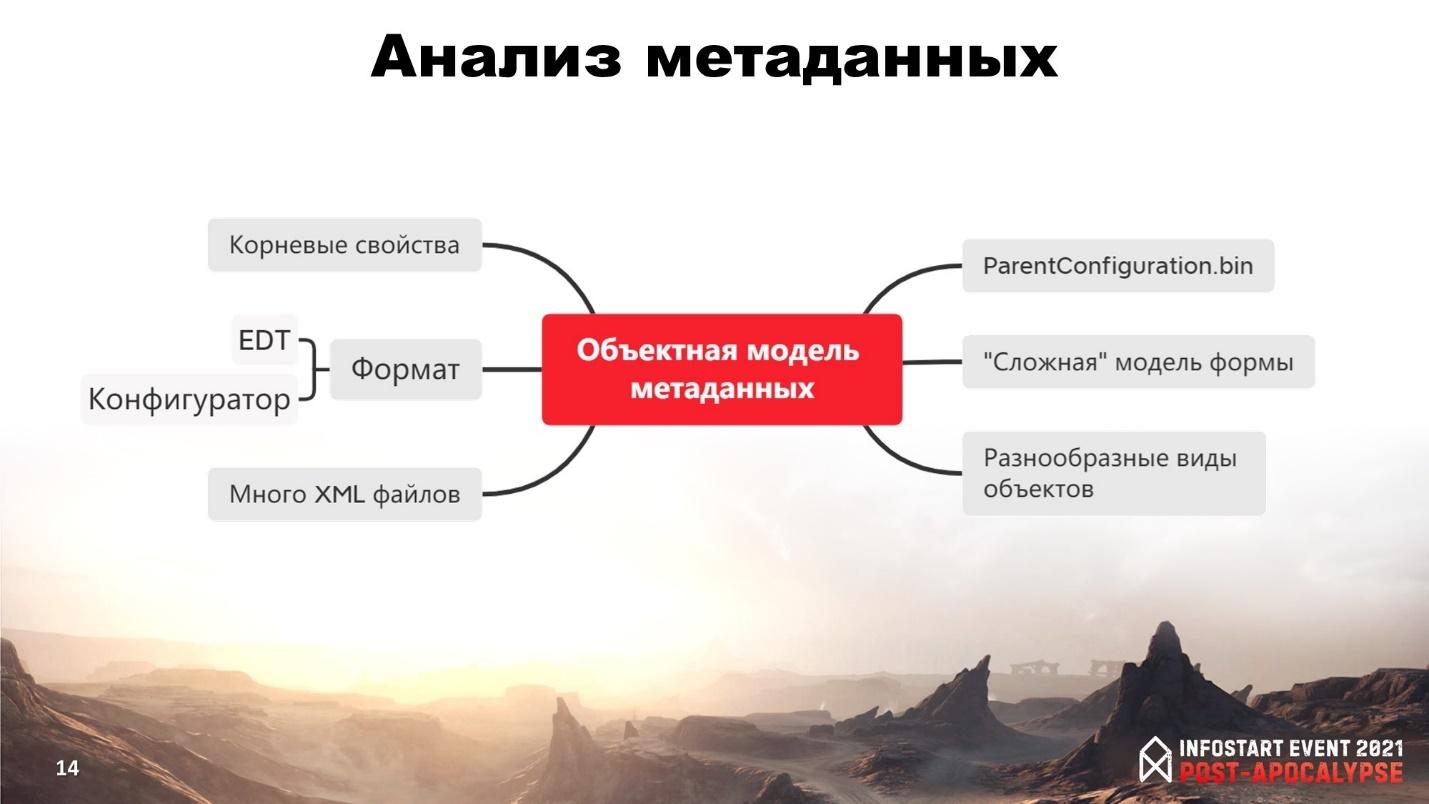
Еще одна из очень интересных и непростых задач – это прочитать все данные из исходного кода 1С и построить на основании этого объектную модель метаданных.
При этом нужно еще учитывать, что у нас сейчас на данный момент два формата метаданных:
-
Первый – это формат экспорта из конфигуратора 1С.
-
Второй – это формат EDT.
Для построения объектной модели метаданных нужно анализировать:
-
множество MDO и XML-файлов с различными видами объектов;
-
у каждого вида объектов – свой набор свойств объектов метаданных;
-
сложная модель формы, особенно, в формате конфигуратора;
-
и, бывает, что нужно получить статусы поддержки из конфигурации поставщика.

Для этого существует проект MDClasses. Он написан на Java, имеет открытый код и развивается на GitHub сообществом «1С-syntax».
Проект покрывает большинство кейсов, которые нужны при статическом анализе в данный момент – это метаданные, формы и макеты СКД.
Пока что проект не умеет строить, например, модель табличного документа, чтобы с ней потом можно было работать – не хватает рук, чтобы это допилить.
