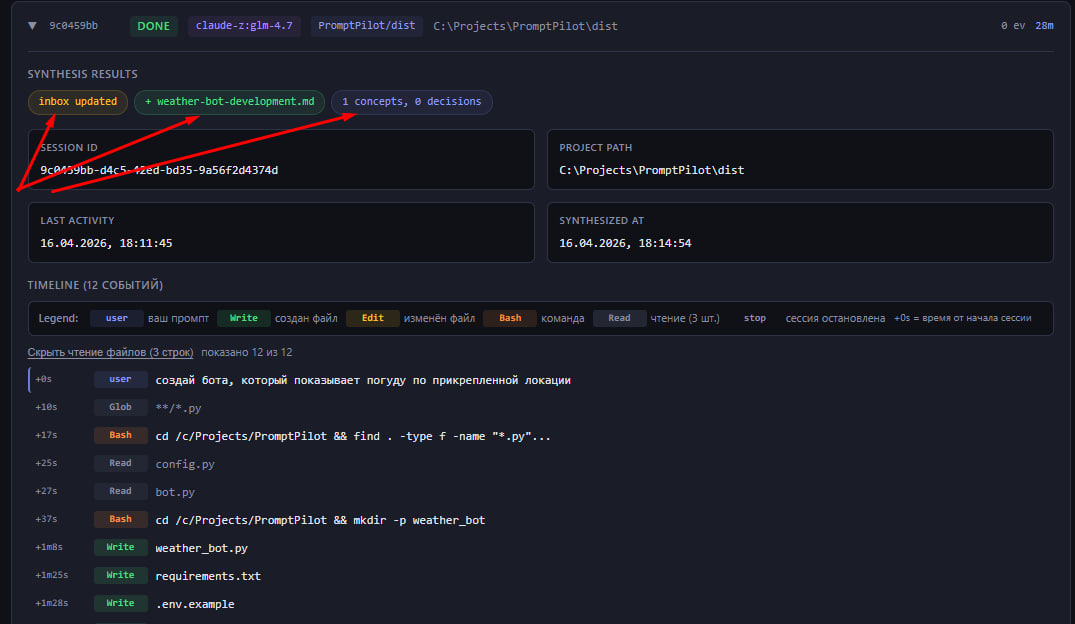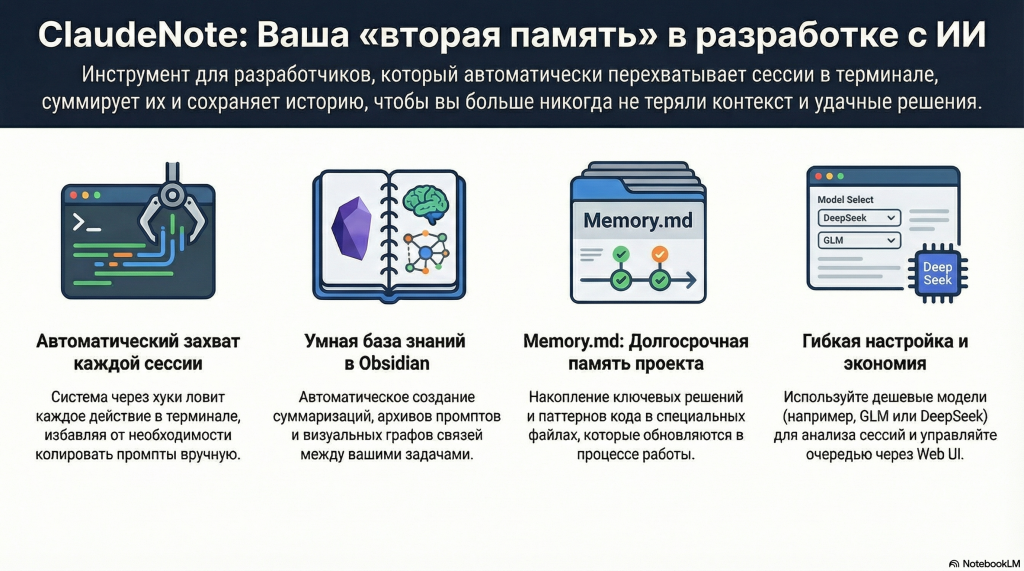
С самого начала моих отношений с ИИ я стремился их улучшать. Для этих целей я записывал промпты, результаты, а иногда и интересные диалоги в текстовые файлы. В итоге получались такие вот скопления файлов, часть из которых потом превращались в статьи, часть я использовал для выбора оптимальных моделей, подходов и т.п.
