Одна задача вторую неделю ждет приемки, по другой нет ответа по требованиям, третью уже два раза переносили из релиза. Такие ситуации могут возникать регулярно и о них можно даже и не знать.
Если руководитель узнает о проблеме только тогда, когда срок уже поехал или релиз пришлось резать - это не есть хорошо.
В проектной команде задача редко идет по прямой. На каждом участке она может зависнуть. Если это не видно в системе, проблема превращается в ощущение: «что-то долго», «кажется, перегруз», «почему опять не успели». Но ответов, почему именно так происходит обычно нет.
Получить ответы на многие вопросы можно с помощью различных метрик. Их я воспринимаю не как способ оценить людей, а как способ увидеть поток работы. Хорошая метрика не ищет виноватого. Она показывает место, где задача застряла, качество просело или команда распылилась.

Если проблему не видно, с ней трудно работать
Фраза «что не измеряется, то не управляется» звучит жестко. В работе команды не все можно честно разложить по цифрам: есть сложность задачи, контекст, усталость, внезапные изменения со стороны бизнеса.
Но если важная проблема вообще никак не видна, с ней почти невозможно работать.
Пока нет данных, разговор остается на уровне ощущений. Кажется, что задачи долго ждут приемки. Кажется, что приоритеты постоянно меняются. Кажется, что один разработчик перегружен, а у другого есть запас. Но ощущения плохо обсуждаются: один человек видит так, другой иначе.
Когда появляется простой показатель, разговор становится предметнее. Не «у нас все долго», а «пять задач старше двух недель стоят на уточнении требований». Не «команда перегружена», а «на одном человеке сейчас две высокоприоритетные задачи и критичная правка к релизу».
Измерение само по себе ничего не исправляет. Но оно вытаскивает проблему из ощущения в рабочую плоскость. Дальше уже можно решать: менять приоритет, подключать аналитика, переносить задачу из релиза и т.д.
Что держать перед глазами
В проектной команде полезно видеть очередь и бэклог, приоритеты, загрузку участников, сроки реализации, задачи с риском задержки, состав релизов и баги после выпуска. Лучше, когда это живет там же, где живет работа: в Jira, системе учета задач, service desk, дашборде или простом отчете, доступном команде. Смысл такого табло не в давлении цифрами, а в общей картине для команды.
Закрытые задачи еще не означают результат
Самая простая цифра — количество закрытых задач. Ее легко посчитать и показать в отчете. Но сама по себе она почти ничего не объясняет.
Можно закрыть много мелких обращений и не продвинуть важную доработку. Можно быстро закрывать простые задачи, а сложные неделями держать на уточнении. Можно формально закрыть обращение, которое через два дня вернется с тем же вопросом.
Количество задач считать можно. Просто это не главный показатель результата. Лучше смотреть, что стоит за этой цифрой: какие задачи дошли до релиза, какие вернулись с багами, какие висели на требованиях, какие застряли на приемке.
Плохая метрика меняет поведение не туда
У любой метрики есть побочный эффект: люди начинают учитывать ее в работе. Если показатель выбран неудачно, команда быстро учится работать не на результат, а на цифру.
Если давить количеством закрытых задач, выгоднее брать мелкие работы. Если давить скоростью, появляется соблазн закрывать раньше, чем задача дошла до результата. Если смотреть только техподдержку, обращение можно закрыть формально, но пользователь потом придет снова.
Сравнивать людей между собой по количеству задач или средней скорости закрытия опасно. Один разработчик может делать сложную интеграцию, другой — несколько небольших исправлений. В отчете второй выглядит быстрее, но это ничего не говорит о реальной пользе. Разрез по сотрудникам нужен не для рейтинга, а для карты рисков.
