1С умеет предсказывать будущее
Всем привет! Меня зовут Айдар Сафин. Я главный разработчик 1С в MAGNIT TECH.
Я открою вам страшную тайну: 1С умеет предсказывать будущее. И для этого не надо ехать в Тибет и учиться у монахов, достаточно установить пару программ и настроить мозги.
Эта статья о том, как перестать тушить пожары и начать их предсказывать. Сначала будет теория, чтобы передать основную идею, то есть теоретический блок. Далее я дам практический стек. Я создал новый публичный репозиторий в GitHub, и все, о чем я рассказываю, подкреплено скриптами.
Это пока концепт, эксперимент, первые шаги.
Но там уже есть полезные и рабочие мысли, которыми я хочу поделиться.
Я подробно покажу и объясню, что и где смотреть.
Лучше быть капитаном, видящим риск на горизонте, чем юнгой, затыкающим пробоины.
Часть 1: Классическая картина vs Новая реальность

Давайте обозначим проблему. Как у нас обычно происходит в классическом, или реактивном, сценарии?
Например, 9:00. Вася с бухгалтерией начинает возмущаться: «Все виснет, деньги не платят, вы что там сломали?»
Через полчаса ругани и ковыряния админ говорит: «Спокойно, мы все нашли. Это дедлок в регистре сведений или накопления. Сейчас все перезагрузим».
Еще проходит 15 минут, все начинает работать, но от бизнеса мы получаем потерянные деньги, нервы и минус 1005000 к карме IT отдела. Такой подход – это потеря денег.
Узнаете? Мы привыкли работать в режиме пожарных. Прилетело – потушили.
Но цена такого подхода – это не только нервы, это прямые потери бизнеса.
Чем быстрее мы реагируем, тем мы круче? Или все-таки есть другой путь?
Реактивный подход это потеря денег. Главная проблема: мы всегда реагируем постфактум.
Какое решение? Решение – превентивный подход. Это новая парадигма, когда мы предсказываем проблемы и работаем превентивно.

Например, сценарий новой реальности. За три дня до инцидента робот HAL9000 говорит: «Айдар, рост блокировок регистра взаиморасчетов прогнозируется на 200%. Прогнозируется коллапс через 72 часа. Предлагаю оптимизировать индекс».
Понятно, это шутка. На самом деле у нас выполняется скрипт на Python, срабатывает алерт, и мы получаем такое сообщение.
Далее, за два дня до инцидента админ, попивая кофе, в плановом порядке спокойно говорит: «Окей, давайте перестроим индекс».
А в день инцидента, который теперь не происходит, тот же пользователь Вася говорит: «Айдар, слушай, а что у нас так все шустро работает? Ты что улучшил?»
От бизнеса мы получаем спокойствие, доверие, любовь к IT. Хотите жить так же? Я дам вам рецепт, как можно к этому прийти.
Часть 2: Что мы мониторим? От симптомов к причинам
Где искать следы? Два источника истины. Технологический журнал 1С: Ключевые метрики

У нас есть два глаза. Первый глаз – технологический журнал 1С. Второй – метрики СУБД. ТЖ показывает, что конкретно в 1С тормозит и чего оно ждет: может быть, оно ждет, пока база данных читает с диска.
Метрик на самом деле много, но это основные, которые дают 80% результата, – это Duration, длительность операций; WaitTime, время ожиданий; LockTime, время блокировок; и Контекст, пользователи и сеансы.
Где искать следы? Два источника истины. Ключевые метрики СУБД

В СУБД мы смотрим в первую очередь рост размера таблиц и индексов, эффективность кэша, или Cache Hit Ratio, статистику ожиданий БД и количество активных сессий.
Они объясняют почему базе данных так плохо. Только соединив эти два взгляда, мы получаем 4D-очки, в которых видно будущее.
Что ищем? Аномальные всплески, тренды, тех, кто стал тормозом.
Практика: Какие тренды убивают систему первыми

Есть три тренда, которые гарантированно уничтожат производительность, если их игнорировать. Посмотрите на них. Если вы увидели такое у себя – проблема приближается. Но главное – знать, что делать.
Первый тренд – заполнение диска. Мы замеряем размер каждый день и говорим: «Диск закончится через N дней». Что делать? Заказать новый диск, расширить том или почистить архив. У вас есть N дней на спокойное планирование.
Второй тренд – рост блокировок. Если время ожидания растет быстрее числа пользователей – это верный признак приближающегося дедлока. Что делать? Искать проблемные запросы, перестраивать индексы, разбирать длинные транзакции. У вас есть M дней до коллапса.
Третий тренд – деградация индексов. Когда база данных вместо быстрого Index Scan начинает читать всю таблицу целиком – производительность тяжелых отчетов неумолимо падает. Что делать? Перестроить индексы, обновить статистику, оптимизировать структуру таблиц.
Наша задача – не ждать, когда красная линия пересечет критический порог, а вмешаться заранее. И знать, какой инструмент взять в руки.
Часть 3: Применяем ML без data science-отдела


