


Flowcon - это не самостоятельная конфигурация, ее нужно встраивать в корпоративную информационную систему (КИС), вроде УПП, ERP, УТ, УНФ, КА и т.д. Причина проста - управлять надо на основе данных, а данные лежат в КИС. Значит, и работать с ними надо в КИС.
Часть функционала реализована в виде единой конфигурации, часть - в виде расширений.
Список расширений постоянно пополняется.
Принципиально Flowcon охватывает следующие направления:
1. Управление качеством данных - потому что без качественных данных управлять можно только вслепую;
2. Представление и доставка информации - чтобы пользователи и руководители видели то, что им нужно, не тратя много усилий на поиск, навигацию, фильтрацию и т.д.;
3. Управление оперативными задачами - организация рутинных процессов и задач, с нужной прозрачностью, автоматизированным контролем и отслеживанием;
4. Управление уникальными задачами - теми, которые не повторяются ежедневно. Например, работой программистов или инженеров-конструкторов;
5. Управление закупками - процессом, который есть у всех компаний;
6. Список будет пополняться.
Далее, под спойлерами, описаны текущие подсистемы, которые уже доступны в конфигурации. В последнем спойлере - то, что еще будет добавлено позже.
Методика
Ключевое отличие управления задачами Flowcon в том, что это конфигурация, реализованная по методике. Это не очередное решение, в котором «вы сможете настроить свои бизнес-процессы».
Вы наверняка знаете простую истину: проблема в процессе, а не в его автоматизации.
Методику управления задачами и проектами, которая повышает эффективность работы, мы нарабатывали несколько лет. И на внутренней автоматизации, когда работали на заводах, и на разработке массовых продуктов, и на проектах внедрения для внешних заказчиков.
Эта методика и стала основой Flowcon, а конфигурация управления задачами просто автоматизирует ее применение.
Соответственно, хочу вас предостеречь: если вам принципиально важно работать так, как вы привыкли, то Flowcon может вам не подойти. Может, поэтому никто свою систему не дорабатывает?
Что-то, конечно, получится, может станет прозрачнее, или проще, или интереснее, но вы не получите главного – повышения эффективности.
Если ваша эффективность не растет, или вообще не измерена (оценка «да все нормально вроде» - не измерение), то проблема в процессе, в методике управления задачами. Какой тогда смысл брать очередное решение, подстраивать его под свои процессы, и получать тот же результат?
Поэтому, если решитесь заточиться под Flowcon, будьте готовы к изменениям. Иначе вас ждет разочарование – эффективность не вырастет.
Повышение эффективности – главное назначение Flowcon, и как методики, и как автоматизированной системы.
Краткая история методики Flowcon
Краткая история методики Flowcon – не такая уж и краткая, потому что продолжалась более 10 лет. Но мы старались подсократить, как могли – вот статья.
Процесс
Процесс движения задачи очень простой, состоит из трех участников – инициатора, ответственного и исполнителя. По нашей практике, это самый распространенный случай.
Инициатор – тот, кто ставит задачу. Это может быть внутренний заказчик, вроде главбуха, или начальник, или человек может сам себе поставить задачу. Ответственный – это координатор, который распределяет задачи. Может быть руководитель подразделения, или тимлидер, или просто координатор – такие должности тоже встречаются.
Исполнитель – тот, кто непосредственно реализует то, что написано в задаче. Исполнителя выбирает ответственный.
Разумеется, все эти роли может выполнять один человек – я сам, в основном, так и делаю, т.к. использую флакон для себя. Чтобы не тратить много времени на выбор самого себя, мы приделали быстрые кнопки.
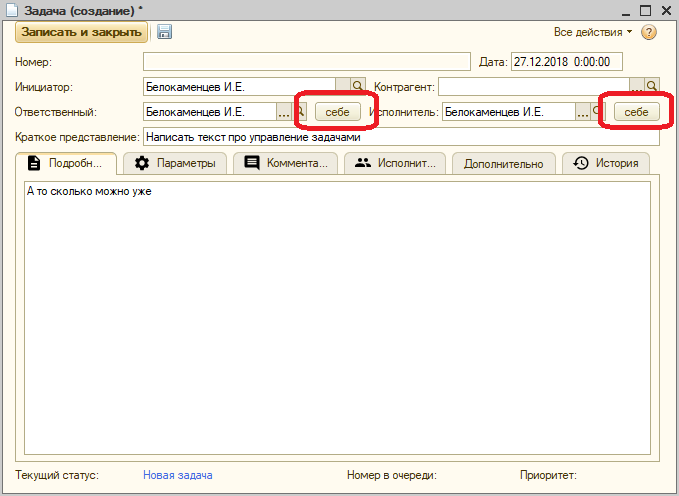
Жизненный цикл задачи
В методике Flowcon крайне важен жизненный цикл задачи. По каждой из них, в любой момент времени, должно быть понятно – кто и что должен сделать. Принять в работу, выполнить, проверить результат, назначить исполнителя и т.д.
Выглядит жизненный цикл так:
- Инициатор создает задачу, указывает ответственного, пишет чего хочет;
- У ответственного два варианта – принять задачу в работу, или отправить на доработку, если постановка не годится:
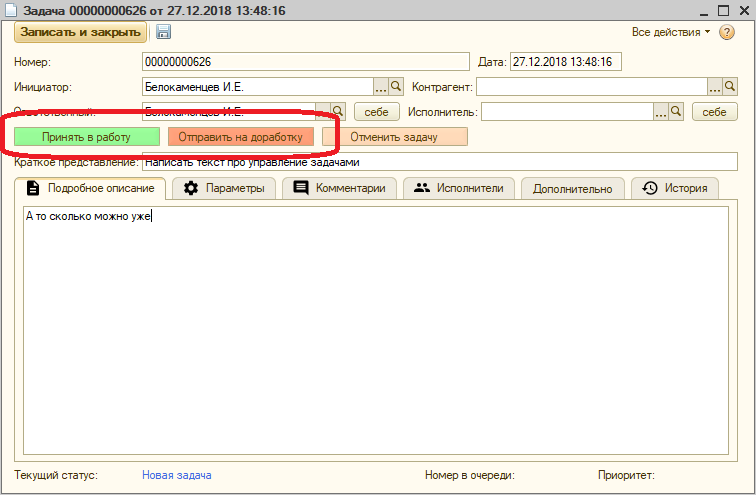
- В любой момент, пока задача не прошла весь цикл, инициатор может ее отменить;
- Если ответственный отправляет задачу на доработку, инициатор может или пойти ему навстречу, или отменить задачу:

- Когда задача, наконец, принята в работу, надо назначить исполнителя – этим занимается ответственный.
- У исполнителя вариантов не много – он может только выполнить задачу
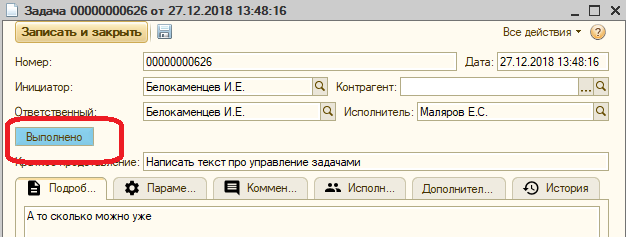
- Когда исполнитель закончил, задача улетает инициатору, у которого два разумных варианта действий:
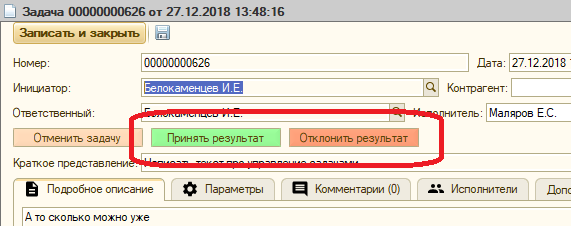
- Если результат устраивает инициатора, то жизненный цикл задачи завершается. Если же что-то не так, то задача возвращается исполнителю.
История смены статусов, то есть жизненный цикл задачи, сохраняется: 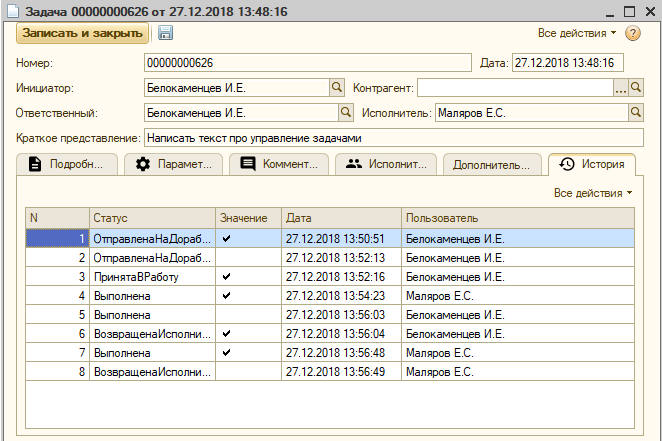
История нужна для того, чтобы оценивать потери времени на этапах согласований, и соотносить ее со временем выполнения в соответствующих отчетах.
