В одном проекте возникла необходимость вывести отчет с иерархией. То есть без нее. Там иерархия не простая, а с неудобствами. Если оставить только суть, задача выглядит вот как.
Есть справочник Укладки. В нем есть табличная часть, состоящая из строк:
ВложеннаяУкладка, Количество
ВложеннаяУкладка – элемент того же справочника Укладки. Во вложенной укладке, в свою очередь, тоже могут быть вложенные укладки, и так далее. Зацикливание вложенности не допускается. С этим у нас строго. Но об этом потом.
В нашей базе укладка – это нечто такое, что содержит в себе другие предметы, но воспринимается как единое целое. Пока не откроешь. Например, сумка, рюкзак, чемодан, аптечка, маникюрный набор, кошелек и вообще что угодно. Аптечка может быть в сумке, сумка в чемодане – вот вам и вложенность.
А неудобство заключается в том, что экземпляры одной и той же вложенной укладки могут находиться на разных ветках дерева вложенности и даже в разных строках внутри другой укладки, причем в любом количестве.
Например, собираемся мы в поход туда, где нет розеток. Совсем нет. Никаких. А потому запасаемся контейнерами с батарейками. Распихиваем по всем карманам всех рюкзаков. А также в аптечки и кошельки. И даже в маникюрный набор. В итоге очень развесистое дерево вложенности получается. Но при этом все контейнеры – это один и тот же элемент справочника Укладки.
Ну так вот, очень хочется в запросе для отчета получить плоский список, содержащий все вложенные укладки, оказавшиеся в одном дереве, причем с указанием количества вхождений каждой. И чтобы никакой иерархии.
В общем-то, задача легко решается средствами процедурного языка. Рекурсию не вчера придумали. Но в отчете хочется обойтись языком запросов. Ну ладно, сам запрос можно сделать процедурными средствами, но результат все равно лучше получить из запроса.
И проблема здесь в том, чтобы правильно посчитать количество. То есть решения, которые просто отмечают факт вложенности, не подходят. Например, хорошо известный прием со связью наборов данных в СКД не годится именно по этой причине.
Но тут нашлась отличная статья «Транзитивное замыкание запросом». Кратко перескажу суть.
Допустим, есть у нас иерархия, в которой все элементы уникальны. И вот нужно получить список всех пар элементов, которые связаны отношением подчиненности, хоть непосредственно, хоть опосредованно. Решение просто восхитительное.
На первом этапе составляем список всех пар элементов, связанных непосредственной подчиненностью. То есть собираем все переходы в один шаг. В статье это немного по-другому называется. В общем, тут все очевидно.
Заодно добавляем туда пары, состоящие из одного и того же элемента. Это такой чисто математический трюк. Если есть переход в один шаг, почему бы не быть переходу в ноль шагов? Вот это как раз они и есть.
А потом в несколько приемов весело и задорно соединяем эти кусочки. Те, которые соединяются, разумеется. На каждом этапе максимальная длина перехода увеличивается вдвое. В итоге за несколько повторений можно охватить сколь угодно развесистое дерево. Нужный запрос формируется процедурно, а выполняется там, где положено.
Великолепно. Но не годится. То есть прямо так не годится. Надо слегка доработать.
Прежде всего, что там с количеством? Как будто бы все просто. Соединяя кусочки, надо умножать количества в них и записывать результат в объединенный кусок. У переходов в ноль шагов количество равно единице. Кстати, они сами играют роль единицы в арифметике переходов. А заодно и нуля. Такая вот арифметика.