Некоторых слово ML пугает. Кажется, что нам нужны бородатые профессора и тонны золота. Нет, нам нужна простая школьная математика и библиотеки, которые уже все умеют.
Не бойтесь аббревиатуры ML. Это не искусственный интеллект, который хочет вас убить, это просто алгоритм, просто инструмент.
Для начала я взял два простых инструмента. Далее еще поясню, какие бывают алгоритмы.
Самый простой – регрессия. У вас есть точки на графике, история роста. Вы проводите через них линию и смотрите, когда она упрется в потолок.
Если объяснять по-простому: представьте, что вы кидаете камень. Зная его скорость и направление, вы можете сказать, куда он упадет. Здесь то же самое.
Второй инструмент – классификация. Это уже интереснее. Это как игра из детства «Найди десять отличий». Мы берем алгоритм, скармливаем ему много ситуаций, когда у нас была проблема.
Это как учить ребенка отличать котиков от собачек. Мы показываем ему много фотографий котиков и собачек, потом ребенок берет картинку и говорит: «Это 85% котик». То же самое, когда мы скармливаем данные алгоритму: он говорит, например, «это 85% дедлок».
Не нужен сложный ИИ. Достаточно классики, которая есть в любой BI-системе (Power BI, Grafana ML) или библиотеке (Python scikit-learn).
Выявление аномалий: когда тишина не норма

Мир 1С цикличен. Утром все приходят, в обед обедают, вечером закрывают день. Если ритм сбился – это аномалия.
Очень важный момент – аномалии бывают не только когда все плохо, но и когда «слишком хорошо».
В этой статье и в репозитории аномалии мы смотрим на сессиях 1С.
Например, если у нас в 11:00 обычно 500 сессий, плюс-минус 20, а в какой-то момент вместо 500 стало 200 сессий, это аномалия. Это не повод для радости. Это не значит, что база стала меньше потреблять или меньше нагружаться. Это значит, что что-то отвалилось. Например, планировщик фоновых заданий. Через какое-то время пойдет лавина или шквал звонков, или еще какие-то вещи. Поэтому на это тоже нужно реагировать. И это тоже можно предсказывать с помощью Python.
Если график активных пользователей резко упал, это не значит, что все ушли в отпуск.
Это значит, что, скорее всего, отвалился вход в систему. И через час раздастся шквал звонков. Мы должны предупредить это.
По-простому: представьте, что у вас есть сосед, который каждый день в 22:00 начинает сверлить. И в какой-то момент у вас тишина. Вы не радуетесь, вы в панике. Наверное, он или сильно заболел, или, наоборот, задумал что-то глобальное.
Типы машинного обучения: краткий обзор с примерами
Часть 4: Встраиваем прогнозы в процесс: от алерта до тикета
Просто сделать прогноз – это половина дела. Нам нужно, чтобы при этом что-то происходило. В этом примере я покажу практическую часть: когда у нас сработает алерт, должно что-то происходить – например, возникать тикет.
Обычный алерт приходит, когда диск уже заполнен на 95% – в 3 часа ночи, срочно вставай и чисти.
Превентивный алерт приходит за неделю: «Диск заполнится через 7 дней, скорость роста 5 ГБ/день, запланируй расширение».
Разница между паникой и плановой работой.
Proactive-алерты: как не будить админа ночью


Посмотрите на разницу в формулировках. Старый реактивный алерт приходит в 3 часа ночи и требует немедленных действий. Новый превентивный алерт приходит в рабочее время, дает неделю на спокойное планирование и не требует вставать с кровати. Все дело в том, что мы мониторим не текущее состояние, а скорость приближения к катастрофе.
Прогнозировать можно с помощью Prometheus и Grafana. В Grafana есть встроенный Grafana ML. Либо можно использовать Python-скрипты. Такой пример я тоже дам.

Прогноз – это половина дела. Вторая половина – сделать так, чтобы он не потерялся.
У нас это работает как часы: модель видит угрозу, дергает за ниточку, и в Jira появляется задача.
Разработчик не гадает, что бы такого сделать, он уже знает, что через 5 дней будет проблема.
Это не магия, это API и немного скриптов.
Чтобы прогноз не оставался просто прогнозом или гаданием на кофейной гуще, нам нужно, чтобы при срабатывании автоматически создавался тикет в одной из ваших систем. Классическая ITSM-система – Jira.
Например, модель, то есть скрипт, обрабатывает данные и видит проблему с отчетом. Уверенность – 92%. Дальше скрипт стучится в Telegram, отправляет уведомление и при этом создает тикет в Jira.
Текст может быть таким: «Отчет «Оборотка» перестанет работать через 5 дней». Описание говорит, что сейчас отчет формируется 45 секунд, но я прогнозирую, что через три дня он начнет формироваться 180 секунд. Кому назначаем? Группе 1С-разработки. Приоритет высокий.
Разработчик приходит на следующий день, берет задачу из бэклога и спокойно ее делает без аврала. Это все реально сделать.
Часть 5: Практический стек
Это была теория, переходим к практике.
Я выложил в GitHub https://github.com/magnit-tech/1CML новый публичный репозиторий, который называется 1CML.
Этот репозиторий пока концепт, эксперимент, первые шаги. Можно сказать, что это мой pet-проект. Но на тестовом контуре, на своих рабочих тестовых машинах, я это все обкатывал. Это еще пока не продуктив, но здесь уже есть много рабочих скриптов, готовые конфиги, дашборды, подробная документация. Вы можете этим спокойно пользоваться.
Я выложил все в открытый доступ, чтобы вы могли покрутить, потестировать и забрать себе полезные куски.
Что внутри репозитория?

