Зачем нужно нагрузочное тестирование перед внедрением
Тема статьи – нагрузочное тестирование, точнее, математическое моделирование для нагрузочного тестирования. Будем предсказывать пики, на проекте будем заранее понимать, какие у нас возможны проблемы с производительностью, как правильно это донести до заказчика и как корректно все рассчитать.
Начнем с того, что нам предстоит сделать на проекте перед внедрением. Мы должны проверить, выдержит ли система нагрузку. Раньше, когда 1С не была настолько нагруженной и проблемной, этим вопросом часто пренебрегали. Сейчас ситуация другая: есть риск, что заказчик просто не примет систему, потому что она неудовлетворительно работает под нагрузкой.
Это проявляется очень просто: постоянные тайм-ауты, операции выполняются слишком долго. Если это розничная сеть, и чек пробивается на четыре секунды дольше на каждого покупателя – при наличии очереди это быстро превращается в проблему. За эти четыре секунды покупатель выскажет кассиру все, что думает, кассир – менеджеру, а менеджер – вам. Чтобы до этого не доходило, на определенном этапе проекта необходимо закладывать работу эксперта и аналитика.
Под экспертом в данном случае я имею в виду эксперта по технологическим вопросам. Понятно, что мы все эксперты в своих областях, но здесь речь о конкретной роли – человеке, который помогает провести нагрузочное тестирование.
Идеальная ситуация – когда у нас есть система, которая переходит в систему с увеличением нагрузки: растет количество пользователей, интенсивность операций. Это практически идеальный сон эксперта: можно взять коэффициенты, рассчитать нагрузку, воспроизвести ее – и получить результат. Но на практике так бывает редко.
Чаще всего вам нужно объединить несколько систем: четыре УПП, пять УТ, несколько Бухгалтерий и еще пару старых решений, написанных, например, на Delphi, – все это перевести в одну 1С:ERP УХ. И в этот момент возникает главный вопрос: а выдержит ли система? Настанет момент, когда зайдет, условно, тысяча пользователей. И нельзя услышать от заказчика: «Знаете, на ста пользователях все работало нормально, а когда зашла тысяча – все упало». Такие ситуации нужно предотвращать заранее. Для этого и требуется нагрузочное тестирование.
Сбор данных для нагрузочного тестирования
Чтобы провести нагрузочное тестирование, сначала нужно собрать данные. В первую очередь – технические: запросы, работа пользователей, обработка серверов. Это так называемый технологический лог. В 1С он называется технологическим журналом – это важно запомнить. Если система не на 1С, данные все равно нужны – это могут быть, например, запросы к СУБД.
Далее – данные о работе пользователей. Нужно понимать, кто и что делает. Желательно получить регламент или попросить аналитиков и консультантов опросить пользователей – не всех подряд, а по группам: кладовщиков, операторов, менеджеров. Нужно зафиксировать, какие операции они выполняют, чтобы сформировать регламент. Важно, чтобы этот регламент в целом совпадал с тем, что мы видим в технологическом логе.
Также нужно получить данные о действиях пользователей. Журнал регистрации есть не только в 1С – он присутствует в любой учетной системе, потому что это базовый элемент безопасности. Он показывает, что именно делает пользователь.
И еще один важный блок – первичные данные. Нужно понимать, какие данные уже есть в базе: статистика, структура, распределение. Это критично, потому что в нагрузочном тестировании мы должны воспроизводить поведение, близкое к реальному.
Например, если в системе есть 10 складов, из них 4 основных, по которым проходит основной поток документов, и в каждом документе в среднем 10–12 строк, – в тестировании нужно воспроизвести это распределение. Нельзя моделировать документы с одной строкой, если в реальности их больше. Такие детали сильно влияют на результат.
Анализ данных и формирование сценария
Когда все данные собраны, мы переходим к анализу. Формируем общую картину того, что мы будем делать с базой. По сути, мы моделируем ее поведение, наполняя базу данными, приближенными к реальным, например, за год.
На основе технологического журнала, регламента пользователей, журнала регистрации и данных самой базы мы формируем сценарий. Определяем, что делает каждый тип пользователя.
