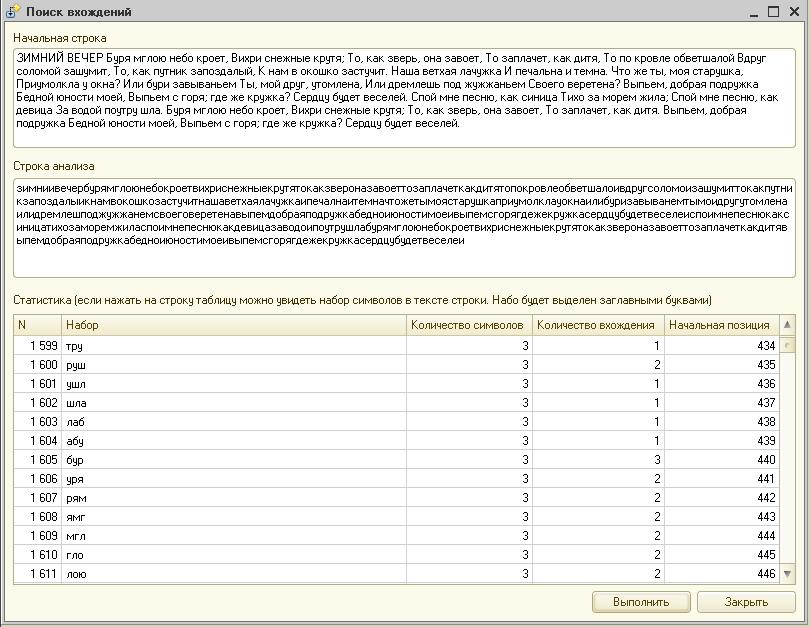
В конкурсе "Вопрос-Решение" была задана задача": "Найти символьные вхождения в строке". Вот моё решение.
Файлы
ВНИМАНИЕ:
Файлы из Базы знаний - это исходный код разработки.
Это примеры решения задач, шаблоны, заготовки, "строительные материалы" для учетной системы.
Файлы ориентированы на специалистов 1С, которые могут разобраться в коде и оптимизировать программу для запуска в базе данных.
Гарантии работоспособности нет. Возврата нет. Технической поддержки нет.
Данная внешняя обработка для платформы 1С:Предприятие реализует усовершенствованный алгоритм Левенштейна для вычисления схожести строк с учетом различных лингвистических особенностей русского языка. В отличие от классической реализации, этот алгоритм учитывает фонетические, визуальные и контекстные особенности набора текста.
На написание данной работы меня вдохновила работа @glassman «Переход на ClickHouse для анализа метрик». Автор анализирует большой объем данных, много миллионов строк, и убедительно доказывает, что ClickHouse справляется лучше PostgreSQL.
Я же покажу как можно сократить объем данных в 49.9 раз при этом:
1. Сохранить значения локальных экстремумов
2. Отклонения от реальных значений имеют наперед заданную допустимую погрешность.
Что ж... лучше поздно, чем никогда.
Подсистема 1С для работы с регулярными выражениями: разбор выражения, проверка на соответствие шаблону, поиск вхождений в тексте.
В статье анализируются средства платформы для решения системы линейных уравнений в 1С. Приводятся доводы в пользу некорректной работы встроенных алгоритмов, а значит потенциально некорректного расчета себестоимости в типовых конфигурациях.
Под конструктивной критикой можно понимать лучшее решение. В этом смысле моя критика будет неконструктивной.
1. Пример текста к задаче был бы гораздо интереснее и привлек бы больше внимания, если бы являлся кодом программы на языке 1С. Поиск повторов в тексте программ – для многих здесь более актуальная задача, чем анализ стихотворного текста.
2. Относительно небольшое решение должно публиковаться в тексте статьи, а текст обработки прилагаться для проверки. Комментировать решения, методы и алгоритмы удобнее, имея их перед глазами.
3. В обработке по сути, два отдельных метода: предварительная обработка строки (фильтрация и замена символов) и собственно, поиск повторов.