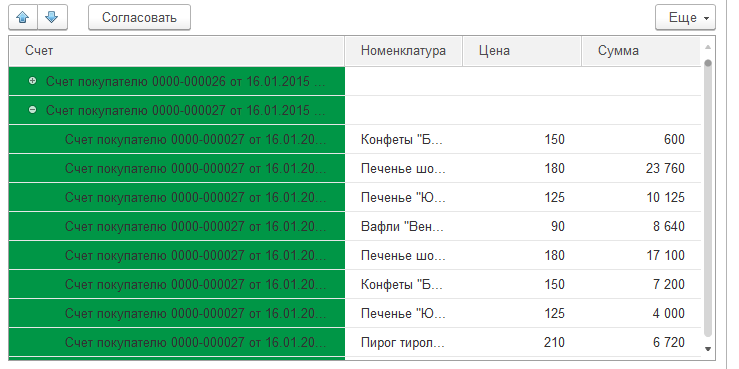
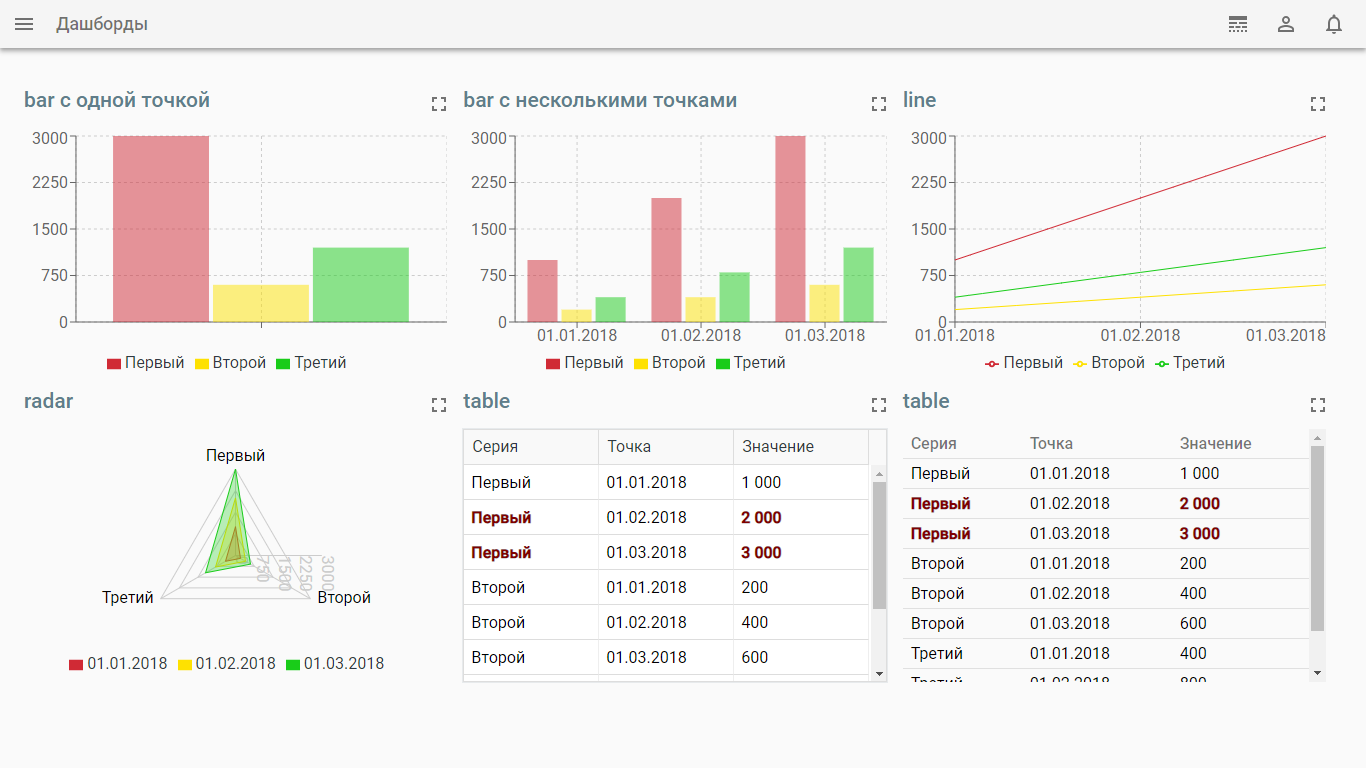
Текущий статус задачи отображается как в форме документа:
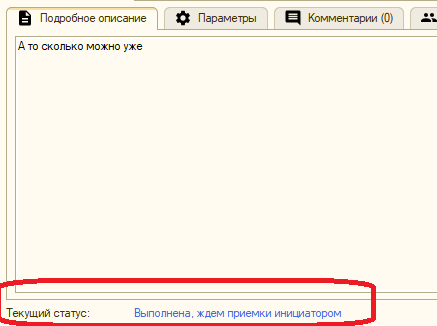
Так и в форме списка всех задач:
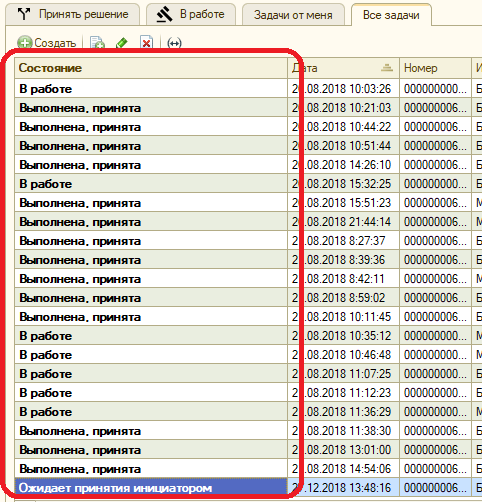
Регулярный менеджмент
Принципиально задача может находиться в трех ипостасях:
- Нужно чье-то решение;
- Ее нужно выполнять;
- Про нее нужно забыть.
Про выполнение поговорим дальше, а пока – про принятие решений. Прием в работу, назначение исполнителя, уточнение постановки, проверка результата, доработка – все это состояния, в которых кто-то должен принять какое-то решение.
Методика Flowcon говорит, что решения надо принимать, по возможности, быстро, потому что пока нет решения, задача зависает на соответствующем участке жизненного цикла.
Чтобы не мучить пользователей, мы разделили список задач на три принципиальных раздела: принять решение, выполнить и просто список всех задач.
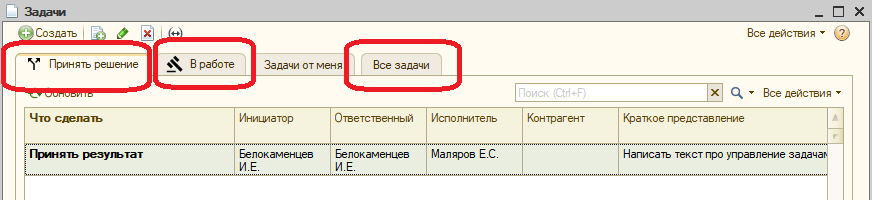
На закладке «В работе» собираются все задачи, по которым надо принять решение текущему пользователю системы:
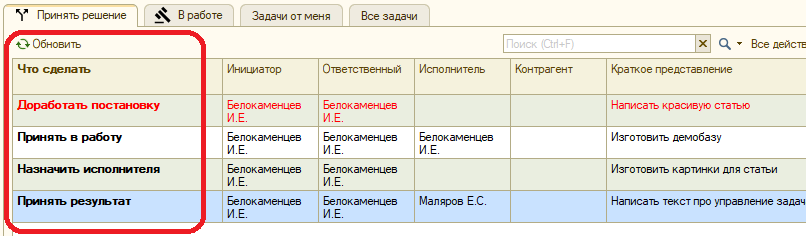
Прелесть в том, что не надо ничего искать. Зашел в форму списка задач и сразу увидел, где нужно твое решение. Все раскидал, и занялся исполнением. Нормальное состояние списка «Принять решение» - пустое.
Но флакон не было бы флаконом, если бы не контролировал принятие решений. На каждый вид решения есть норматив времени в настройках Flowcon:
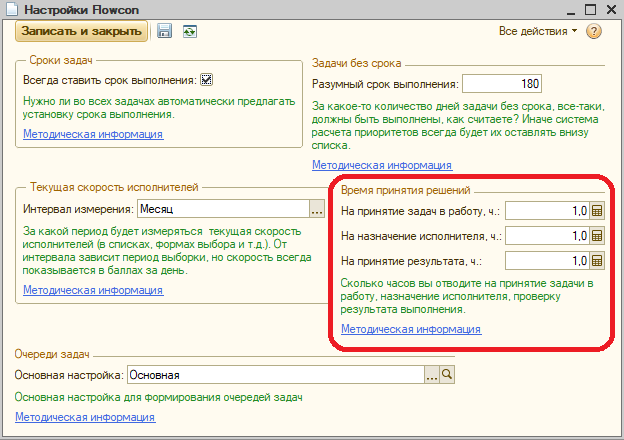
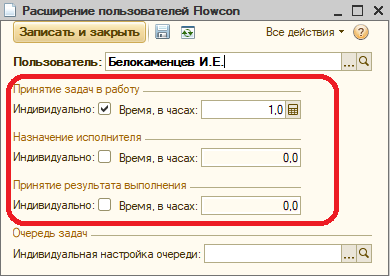
Понятно, что в реальной жизни одним и тем же нормативом всех пользователей не опишешь – кто-то ведь реально не может принимать решение в течение часа? Поэтому есть возможность задавать индивидуальные цифры, в расширении пользователя:
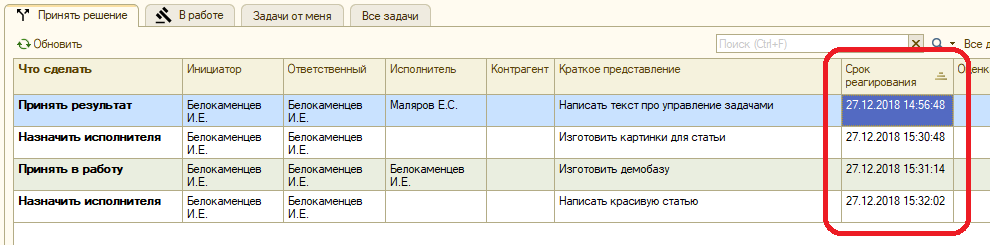
Соответственно, в списке «Принять решение» отображается срок реагирования, чтобы человек не переживал:
Параметры задачи
Параметры задачи – это оценка в баллах, срочность/важность и срок выполнения:
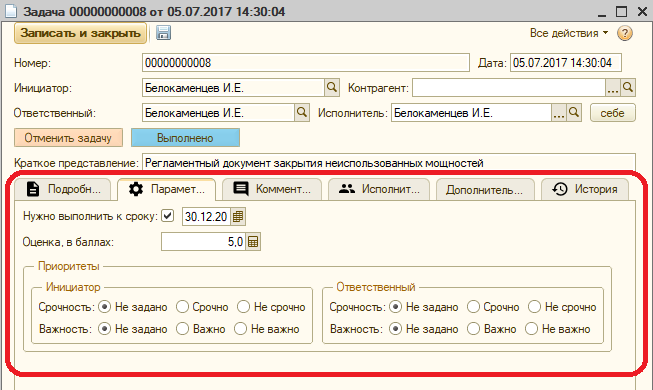
Оценка задачи в баллах – это самое главное. В методике Flowcon этому посвящен целый раздел, поэтому повторяться не буду.
Ставить задаче срок, или нет, решает инициатор. У меня нет однозначной рекомендации на счет того, нужен задачам срок, или нет. Важно правильно понимать, что этот срок означает.
