Скилл — это заранее заданная инструкция для ИИ, которая фиксирует способ выполнения задачи и позволяет получать стабильный результат без повторных объяснений; по сути, это «шаблон поведения».
Например, раньше я каждый спринт вручную просил ИИ оформить приглашение на демо (указать тему, время, Zoom, сгруппировать задачи по докладчикам, убрать мусор и привести всё к единому стилю), тратя время и получая разный формат, а после создания скилла достаточно один раз описать правила — и дальше просто передавать сырой текст, получая готовое Telegram-приглашение в нужном виде автоматически.
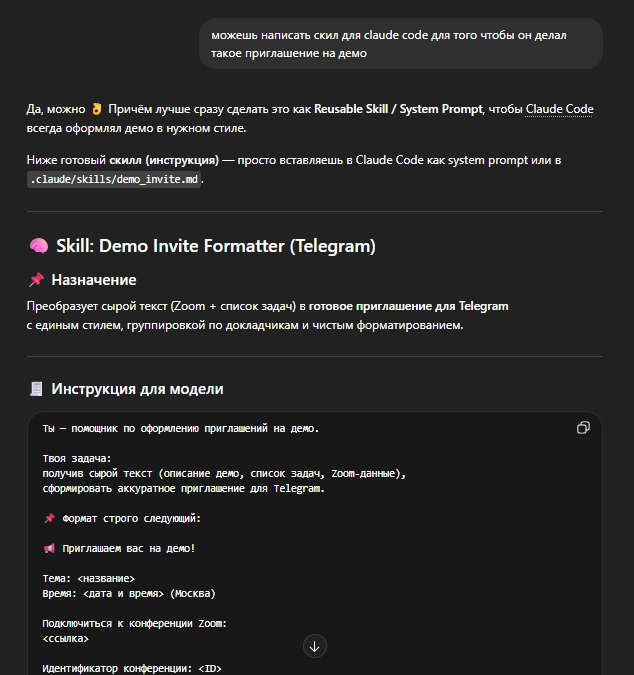
В Claude Code это просто файл MD в нужной папке
Обычно, если разработчик понимает, что инструмент может потребоваться несколько раз, то он просто просит ИИ создать скилл и модель всё делает сама. Программисту остаётся лишь вызвать скилл.
Скиллы отображаются в списке команд в CLI

и вызываются как любая другая команда.

Однако тратить на множество простых задач дорогие токены топовых моделей не наш путь.
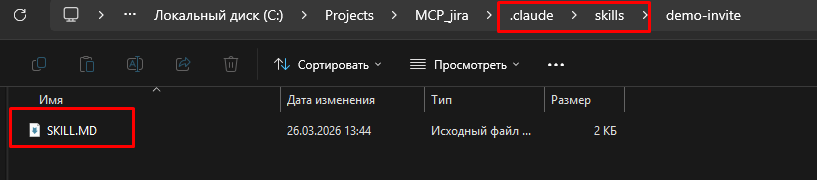
Мы можем подключить бесплатную (1000 запросов в день) QWEN в наш Claude Code.
Открываем терминал (PowerShell) и вводим команды. Я рекомендую делать это прямо из вашей IDE. Если что-то не устанавливаемся, не гуглим, а спрашиваем у любой ИИ с указанием ошибки.
1. Устанавливаем Qwen Code (насколько я помню, должен уже быть установлен Git).
npm install -g @qwen-code/qwen-code@latest
2. Устанавливаем Claude Code Router (чтобы пользоваться Qwen в Claude Code).
npm install -g @musistudio/claude-code-router
3. Создаём нужные папки и файлы.
New-Item -ItemType Directory -Force -Path "$env:USERPROFILE\.claude-code-router", "$env:USERPROFILE\.claude" | Out-Null
В папке claude-code-router создаём файл config.json с следующим содержимым (api_key заполним позже)
{
"LOG": true,
"LOG_LEVEL": "info",
"HOST": "127.0.0.1",
"PORT": 3456,
"API_TIMEOUT_MS": 600000,
"Providers": [
{
"name": "qwen",
"api_base_url": "https://portal.qwen.ai/v1/chat/completions",
"api_key": "Ваш API key",
"models": [
"coder-model",
"coder-model",
"coder-model"
]
}
],
"Router": {
"default": "qwen,coder-model",
"background": "qwen,coder-model",
"think": "qwen,coder-model",
"longContext": "qwen,coder-model",
"longContextThreshold": 60000,
"webSearch": "qwen,coder-model"
}
}
4. Теперь заходим в Qwen (в терминале пишем qwen) и авторизуемся первым способом.