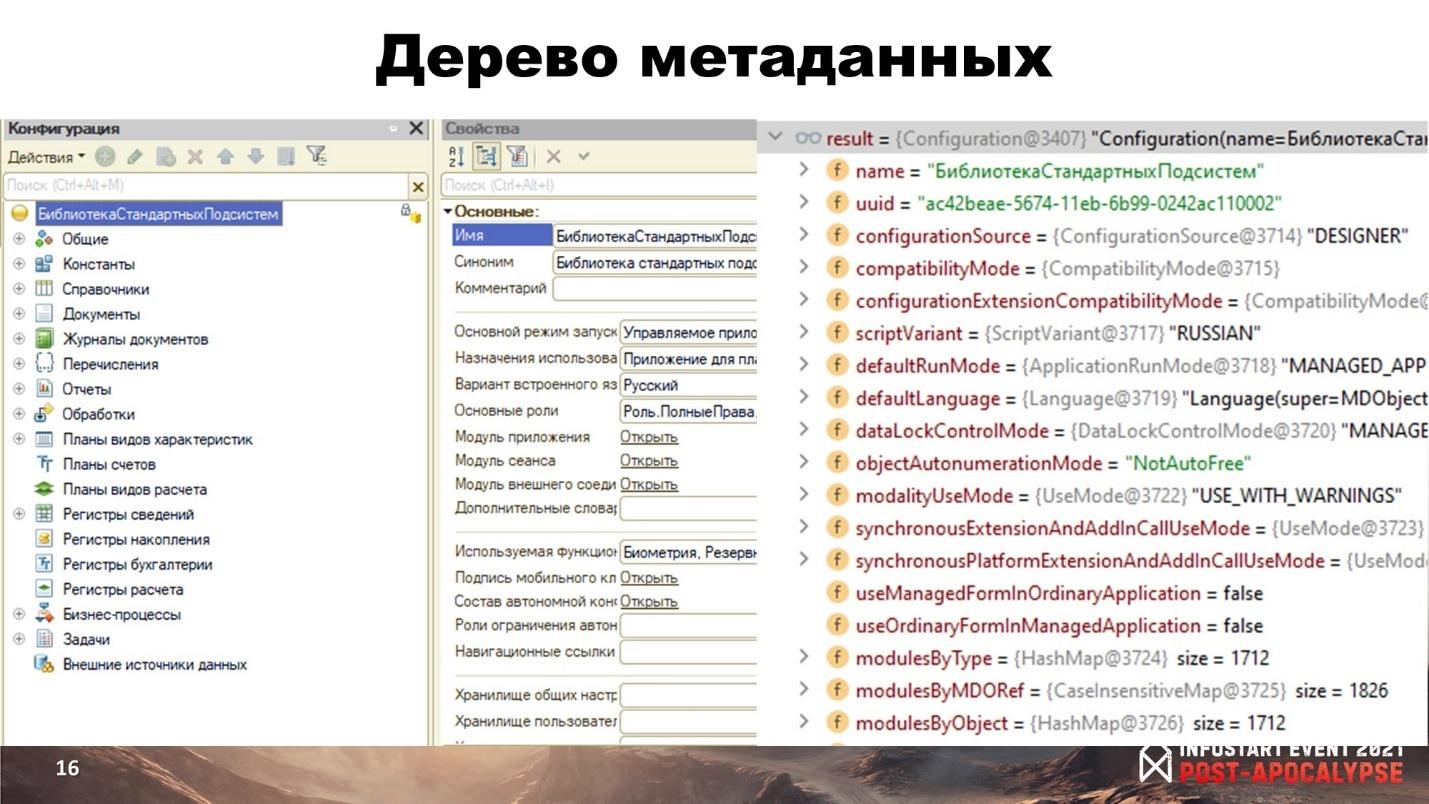
Из чего состоят метаданные? Как их можно представить?
Справа на слайде представление корня конфигурации в виде объекта. Здесь вперемешку и свойства корня, и дочерние объекты (например, документы или общие формы), и какие-то служебные коллекции. Но в целом с этим работать пока еще удобно.
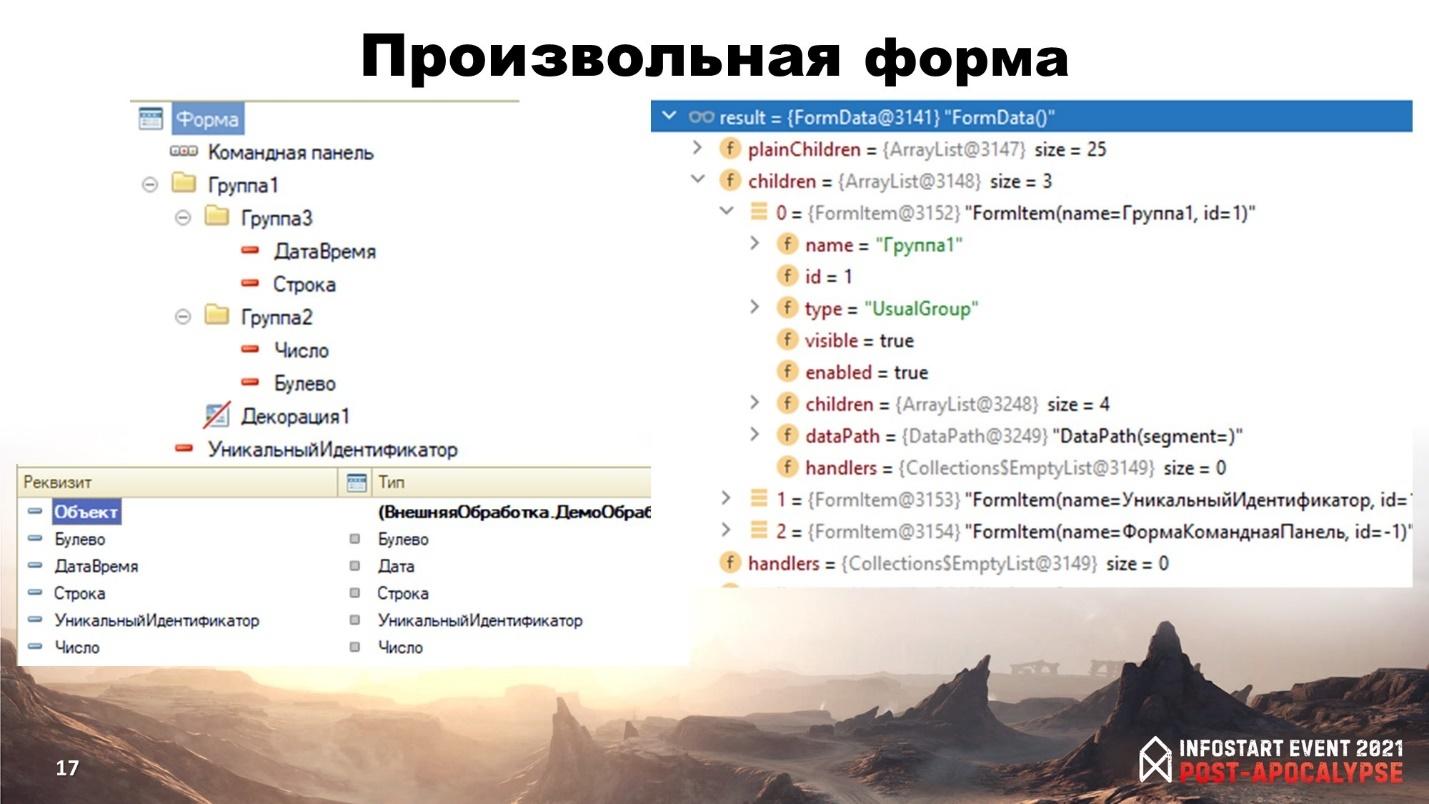
Более сложный пример – это форма.