В процессе нашего совместного обучения (моего и ИИ) я записывал важные решения и подходы в claude.md и memory.md. Следующей ступенью стало автообучение. Я попросил модель самостоятельно записывать важные с её точки зрения моменты себе в память (я рассказывал об этойм лайфхаке тут)
Это существенно улучшило качество кодинга, и сократило количество промптов, но было как-то не системно.
Позвольте теперь представить более удобный инструмент claude note (мопед не мой но я его доработал).
Как это работает: общая схема
Весь процесс выглядит так:
Claude Code Hook → очередь → worker → синтезатор → заметки в vault
Разберём каждый шаг.
Шаг 1. Перехват событий через хуки
| Событие | Когда срабатывает |
|---|---|
| UserPromptSubmit | Пользователь отправил запрос |
| PostToolUse | ИИ выполнил инструмент (чтение файла, bash-команда и т.д.) |
| Stop | Сессия завершена |
Сlaude-note регистрирует себя как обработчик этих событий. При каждом событии Claude Code передаёт JSON-данные через stdin в модуль enqueue.py, который записывает их в ежедневный файл очереди:
{vault}/.claude-note/queue/2026-04-06.jsonl
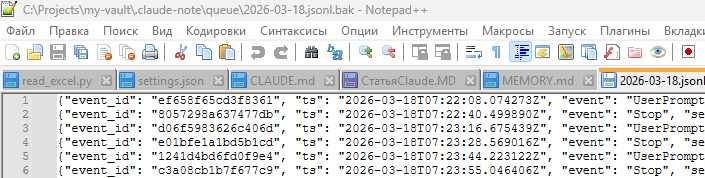
Шаг 2. Фоновый воркер
worker.py запускается как daemon и непрерывно опрашивает очередь. Главная особенность — дебаунс 15 секунд: воркер не обрабатывает сессию сразу, а ждёт паузы после последнего события. Это гарантирует, что сессия обрабатывается только после реального завершения работы, а не в середине.
Для каждой сессии воркер ведёт файл состояния:
{vault}/.claude-note/state/{session_id}.json
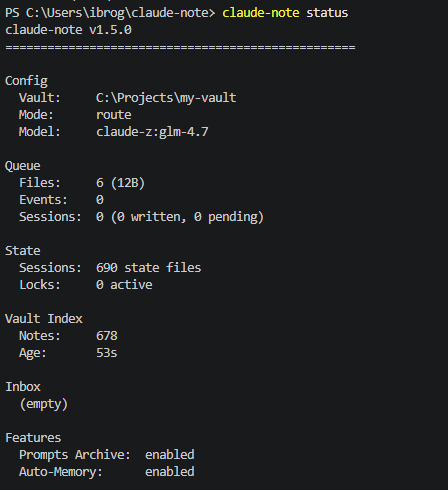
Шаг 3. Чтение транскрипта
Перед синтезом transcript_reader.py читает файл транскрипта сессии Claude Code и извлекает:
- Запросы пользователя — что именно просили сделать
- Использованные инструменты — какие файлы читались, редактировались, какие команды запускались
- Файлы, которых касались — список всех задействованных путей
- Ошибки — если что-то шло не так
Шаг 4. Синтез знаний через Claude
Это ключевой шаг. synthesizer.py формирует промпт и отправляет его в Claude CLI (headless-режим). Промпт содержит:
1. Запросы пользователя из сессии
2. Сводку по инструментам (что читалось, что менялось)
3. Список файлов
4. Контекст текущего vault — какие заметки уже существуют
5. Семантически похожие заметки (через векторный поиск qmd)
В ответ Claude возвращает структурированный JSON — KnowledgePack:
{
"session_id": "abc123",
"date": "2026-04-06",
"title": "Настройка atomic write на Windows",
"highlights": [
"os.replace() на Windows падает если файл существует",
"Решение: delete=True + явный close() перед replace()"
],
"concepts": [...],
"decisions": [...],
"open_questions": [...],
"howtos": [...],
"note_ops": [...]