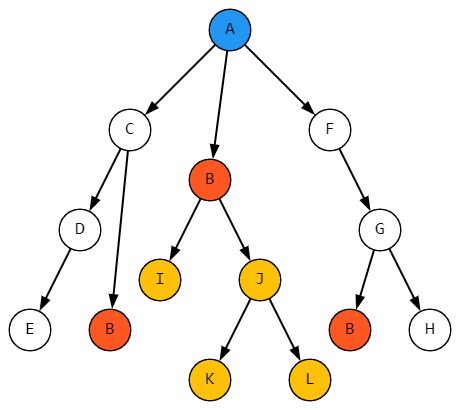
Проблема в другом. Наша база, как уже было сказано, легко допускает вот такие деревья вложенности:
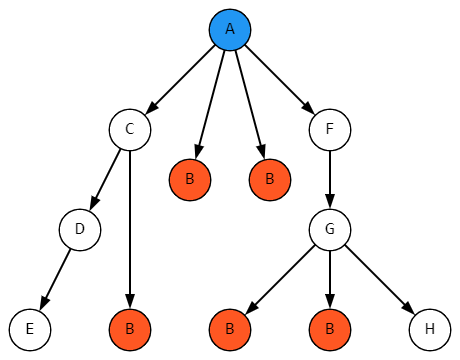
Ну ладно, воспользуемся полем Количество, раз уж оно и так есть, и объединим укладки, непосредственно вложенные в одну и ту же укладку:
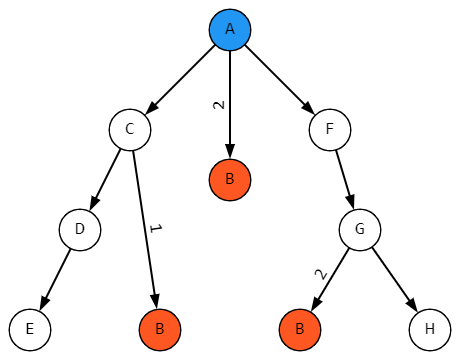
Но сюрприз ожидает на этапе соединения кусков. Как только фрагменты AC и CB соединятся в AB, кривой путь от A до B моментально будет перепутан с прямым. То есть нет, здесь еще не будет. Просто разные значения поля Количество не позволят перепутать маршруты.
А вот когда соберется путь через F и G, тут и количество совпадет. В итоге из нашего отчета пропадут два контейнера с батарейками. Ну, или что там у вас.
Таким образом, возникла задача как-то идентифицировать каждый маршрут. Но тут внимательный читатель спросит, а в чем, собственно, проблема? Видно же, что укладки B висят каждая на своей ветке. Раздаем номерки – и все дела. Получаем иерархию уникальных элементов и делаем, как в статье написано. А в конце номерки отнимем, и укладки снова станут одинаковыми. Тогда и посчитаем общее количество.
Вот тут-то нас и поджидает настоящий сюрприз. Неправильное на картинке дерево.
Точнее, в физическом мире, где реально будет 5 одинаковых контейнеров с батарейками, оно так и выглядит. Но только не надо забывать, что в базе данных все 5 укладок B – это один и тот же элемент справочника Укладки.
Так что с точки зрения программиста правильное дерево выглядит совсем по-другому:
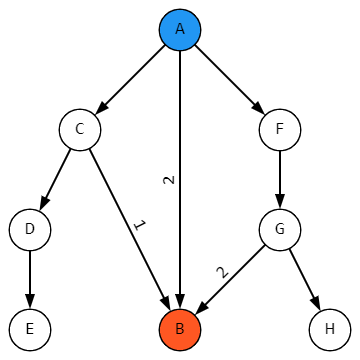
В общем, некому там раздавать номерки. Все пути от A до B не только начинаются в одном месте, но и заканчиваются в одной-единственной точке. Надо как-то накапливать идентификаторы промежуточных укладок и постараться не растерять их по дороге.
Однако ж, идею с раздачей номерков тоже не стоит с ходу отбрасывать. После объединения укладок, вложенных в одну и ту же укладку, действительно получается, что разные экземпляры висят на разных ветках. И у них уже есть уникальные идентификаторы – ссылки на те самые укладки, в которые они вложены.
Неприятность лишь в том, что в запросах нельзя сделать со ссылками ничего такого, что могло бы нам пригодиться. Нет над ними никакой арифметики. Их даже в строку преобразовать нельзя. То есть в строку, которая содержит уникальный идентификатор. Да и просто в строку, с которой можно что-то делать.
А что насчет поля Код? Если не разрешать пользователям редактировать коды элементов справочника, то и оно сгодится. А как же, уникальная строка из 9 цифр. Или сколько захотите. Очень удобно. В общем, номерки нашлись.
Если не удалось отгородить поле Код от пользователей, можно прямо в запросе предварительно раздать элементам справочника номера с помощью функции АВТОНОМЕРЗАПИСИ(), а затем преобразовать их в строки. В версии платформы 8.3.20 такая возможность была наконец-то реализована. Только надо не забыть добавить к этим строкам разделители, чтобы 1 и 2 не совпали с 12.