Слева у нас представление простой формы, которую мы можем нащелкать в конфигураторе, а справа ее представление в модели.
Тут помимо атрибутов, команд, обработчиков можно увидеть иерархический или плоский список элементов формы.
Для чего все это нужно? Например, можно написать проверку, которая будет проверять, что у всех элементов формы путь к данным написан корректно. Либо в текстах модуля проверить, что все элементы формы, к которым мы обращаемся, существуют.
Точно так же можно анализировать реквизиты объектов метаданных и проверять обращения к ним в запросах.
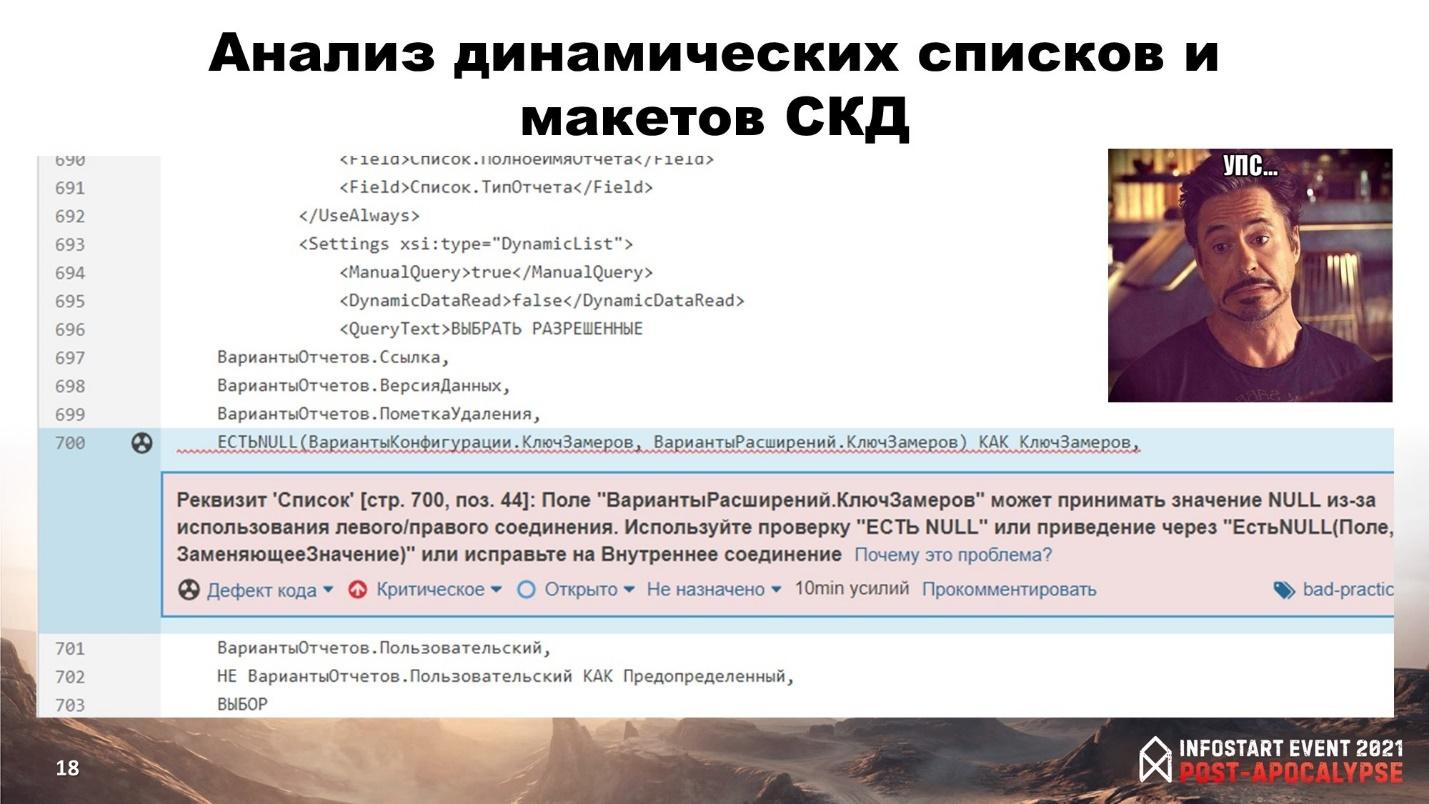
Давайте посмотрим на примерах – начну с доп. возможностей анализа текстов запросов.
Имея модель СКД-макетов и динамических списков мы можем получить тексты запросов и прогнать их на существующие проверки.
В данном случае на слайде проблема с соединениями и значениями «NULL». Разработчик себя обезопасил, но не до конца – второе значение тоже может принимать значение NULL.
Соответственно, может произойти ситуация, когда поиск по этому полю в динамическом списке будет работать некорректно.