magnit-tech/1CML
Давайте быстро пройдем по структуре репозитория. В папке prometheus лежат готовые конфиги для сбора метрик с Windows и PostgreSQL, а также правила алертов. В grafana – три дашборда в формате JSON: прогноз диска, тренды блокировок и контрольные карты аномалий. Импортируются в два клика.
В репозитории четыре основные папки.
рrometheus – готовые конфиги для сбора метрик.
grafana – три дашборда, которые импортируются за минуту.
scripts – все Python-скрипты: прогноз диска, парсер техжурнала, детектор аномалий.
И отдельная папка itsm с интеграциями под Jira, YouTrack, ServiceNow, Redmine и GitLab.
Все остальное – схемы для ClickHouse и PostgreSQL, документация и пример .env файла. Клонируйте и пользуйтесь.
Самое интересное в папке scripts. Здесь у нас отдельные модули: disk для прогноза диска, locks для анализа дедлоков, anomalies для детектора аномалий. В папке ideas – заготовки на будущее: прогноз длительности закрытия месяца, анализ медленных запросов, прогноз пиковых нагрузок и еще 7 идей. И отдельная папка itsm с интеграциями под Jira, YouTrack, ServiceNow, Redmine и GitLab.
В clickhouse и postgresql – SQL-скрипты для создания таблиц. В docs – подробная документация по каждому модулю, включая future_1C_ML.md с планами развития. Есть тесты в папке tests, а models и logs создаются автоматически при работе – они в .gitignore.
И, конечно, .env.example – шаблон для настройки, requirements.txt со всеми зависимостями и главный README.md. Все структурировано, все готово к использованию.
Но повторюсь – это пока пилот, в проде мы это еще не используем. Но потенциал, надеюсь, очевиден.
Архитектура решения
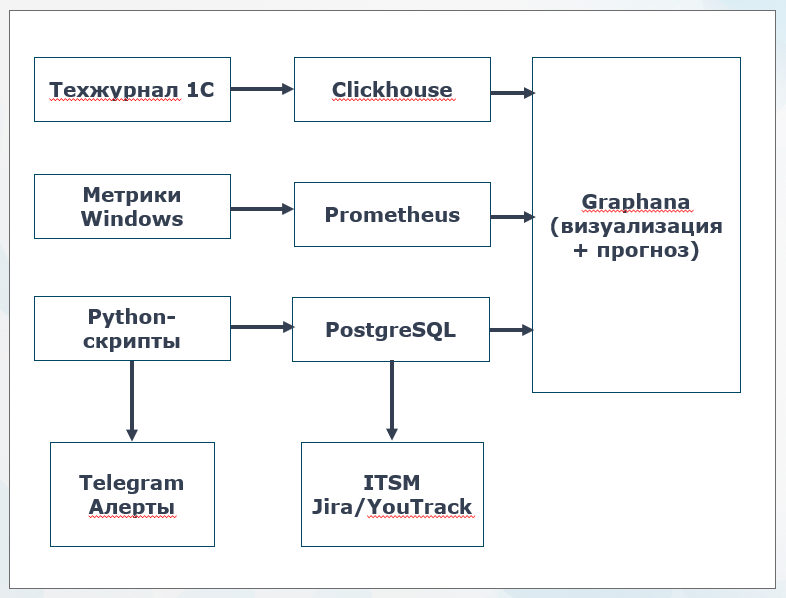
Архитектура строится вокруг четырех компонентов. ClickHouse хранит техжурнал 1С.
Prometheus собирает метрики с Windows и СУБД. Python-скрипты обучают модели, делают прогнозы и сохраняют результаты в PostgreSQL.
И все это визуализируется в Grafana – здесь мы смотрим графики, тренды и прогнозы.
При срабатывании алертов уходят уведомления в Telegram и автоматически создаются задачи в Jira или других ITSM-системах.
Все компоненты open source, все уже лежит в репозитории готовое.
Источники данных
| Технологический журнал 1С | Метрики СУБД |
| Длительность операций | Размер таблиц |
| Время ожиданий (WaitTime) | Cache Hit Ratio |
| Время блокировок (LockTime) | Статистика ожиданий |
| Контекст (пользователи) | Активные сессии |
Схема в ClickHouse: clickhouse/schema.sql
Еще раз напомню про источники данных. С ТЖ мы собираем и смотрим длительность операций, WaitTime, LockTime, контекст. С СУБД мы смотрим размер таблиц, Cache Hit Ratio, статистику ожиданий, активные сессии.
У нас два источника данных. Технологический журнал 1С показывает, что происходит внутри платформы: длительность операций, блокировки, ожидания.
А метрики СУБД и Windows рассказывают, почему базе данных плохо: заполнен ли диск, хватает ли памяти, кто создает нагрузку.
Критические тренды
| Тренд | Что измеряем | Прогноз |
| Заполнение диска | Размер таблиц | "Диск кончится через N дней" |
| Рост блокировок | LockTime в техжурнале | "Риск дедлока через M дней" |
| Деградация индексов | Рост Seq Scan | "Отчет упадет ниже SLA через K дней" |
Критические тренды, которые реализованы и вокруг которых построены скрипты, дашборды и прочее, такие.
Мы отслеживаем три главных тренда. Заполнение диска – считаем скорость роста и прогнозируем дату, когда место кончится.
Рост блокировок – если время ожидания увеличивается быстрее числа пользователей, скоро будет дедлок.
И деградация индексов – когда база начинает читать таблицы целиком вместо быстрого поиска по индексу.
ML-модели в проекте
| Модель | Файл | Назначение |
| Linear Regression | predict_disk.py | Прогноз заполнения диска |
| Isolation Forest | train_anomaly_detector.py | Поиск аномалий |
| Prophet | Grafana plugin | Прогноз с сезонностью |
ML для чайников: docs/ml_for_dummies.md
В проекте пока реализованы три типа моделей.
Первая – линейная регрессия (Linear Regression). Например, predict_disk.py – это прогноз диска.
Вторая – train_anomaly_detector.py, поиск аномалий. Это пример, когда мы анализируем сессии и падение количества сессий.
Третья – Prophet-модель. Она может учитывать сезонность, например то, что в понедельник нагрузка всегда выше, чем в пятницу.
PostgreSQL: хранение результатов