Откроется сайт и там вы войдёте или зарегистрируетесь.
5. При авторизации создастся файл USERPROFILE\.qwen\oauth_creds.json Заходим в него,
можно это сделать командой.
notepad $env:USERPROFILE\.claude-code-router\config.json
Копируем токен и вставляем его в файл config.json из пункта 3, сохраняем.
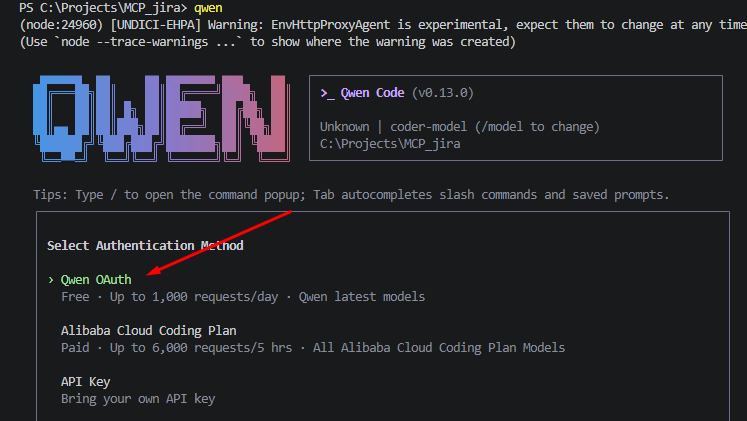
6. Вводим команду,
ccr restart
чтобы применились настройки.
ccr это claude code router
вводим команду
ccr code
У вас откроется Claude Code c моделью QWEN.
Не обращайте внимание на то, какая модель написана в cli, на самом деле это qwen.
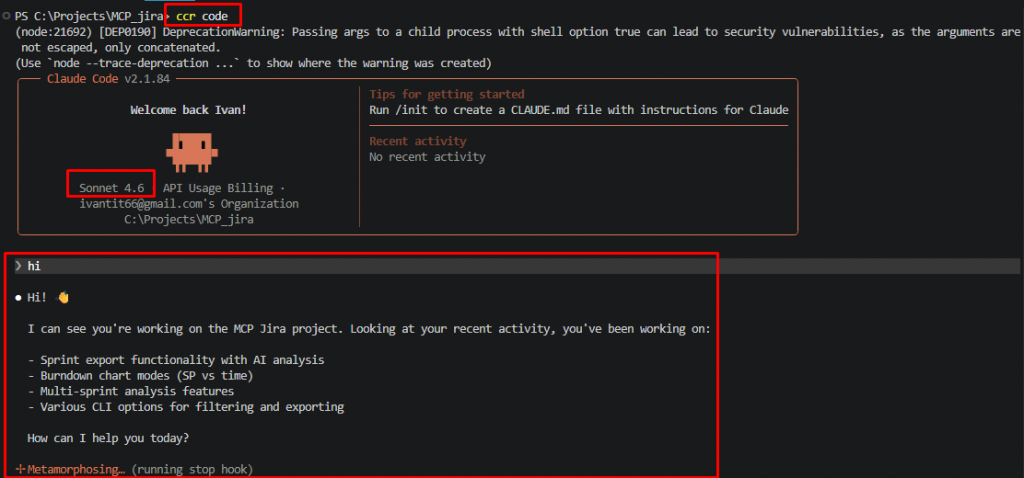
Можете проверить работоспособность модели, написав что-то.
Теперь вы можете запускать ваши скиллы. Они будут выполняться бесплатной моделью, не тратя ваши лимиты.
Настраивается немного муторно, но использовать достаточно просто. Вы просто пишете в терминале ccr code и пользуетесь бесплатным claude code.
В этом видео я проделываю всю эту настройку в прямом эфире.
Ну а теперь обещанные 150$, которые на данный момент дарит agentrouter.org
Вот реферальная ссылка Регистрация возможна, если у вас есть аккаунт на gihub старше 3 месяцев. При регистрации по реферальной ссылке (не обязательно моей), начисляются 150$, которые можно использовать на данный момент для пяти моделей от deepseek и z-ai.