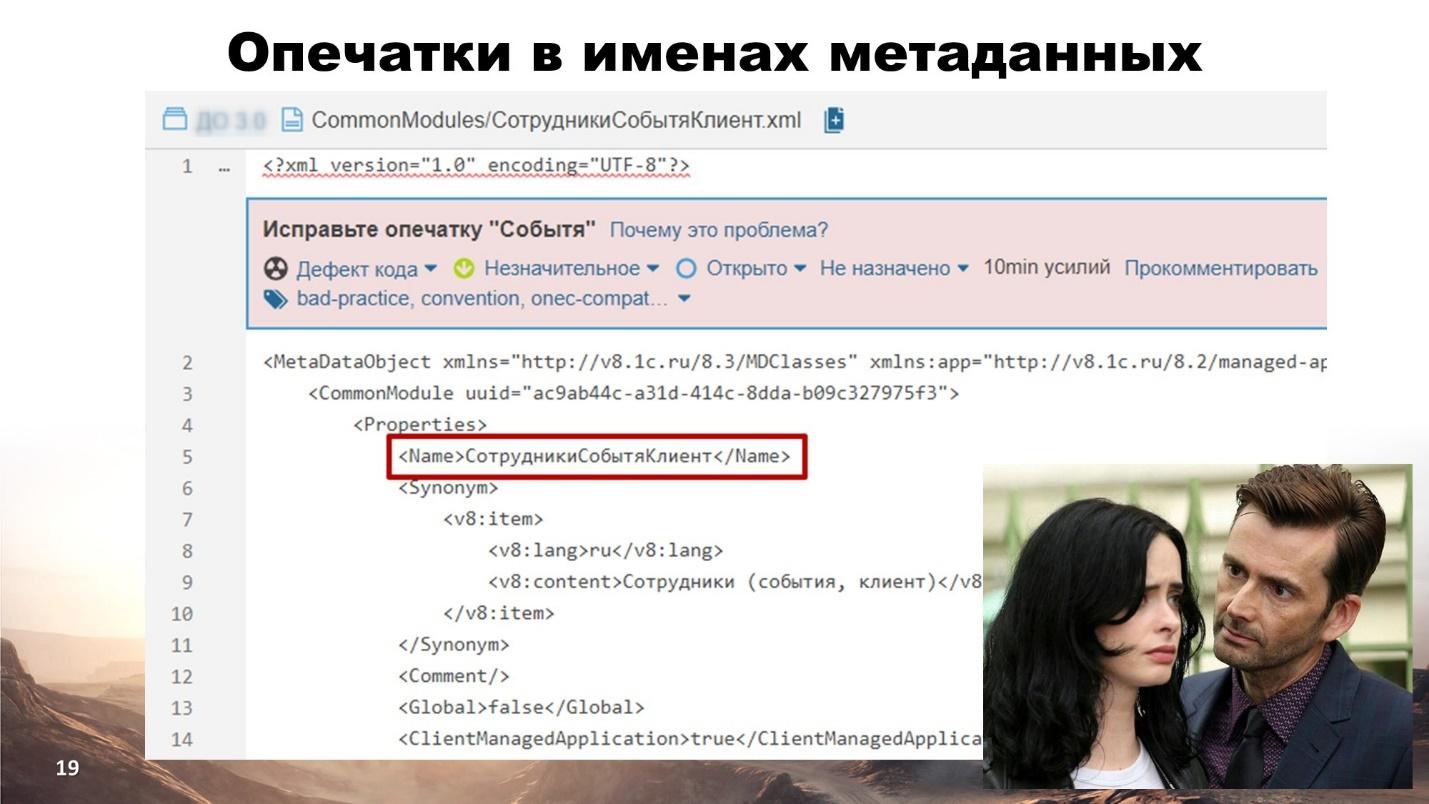
Идем дальше – опечатки в именах справочников, общих модулей и т.п.
Прогоняем элементы метаданных, проверяем опечатки.
Такие опечатки можно найти в отраслевых решениях. Особенно печалит, что это требование является обязательным при сертификации 1С-Совместимо.
Единственный выход – исправить опечатку и прикладной код, пока проблема не разрослась.
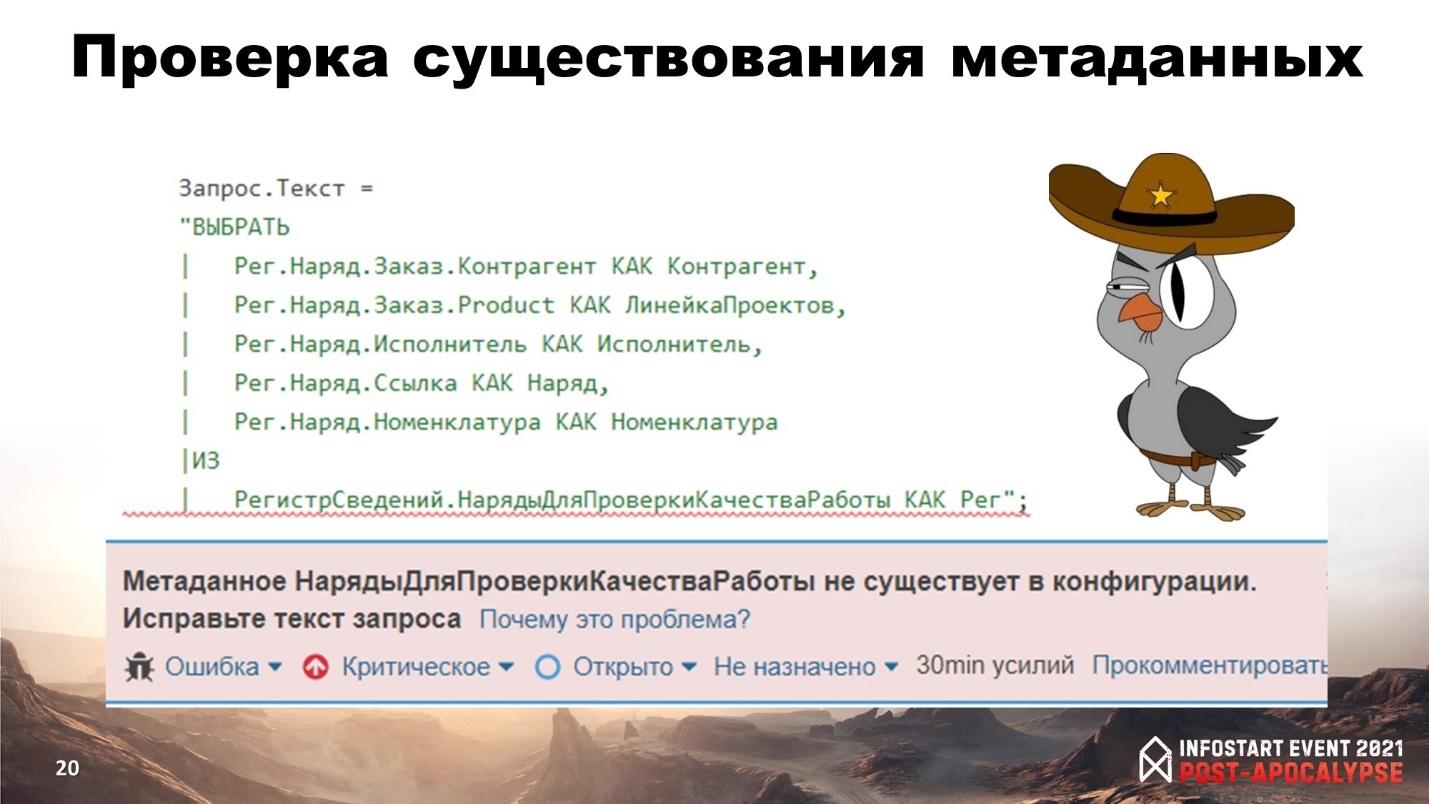
Следующий пример. Одно из самых полезных правил проверки текстов запросов – это проверка существования метаданных, о которой я говорил ранее. Может возникнуть ситуация, что, допустим, объект метаданных удаляется, переименовывается, либо какая-то подсистема внедряется, где его забыли. В данном случае текст запроса у нас был найден в обработке в одной из конфигураций.