postgresql/create_tables.sql
PostgreSQL отвечает за сохранение результатов и прогнозов. Когда Python-скрипт отработал и сделал прогноз, он сохраняет результат в таблицу, например disk_forecast в PostgreSQL. Здесь как раз пример того, какие таблицы создаются. SQL-файл тоже можно посмотреть.
ClickHouse: хранение техжурнала

Полезные запросы: clickhouse/queries.sql
ClickHouse, как я уже сказал, используется для хранения ТЖ. Здесь мы выполняем и парсинг, и хранение. Здесь есть запрос: какая таблица создается, какой вид. Используется techlog_parser.py для парсинга технологического журнала регулярками и сохранения его в эту таблицу.
Технологический журнал 1С – это десятки, сотни гигабайт текста в день.
ClickHouse создан для таких объемов: он сжимает данные в 5-10 раз и отвечает на запросы за секунды.
В репозитории лежит готовая схема таблиц и полезные запросы для анализа блокировок.
Prometheus: сбор метрик
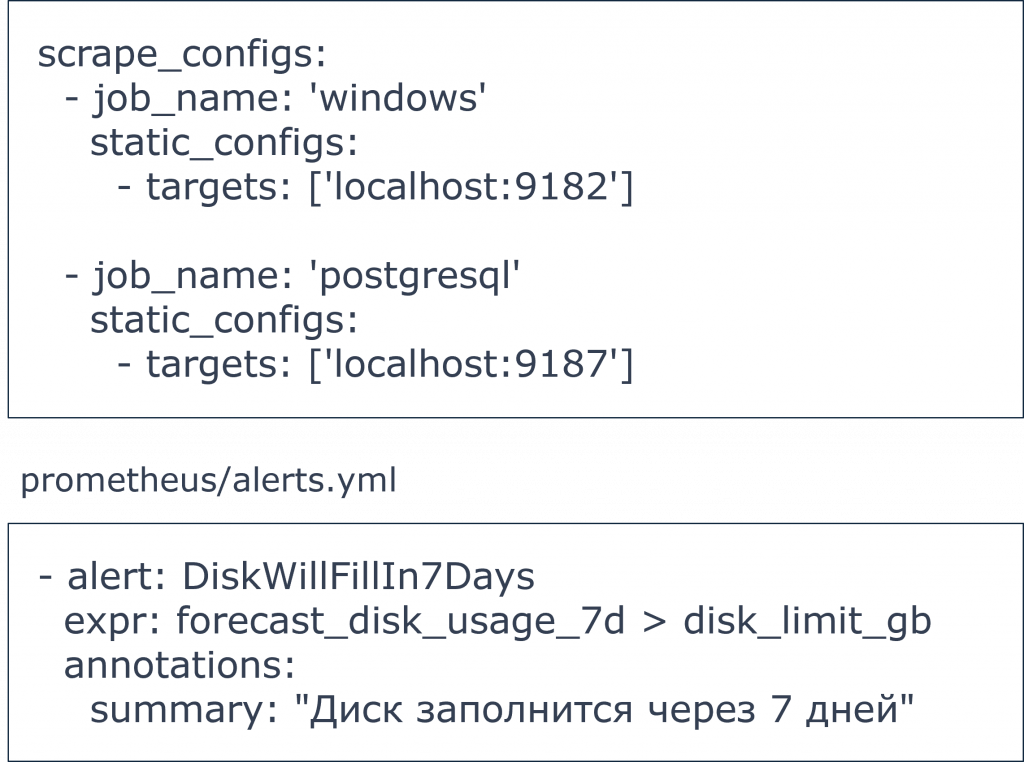
Prometheus использует pull-модель, то есть сам забирает метрики с эндпоинтов.
Для Windows используется windows_exporter на порту 9182.
Для PostgreSQL используется postgres_exporter на порту 9187.
Все метрики хранятся с временными метками и доступны через PromQL.
В репозитории уже готовый prometheus.yml со всеми нужными job'ами – просто укажите свои таргеты
Скрипт прогноза заполнения диска
Перейдем непосредственно к скриптам, о которых я говорил. Сначала дам сам скрипт, а потом подробное пояснение.