Например, оператор склада может за час оформлять около двадцати накладных. Причем это не однотипные документы, а с разным набором номенклатуры. Помимо этого, он может формировать отчеты, выставлять счета, создавать другие документы. Все это нужно учитывать.
Технологический журнал и журнал регистрации помогают понять, какие действия выполняются, а анализ базы – какие именно данные используются: по каким складам, с какими номенклатурами, для каких клиентов. В результате у нас появляется каркас сценария, на основе которого уже можно строить нагрузочное тестирование.
Ошибки при упрощенном подходе к сценариям
Если вы подходите к моделированию поверхностно, это почти гарантированно приведет к проблемам в нагрузочном тестировании. Вы провели тест, у вас все хорошо, кажется, можно запускаться в продуктив. Но давайте представим, что вы ошиблись со сценарием.
Частая ошибка – это слишком «плавное» распределение нагрузки. Мы говорим: «У нас пользователи вводят тысячу накладных в час, значит, распределим их равномерно: каждые 10 минут по 180». Бухгалтер загружает проводки, банк – платежки, и мы тоже равномерно размазываем их по часу. Но вопрос – а в реальности так бывает? С вероятностью 90–99% – нет. В реальных системах нет плавного распределения.
Еще один момент – сценарии работы. Особенно если у вас система работает круглосуточно. Не ограничивайтесь одним сценарием: почти всегда есть минимум два – дневной и ночной. Причем ночные часы могут быть даже более нагруженными. Пользователей меньше, но идут обмены, загрузки с сайтов, интеграции – и нагрузка может быть колоссальной. В итоге проблемы ловят не 1500 пользователей, а, например, 300–400, но это тоже критично. Парализовать работу нельзя ни днем, ни ночью, поэтому сценариев должно быть несколько.
Средние значения почти всегда вводят в заблуждение. Когда вы делите час на маленькие промежутки времени, вы увидите, что нагрузка распределяется неравномерно. Это не ровная линия – это график с подъемами и падениями, иногда очень резкими.
Если вы распределили все по среднему, у вас в тесте будет гладкая картина: никаких тайм-аутов, все стабильно. Но в реальной системе в определенные моменты времени нагрузка резко возрастает. Например, на десятой минуте часа запускается обмен данными. В этот момент оператор, который проводит документы, может начать ловить тайм-ауты. И это уже проблема.
Нельзя моделировать только интерактивные операции и равномерно их распределять. Нужно учитывать и фоновые процессы, и обмены – причем полностью, а не частично. Не просто «обмен создает документы», а весь цикл: загрузка файлов, обработка сообщений, запись данных.
Если этого не сделать, последствия могут быть серьезными. На одном проекте загрузка сообщений в определенный момент занимала до 97% процессорного времени. При этом тайм-аутов не было, все выглядело «нормально», но ресурсов просто не хватало. Пришлось экстренно добавлять сервер 1С, включать его в кластер и стабилизировать систему. Ситуацию решили, но цена – нервы и лишние риски.
Валидация модели и обратная проверка
После того как модель построена, ее нужно проверить. Желательно сделать обратную проверку: прогнать нагрузочный тест так, как будто вы переносите систему заново, и сравнить результаты с исходными логами.
По сути, вы смотрите: если моделировать по среднему, получается одна картина, а в реальности – совсем другая. Если вы не учли неравномерность, конфликты блокировок, особенности фоновых задач, то тест даст искаженный результат.
Часто упускаются важные вещи. Например, операции, которые редко встречаются, но сильно нагружают систему: документ на 5000 строк, который проводится раз в час. Если вы ориентируетесь на средние значения, вы его просто не заметите – а он есть, и он влияет.
Также часто не учитываются загрузки, выгрузки, фоновые задания. Они работают неравномерно, обрабатывают разный объем данных и создают пики нагрузки. Все это нужно закладывать в модель.
Чтобы избежать всех этих проблем, необходимо использовать математический аппарат. Я сознательно убрал сложные формулы, потому что сейчас речь идет не о глубокой технике, а о понимании подхода. Но базовые понятия все равно нужны.
Математический аппарат
Итак, математический аппарат. У нас есть вариация данных, корреляция данных и проверка на парадокс Симпсона.