И выводов у меня, как минимум, несколько.
-
Во-первых, никто не искал использование этого метаданного в тексте запросов.
-
Во-вторых, если этот объект метаданных изменялся давно, то либо этой обработкой пользуются очень редко, либо это просто мертвый код, и его нужно обязательно удалить.
Модуль контекста и конфигурация «Context collector for BSL» для сбора контекста платформы
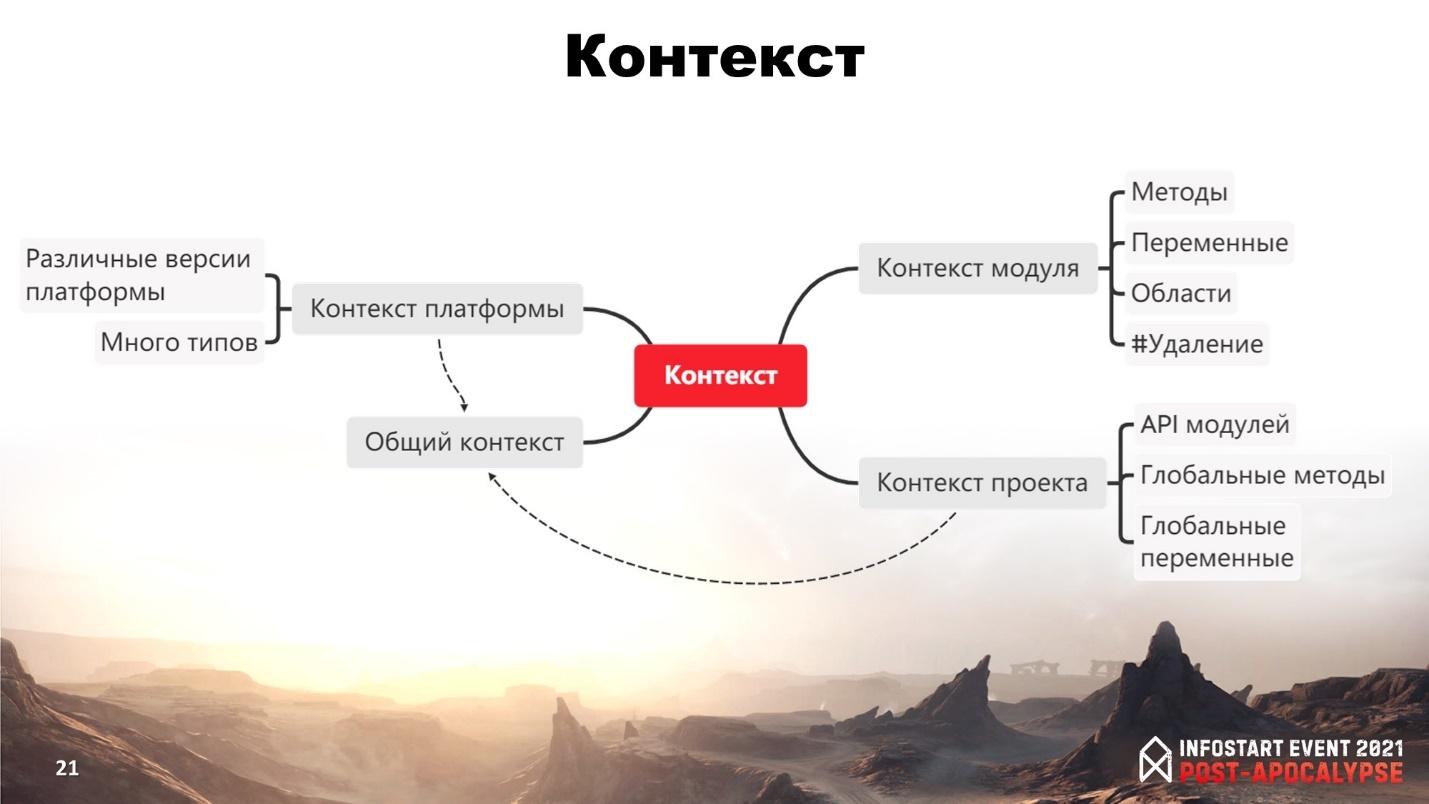
Следующий компонент статического анализа – это контекст, куда относится:
-
Контекст модуля
-
Контекст проекта
-
Контекст платформы
-
Общий контекст.
В контекст модуля входят:
-
Методы
-
Переменные – их описание и определение.
-
Области
-
И инструкции препроцессора из расширений, которые регулируют удаление и вставку объектов
Хороший пример использования контекста модуля – это использование недокументированных параметров методов в публичном API.