Скрипт predict_disk.py запускается раз в день, берет историю заполнения диска за 60 дней, обучает линейную регрессию и считает прогноз на 7, 14 и 30 дней вперед.
Если прогноз пересекает критический порог – создает задачу в Jira и отправляет алерт в Telegram.
Код открыт, можете посмотреть – там всего 5 строчек с моделью.
Как это физически работает? Прогноз диска
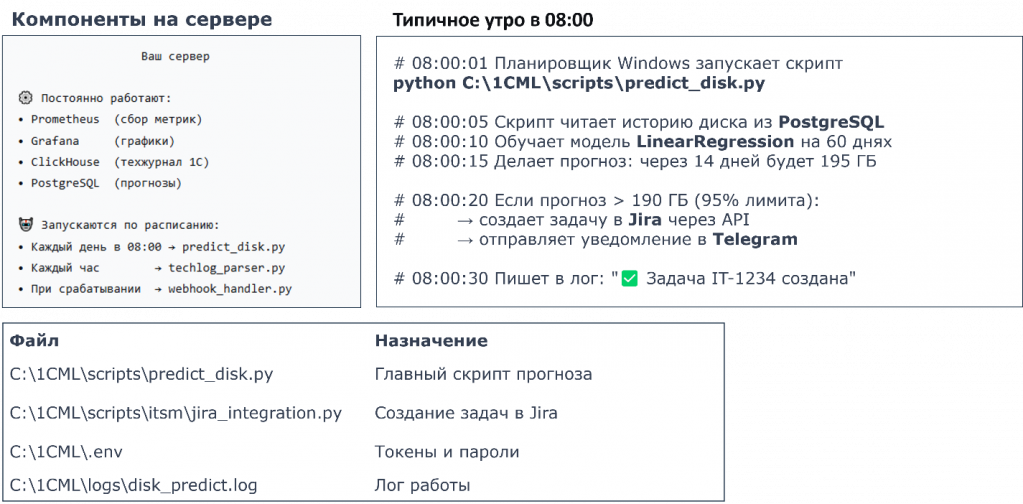
Давайте посмотрим, как это работает физически.
Каждое утро в 8 часов планировщик Windows запускает скрипт.
Он за 30 секунд делает все: читает историю, обучает модель, считает прогноз, проверяет пороги.
Если диск грозит заполниться – создает задачу в Jira и отправляет уведомление в Telegram.
Все автоматически, вы только смотрите дашборды и выполняете задачи из Jira.
Чтобы это было наглядно, я в docs создал MD-файлы с полным описанием того, как это работает: начиная от забора метрик, сохранения в таблицу, запуска скриптов и так далее. Например, disk_forecast_physical.md в docs – это сквозной пример.
Подробное описание, как физически работает прогноз диска:
disk-forecast-physical-workflow.md
Для прогноза диска у нас постоянно крутятся Prometheus, Grafana, ClickHouse, PostgreSQL. По расписанию для прогноза диска раз в день в 8:00 запускается планировщик.
Что он делает? Считает историю диска из PostgreSQL, обучает модель линейной регрессии с помощью Python на 60 днях, делает прогноз. Например, говорит, что через 14 дней будет 195 ГБ.
Если диск 200 ГБ, а у нас 195 ГБ, это выше 95% лимита. Значит, срабатывает алерт. В группу админов отправляется Telegram-уведомление и создается задача в Jira. В логе записывается, что задача такая-то создана.
Детектор аномалий

scripts/train_anomaly_detector.py
Детектор аномалий ищет необычное поведение системы.
Раз в неделю train_anomaly_detector.py обучает модель Isolation Forest на истории сессий и блокировок, а каждый час detect_anomalies.py проверяет текущие метрики.
Если сегодня в 10 утра сессий на 70% меньше обычного – система бьет тревогу.
Например, на 10:00 утра он смотрит: если обычно у нас 200 сессий, а сейчас на 70% меньше, будет алерт. Схема та же: уведомление в Telegram и задача в Jira.
Как это физически работает? Детектор аномалий