Вариация данных
Вариация данных – это различие значений какого-либо признака у разных единиц совокупности за один и тот же промежуток времени.
Нас интересуют несколько характеристик: абсолютные отклонения, коэффициент вариации случайной величины и дисперсия.
Если не уходить в сложную математику, логика такая: мы рассматриваем данные как случайные. Понятно, что в базе они не случайны, но для модели мы не можем заранее предсказать, кто, когда и сколько операций выполнит. Поэтому мы работаем с ними как со случайной величиной.
При этом мы должны понимать, какое значение за чем стоит, и вариация позволит оценить ее.
Корреляция
Одной вариации данных недостаточно, поэтому подключаем еще один инструмент – корреляцию. Часто ее определяют как взаимосвязь двух величин, но на практике это взаимосвязь двух и более величин.
Сейчас мы в команде, чтобы автоматизировать этот процесс, разрабатываем векторную базу данных. Нам важно учитывать, как между собой коррелируют разные показатели. Если формально, корреляция – это статистическая взаимосвязь двух или более случайных величин (либо величин, которые можно с некоторой допустимой степенью точности считать таковыми), при этом изменения значений одной или нескольких из этих величин сопутствуют статистическому изменению значений другой или других величин.
Корреляционный анализ – это метод обработки статистических данных, с помощью которого измеряется теснота связи между двумя или более переменными. Корреляционный анализ тесно связан с регрессионным анализом (также часто встречается термин «корреляционно-регрессионный анализ», который является более общим статистическим понятием), с его помощью определяют необходимость включения тех или иных факторов в уравнение множественной регрессии, а также оценивают полученное уравнение регрессии на соответствие выявленным связям (используя коэффициент детерминации).
Теперь на практике. У нас есть несколько групп показателей – условно, векторы.
Первый – вектор производительности железа: процессор, память, дисковая подсистема.
Второй – вектор базы данных: количество транзакций, отказов, чтений, записей, объем данных, тайм-ауты.
Третий – вектор бизнеса: количество проведенных РТУ, их «вес» и так далее.
И все это в конкретный момент времени соотносится с одним показателем – например, с APDEX, метрикой производительности.
Что нам дает корреляция? Очень простую вещь – понимание взаимосвязи между этими векторами и APDEX. Корреляционный анализ позволяет определить, какой именно фактор влияет на изменение производительности.
Мы можем увидеть, из-за чего падает или растет APDEX: из-за перегрузки железа, тайм-аутов, увеличения количества транзакций, роста объема чтений – или из-за конкретного сочетания этих параметров.
Кроме того, с его помощью можно анализировать и бизнес-данные. Например, взаимосвязи внутри вектора «склад – номенклатура – организация»: как распределяются документы, как они соотносятся друг с другом. Это позволяет корректно воспроизвести структуру данных в нагрузочном тестировании и сделать модель максимально приближенной к реальности.
Номенклатура во времени
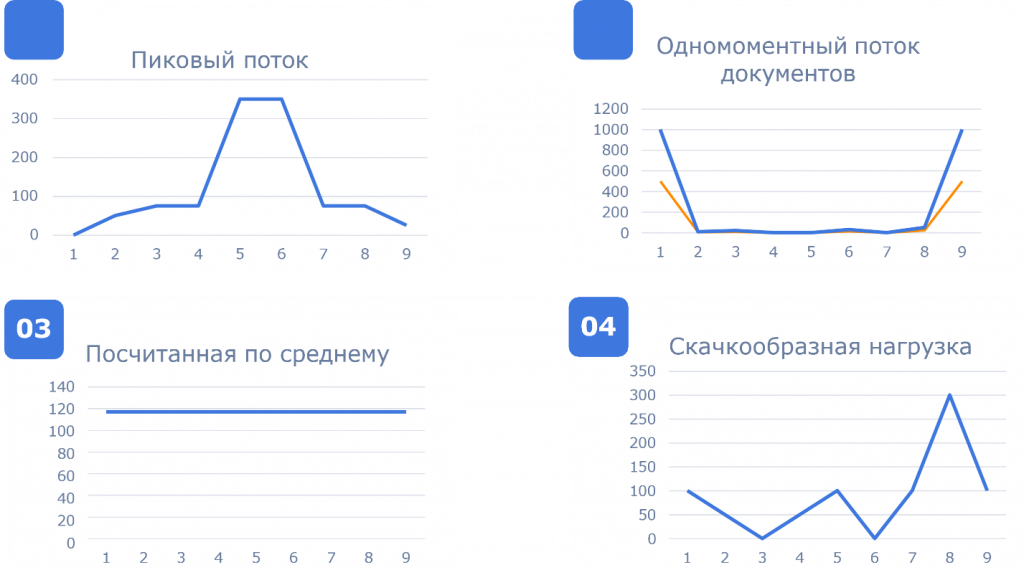
Если применить эти методы, вы увидите, как в реальности распределяется поток данных. И он почти никогда не выглядит как ровная линия со средним значением, например, 0,3.