}
| Поле | Что хранит |
|---|---|
| highlights | 1–3 главных вывода сессии |
| concepts | Концепции и темы с кратким объяснением и тегами |
| decisions | Принятые решения с обоснованием и доказательствами |
| open_questions | Открытые вопросы с контекстом и следующим шагом |
| howtos | Пошаговые инструкции с подводными камнями |
| note_ops | Операции над заметками (создать, дополнить, обновить блок) |

Шаг 5. Маршрутизация в заметки
note_router.py берёт note_ops из KnowledgePack и выполняет операции над vault:
- create — создать новую заметку с frontmatter
- upsert_block — обновить именованный блок в существующей заметке (идемпотентно)
- append — дописать в раздел заметки
Режим работы настраивается:
- log — только логировать, ничего не писать
- inbox — все результаты складываются в папку inbox (безопасный режим)
- route — полная маршрутизация по заметкам vault
После общения с моделью он сам генерирует такие статейки по вашим разработкам да и просто разговорам.
Шаг 6. Auto-Memory: знания возвращаются в следующие сессии
Самое мощное — claude-note автоматически собирает знания в `MEMORY.md` внутри каждого проекта
Claude Code. Этот файл загружается при следующей сессии, поэтому ИИ "помнит":
- Какие решения были приняты и почему
- Подводные камни
- Паттерны кода, которые работают
- Проверенные инструкции
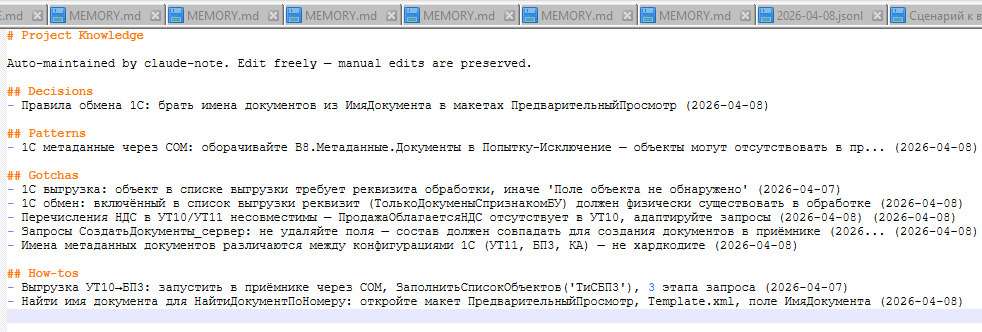
MEMORY.md структурирован по типам знаний:
## Decisions
- Использовать stdin вместо -p флага для Claude CLI на Windows (2026-03-27)
## Patterns
- Всегда резолвить .bat/.cmd через shutil.which на Windows (2026-03-27)
## Gotchas
- archive_path должен быть определён до вызова _is_duplicate_entry (2026-03-27)
- PyInstaller windowed mode: sys.stdout/stderr становятся None (2026-04-07)
## How-tos
- Backfill пропущенных промптов: python -m claude_note backfill-prompts --since 2026-03-25 (2026-03-27)
**Как это работает:**
1. После окончания сессии Claude анализирует транскрипт
2. Извлекает проектно-специфичные знания (decisions, patterns, gotchas, how-tos)
3. Дедуплицирует — не пишет одно и то же дважды
4. Обрезает старые записи когда превышен лимит строк (190 по умолчанию)
5. Сохраняет в `~/.claude/projects/{project}/memory/MEMORY.md`
**Результат:** Вы закрываете сессию, а на следующий день Claude уже знает контекст:
- Почему вы выбрали именно этот подход
- Какие баги вы уже встречали
- Как именно вы решали похожие задачи раньше
Установка и настройка
Требования
- Python 3.11+
- Claude Code CLI
- Obsidian (опционально, но рекомендуется)
Установка
Вариант 1 — установить из GitHub :
# Через uv
uv tool install git+https://github.com/ivanarama/claude-note.git
# Или через pip
pip install git+https://github.com/ivanarama/claude-note.git
Вариант 2 — скачать готовый exe для Windows:
Скачать с: https://github.com/ivanarama/claude-note/releases
Вариант 3 — установить из исходников:
git clone https://github.com/ivanarama/claude-note.git
cd claude-note
pip install -e .