Как это физически работает? В 3:00, допустим, раз в неделю скрипт загружает 30 дней, обучает модель и сохраняет ее в anomaly_model.pkl. Каждый час detect_anomaly.py загружает свежие данные за последний час и сравнивает с обычной моделью. Если отклонение больше трех сигм, отправляется Telegram.
Пример срабатывания. Обычно у нас, к примеру, 150 сессий. Сегодня 40 сессий. Скрипт смотрит: 40 минус 150, стандартное отклонение равно 5,5 – это больше трех. Срабатывает условие, что нужно выполнить. Это реальные процедуры на Python: send_telegram и create_jira_ticket.
Система сразу бьет тревогу: возможно, упал планировщик или проблемы с доступом.
Мы узнаем об этом за часы до того, как пользователи начнут жаловаться.
В docs есть 1c-anomaly-detector.md. Это тоже сквозной пример от начала до конца, как все работает.
Подробное описание, как физически работает детектор аномалий сессий 1С:
1c-session-anomaly-detector.md
Прогноз дедлоков
Последнее – как физически работает прогноз дедлоков.
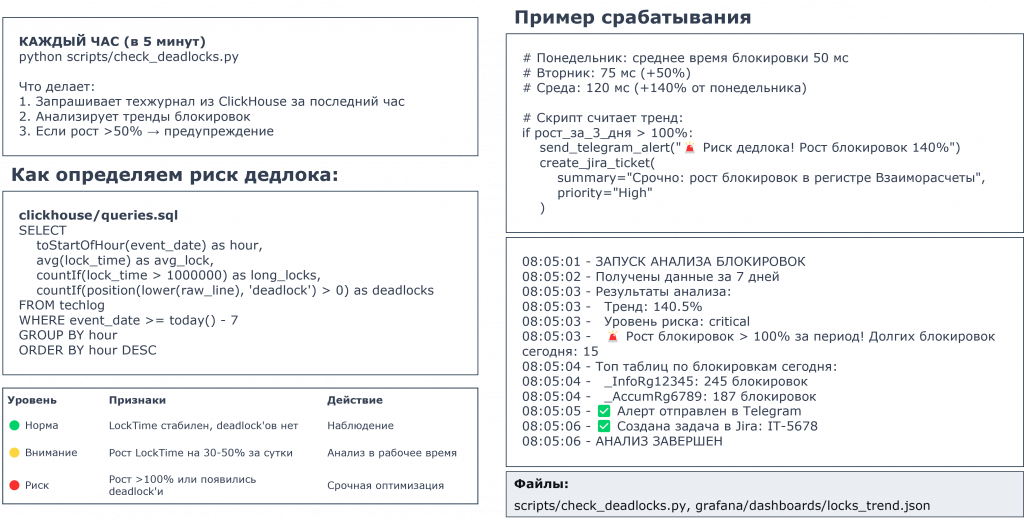
Каждые пять минут запрашиваются данные из технологического журнала в ClickHouse, где он у нас хранится. Далее скрипт анализирует тренды блокировок. Если рост больше 50%, можно смотреть, к примеру, время выполнения: среднее выполнение было одно, стало больше на 50% или больше на 100%. Если больше 100%, мы считаем, что сработал алерт.
Есть специальный скрипт. Данные по дедлокам сохраняются в ClickHouse, выполняется SQL-скрипт, который решает, сработал алерт или нет.
Пример срабатывания справа: в понедельник среднее время блокировки было 50 мс, во вторник стало 75 мс, в среду – 120 мс. Это плюс 140% от понедельника. Мы считаем тренд, и если тренд больше 100%, отправляем алерт в Telegram и создаем задачу в Jira.
По ходу определяется топ таблиц. В сообщении, которое будет создано в Jira, будет записано, какие именно таблицы нужно посмотреть.
Подробнее весь цикл от начала до конца можно посмотреть в docs, в 1c-deadlock-prediction.md. По запросу коллег я сделал дополнительный MD по расходованию ресурсов этими скриптами: ml_scripts_resource_usage.md.
Подробное описание:
Расход ресурсов ML-скриптами:
Сколько ресурсов потребляют скрипты
Самый тяжелый скрипт – techlog_parser.py. Ему нужны SSD и 2-4 ядра CPU с частотой от 2.5 ГГц
Пиковая нагрузка раз в неделю – train_anomaly_detector.py. Потребляет много CPU и RAM на 5-30 минут
Ежечасные скрипты – легкие, не создают заметной нагрузки, работают на 2.0+ ГГц
Частота CPU важна – разница между 2.0 ГГц и 3.0 ГГц дает ускорение в 1.5 раза для парсинга