Следующий контекст – это контекст проекта. Он состоит из публичного API модулей и глобальных методов. Такой контекст позволяет реализовать более сложные проверки, например, использование устаревших методов.
Но самая трудная задача – это разобрать и получить контекст платформы. Нужно учитывать, что версий множество, соответственно, нужно хотя бы поддерживать версию с «8.2.19». У нас сейчас данные по контексту платформы частично захардкожены, но мы параллельно ведем разработку проекта, чтобы делать это прозрачно и более удобно.

Для этой цели на GitHub есть открытый проект https://github.com/otymko/bsl-context-collector
Он читает справку 1С и фиксирует ее в информационную базу. Затем с этими данными можно провести различные трансформации, и все это выгрузить в произвольном формате.
Как раз этими данными мы и пользуемся в модуле контекста платформы, чтобы правильно проверять устаревшие методы и свойства платформы.
Имея контекст платформы и контекст проекта можно собрать единый глобальный контекст и начать проверять вызовы глобальных методов.
Какие проблемы можно выявить

Возвращаемся к примерам. Когда вы пилите типовую конфигурацию либо свою на базе БСП, вы, скорее всего, рано или поздно, будете использовать методы из публичных API.
Хороший пример – метод «СообщитьПользователю» из конфигурации «Библиотека стандартных подсистем». Раньше этот метод был только в модуле «ОбщегоНазначенияКлиентСервер», теперь реализацию разделили – этот метод есть в общем модуле «ОбщегоНазначения» и в модуле «ОбщегоНазначенияКлиентСервер», где он помечен в документирующем комментарии меткой «Устарело».
Соответственно, когда разработчики БСП будут уверены, что они больше не будут поддерживать этот API, удалят этот метод, возникнет очень неприятная ситуация – потребуется потратить больше времени на доработку этой функциональности у себя.
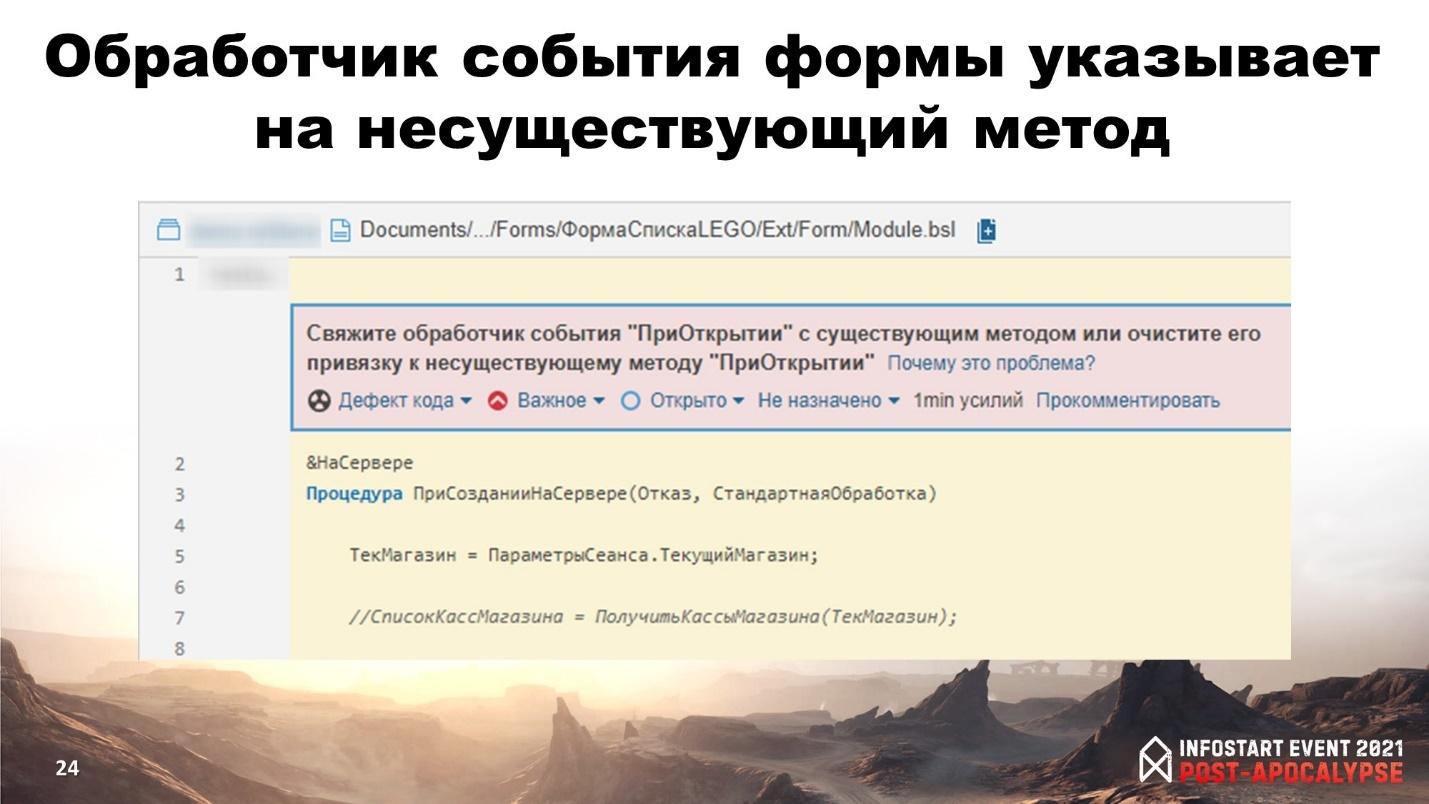
Следующая проверка – встречались с ситуацией, что обработчик у элемента формы почему-то не работает? Такая проблема возникает, когда изменения переносят из конфигурации в конфигурацию, либо разработчик сначала создал процедуру обработчика для события элемента формы, а потом эту процедуру удалил или переименовал, а в элементе формы эту привязку не поменял.
Эта проверка как раз и отслеживает такие ситуации – с помощью контекста модуля – мы знаем список методов, которые есть. И модель формы – мы знаем обработчики для ее элементов и сверяем, все ли у нас соответствует.