Запуск
Windows (через трей):
.\cn.exe # появится иконка в трее
Linux/macOS/Windows (CLI):
# Запустить worker
claude-note worker --foreground
# Проверить статус
claude-note status
# Web UI
claude-note web
Настройка хуков в Claude Code
В файл настроек Claude Code (settings.json) добавляется:
{
"hooks": {
"UserPromptSubmit": [{"command": "claude-note enqueue"}],
"PostToolUse": [{"command": "claude-note enqueue"}],
"Stop": [{"command": "claude-note enqueue"}]
}
}
Семантический поиск по vault
Если установлен qmd (векторная база данных для Obsidian), claude-note автоматически ищет семантически близкие заметки перед синтезом. Это позволяет Claude понять, в какие уже существующие заметки добавить новые знания, а не создавать дубликаты.
Особенности реализации
Только стандартная библиотека Python — нет runtime-зависимостей кроме самого Claude CLI. Это упрощает установку и избавляет от конфликтов версий.
File-based очередь — никаких баз данных. Всё хранится в простых JSONL-файлах, которые можно читать и редактировать вручную.
Atomic write на Windows — файлы пишутся через временный файл с явным close() перед os.replace(), что гарантирует целостность даже при сбое.
Fallback между моделями — если основная модель недоступна, синтезатор автоматически переключается на резервную с экспоненциальной задержкой.
Практический результат
После настройки каждая нетривиальная сессия работы с Claude Code автоматически превращается в структурированную заметку.
Через несколько дней использования в vault накапливается персональная база знаний:
- Как решались конкретные задачи
- Почему были приняты те или иные решения
- Пошаговые инструкции по нетривиальным операциям