Для старта достаточно 4 ядер CPU 2.5 ГГц и 2 ГБ RAM под ML-скрипты (плюс отдельно под БД)
Золотое правило: планируйте пиковые нагрузки (обучение моделей) на ночное время, когда мало пользователей.
Отдельно я не считаю базу данных. Я хочу сказать, что сами ML-скрипты потребляют относительно мало ресурсов.
Дашборды Grafana
Я уже упомянул, что в Grafana есть встроенный Grafana ML. Для Grafana я добавил три дашборда.
| Дашборд | Файл | Назначение |
| Прогноз диска | disk_forecast.json | Факт + прогноз + пороги |
| Тренды блокировок | locks_trend.json | Анализ LockTime |
| Контрольные карты | anomalies.json | Выявление аномалий |
Первый – disk_forecast.json. Это прогноз заполнения диска с доверительным интервалом.
Второй – locks_trend.json. Это график блокировок и топ таблиц.
Третий – anomalies.json. Это контрольные карты, где видно отклонение от нормы.
Пример дашборда: прогноз диска
Файл: grafana/dashboards/disk_forecast.json
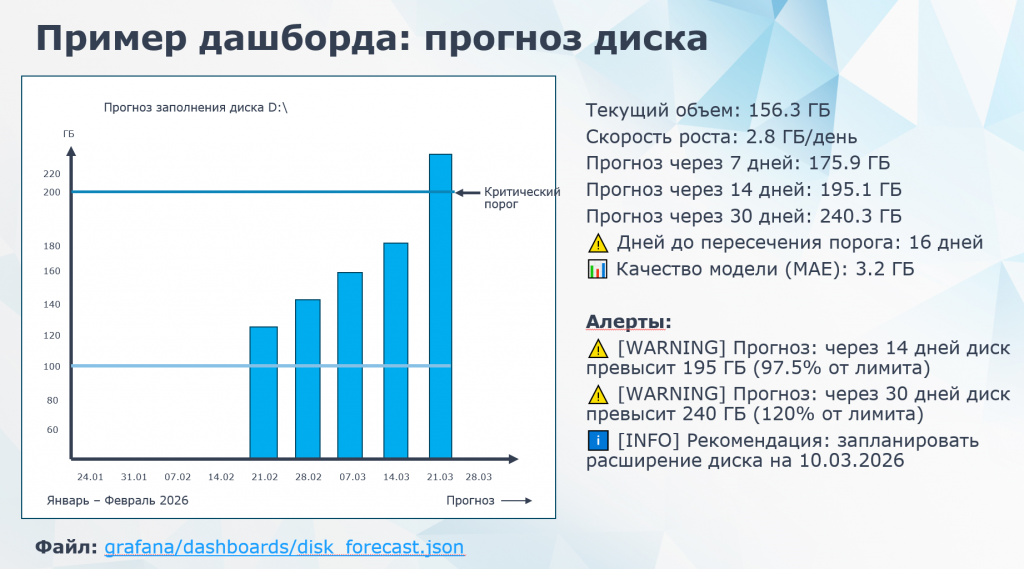
Для примера: прогноз диска именно в Grafana. Мы смотрим, что текущий объем, например, 156,3 ГБ, всего диск – 200 ГБ. Grafana тоже может предсказывать линейную регрессию.
Смотрим: через семь дней у нас 175 ГБ, через 14 дней – 195 ГБ, через 30 дней – 240 ГБ. Через 14 дней уже 97,5%, это плохо. Это больше 95%, уже warning. А через 30 дней прогноз вообще 240 ГБ. Понятно, что это никак не влезет в диск, который сам 200 ГБ.
Вот так это настраивается в Grafana.
Алерты в Telegram и ITSM-интеграция
Отдельно есть репозиторий scripts/alert_telegram.py, где с отзывами, заголовками, деталями можно отправлять сообщения. Это кусочек кода.
Алерты в Telegram
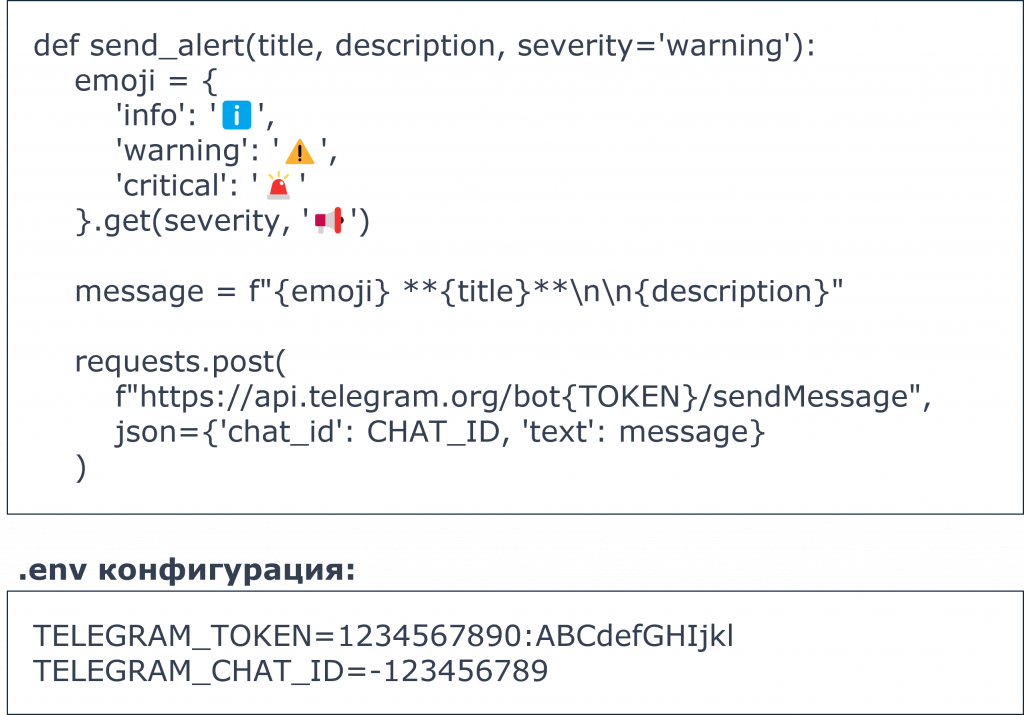
Как это настраивается? В общем файле можно настроить токен Telegram и chat ID, куда вы хотите отправлять эти уведомления. Таким образом можно связать Telegram со всей этой историей.
ITSM-интеграция: файлы репозитория
| Система | Версия API | Файл |
| Jira Cloud | REST v3 | jira_integration.py |
| Jira Server | REST v2 | jira_integration.py |
| YouTrack | Hub REST | youtrack_integration.py |
| ServiceNow | Table API | servicenow_integration.py |
| Redmine | REST | redmine_integration.py |
| GitLab Issues | REST v4 | gitlab_integration.py |
Есть также блок ITSM. Это то, что я говорил про ITSM-системы: например, Jira, YouTrack, GitLab Issues и прочее.
В репозитории есть отдельный модуль, папка scripts/itsm. Там они перечислены. В .env-файле можно указать тип вашей ITSM-системы и настроить ваши данные. Тогда уведомления будут отправляться туда, куда вам нужно.
Быстрый старт за 15 минут