На практике поток либо имеет выраженные пики, либо просадки, либо и то и другое. Теоретически можно представить «идеальную» форму, но в реальных системах данные ведут себя иначе. Чаще всего это график с резкими подъемами – когда нагрузка концентрируется в определенные моменты.
Именно такие пики вы и должны воспроизводить. Корреляционный анализ позволяет увидеть, где возникают эти всплески, какие данные их формируют и как они распределяются во времени. А значит – правильно заложить нагрузку в сценарий.
Интерпретация результатов распределения во времени
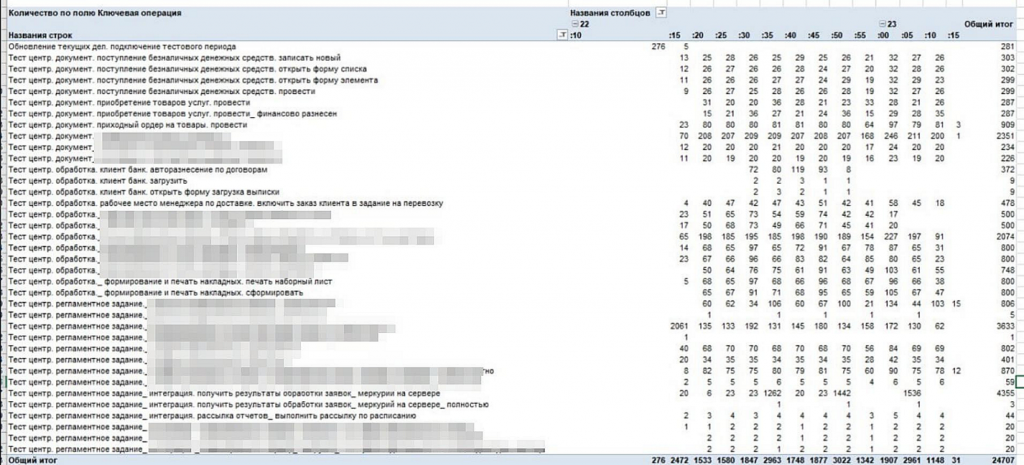
Здесь важно показать, что происходит, когда нагрузочное тестирование проводится не по средним значениям. Возьмем, например, загрузку клиент-банка по договорам. На графике видно, что активность сосредоточена в конкретном интервале – примерно с тридцатой по пятидесятую минуту.
И это полностью соответствует реальности. Бухгалтер не загружает файлы каждые пять минут равномерно. Он садится и в течение определенного промежутка времени последовательно выполняет загрузку. В этот момент и возникает выраженный пик нагрузки.
Также видно, что нагрузка может возникать в начале часа – из-за регламентных заданий, которые прогружают данные. И дальше в течение часа она уже не распределяется равномерно. Более-менее плавно выглядят только интерактивные операции, а все, что связано с загрузками, обменами и регламентными процессами, дает неравномерную нагрузку на этапе всего теста.