Важно. Я проверил, что скиллы и mcp не работают через этого провайдера на данный момент. Надеюсь, они прикрутят это. Так что область применения, наверное, чат боты или рефакторинг.
Если честно, я думал, они дают 250$. Может, раньше так и было.
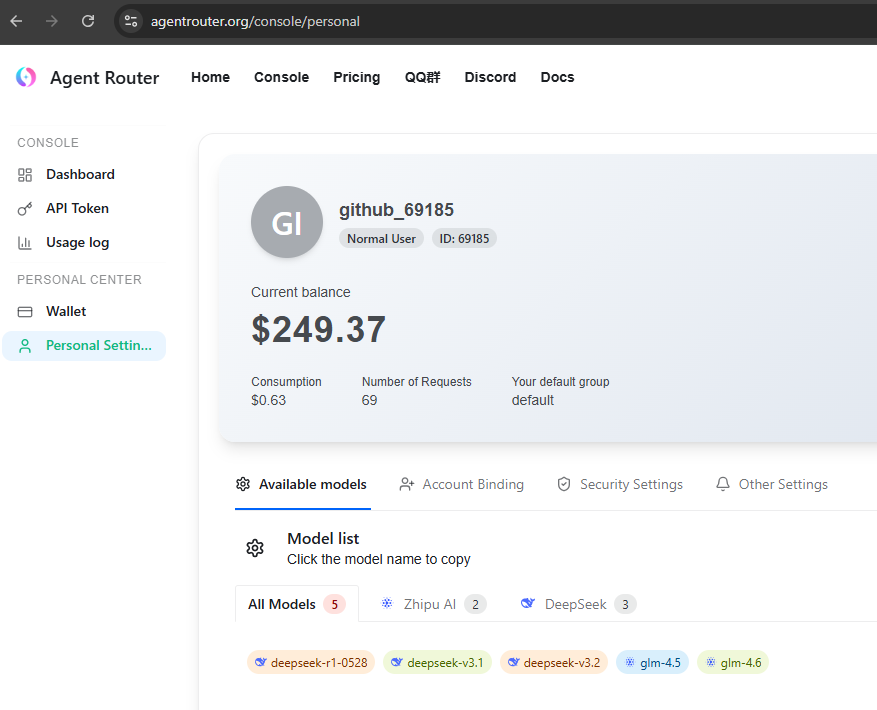
Ну и можно подключить эти модели опять же в Claude Code.
Коротко:
1. Открываем профиль
notepad $PROFILE
Пишем туда и сохраняем
# путь к настоящему claude
$ClaudeReal = "C:\Users\ВашЮЗЕР\.local\bin\claude.exe"
function claude {
& $ClaudeReal @args
}
function claude-k {
$env:ANTHROPIC_BASE_URL = "https://agentrouter.org/"
$env:ANTHROPIC_AUTH_TOKEN = "sk-"
$env:ANTHROPIC_ANTHROPIC_API_KEY ="sk-"
$env:ANTHROPIC_DEFAULT_SONNET_MODEL = "deepseek-v3.2"
$env:ANTHROPIC_SMALL_FAST_MODEL = "deepseek-v3.2"
$env:ANTHROPIC_DEFAULT_OPUS_MODEL = "deepseek-v3.2"
$env:ANTHROPIC_MODEL = "deepseek-v3.2"
$env:ANTHROPIC_DEFAULT_HAIKU_MODEL = "deepseek-v3.2"
$env:CLAUDE_CODE_SUBAGENT_MODEL = "deepseek-v3.2"
$env:API_TIMEOUT_MS = "3000000"
& $ClaudeReal @args
}