Control flow graph или граф потоков управления
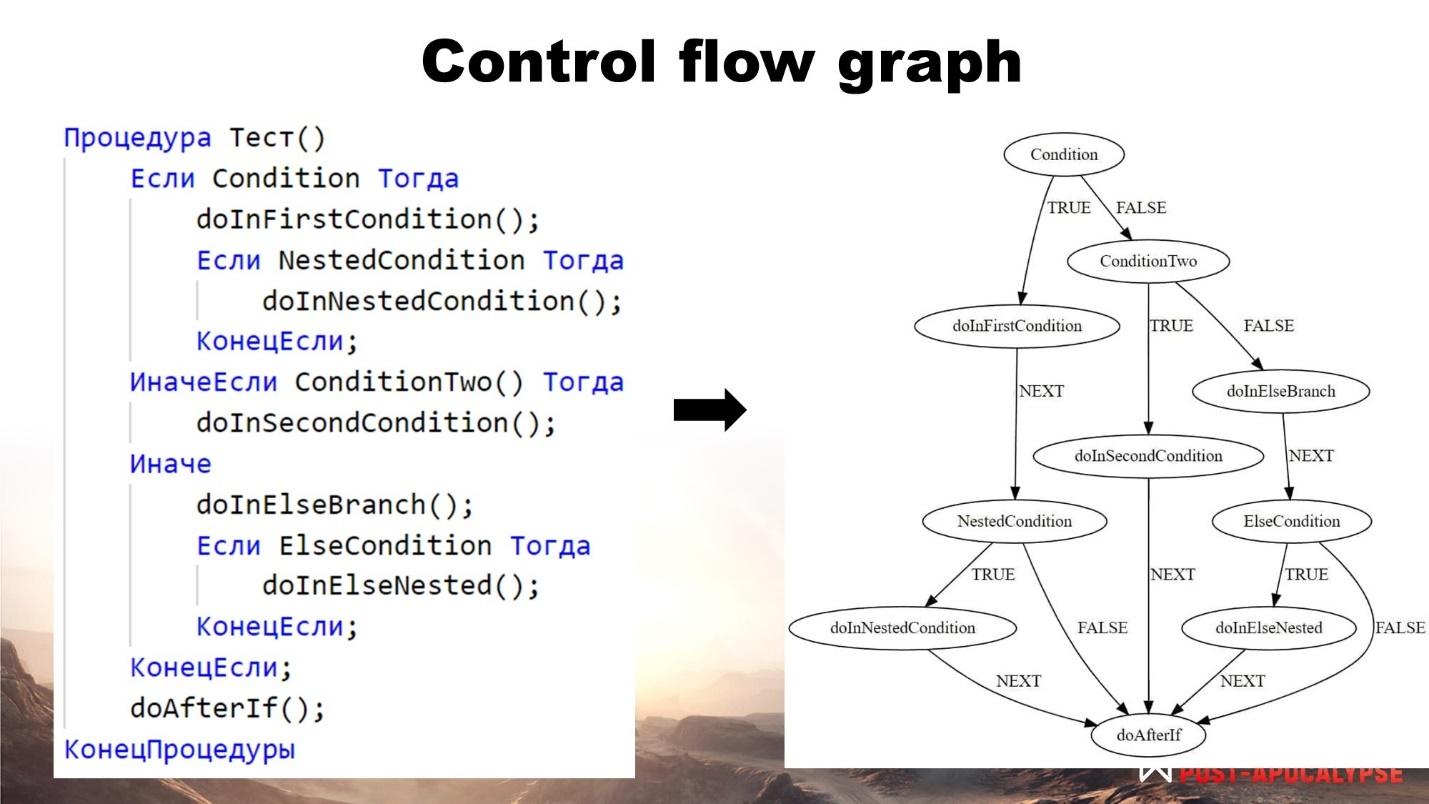
Напоследок хочу рассказать об еще одном интересном модуле статического анализа – это граф потоков управления, сокращенно «CFG».
«CFG» – это граф, в котором мы знаем все пути выполнения кода.
В графе есть:
-
два спецблока – входной и выходной блок;
-
узлы операторов;
-
дуги, которые представляют собой инструкции перехода.
Давайте посмотрим на примере. На слайде – процедура Тест(), в которой есть:
-
блок с условиями;
-
и вызов метода «doAfterIf()».
Справа вы видите представление этой процедуры в виде дерева, с которым мы уже можем работать в проверках.
В примере представлено два вида выражений – это «expression_statement» и «if_statement». В нашей реализации таких видов может быть 13.
Теперь с помощью графа потока управления мы знаем все возможные пути выполнения процедуры, и можем это использовать в проверках.

На слайде показан классический пример недочета при реализации функции.
Как только в переменной «ТекстОбласти» появится новое значение, функция вернет «Неопределено» за счет скрытого оператора возврата.
Это – неочевидное поведение алгоритма, и иногда такие проблемы не получается быстро выявить. «CFG» позволяет получить все пути выполнения кода и проверить все выходы из блока на «Возврат» или «ВызватьИсключение».
Какие есть статические анализаторы для 1С

Теперь хочется рассказать, какое еще есть ПО для статического анализа для 1С.
-
Как я говорил ранее, есть плагин для SonarQube от сообщества 1c-syntax. Он написан на Java.
-
Также у фирмы «1С» есть расширенная проверка конфигураций, которая доступна из меню конфигуратора, либо мы можем ее вызвать с помощью пакетного режима платформы.
-
Далее, есть платформа EDT, в которой реализовано множество проверок статического анализа, их там более ста. Они работают с помощью модуля v8-code-style. Это модуль, который 1С сейчас разрабатывает в OpenSourсe.
-
Кроме этого, на 1С есть конфигурация «1С:Автоматизированная проверка конфигураций». Развитие этого проекта сейчас остановилось в пользу EDT, но релизы еще выпускаются.