В конце концов, можно добавить в элемент справочника реквизит, в который заранее класть УникальныйИдентификатор, но только в виде строки. Например, вот так:
&НаСервере
Процедура ПриСозданииНаСервере(Отказ, СтандартнаяОбработка)
ЭтоНовыйОбъект = Не ЗначениеЗаполнено(Объект.Ссылка);
Если ЭтоНовыйОбъект
Или Не ЗначениеЗаполнено(Объект.УИдСтрока) Тогда
Объект.УИдСтрока = Строка(Новый УникальныйИдентификатор);
КонецЕсли;
КонецПроцедуры
Ладно, какие-то строковые идентификаторы нашлись. Осталось придумать, как собирать их по пути. А дело в том, что на этапе соединения кусков каждый маршрут собирается всеми возможными способами. Просто лишние дубли каждый раз выкидываются.
Нужно, чтобы независимо от способа сборки один и тот же путь всегда получал один и тот же идентификатор.
Самый простой вариант – соединять значения поля Код, раз уж они строковые. В итоге они соединятся именно в том порядке, в каком идут вложенные укладки. Да, чуть не забыл, у переходов в ноль шагов код – пустая строка.
Однако мы все знаем, что в запросах ограничена длина строк, над которыми выполняются операции сравнения. Делим 1024 на 9 – получилось 113. Очень трудно представить себе реальную укладку с сотней уровней вложенности. Можно считать, что этого вполне хватит, учитывая назначение нашей базы.
Другой вариант – вычислить хэш поля Код каждого элемента справочника, а потом складывать хэши при сборке кусков. Есть опасение, что сумма где-нибудь да совпадет, но нам достаточно различать только те пути, у которых совпадают начала и концы. То есть количество значений резко ограничено, а диапазон превосходит все разумные потребности. Зато никаких проблем с длиной строки, даже гипотетических.
Как в запросе вычислять хэш кода элемента справочника, показано в другой статье того же автора – «Расчет хэш-функции в запросе». Смотрите в ней Пример 1.
Вот тут сообразительный читатель снова задаст вопрос. Да, скажет он, от перестановки скобок сумма не меняется, так что складывать хэши можно во всех сочетаниях. Но ведь, как учили в школе, сумма не меняется и от перестановки слагаемых. Как тогда быть с вот такой ситуацией?
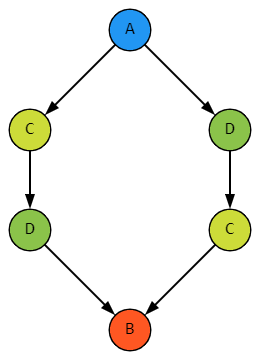
А никак. В нашей базе такая ситуация невозможна. В какой-то другой – может быть, а у нас – нет. Причина в отношениях вложенности. А еще в том, что все экземпляры какой-либо укладки – это один и тот же элемент справочника, и он содержит в своей табличной части сведения о непосредственной вложенности.
Получается, что в этом дереве в параллельных ветках показаны одна и та же укладка C и одна и та же укладка D. И то, что C в одной ветке содержит D, а в другой сама в ней содержится, означает только одно – зацикливание вложенности:
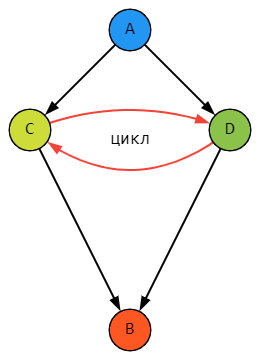
Как так получилось? Попробуем реализовать этот пример в базе. Допустим, сначала есть только левая ветка. Пока все хорошо.
Начинаем строить правую – добавляем D в корень дерева. Никаких проблем. Надо только внимательно смотреть, куда направляются стрелочки.