Единственное, что хочется отметить: какой-то срок все-таки должен быть, иначе система приоритетов (см. ниже) сделает так, что задача не решится никогда. Поэтому у нас в настройках есть две опции:

Разумный срок – это некий срок по умолчанию, который ставится всем задачам, если инициатор не указал точную дату. Флажок «Всегда ставить срок выполнения» - чисто интерфейсный, он взводит флажок «Нужно выполнить к сроку» в каждой новой задаче.
Срочность и важность – это приоритеты по матрице Эйзенхауэра. Понимая, что мнение у инициатора и ответственного может различаться, мы возможность расстановки приоритетов для каждого. Заполнять эти реквизиты не обязательно.
Система приоритетов
Система приоритетов – одна из важнейших частей флакона. В методике много написано о том, почему важно максимально убрать возможность выбора задачи для исполнителя – эффективность от этого только выиграет, а человек мучиться не будет.
Мы долго думали, как устроить систему приоритетов, и пришли к самому простому решению – суммированию отдельных оценок каждого фактора, влияющего на приоритет. Сейчас таких факторов пять (будет больше):
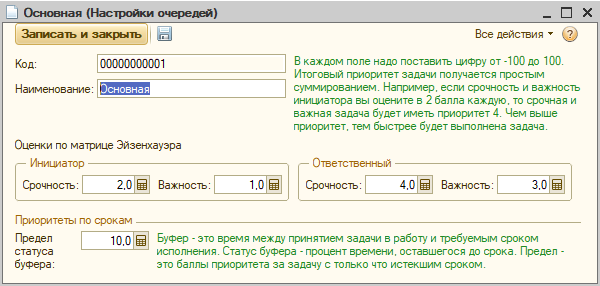
Вы просто ставите баллы приоритета каждому фактору, а система смотрит на задачу, и если фактор присутствует, добавляет их к общей цифре приоритета. Например, если вы выбрали только один фактор – срочность инициатора, и поставили ему 2 балла, то срочная задача будет иметь приоритет 2, а не срочная – 0.
Чуть подробнее скажу про статус буфера. Буфер – это длина отрезка времени от даты принятия задачи в работу до установленного срока исполнения. Например, пусть это будет 10 дней.
В любой момент времени мы находимся в какой-то точке этого отрезка. Прошел один день – значит, позади 10 % отрезка. Прошло три дня – 30 %, и т.д.
Соответственно, есть и обратная цифра – сколько времени осталось до срока. Если прошел один день, то осталось 90 %. Если прошло три дня, то осталось 70 %, и т.д. Это и есть статус буфера.
Ну а дальше все просто. Вы в настройке приоритетов ставите цифру, которая называется «Предел статуса буфера» - это сумма, добавляемая к приоритету, когда статус буфера равен нулю, т.е наступил срок выполнения задачи. А пока срок не пришел, эта цифра умножается длину пройденного участка времени.
Например, вы поставили оценку 10. Если прошло 30 % времени, то к приоритету добавится 3. Если задача только-только поставлена, то прибавится 0. Если времени совсем не осталось, то добавиться 10.
А если срок уже прошел, то добавится больше 10. Например, если прошло 150 % времени, то добавится 15. Таким образом, никакая задача не пропадет, и не затеряется.
Настройки приоритетов хранятся в справочнике «Настройки очередей». Раз это справочник, то понятно – настроек можно быть сколько угодно. Основная, работающая по умолчанию, указывается в настройках Flowcon. Для конкретного исполнителя можно переопределить, в расширении пользователя.
Главный смысл, который мы вкладывали в систему приоритетов – простота. И настройки, и использования. Систему приоритетов нужно настроить один раз, и надолго о ней забыть – она будет работать сама.
Если приоритеты по матрице Эйзенхауэра – статические, то по статусу буфера – динамические. Система не забудет, что время идет, и будет автоматически двигать задачи в очереди, чтобы не допустить просрочку.
Каждой задаче присваивается, и автоматически пересчитывается номер в очереди. Очередь привязана к текущему исполнителю, т.е. она у каждого своя.
Текущий номер в очереди и приоритет можно увидеть как в форме задачи:

Так и в списке задач к исполнению:
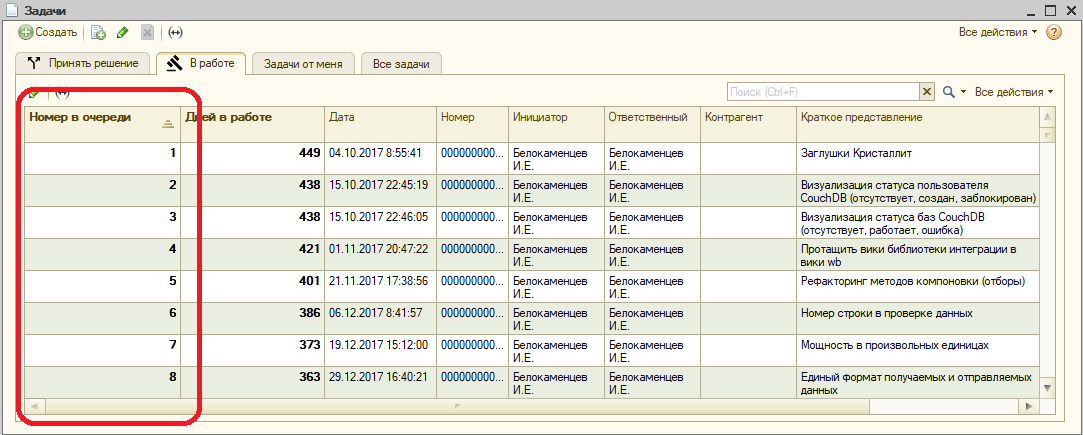
Список задач, разумеется, сортирован по номеру в очереди. Исполнитель должен просто брать их по порядку, и делать. А если не делает, то флакон об этом покажет.
Отчеты
Соблюдает исполнитель очередность, или нет, видно в отчете «График отклонений от очереди»:
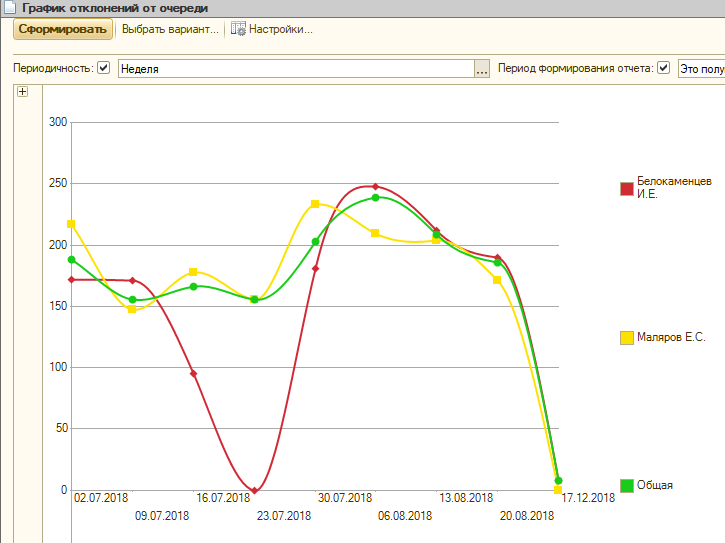
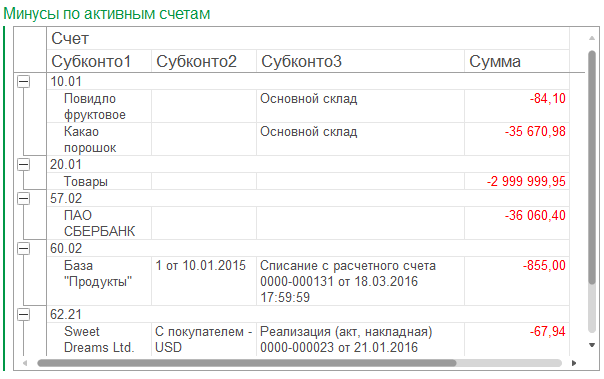
Когда исполнитель закрывает задачу, как выполненную, система запоминает, на какой позиции в очереди она была. Ну и рисует на графике сумму отклонений за период. Отклонение – это разница между позицией в очереди на момент закрытия, и единицей.
Как видите, у нас в Окнософте с очередью большие проблемы. А когда перешли на флакон, и увидели, то схватились за голову и стали исправляться – график пошел вниз.
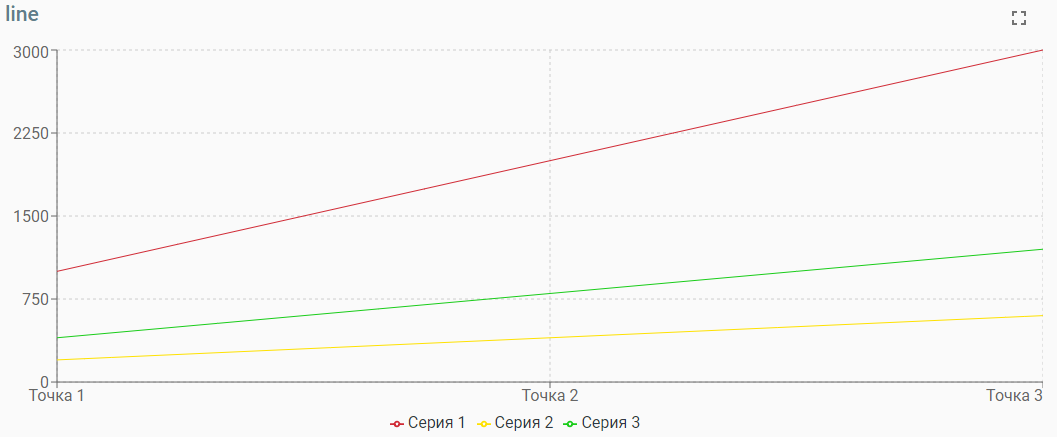
Второй отчет – «График эффективности». Это самый главный отчет, в котором будет видеy рост эффективности исполнителей. На графике выводится количество баллов выполненных задач, в привязке к периоду.
Например, вот что происходило с нашей эффективностью:

Отчетливо видно, когда мы ходили в отпуск – март и август, был провал в сумме баллов. Хотя, в целом, тренд положительный и очень впечатляющий.
Не менее важный отчет, необходимый, в первую очередь, координатору каждый день – это «Контроль исполнителей».