Планы и полезные ссылки
Хочется рассказать о планах – что мы собираемся сделать по нашему статическому анализу:
-
мы хотим выпустить контекст платформы;
-
поддержать мультиконтекст при анализе, когда мы хотим анализировать и конфигурацию и обработки либо расширения;
-
хотим выпустить MVP анализа потока данных (DFA) – пока планируем, изучаем подходы, хотим реализовать для начала примеры с примитивами, чтобы вызовов лишних не было и т.п.
Материалы, которые использовались в рамках доклада:
Вопросы
Сколько времени занимает статический анализ ERP?
Помимо стат. анализа есть еще расчет авторов – кто какую строчку изменил (git blame). Если его откинуть, то на средних раннерах статический анализ занимает примерно 12-15 минут. Но это только на стороне клиента. Еще потом запускается процесс на самом сервере SonarQube, который эти данные загружает. На облачном сервере SonarQube, который мы используем, это тоже происходит в течение 10-15 минут, в зависимости от количества изменений. В первый раз будет подольше.
Когда мы коммит помещаем, Sonar анализирует изменения только в этом коммите?
Нет, Sonar всегда анализирует полностью проект, потому что когда он проанализировал, он сверяет данные с предыдущими замечаниями. И, если что-то пропало, он это замечание закрывает. Поэтому анализ происходит весь.
Если хочется анализировать только новый код, лучше пользоваться линтерами в платформе EDT или в конфигураторе 1С.
Насколько различается функциональность вашего плагина и 1С (BSL) Community Plugin?
Если вы хотите видеть в плагине какую-то конкретную диагностику, но ее сейчас нет, вам нужно либо реализовать эту проверку самим, либо надеяться, что в Community кто-то ее сделает, либо кого-то нанять, либо не ждать в принципе.
В нашем плагине мы в режиме доработок интересные проверки делаем оперативно и сразу включаем в ближайшие релизы. Если проверка специфическая, то договариваемся с заказчиками.
Разница у нас в качестве поддержки и в количестве проверок, а также в том, что у нас это – основная работа, мы это пилим фуллтайм. В Community люди пилят это по желанию – у кого есть желание, те и разрабатывают.
Как нам использовать у себя вашу систему при разработке? Какие первые три шага нужно сделать, чтобы внедрить у себя статический анализ?
Первый момент – организационный. Вам нужно решить, что вы точно хотите использовать у себя статический анализ.
Второй шаг – берете инструкцию, и по ней выгружаете конфигурацию в XML-файлы, рядом добавляете файл с настройками и запускаете sonar-scanner, который все это отправит в сервер SonarQube (вам его, соответственно, тоже нужно установить).
И все, это все шаги. Но это – ручные действия.
Потом идет развитие. Если у вас есть CI, вы можете в Jenkins, в GitLab-CI либо в GitHub-CI настроить уже автоматические действия. Допустим, появился новый коммит в проекте Git, автоматически по какому-то триггеру запускается событие, которое анализирует.
Следующий этап – строится проверочный контур, где уже одним из этапов может выступать как раз анализ SonarQube.
Дальше вы для себя можете определить, какие вам нужны проверки, и потом уже закручивать себе гайки. Например, вы можете решить, что уязвимости вообще нельзя пропускать. Соответственно, устанавливаете порог качества «Количество уязвимостей = 0», и при нахождении уязвиомстей ваша линия сборки теперь будет падать.
Развивать можно бесконечно.
Все говорят про SonarQube, но я использую PhoenixBSL на локальном компьютере. Планируете ли вы его дальше развивать, добавлять новые правила?
PhoenixBSL сейчас работает в двух режимах.
Первый режим основывается на проекте BSL Language Server, поэтому количество проверок зависит от него – если в BSL Language Server сделают новые проверки, они появятся в PhoenixBSL.
При работе в этом режиме у PhoenixBSL есть сейчас три недочета.
- Первый недочет – он не знает, какой мы файл редактируем.
- Второй недочет – он не знает, что существуют метаданные, т.е. этих проверок сейчас не хватает.
- И третий недочет – нет возможности смотреть diff, т.е. мы написали новый код, и мы хотим посмотреть только новый код – быстро, без всего списка замечаний, потому что сейчас чаще всего люди дорабатывают типовые конфигурации и там много шума идет от этих типовых отраслевых решений.
А во втором режиме вы используете сервер с нашим плагином к SonarQube. Вы можете получить к нему доступ, чтобы запускать анализ локально, если вы что-то дорабатываете в OpenSource. По его подключению есть статьи для двух платформ разработки – для EDT и для конфигуратора.
Вы можете попробовать сами локально все это у себя погонять – будет скачан плагин и запущен анализ в ограниченном режиме SonarLint (без расчета метрик, подсветки и всего подобного).
Вопрос по поводу построения AST-дерева для запросов. Можно ли как-то ему скормить текст запроса из 1С и получить обратно JSON с деревом запроса? Я находил подобные решения на GitHub для модулей 1С – там очень удобно, можно ему скормить модуль, и отобразить в виде дерева переменные и методы, которые находятся в определенных экспортных процедурах. А для запросов такой штуки нет.
Здесь есть как минимум три варианта.
Первый вариант – вы можете взять проект BSL-parser от сообщества 1c-syntax, написать над ним надстройку, которая анализирует текст запроса, чтобы он вам выдал JSON. Но для этого нужно будет покодить на Java.
Второй способ – если вы используете наш плагин, там есть инструмент SonarTools, он строит XML, которую можно использовать и иерархический список, с которым вы можете взаимодействовать. Ему на вход можно передать и текст, и путь к файлу, который нужно проанализировать
И третий способ – есть парсер модулей на OneScript с функциональностью анализа текста запросов. Соответственно, там уже можно будет на 1С накодить и сделать выгрузку в JSON.
Проще всего сделать доработку в плагине BSL LS и там написать правила на Java – если вы хотите проверки свои писать. А если пользуетесь нашим плагином, используйте SonarTools либо напишите нам, что вам нужна новая проверка. Мы уже вам поможем.
*************
Данная статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Post-Apocalypse.


Вступайте в нашу телеграмм-группу Инфостарт