А теперь попытаемся вложить C в D. Возникает зацикливание вложенности, чего конфигурация нам сделать не позволит:
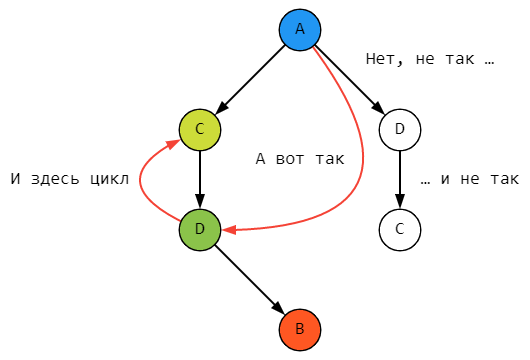
После этого останется провести стрелочку от C к B, но только на бумаге. Результат показан выше. А в физическом мире попытка реализовать такую вложенность породит кошмар завхоза, уходящий в бесконечность:
Между прочим, пример с перестановкой наглядно показывает отличие модели укладки в базе данных от ее реализации в привычном физическом мире. Очень трудно свыкнуться с мыслью, что добавление еще одного экземпляра вложенной укладки означает не просто кружок на схеме, а дублирование всей ветки, которая начинается с этой укладки.
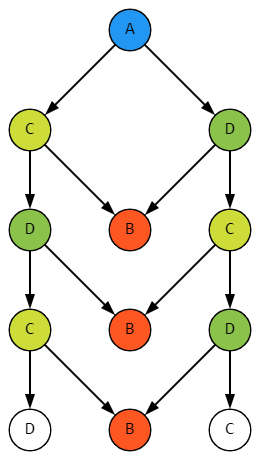
Вернемся к основному примеру. Если на дереве с тремя укладками B открыть ту, что поближе, структура вложенности будет выглядеть, к примеру, так:
На самом деле это означает, что в физическом мире должно полностью копироваться все содержимое укладки B:
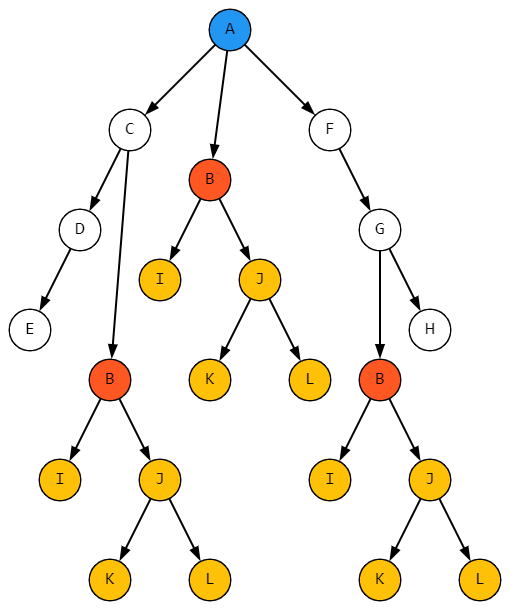
Как уже не раз было сказано, причина в том, что в базе данных существует только один элемент справочника, описывающий структуру укладки B:
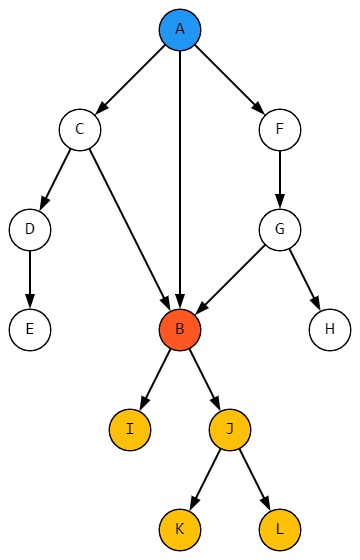
Если хочется, чтобы ветки, идущие из разных экземпляров B, отличались хотя бы в мелочах, необходимо создать разные элементы справочника. Они могут быть похожи, как близнецы, но все равно это разные элементы. И для примера с перестановкой пришлось бы создать разные элементы, даже если в физическом мире они выглядят совершенно одинаково.
На этом завершу рассуждения. Наверняка читатели давно уже хотят увидеть программный код. Но мне пришлось бы просто скопировать код из статьи, дополнив парой строчек от себя. Позвольте мне этого не делать.
Лучше я в завершение поблагодарю автора упомянутых статей, а также авторов онлайн-редактора Programforyou, в котором нарисованы все иллюстрации. Замечательный, очень удобный и понятный инструмент.