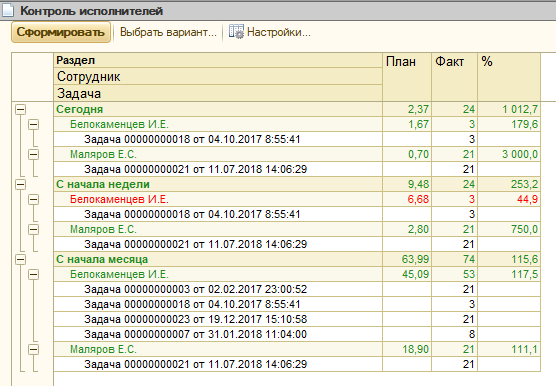
Этот отчет – все в одном окне. Не надо никого дергать, спрашивать, кто как работает, кто сколько сделал. Зашел, и посмотрел.
Что важно – исполнение задач поделено по периодам, чтобы избежать влияния «вспышек» - например, если исполнитель закрыл сегодня одну большую задачу, а с начала месяца ничего не делал. Тут видно сразу и месяц, и неделю, и сегодняшний день. А подсветка красным поможет понять, у кого динамика нормальная, а у кого – трудности. Отличный повод поговорить.
Количество отчетов будет расти, пока – только те, без которых нельзя обойтись.
Мгновенные оценки
Важнейшим направлением развития системы являются мгновенные оценки. Раз мы знаем, с какой скоростью работают исполнители, как они соблюдают очередь, как укладываются в сроки, то мы можем делать прогнозы. Например, сколько реально времени займет выполнение задачи.
Функциональность мгновенных оценок еще не закончена, пока есть только один параметр – текущая скорость, т.е. сколько баллов задач человек выполняет в день.
Видно ее в форме выбора исполнителя:
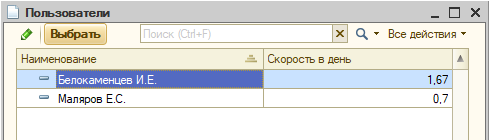
Ответственный, зная оценку задачи, может сразу прикидывать, кому ее лучше поручить, исходя из текущей скорости.
Комментарии
Какая система управления задачами без прений? У нас тоже есть – комментарии.
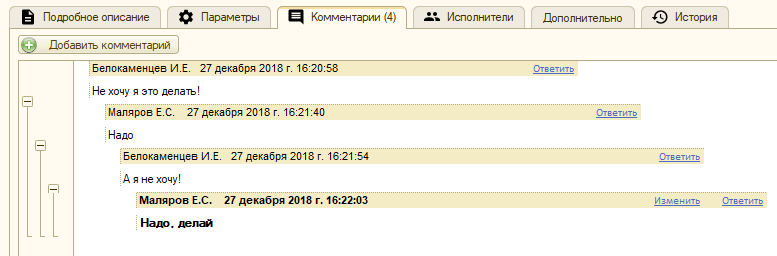
Комментарии иерархические, поэтому видно, кто кому и на что отвечает. Ведется учет прочтения комментариев, поэтому в списке задач жирным выделяются те, где есть что почитать:
Сотрудничество
Методика флакон говорит, что люди должны сотрудничать. Часто бывает так, что один человек помогает другому решить задачу. Нам важно, чтобы вклад каждого был учтен, поэтому в задаче можно уточнить список исполнителей, и определить для каждого коэффициент трудового участия (КТУ):
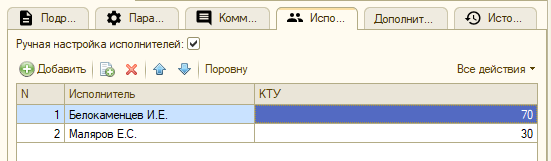
Баллы за задачу будут поделены между исполнителями, в пропорции КТУ. Так, вроде, честнее.
Кстати, пока писал статью, весь мой список задач для принятия решения покраснел: 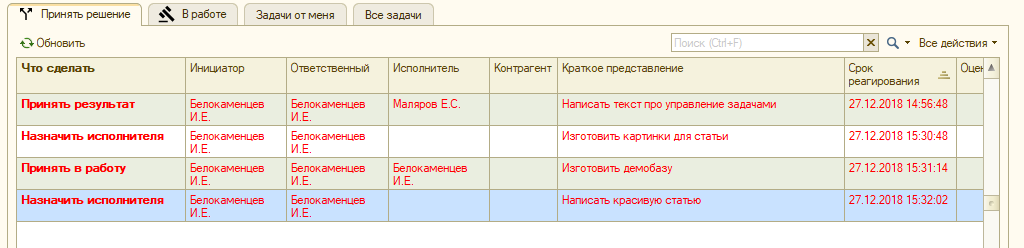
Что такое «Рабочий стол», зачем он создан и какие дает возможности, описано здесь.
В данном материале – инструкция по настройке.
Внедрение в конфигурацию
Рабочий стол будет работать с любой конфигурацией на платформе 8.2 и старше. Все объекты, необходимые для работы «Рабочего стола», находятся в подсистемах «флРабочийСтол», «флОбщиеОбъекты» и «флОтчетыИПоказатели». Вот перечень объектов:
- Общий модуль «флОтчеты»;
- Роль «флПользователь»;
- Интерфейс «флОбщий»;
- Общая картинка «флФлакон»;
- Справочник «флКоманды»;
- Справочник «флРабочиеСтолы»;
- Справочник «флСхемыКомпоновки»;
- Справочник «флЭлементыРабочегоСтола»;
- Перечисление «флГруппировкаГруппыУФ»;
- Перечисление «флВидыЭлементовРабочегоСтола»;
- Перечисление «флТипыПолейНабораСсылок»;
- Обработка «флРабочийСтол»;
- Регистр сведений «флНазначениеРабочихСтолов».
Для того, чтобы пользователи могли увидеть свои рабочие столы, нужно дать им роль «флПользователь». Настройка элементов и рабочих столов осуществляется под полными правами.
Для того, чтобы рабочий стол открывался автоматически при старте системы, нужно выполнить определенные действия в конфигурации:
- Для управляемых приложений – поместить обработку «флРабочийСтол» на начальную страницу;
- Для обычных приложений – написать в модуле обычного приложения конфигурации, в процедуре «ПриНачалеРаботыСистемы», строку: ОткрытьФорму("Обработка.флРабочийСтол.Форма.Форма");
Для обычных приложений, также, создан непереключаемый интерфейс «флОбщий», который содержит всего одну кнопку – «Рабочий стол», с вызовом по сочетанию клавиш Ctrl+D (по аналогии с рабочим столом Windows, который вызывается комбинацией Wnd+D).
Обработка «Рабочий стол»
Собственно, это и есть рабочий стол. При запуске он определяет, какие рабочие столы назначены текущему пользователю, читает их настройку и элементы, рисует все это на экране. Выглядит примерно так:
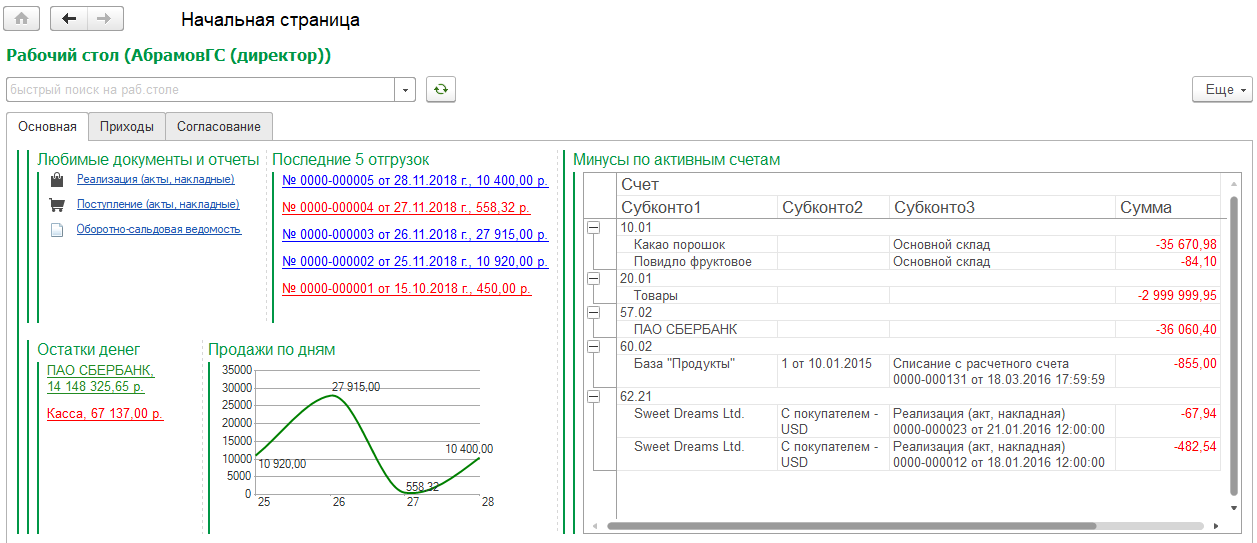
На форме есть группа типа «страницы», между которыми можно переключаться. На каждой странице – свой набор элементов. Можно нажимать на все элементы, что при этом произойдет – зависит от фантазии программиста, который настраивал рабочий стол. Как правило, произойдет открытие чего-либо – формы списка, объекта, расшифровка отчета, выбор команды для исполнения.
В верхней левой части формы находится поле поиска. Это для тех случаев, когда на рабочем столе выведено много элементов, и пользователю трудно или лень искать то, что ему нужно. Тогда он может воспользоваться поиском.
У рабочего стола два варианта ручного обновления:
- Кнопка «Обновить» на форме – обновляет содержимое элементов, т.е. переформирует отчеты, наборы ссылок, диаграммы и т.д., не пересоздавая элементы;
- Кнопка «Еще - Перезагрузить» - полностью обновляет рабочий стол, по поведению аналогична открытию и закрытию формы. Создана для того, чтобы можно было обновить рабочий стол в управляемой форме – начальную страницу ведь нельзя закрыть.
Есть еще автоматическое обновление, о нем будет рассказано дальше.
Справочник «Рабочие столы»
Справочник «Рабочие столы» содержит, собственно, настройки рабочих столов, т.е. их компоновку из элементов и групп. Про элементы поговорим позже.