- Открытые вопросы, требующие дальнейшего изучения
Ну и специально для вас, друзья (и для себя), я доработал этот механизм. Вот что я добавил:
1. Веб интерфейс, в котором можно видеть онлайн процесс и статус обработки сессий
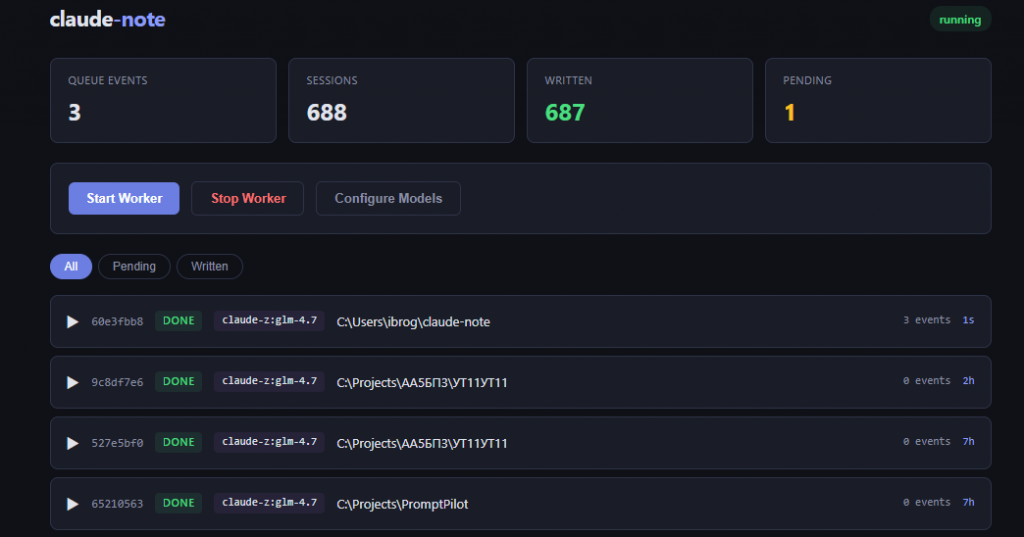
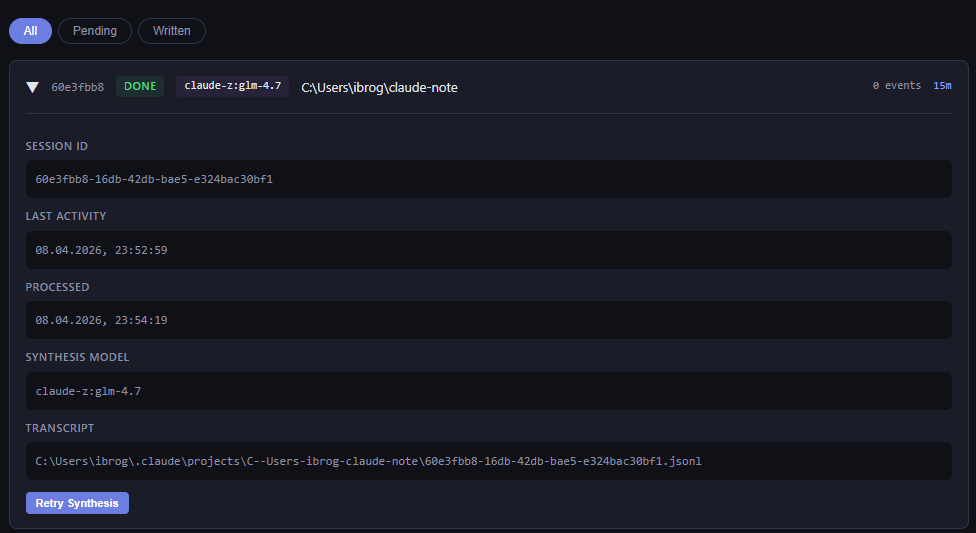
2. Выбор модели для анализа. По умолчанию это была та же модель, которой мы программируем. Но это дорого. Однажды эта штука сожрала все мои лимиты и залезла в экстра юзадж... (не пугайтесь я тогда накосячил с воркером). Теперь же можно выбрать модель из описанных ваших клодсовместимых провайдеров (вот моё видео о настройке этого).
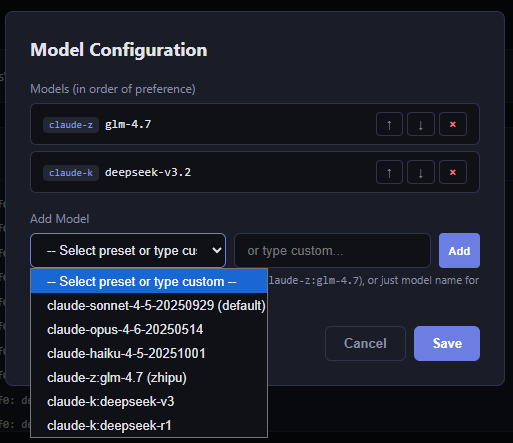
Ссылки
- Репозиторий оригинальный: Оригинальный GitHub
- Репозиторий мой с блэкджеком и web UI: Мой доработанный

Ссылка ютуб на видеоверсию (можно скачать, если тут не открывается).
Предыдущие статьи про вайбкодинг:
Вайб-кодинг в 1С: как рефакторить код бесплатно с помощью VS Code и Roo Code
Вайб-кодинг в 1С: как заставить ИИ БЕСПЛАТНО писать новый код с помощью MCP-серверов
Вайб-кодинг в 1С: Подключаем локальные MCP-сервера к любой нейросети через MCP SuperAssistant
Вайб-кодинг в 1С: Создаём MCP для 1С 7.7 за вечер и пишем обмен с Бухгалтерией 3
Вайб-кодинг в 1С: Codex Desktop + GPT-5.4 пишет обработку САМ (Скайнет?)
Вайб-кодинг в 1С: Настраиваем эффективный workflow
Вайб-кодинг в 1С: Обходим лимиты поиска в Z AI и Claude: поднимаем свой поисковый движок через MCP
Вайб-кодинг в 1С: Бесплатное выполнение рутинных скиллов Claude Code
PromptPilot: менеджер задач для Claude Code, Codex и других CLI
Вступайте в нашу телеграмм-группу Инфостарт