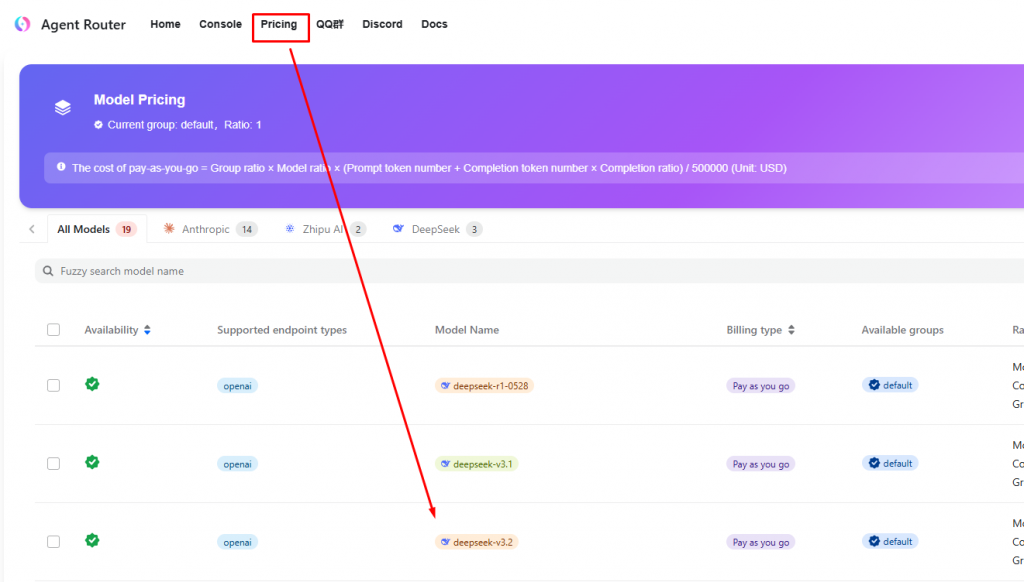
Где не забываем указать правильный путь к claude и токен, который вы создадите в agentrouter.org.
Название модели можно посмотреть в меню pricing
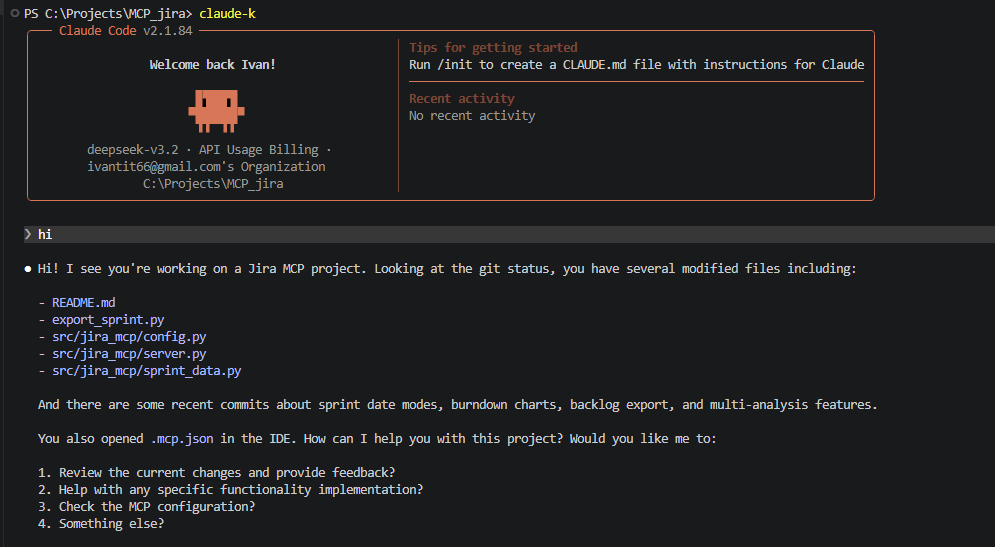
Теперь при вводе команды claude-k у вас будет открываться Claude Code с моделью из этого провайдера.

Ссылка ютуб, на видеоверсию (можно скачать, если тут не открывается).
Предыдущие статьи про вайбкодинг:
Вайб-кодинг в 1С: как рефакторить код бесплатно с помощью VS Code и Roo Code
Вайб-кодинг в 1С: как заставить ИИ БЕСПЛАТНО писать новый код с помощью MCP-серверов
Вайб-кодинг в 1С: Подключаем локальные MCP-сервера к любой нейросети через MCP SuperAssistant
Вайб-кодинг в 1С: Создаём MCP для 1С 7.7 за вечер и пишем обмен с Бухгалтерией 3
Вайбкодинг в 1С: Codex Desktop + GPT-5.4 пишет обработку САМ (Скайнет?)
Вайб-кодинг в 1С: Настраиваем эффективный workflow
Вайб-кодинг в 1С: Обходим лимиты поиска в Z AI и Claude: поднимаем свой поисковый движок через MCP
Спасибо за внимание!
Вступайте в нашу телеграмм-группу Инфостарт