Выглядит настройка рабочего стола вот так:
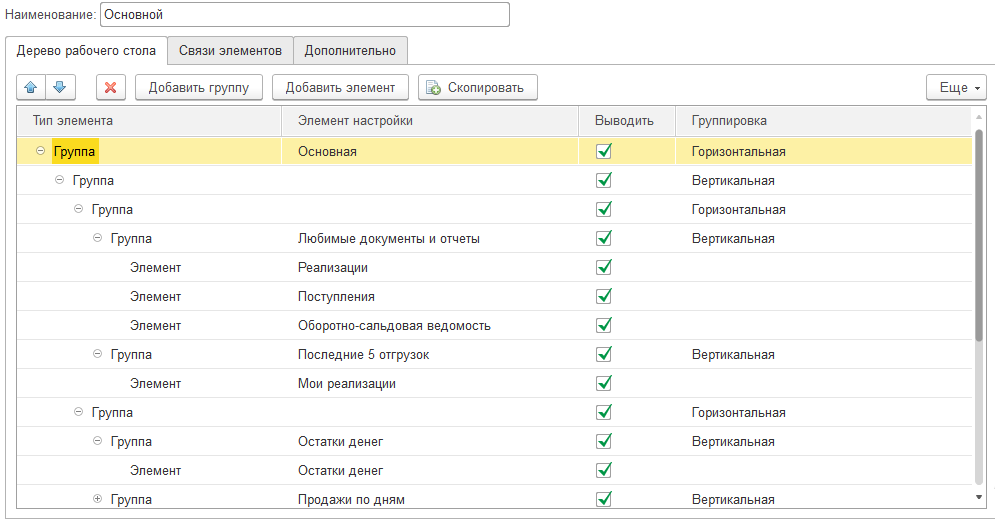
Компоновка рабочего стола представляет собой дерево. Не верхнем уровне иерархии – страницы, которые нарисуются на рабочем столе пользователя. Для страницы можно указать название (в поле «Элемент настройки»), признак «Выводить» и группировку – горизонтальная или вертикальная. В зависимости от группировки элементы будут в столбик, или в строчку – ровно как в настройке управляемых форм.
В иерархию страниц можно добавлять произвольное количество групп, которые будут превращаться в группы формы. Настраиваются аналогично страницам – заголовок, выводить, группировка. Можно вкладывать группы в группы, без ограничений. Добавление группы осуществляется по кнопке «Добавить группу». Перед этим надо встать на родительскую строку.
Когда группы созданы, можно выводить элементы. Тут все аналогично, только вместо заголовка надо выбрать элемент, из справочника «Элементы рабочих столов». Добавление элемента осуществляется по кнопке «Добавить элемент».
Копирование ветки осуществляется кнопкой «Скопировать». При этом копируется и текущая строка, и все вложенные в нее элементы и группы.
При удалении, если внутри текущей строки есть элементы или группы, будет задан соответствующий вопрос.
Работает перетаскивание групп и элементов – так можно переподчинять куски дерева.
Назначение рабочих столов
Пользователю можно назначить несколько рабочих столов одновременно. При этом произойдет объединение на уровне страниц. Например, если вы назначили два рабочих стола, в каждом – по две страницы, то в итоге пользователь увидит четыре страницы.
Это очень удобно, если всем, или нескольким пользователям надо видеть одну-две одинаковые страницы, но, при этом, еще и пару своих, уникальных.
Назначение рабочих столов осуществляется в регистре сведений «Назначение рабочих столов». Добавляете запись, указываете пользователя, рабочий стол и порядок, который определяет, какой рабочий стол выведется первым, какой – вторым и т.д. Можно указывать любые цифры в порядке, лишь бы они разные были. Один и тот же рабочий стол назначить одному пользователю дважды не даст.
Схемы компоновки
Это справочник, который используется при настройке большинства элементов рабочего стола. Он очень простой по своей структуре и функциональности.
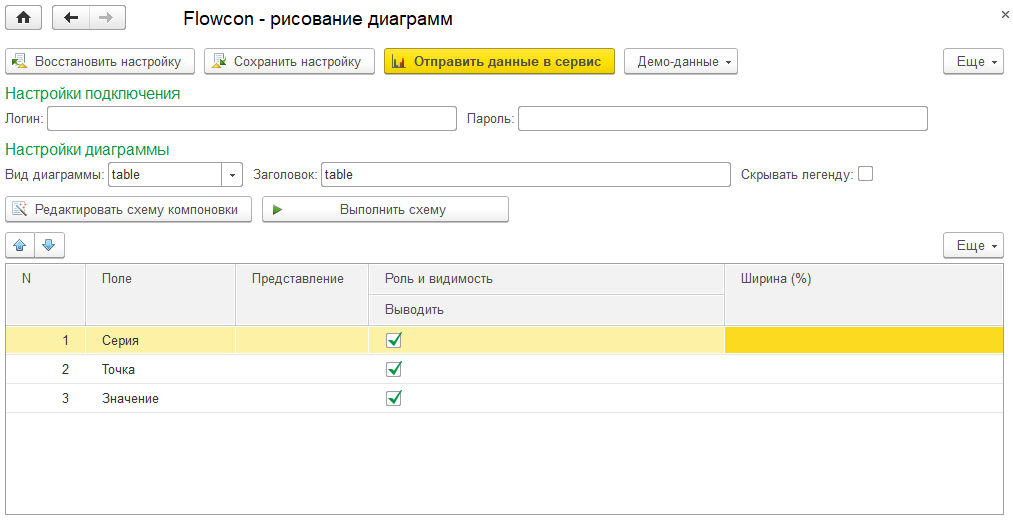
Выглядит элемент справочника так:
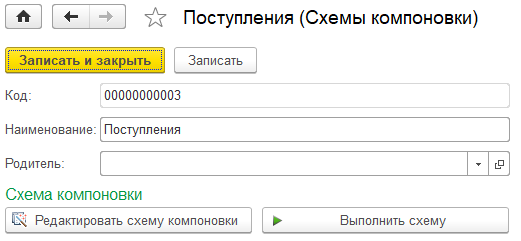
Элементов управления всего два. «Редактировать схему компоновки» открывает конструктор схемы. «Выполнить схему» - выполняет схему с настройками по умолчанию, результат выводит в табличный документ, показывает его на экране.
Разумеется, для настройки схем компоновки необходимо запустить 1С в режиме толстого клиента, обычном или управляемом приложении. Пользователю, чтобы увидеть результаты выполнения схем на своем рабочем столе, толстый клиент не нужен, т.к. выполнение схем происходит на сервере.
Требования к схеме компоновки зависят от того, в каком элементе она будет использована.
Справочник «Команды»
Этот справочник используется в нескольких видах элементов рабочего стола, поэтому напишем про него отдельно.
Справочник очень простой. Выглядит так:
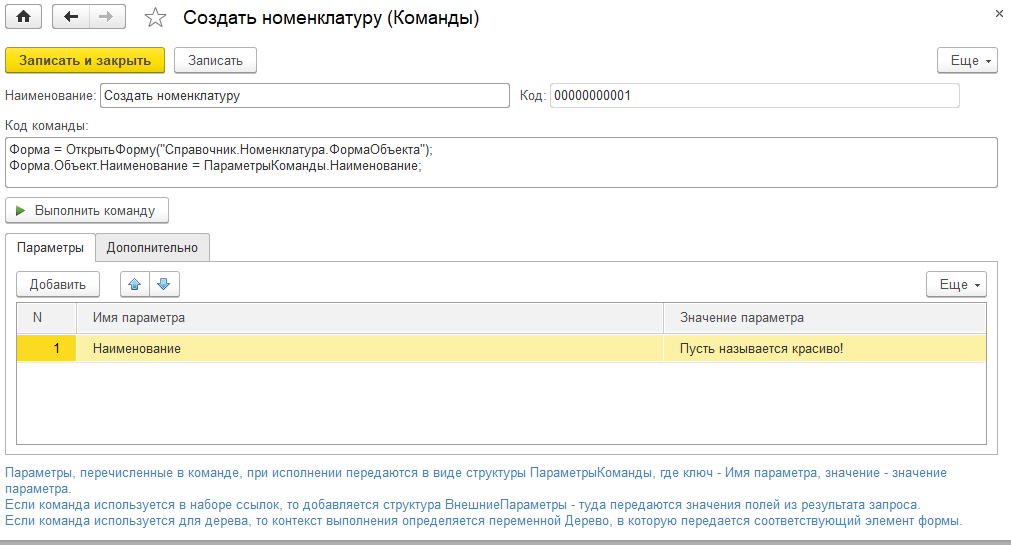
Назначение справочника – исполнение произвольного кода, который вы напишете в поле «Код команды». Код может быть как независимым – например, если он будет исполняться по нажатию кнопки на рабочем столе, так и контекстно-зависимым, если будет исполняться по нажатию на ссылку или вообще привяжется к дереву.
При написании произвольного кода важно иметь привязку к данным – например, открыть определенную обработку, или создать документ и подставить определенные значения в реквизиты. Чтобы не использовать любимые конструкции вроде «НайтиПоКоду», в команде есть параметры – табличная часть.
Вы просто добавляете любые параметры, которые нужны вам в коде, даете им имена и устанавливаете значение (число, строка, булево, дата, любая ссылка). А в коде обращаетесь к этим параметрам – они лежат в структуре «ПараметрыКоманды» (см. пример использования на скриншоте).
Когда команда контекстно-зависимая, то появляется еще структура «ВнешниеПараметры» или даже «Дерево» (см. подсказку внизу формы). Более подробно использование этих возможностей будет рассмотрено ниже.
Элементы рабочего стола
Это – главный справочник всей подсистемы. В нем настраиваются элементы – кирпичики, из которых компонуется рабочий стол конкретного пользователя.