4. Фильтрация и замена символов сделана «с многочисленными огрехами»:
4.1. Сам по себе принцип «наращивания» результирующей строки приведет к тому, что на реальных данных производительность метода быстро деградирует (см. статью ). То есть здесь ГОРАЗДО быстрее будет работать цикл из функций «СтрЗаменить».
4.2. В такой простой задаче используется три разных механизма фильтрации и замены: структура для замены (???), поиск в строке алфавита для фильтрации и приведение к нужному регистру. Все преобразования можно выполнить через одно соответствие.
4.3. Структуру для замены использовать неправильно – она для этого не предназначена (хотя и работает, но логарифмической линейкой тоже гвозди забивали) – см. комментарии к статье .
4.4. Зачем заменять на пустышку мягкие и твердые знаки? – Их лучше исключить из алфавита.
4.5. Какой смысл в плавающих отступах?
5. Никаких алгоритмических находок нет. Это решение задачи «в лоб». Время решения пропорционально длине строки в кубе! Тогда как применение суффиксного массива и алгоритма Касаи дает линейное время (не вполне уверен именно в линейности, но точно меньше квадрата). Но даже просто кодирование поиска повторов также не может быть образцом:
5.1. Лишние присваивания исходной строки.
5.2. Лишние вычисления длины строки (в ограничении цикла Для функции вычисляются единственный раз, поэтому нет нужды вычислять длины заранее).
5.3. Вместо ограничения диапазона внутреннего цикла делается проверка длины вырезки, а ведь длина строки долго (пропорционально длине строки) вычисляется.
5.4. Для уже отстатистированной подстроки опять считается число вхождений! (зачем закомментирована проверка?).
5.5. Если подстрока уже не найдена более одного раза, зачем искать еще раз искать более длинные подстроки? Результат будет тем же.
В общем, задача актуальная и интересная, а решение еще улучшать и улучшать.
(5) Провести рефакторинг Вашего решения - тут нет проблем, это не долго (но не интересно), а вот реализовать правильный алгоритм - пока не решил - стоит ли этим заниматься. Вообще не уверен, что на 1С следует решать сложные задачи обработки строк не как учебные. Это не та сфера применения, где платформа 1С эффективна. Для таких случаев разработчики заложили в платформу технологию внешних компонент и нужно использовать их.
(8) все же не давала мне покоя эта задача и я постарался ее решить. Решение приведено в статье . Правда, в самой статье акцент сделан на практическое применение - поиск повторяющихся фрагментов кода в типовых конфигурациях.
Получились очень интересные результаты (повторов кода в типовых - до фига и больше).
Решение описано штрих-пунктирно, но, если заинтересуетесь, могу дать пояснения. В целом, оказалось, что применив алгоритм Мандера-Майерса и Касаи, можно НА ЧИСТОМ 1С за 15 минут найти ВСЕ повторяющиеся фрагменты в строке из 3,5 миллиона символов.
До этого то же самое сделал на языке запросов, но получилось слишком громоздко и есть одно тонкое место - пока не стал доводить до ума, хотя осталось чуть-чуть.
(14) ildarovich,
Спасибо! вернее ОЧЕНЬ тебе БЛАГОДАРЕН за все твои решения и великие умения !!!
"В целом, оказалось, что применив алгоритм Мандера-Майерса и Касаи, можно НА ЧИСТОМ 1С за 15 минут найти ВСЕ повторяющиеся фрагменты в строке из 3,5 миллиона символов. "
- вот ведь !!!
если же смотреть на "Повторяемость кода в 1С" - то надо задать и другой вопрос - "А?!, где он не повторяется?" ... сложность написания программы коллективом сложнее чем представляется с т.з. "просто кода" т.к. не "код" определяет работу программы.
это как изволите анализировать? :)
Точнее, как собираетесь анализировать эти самые повторы?
Про невозможность в принципе "увидеть" код типовых - не говорю уже.
И никакая 8.3 тут не поможет, пока 1С не сделает компиляцию отдельно от платформы.

{kind=link}