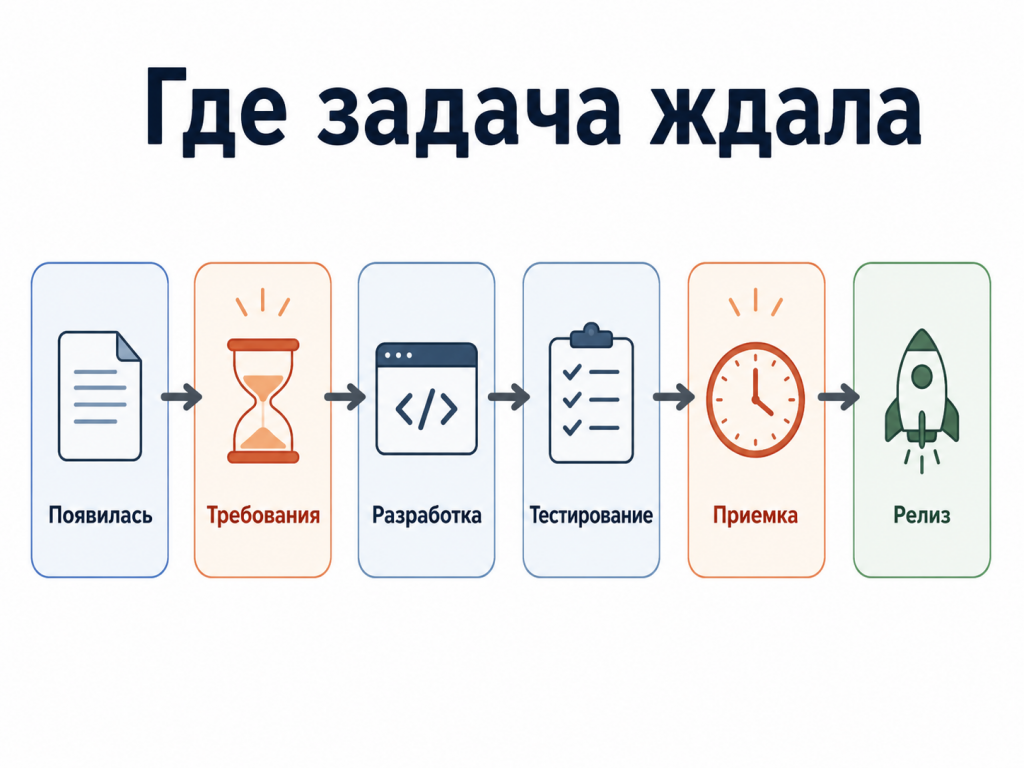
Где задача ждала
Время выполнение показывает, сколько прошло от появления задачи до результата. В проектной работе это может быть путь от регистрации задачи до приемки или релиза. Главное — заранее договориться, какие точки считаем началом и концом.
Эта метрика полезна не общей цифрой, а возможностью увидеть ожидания. Задача могла быть небольшой в разработке, но неделю ждать ответа по требованиям. Или быстро пройти разработку, но зависнуть на приемке. Или быть готовой технически, но не попасть в релиз из-за очередности.
Я бы смотрел не только общий срок, но и статусы, в которых задача провела больше всего времени. Тогда разговор становится конкретным: не «разработка долго делает», а «задачи этого типа чаще всего стоят на уточнении требований». И самое неприятное — формально задача уже почти готова, но результата для пользователя еще нет.
Приоритеты, загрузка и сроки
Без явных приоритетов очередь быстро превращается в борьбу голосов. Кто громче попросил, тот и срочный. Кто ближе к руководителю, тот и попал в работу. В итоге план есть, но живет он недолго.
Фиксация приоритета по каждой задаче сильно помогает. Только приоритет должен объясняться не эмоцией, а последствиями для бизнеса.
Если высокий приоритет становится обычным режимом, это сигнал, что вход задач работает плохо: приоритеты назначаются слишком легко или плановая работа регулярно проигрывает громким обращениям.
Загрузку по людям тоже нужно смотреть аккуратно. Пять задач у одного разработчика и пять задач у другого могут означать разную нагрузку. У одного — небольшие исправления. У другого — интеграция, доработка к ближайшему релизу, баг после выпуска и задача с неполными требованиями. Поэтому важен не только счетчик задач, но и их вес.
Если по задаче есть оценка, исполнитель и плановый срок завершения разработки, этим можно управлять. Не для ежедневного контроля в стиле «ну что там?», а для раннего сигнала. Если на второй день задачи на три дня видно, что требований не хватает или найден технический риск, еще можно уточнить объем, изменить срок или убрать задачу из релиза. В последний день выбор обычно хуже.