Форма элемента рабочего стола выглядит примерно так:
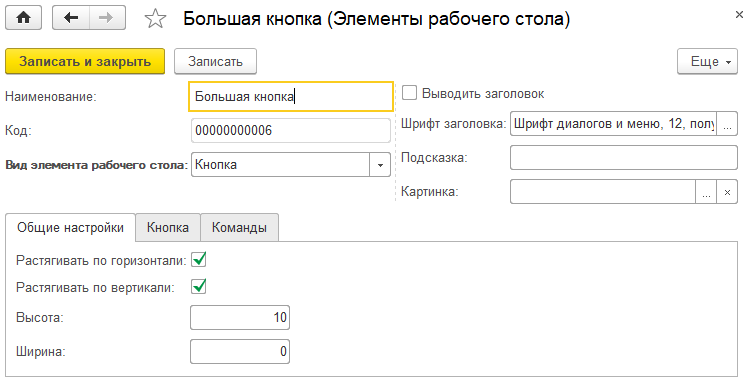
Но, в зависимости от выбранного вида элемента, внешний вид формы будет меняться. Основные реквизиты, доступные для всех видов элемента:
- Вид элемента рабочего стола – определяет, что это будет – отчет, диаграмма и т.д.;
- Выводить заголовок – определяет, нужен ли заголовок элементу;
- Шрифт заголовка – можно изменить типовой, чтобы выделить элемент на рабочем столе;
- Подсказка – ну, тут все понятно;
- Картинка – выводится у заголовка, можно выбрать любую из стандартных или добавленных в конфигурацию. Из файлов выбирать нельзя, управляемые формы этого не любят;
- Растягивать по горизонтали, растягивать по вертикали – для точечной настройки размеров элемента. По умолчанию все элементы растягиваются и вверх, и вниз на доступное свободное пространство;
- Высота, ширина – аналогично. Если стоят нули, то размеры определяются автоматически.
Теперь рассмотрим настройку элементов рабочего стола в зависимости от вида.
Объект метаданных
Вид элемента «Объект метаданных» – это ссылка на форму списка документа, справочника, регистра сведений и т.д. Самый простой тип элемента.
Настройка выглядит так:
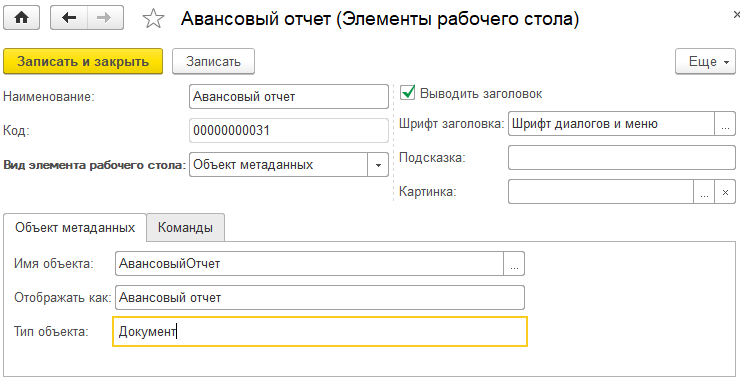
Главное, что надо выбрать – реквизит «Имя объекта». При выборе открывается такая форма:
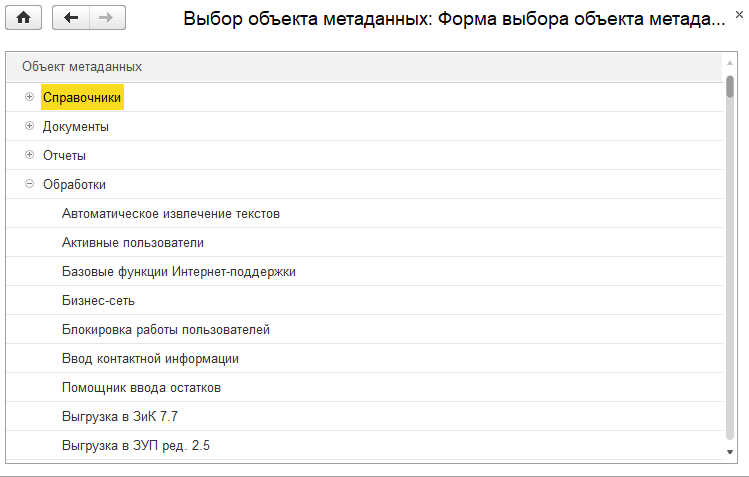
Просто выбираете объект, который должен открываться с рабочего стола, и он будет открываться. В поле «Отображать как» можно переопределить заголовок (по умолчанию берется синоним объекта метаданных).
Отчет
Отчет – тоже очень простой в настройке объект, даже картинку можно не приводить. Единственное, что надо указать – схему компоновки.
На рабочем столе просто выведется табличный документ с отчетом. Единственное ограничение на разработку схемы компоновки – она должна содержать в себе все, что надо для формирования отчета, потому что пользователь ничего настраивать не сможет. Поэтому внимательно выполняйте настройку по умолчанию.
У отчетов есть еще один вариант использования – расшифровка динамических списков, об этом будет рассказано далее.
Выглядеть отчет на рабочем столе будет примерно так:
Диаграмма
Настройка полностью аналогична отчету, разница только в настройке схемы компоновки. Нужно сделать так, чтобы выводилась диаграмма, причем – одна.
Особенность в том, что диаграмма выводится не на рабочий стол, а на форму. Создается элемент формы диаграмма, в него копируются все серии, точки и настройки из диаграммы, которую построила схема компоновки.
Соответственно, если ваша схема вернет больше одной диаграммы, выведется только первая.
Требования к схеме компоновки – как в отчете. Настроек пользователь делать не сможет, поэтому схема компоновки должна без вопросов возвращать готовую диаграмму.
Выглядеть будет примерно так:

Перерисовка диаграммы из табличного документа на форму нужна для того, чтобы смотрелось прилично, и можно было управлять размером элементов – пользователь двигает границы, диаграммы меняют свой размер. Вот картинка, показывающая разницу между диаграммами в табличном документе и на форме:
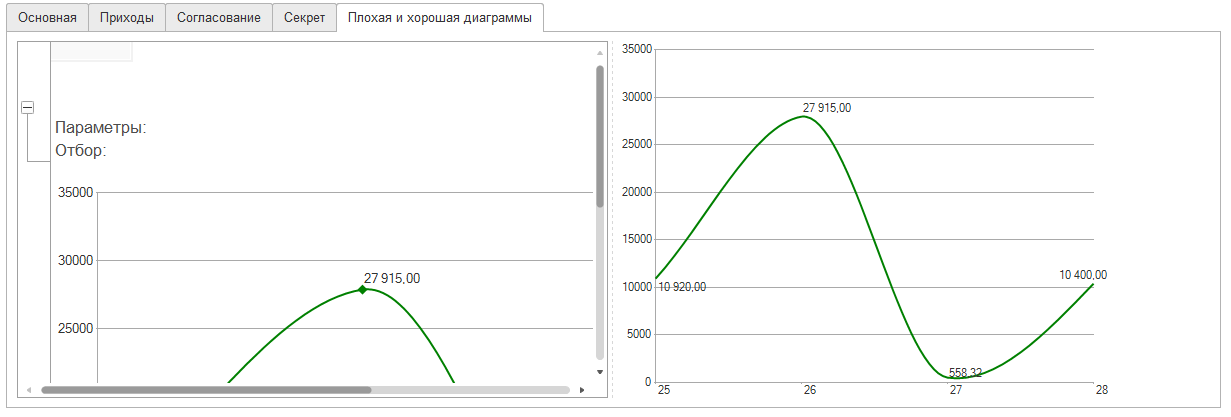
Разумеется, если вам сильно хочется, можно нарисовать и страшную диаграмму, в табличном документе. Только для этого нужен элемент рабочего стола типа «Отчет» - он выведет все, что хотите.
Динамический список
Тут все очень просто. Основа любого динамического списка – запрос. Он бывает либо произвольным, либо – по основной таблице, типа «Документ.ПоступлениеТоваровУслуг».
Чтобы не заморачиваться с настройкой, у нас запрос всегда произвольный, но основная таблица определяется, автоматически.
Настройка элемента рабочего стола типа «Динамический список» выглядит так:
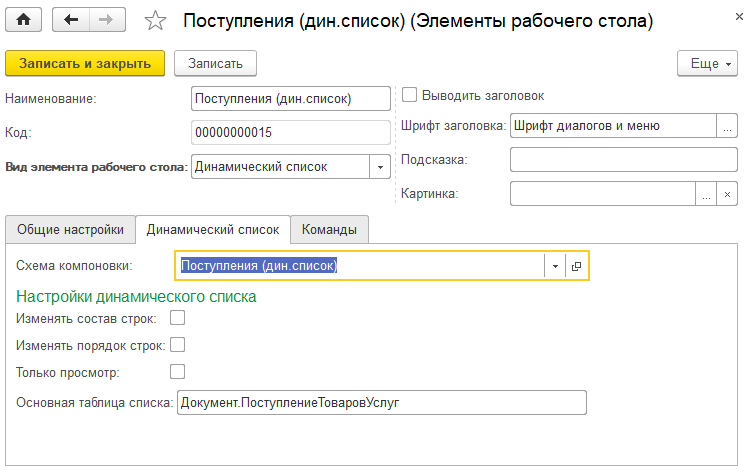
Вы выбираете схему компоновки, в которой написан запрос динамического списка, определяете поведение элемента формы (изменять состав и порядок строк, только просмотр), и все.
В элемент формы попадут все поля, которые есть в выбранных полях схемы компоновки. Рекомендуем использовать плоские динамические списки, без группировок.
Условное оформление, отборы, сортировка так же берутся из схемы компоновки.
Выглядеть в итоге будет примерно так:

Кнопка
Кнопка есть кнопка. Просто указываете команду (из справочника «флКоманды»), которую должна выполнять кнопка, и все. Можно переопределить заголовок, и управлять размерами кнопки.
Набор ссылок
Это самый непонятный большинству программистов вид элемента, и при этом – самый полезный, на наш взгляд.
Набор ссылок – это вывод результата запроса в виде гиперссылок. Обычно мы, программисты, показываем пользователю ссылки на документы, справочники и т.д. либо в виде списка (динамического, или обычного), либо в виде отчета.
Но бывают ситуации, когда надо вывести ограниченный набор ссылок. Например, только заказы поставщикам, по которым вышел срок поставки. Или договоры, которые текущий пользователь должен согласовать. Или счета на оплату, которые пользователь должен проверить, и т.д.
Заставлять пользователя формировать отчет ради того, чтобы увидеть несколько документов – слишком затратно. Особенно, если отчет надо еще и настраивать – фильтровать по ответственному, например. Разрабатывать отдельную форму, или закладку на форме, для вывода этих документов – тоже так себе идея. И отчет, и форма, и закладка – это объекты метаданных, которые надо будет сопровождать, учитывать при обновлениях и т.д. А если речь о типовых объектах? Хотя, обычно речь именно о них. Менять типовую форму – это ж кошмар, который наступит при очередном обновлении.
Вот для таких задачи и служит набор ссылок. Его девиз – «показывай данные», т.е. конкретные ссылки, а не навигацию к формам, где эти ссылки надо будет искать.