Полная инструкция: docs/install_windows.md
Если вы хотите в таком же виде развернуть это на своей тестовой машине, можно использовать быстрый старт: клонировать репозиторий, запустить ClickHouse в Docker, восстановить зависимости и запустить тестовый прогноз, если у вас уже начнут загружаться данные в ClickHouse.
Вам не обязательно делать именно так. Вы можете подстроить это под свой процесс. Здесь имеется в виду вариант, если вы хотите поднять полностью тестовый контур с такими же параметрами, как в репозитории.
Ожидаемые результаты внедрения
Какие бизнесовые ожидания? Что мы получим от внедрения всего этого?
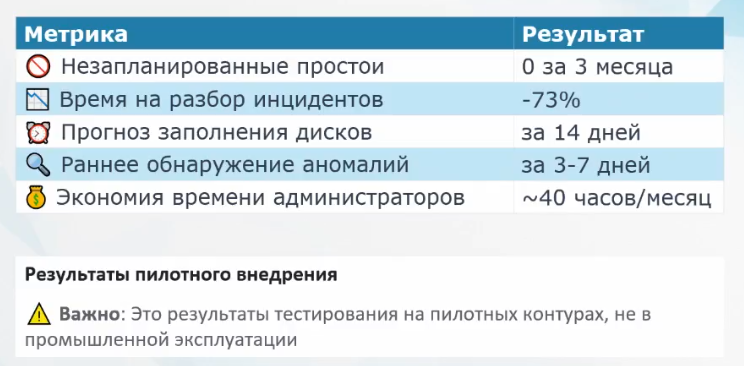
Ноль незапланированных простоев вместо 2-4 часов в месяц. Прогноз проблем за 14 дней вместо реагирования постфактум.
Экономию времени администраторов – 40 часов в месяц. В деньгах для компании с 500 пользователями это около 4.5 миллионов рублей в год.
IT перестает быть статьей расходов и становится стратегическим активом, который приносит бизнесу стабильность и экономию. Окупаемость – с первого же предотвращенного сбоя.
Планы развития 1CML
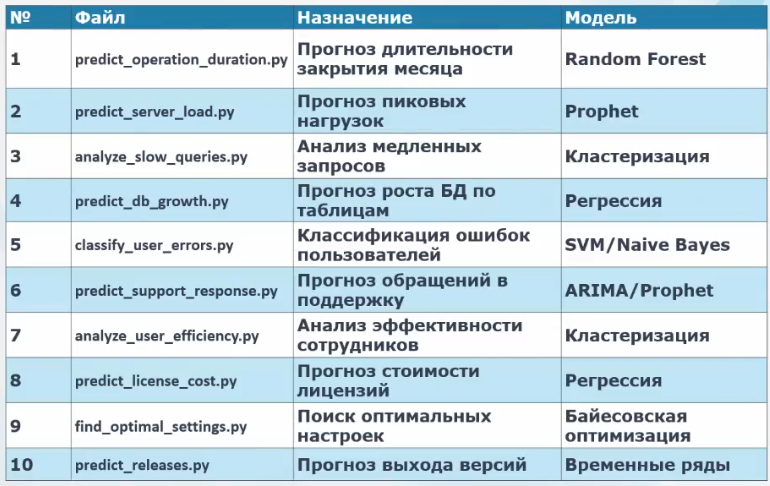
Что дальше? Можно добавить интеграцию с 1С через HTTP-сервисы, улучшить модель для прогноза дедлоков на Random Forest и сделать веб-интерфейс.
В среднесрочной перспективе – три новые ML-модели: прогноз длительности закрытия месяца, анализ медленных запросов с рекомендациями по индексам и прогноз пиковых нагрузок.
Есть и идеи для исследования – анализ эффективности сотрудников, прогноз лицензий, оптимизация настроек кластера. Все это открыто, код на GitHub, Pull Requests приветствуются.
Если интересно, присоединяйтесь!
И помните: это пока концепт, эксперимент, первые шаги. Но вы уже можете забрать себе полезные куски и доработать под свои задачи.
Итог
Итог – это ключевой сдвиг парадигмы.

Если вы раньше работали как пожарный, то теперь вы капитан дальнего плавания. Вы приходите к бизнесу и показываете отчет не о существующих катастрофах, а о предотвращенных катастрофах на текущий квартал и даже на следующий квартал.
Вы становитесь стратегическим активом, который экономит деньги, а не тратит их.
Коллеги, давайте запомним главное. Пока мы бегаем с ведром и тушим пожар, мы просто обслуживающий персонал. Но когда вы приходите к руководству или коллегам и говорите: «Я тут посчитал: если мы сейчас сделаем A, то через месяц случится Б», тогда мы становимся стратегами.
И тогда мы идем к руководству не с жалобой «упал сервер», а с отчетом: «Я предотвратил столько-то проблем на следующий месяц». Тогда можно просить больше денег. Обычно работает безотказно.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TEAM EVENT.


Вступайте в нашу телеграмм-группу Инфостарт