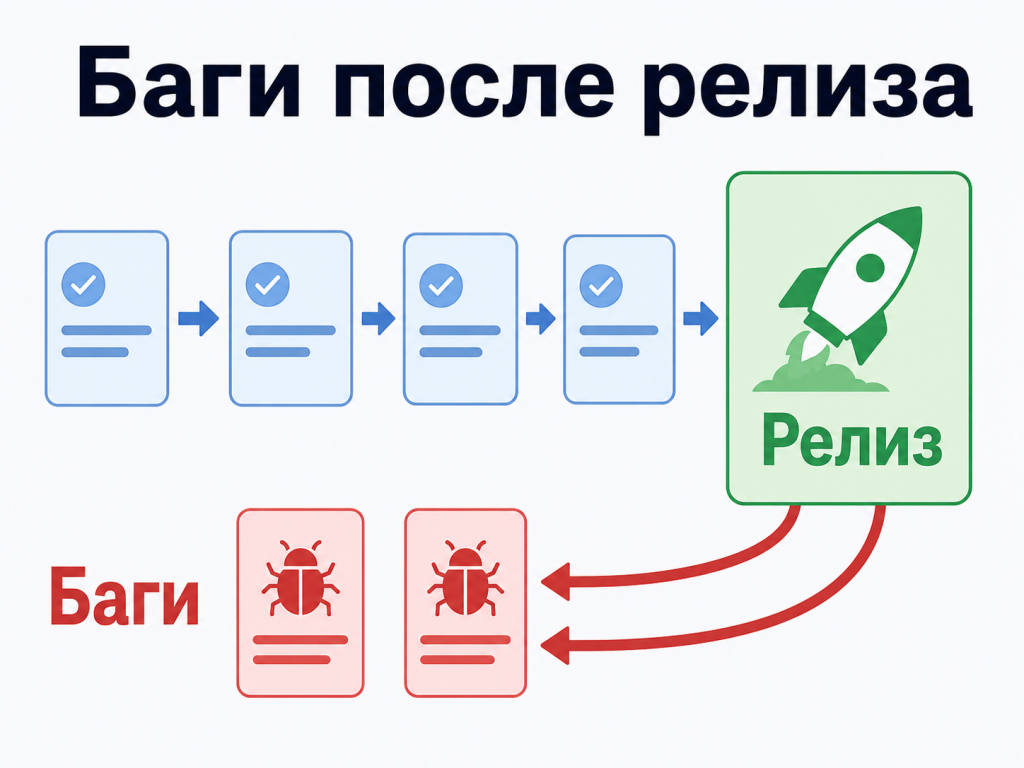
Релизы и баги после выпуска
Количество релизов само по себе тоже не показатель. Один релиз может быть небольшим исправлением. Другой — пакетом изменений, после которого команда неделю разбирает последствия.
В проектной работе полезнее смотреть состав релиза: какие задачи вошли, какой у них приоритет, что перенесли, кто участвовал в разработке и проверке, какие баги появились после выпуска.
Баги после релиза стоит смотреть не только по количеству, но и по характеру.
Если после релизов постоянно возвращаются похожие дефекты, общий счетчик багов мало помогает. Нужен разбор причины: требования, приемка, тестовые сценарии, состав релиза или качество проверки.
Количество и возраст задач
На доске может быть много активных карточек, все заняты, каждый день идут обсуждения, но завершенных результатов мало. Так бывает, когда слишком много задач открыто одновременно: разработчик переключается между доработками, аналитик держит несколько блоков требований, тестирование получает пачку задач перед релизом.
Возраст незавершенных задач помогает увидеть карточки, которые стали фоном. Такие задачи полезно поднимать отдельно: закрываем как неактуальную, уточняем требования, меняем приоритет, дробим объем, переносим в другой релиз или наконец доводим до результата.
Когда метрика превращается в часы и деньги
Польза метрик лучше всего видна там, где результат можно перевести хотя бы в часы. У меня был проект, где мы начали отдельно смотреть обращения: сколько их приходит, по каким причинам, какие повторяются, где пользователю не хватает информации, а где проблема действительно в системе.
До этого обращения воспринимались как обычный поток поддержки. Пришло — разобрали. Пришло снова — снова разобрали. Поддержка работала, но вот с причинами обращений работа не велась.
Когда начали смотреть причины и повторяемость, стало видно, что часть обращений можно не просто обрабатывать, а убирать из потока. Часто это не ошибки системы, а повторяющиеся вопросы одного типа.