Выглядеть набор ссылок на рабочем столе будет примерно так:

На картинке выведены последние пять документов «Реализация товаров и услуг». Но, как вы можете заметить, отображаются не просто строковые представления ссылок – оставлены только номер и дата, но добавлена сумма.
Настройка набора ссылок очень простая. Нужно разработать схему компоновки, и указать ее в элементе рабочего стола.
Требования к схеме компоновки:
- Настройка должна быть плоской (одна группировка «Детальные записи», поля – в выбранных полях);
- Обязательно должно быть поле «Ссылка».
Собственно, этого достаточно для того, чтобы набор ссылок нарисовался. Если хочется переопределить представление ссылки, то надо добавить поле «Представление», и написать в нем то, что сочтете нужным.
Я обычно делаю вычисляемое поле в схеме компоновки – так легче вычислять представление, и в запрос лезть не надо. Например, представление на приведенной выше картинке вычисляется так:
"№ " + Номер + " от " + Формат(Дата, "ДФ=dd.MM.yyyy") + " г., " + Формат(СуммаДокумента, "ЧЦ=15; ЧДЦ=2") + " р."
Поля «Номер», «Дата» и «СуммаДокумента» возвращает запрос. Когда в результате запроса присутствует поле «Представление», его значение автоматически выводится в заголовке гиперссылки.
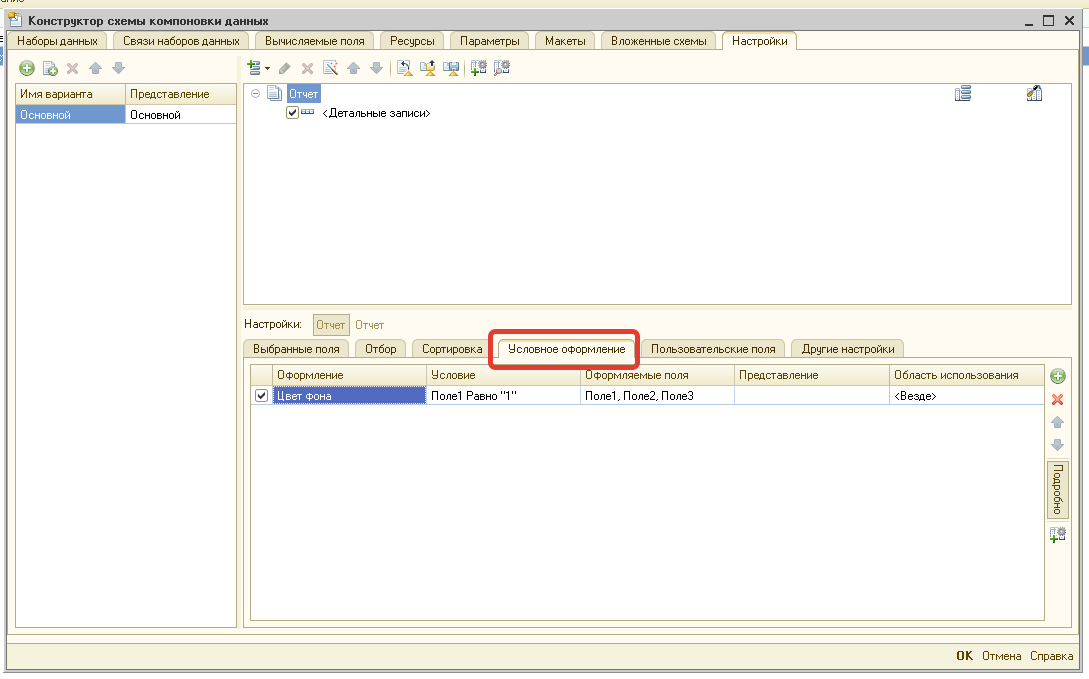
Управление цветом ссылки осуществляется чуть сложнее. Мы попозже добавим парсер условного оформления, он уже есть в другом решении, но пока – по-старинке.
Цвет задается через пользовательские поля. Нужно добавить пользовательское поле типа «Выбор», в нем задать условия выбора цвета в зависимости от данных, а в значение поля записать цвет в виде строки, из коллекции web-цветов. Например, «ЗеленыйЛес», «Красный» и т.д. (цвет в платформе, увы, не является полноценным объектом, и использовать его в качестве данных нельзя).
Пользовательское поле надо добавить в выбранные поля схемы компоновки. И, наконец, в элементе рабочего стола, на закладке «Пользовательские поля», нажать кнопку «Обновить пользовательские поля» - при этом в таб.части появится ваше поле – и сказать в колонке «Тип поля», что это – цвет.
Есть вариант попроще – достаточно добавить вычисляемое поле с именем «Цвет», в котором по тем же правилам должно быть строковое представление цвета, и вытащить его в выбранные поля. Такой способ проще, если условие выбора цвета – не сложное, и без привязки к ссылкам (например, надо просто выделить отрицательные суммы красным).
Потом добавим парсер УО, будет интереснее. Хотя, обычно цветами сильно не играются, используя три стандартных светофорных.
Команды набора ссылок
По умолчанию, при нажатии на ссылку, будет открываться объект. Но есть возможность навесить произвольное количество команд, которые можно выполнить после нажатия на ссылку.
Команды задаются в элементе рабочего стола, на закладке «Команды». Просто перечисляете элементы справочника «флКоманды», которые должны исполняться, и все. Если команд нет, то ссылка просто откроется. Если команда одна, то она молча выполнится. Если команд больше одной, то при нажатии на ссылку откроется форма выбора команды:
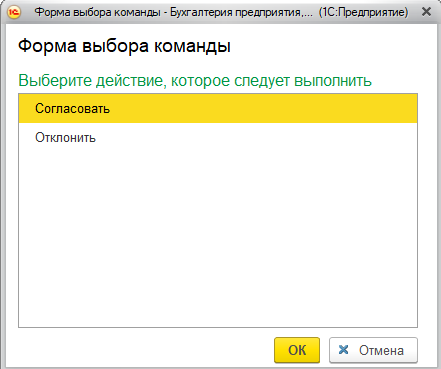
И вот тут вступают в действие «ВнешниеПараметры» команды. В эту структуру передаются все поля, относящиеся к ссылке, на которую нажал пользователь.
Например, на моей картинке с реализациями выведена только ссылка. Но результат запроса возвращает и сумму, и номер, и дату, и контрагента. Вот все эти поля и упаковываются в структуру, и передаются в команду, и их можно использовать в коде. Например, написать так:
Если ВнешниеПараметры.Контрагент = ПараметрыКоманды.ПлохойКонтрагент Тогда Сообщить(«Нечего вам этот документ смотреть!»); КонецЕсли;
Так же, отмечу, что в наборе ссылок можно ограничивать количество этих самых ссылок – достаточно указать число в элементе рабочего стола. Понятно, что можно просто в запросе написать ПЕРВЫЕ 5, но тогда ограничение закладывается в запрос, а при внешнем ограничении можно использовать один запрос для разных целей. Где-то вывести 5 ссылок, где-то – 500.
Ну и платформа иногда странно себя ведет при одновременном использовании конструкций «ПЕРВЫЕ», «УПОРЯДОЧИТЬ ПО» и «ПОМЕСТИТЬ». Просто не получается вывести пять последних документов, если предварительно нужны пара пакетов, которые готовят вспомогательные данные.
Дерево
Дерево работает очень просто: пишете схему компоновки, в которой есть группировка, указываете ее в элементе рабочего стола, и рисуется дерево, вроде этого:
Дерево можно воспринимать, как альтернативу дин.спискам, если очень хочется вывести иерархию. Сами знаете, как дин.списки к ней относятся.
С другой стороны, дерево – это уже настоящий элемент управления, с помощью которого можно строить алгоритмы обработки данных. Для этих целей к дереву можно подключать команды. В отличие от набора ссылок, команды реагируют не на открытие, а прям рисуются на командной панели дерева (см. рисунок выше).
В контекст команды передается элемент формы. Соответственно, вы можете получить и текущую строку, и все выделенные строки, и все содержащиеся в них данные. Вплоть до того, что управлять самим деревом – например, удалять из него строки.
Есть возможность вывести пометку – у строк дерева появится флажок. Полезно при написании алгоритмов, т.к. значения пометок будут доступны из команд.
Методической практики именно по деревьям пока немного, т.к. этот вид элемента появился последним, и не так давно. Возможно, функционал обогатится вашей практикой?
Связи элементов
Динамические списки можно связать с отчетами и диаграммами. В этом случае схема компоновки, лежащая в основе отчета или диаграммы, может быть параметризируемой.
Работает просто. Человек нажимает на любую строку динамического списка, и связанный отчет или диаграмма перерисовываются, с учетом этой строки. Например, так можно выводить краткий состав документа в виде отчета:
На картинке отчет справа показывает товары и услуги поступления, на котором стоит курсор в динамическом списке.
Настройка связей осуществляется в справочнике «Рабочие столы», на соответствующей закладке:
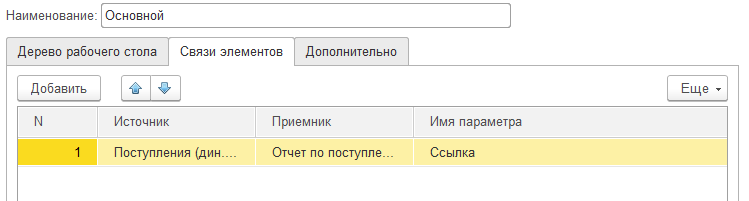
Источник связи – динамический список, приемник – отчет или диаграмма, имя параметра – то, что будет передано в схему компоновки. Разумеется, у дин.списка должна быть колонка с таким же именем. Обычно это «Ссылка».
Таким способом можно, например, строить интерактивные дашборды. Не вываливать кучу диаграмм на один экран, а сделать дин.список с показателями, и при нажатии перерисовывать диаграмму. Может получиться что-то вроде этого:
Фиксация данных – это инструмент для автоматического отслеживания изменений в данных.
Проблема
Во всех, или почти во всех конфигурациях на платформе 1С есть механизмы запрета изменений задним числом. И во всех, или почти во всех реальных внедрениях они успешно игнорируются пользователями.
Потребность в изменении документов прошлого периода возникает регулярно. Меняться может не только сам документ, сколько состояние регистров – например, при перепроведении документов за месяц, квартал или год. Вроде бы, в документах изменений нет, а оборотка, или регистры себестоимости изменились.