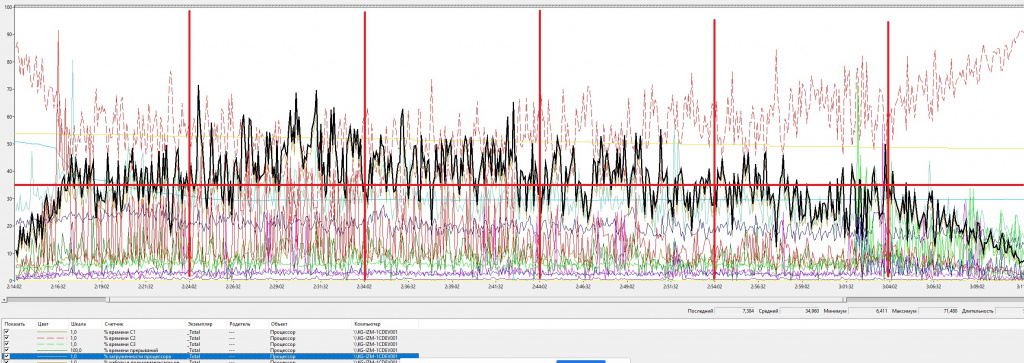
Если посмотреть на загрузку железа, мы увидим характерные пики – в определенных промежутках времени нагрузка резко возрастает, а затем снижается. Это совершенно не похоже на «усредненную» картину.
Если бы мы ориентировались только на средние значения, мы бы не увидели этих пиков. И, скорее всего, сделали бы неверный вывод о требуемых ресурсах – решили бы, что мощности можно снизить. На практике в пике загрузка может доходить до 80%, и это критично учитывать при подборе инфраструктуры.
Такое моделирование дает два ключевых результата.
Первое – позволяет выявить и устранить блокировки еще до запуска. В реальном проекте это была серьезная проблема, и ее удалось решить заранее.
Второе – помогает корректно подобрать железо под реальные пики нагрузки, а не под усредненную картину.
При этом важно понимать: даже после ввода системы в эксплуатацию возможны проблемы с производительностью. Но нагрузочное тестирование позволяет сократить их в разы. А если тестирование проведено корректно, с учетом всех факторов – сократить еще сильнее.
Дополнительные технические рекомендации для экспериментов
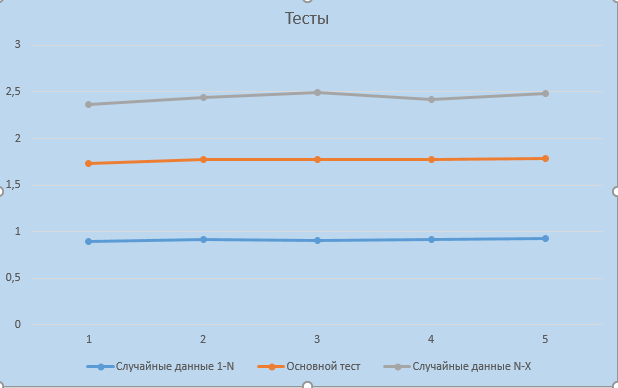
Дальше есть несколько изображений, которые имеет смысл передать технарям. Здесь нужно немного поэкспериментировать. Понимаю, что напрямую обосновать это клиенту будет сложно, но мы как раз готовим инструмент, который позволит это делать уже после нагрузочного тестирования.
Важно, что само нагрузочное тестирование должно быть воспроизводимым. Вы его провели, перезагрузили базу, запустили еще раз – и результат должен получиться тем же самым.
Но если говорить про исследование, про более глубокое изучение, полезно иногда менять сами данные. Не гонять один и тот же набор, а посмотреть, как именно набор данных влияет на нагрузочное тестирование.
Если при изменении данных у вас показатель APDEX в течение часа сильно не меняется – значит, все сделано правильно, система стабильна. А вот если при разных наборах данных, как на изображении, вы видите, что значения расходятся, дельта становится большой, – это повод разбираться.
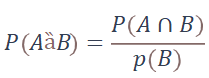
В этом случае можно условно построить зависимость: A – это набор данных для теста, B – это APDEX. И посмотреть, как меняется B при изменении A.
Если кривая начинает сильно «разъезжаться», расхождения становятся заметными, значит, данные напрямую влияют на производительность. И тогда уже нужно исследовать, какие именно данные дают такой эффект и почему. Когда эта зависимость будет выявлена, вам будет легче предвидеть внеочередные проблемы.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Анализ & Управление в ИТ-проектах.


Вступайте в нашу телеграмм-группу Инфостарт