Где-то нужна инструкция. Где-то — поправить процесс. Где-то — небольшая доработка, после которой пользователь перестает спотыкаться об один и тот же сценарий.
В итоге количество обращений удалось снизить примерно на 50%, что позволило очень разгрузить команду. Каждое обращение — это время специалиста поддержки, аналитика или разработчика, которое можно использовать более эффективно.
Грубый расчет простой: количество снятых обращений × среднее время обработки × стоимость часа специалиста.
Допустим, в месяц было около 400 обращений, стало около 200. Если на одно обращение уходило хотя бы 15–20 минут, это уже десятки часов в месяц. При внутренней стоимости часа специалиста даже в 1500 рублей получается заметная сумма. Не точная бухгалтерская экономия, но порядок понятен.
Снижение обращений — это не только «стало спокойнее». Это часы, которые команда может вернуть в доработки, релизы, разбор причин дефектов и нормальную работу с бэклогом.
В материале Agile Alliance описан кейс Siemens Health Services: команда стала смотреть не только на объем выполненной работы, а на сам поток задач — сколько задач одновременно находится в работе, сколько времени они идут до результата и где возникают задержки. После ограничения количества задач в работе 85% задач стали завершаться быстрее: показатель снизился с 71 до 43 дней, а в следующем релизе держался примерно на уровне 40–41 дня. Первый релиз с таким подходом завершили по графику и ниже бюджета более чем на 10%, во втором релизе команда выполнила на 33% больше задач, а доля задач, прошедших проверку с первого раза, выросла с 75% до 86%, затем до 95%. Когда команда видит, где копится незавершенная работа и где задачи ждут, она может ускорять поток, снижать количество переделок и точнее прогнозировать сроки и стоимость релизов.
С чего начать
Я бы не начинал со сложного дашборда. Сначала достаточно нескольких показателей, которые уже можно вытащить из Jira или системы учета задач:
- сколько задач в очереди и бэклоге;
- какие задачи имеют высокий приоритет и почему;
- какие задачи давно не двигаются;
- у кого сейчас перегруз по важным задачам;
- что входит в ближайший релиз;
- какие баги или обращения повторяются.
Этого достаточно для полезного еженедельного обзора. Короткий разбор: что зависло, где нужен ответ, что может сорвать релиз, где приоритет назначен непонятно, какие обращения повторяются чаще всего.
После такого обзора должны совершаться действия по решению возникших проблем.
Когда метрики становятся бесполезным
Метрики теряют смысл, когда их собирают только ради отчета. Цифры есть, графики есть, но после обсуждения ничего не меняется. Через месяц отчет повторяется, проблемы те же, команда уже не воспринимает такие встречи всерьез.
Еще хуже, когда по цифрам начинают наказывать без разбора причин. Тогда люди защищаются: карточки закрываются формально, сложные задачи дробятся, плохие новости прячутся до последнего. Вряд ли это приводит к повышению эффективности.
Чтобы этого не случилось, обсуждать надо не людей, а процесс. Если задачи зависают на приемке — меняем правила приемки. Если приоритеты постоянно пересматриваются — уточняем правила входа. Если релизы возвращаются багами — меняем проверку или качество описания требований. Если обращения повторяются — разбираем причину, а не просто отвечаем снова.
Что хотелось бы дополнительно отметить
Я не утверждаю, что команду можно оценить только цифрами. Я не предлагаю сравнивать разработчиков по количеству закрытых задач. Я не считаю, что срок по задаче или дашборд сами по себе делают работу лучше.
Я также не предлагаю считать экономию там, где ее невозможно честно посчитать. Иногда достаточно часов, иногда — процента снижения обращений, иногда — факта, что релиз стал предсказуемее. Главное, чтобы метрика помогала принять решение, а не украшала отчет.
Финальный вывод
Метрики помогают только тогда, когда по ним можно задать рабочий вопрос и изменить процесс. Если показатель не ведет к решению, он быстро становится отчетным шумом.
Для проектной команды важны не красивые цифры, а сигналы и своевременное реагирование на них.
Если по метрике удалось снизить поток обращений, убрать повторяющиеся проблемы или точнее планировать релизы, эффект можно показать уже не только словами. Его можно посчитать в часах команды, а иногда и в деньгах.