Неприятность в том, что такие изменения очень трудно поймать. Изменение границы запрета изменений данных если и фиксируется, то только в журнале регистрации, но без конкретных данных – не удастся выяснить, какая именно граница была изменена. Некто, например заместитель главного бухгалтера, или добросердечный программист, сдвигает границу назад, человек меняет или просто перепроводит документ, и все живут надеждой, что ничего не изменилось.
Реально проконтролировать, изменилось что-то или нет, практически невозможно. В жизни используются три способа.
Первый – ручная, или зрительная проверка сразу после изменения. Сформировали оборотку, перепровели расчет себестоимости, открыли рядом вторую оборотку, и сравниваем ее с первой. Сначала – общие обороты, потом по счетам, потом по субконто. Можно выгрузить в эксель, и там устроить построчное сравнение.
Второй – сравнение с бэкапом, когда есть подозрение, что данные прошлого периода кто-то поменял. Поднимаем бэкап, формируем отчеты за подозрительный период, сравниваем – теми же способами: руками, глазами и экселем. Иногда выручают самописанные инструменты, которые умеют сравнивать данные из двух баз, соединяясь, например, через COM.
Третий – распечатывание оборотки. Этот способ придуман бухгалтерами от безысходности – печатают, ставят дату, иногда – подпись. Как только возникло подозрение, что оборотка поменялась – смотрим в программе, сравниваем с распечаткой. Если расхождения есть, идем во второй способ – поднимаем бэкап, и погнали в эксель.
На первый взгляд кажется, что может помочь инструмент вроде версионирования, который фиксирует изменение первичных данных – документов, например. Теоретически, можно попробовать обойтись даже стандартным платформенным журналом регистрации, но на реальных базах работать с ним в режиме поиска и выборки довольно затруднительно.
Версионирование иногда помогает найти расхождения, но не обнаружить само их наличие. Когда главбух посмотрел на распечатанную оборотку, и увидел, что цифры уплыли, то можно глянуть в версионирование – отфильтровать его по периоду изменений (с момента распечатки) и дате документа (попадающей в измененный период), и что-то увидеть. Если изменение было разовое, т.е. провели один-два документа, то проблему обнаружить удастся.
Если же шло закрытие квартала, и бухгалтерия перепроводила все документы, например по ТМЦ, то версионирование не поможет – оно честно скажет, что изменено несколько тысяч документов, причем реквизиты и таб.части все на месте, их просто перепровели.
Проблема понятна – версионирование фиксирует изменение первичных данных, а не регистров. А нам, в данной задаче, нужно именно изменение регистров, и только потом – первичные данные. Изменение документа не всегда влечет за собой расхождения в регистрах – например, могли поменять ничего не значащий реквизит, вроде комментария, но регистр все равно поехал.
Еще один источник проблем – изменение настроек и алгоритмов с течением времени. Сегодня документ при проведении ведет себя так, а завтра разработчики 1С или собственные программисты внесли изменения в код, и документ стал вести себя иначе. Вчера он делал одни движения по регистрам, завтра сделает другие.
Или, например, настройки расчета себестоимости. Конечно, разработчики предусмотрели ведение нескольких настроек закрытия месяца в виде справочника, с указанием периода действия, но на практике, обычно, люди не заморачиваются, и вносят изменения в существующую настройку. Вчера статья затрат распределялась на два цеха, сегодня – на один, и только на одну номенклатурную группу. Перепровели старый расчет себестоимости – цифры уплыли.
Копирование регистров
Самое простое решение, в лоб – это копирование важных регистров. Либо внутри текущей базы, либо в отдельной. Просто создаем точную копию регистра, и время от времени перекачиваем туда данные исходника. Ну и периодически сравниваем.
Проблема такого подхода очевидна – нужно хранить слишком большой объем данных. Каждый большой регистр – это плюс несколько гигабайт к размеру базы, дополнительный пересчет остатков, хранение виртуальных таблиц, снижение производительности.
Именно большой размер копий регистров в свое время оттолкнул нас от такого подхода, хотя задачу отслеживания изменений решать удавалось, хоть и с трудом.
Другой вариант – хранить не весь регистр, а, например, только остатки. Вариант так себе, потому что одинаковые остатки на конец периода не гарантируют того, что внутри периода изменений нет. Но идея, сама по себе, неплоха – хранить не весь регистр, а некий уменьшенный слепок.
Скомбинировав оба варианта, мы нашли приемлемое решение – хранить свернутую копию регистра.
Свернутая копия регистра
Рассмотрим решение задачи отслеживания изменений на примере. Допустим, мы работаем с регистром накопления «Продажи». В нем есть организация, контрагент, договор, номенклатура, характеристика и т.д. И у нас есть система версионирования, которая знает – кто, когда и какой документ изменил. И нам надо решить задачу отслеживания изменений.
Нам нужно решить задачу балансировки – сколько информации нам нужно знать о регистре, чтобы с помощью версионирования найти, какой документ произвел изменения.
Мы создаем некий регистр накопления, в котором пока нет никаких измерений. На данном этапе он бесполезен.
Первое, что надо знать – в каком периоде произошли изменения. Периодом может быть день, неделя, месяц и т.д., в зависимости от интенсивности наполнения основного регистра («Продажи»). Допустим, мы решили, что нам достаточно знать месяц, в котором произошли изменения.
Делаем копирование исходного регистра, и тащим из него одно поле – период. Но не в чистом виде (дата со временем), а приводим дату к началу месяца. Так у нас получится одна запись регистра-копии на каждый месяц продаж.
Уже неплохо, потому что объем данных в копии будет очень невелик. Теперь, чтобы определить, были ли изменения, нам достаточно сравнить обороты регистра и его копии в разрезе периодов, свернутых до месяца. Если изменения были, сравнение покажет – например, изменен март 2018 г.
Дальше нам надо идти в версионирование, и по имеющейся у нас информации наложить правильный фильтр – нам нужны документы за март 2018 года. Их может быть немного, тогда задача будет решена.
А может быть много, тогда фильтр надо делать более точным. Добавляем, например, в нашу копию поле «Организация», и получаем более точные данные – изменен март 2018 г. по организации «ООО Рога и Копыта». Снова идем в версионирование, и уточненный фильтр показывает нам чуть меньше документов.
Если все равно получается многовато записей, добавляем еще поле в копию. Например, контрагента. Если у нас, допустим, две организации и, в среднем, тридцать разных покупателей в месяц, то количество записей в копии регистра составит, в среднем, 60 в месяц. Не так уж много, вроде бы.
Теперь, глядя на версионирование, мы получаем выборку еще меньшего размера, и найти измененный документ будет еще проще.
Тут очень важен момент, когда остановиться. В принципе, в копии можно хранить и документ-регистратор, и заказ покупателя, и номенклатуру с характеристикой. Тогда и в версионирование ходить не придется – все данные об изменениях будут в нашей копии. Только объем регистра-копии станет равным оригиналу, и толку от свертки не будет.
Принцип, надеюсь, понятен. Храним свернутую копию регистра, с необходимой точностью. Точность определяется возможностями версионирования, доступными в конкретной конфигурации и базе данных. Теперь переходим к решению «Фиксация данных».
Фиксация данных
Фиксация данных – это инструмент, реализующий описанную выше методику настройки, создания и хранения свернутых копий регистров, а также автоматического отслеживания расхождений.
Фиксировать можно произвольное количество регистров. Вообще, не только регистров – любых данных, которые можно выбрать запросом из базы. Но основное назначение, конечно, регистры.
Разделение фиксируемых данных выполняет справочник «Настройки фиксации данных».
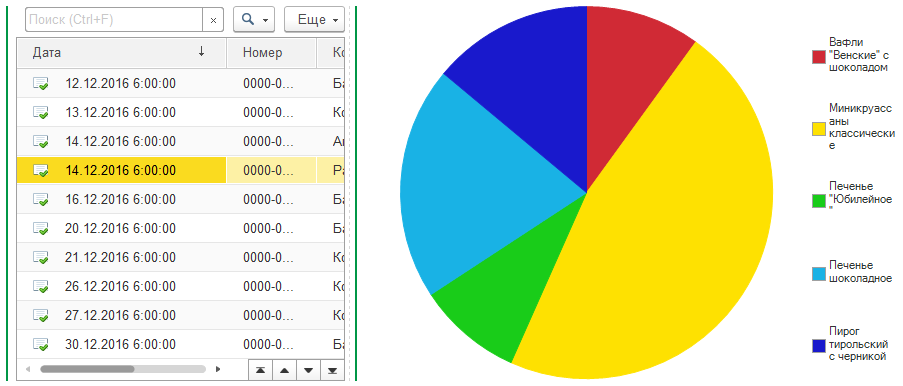
Настройки фиксации данных
Настройка – это основной разрез фиксации данных. Например, вот так выглядит настройка для регистра «Продажи»:
Дата начала определяет, с какой даты нужно фиксировать данные. На скриншоте выбрано начало 2010 года – это значит, что продажи 2009 года фиксироваться не будут. Периодичность фиксации указывает, как данные будут сворачиваться по периоду. Чем шире периодичность, тем меньше данных будет в регистре, но тем больше выборка документов в версионировании. Отставание фиксации – это размер текущего периода, в котором нас не интересует изменение данных. Например, текущий месяц – зачем его фиксировать? Он ведь каждый день меняется по несколько раз.
Данные, которые будут фиксироваться, выбираются с помощью схемы компоновки. Например, для регистра «Продажи» мы делаем запрос очень простым:

Такой запрос означает, что мы будем знать об изменениях количества и суммы, в разрезе месяца и контрагента.
Требований к схеме компоновки немного:
- Данные должны возвращаться в виде плоской таблицы, без группировок и итогов;
- Запрос должен иметь параметры «НачалоПериода» и «КонецПериода».
Наша схема для регистра «Продажи» настроена так:
Остальные настройки схемы, как и запрос – на ваше усмотрение. Можно соединять несколько регистров в запросе, можно фильтровать по значениям измерений, если вам нужны только определенные записи для фиксации, и т.д.
После написания запроса и настройки схемы компоновки, нужно указать в настройке, какие поля составляют ключ фиксации, а какие – идут в ресурсы.
Хранение данных
Значительное внимание в «Фиксации данных» уделено оптимизации хранения этих самых данных.
Все зафиксированные данные лежат в одном регистре накопления, с достаточно лаконичными метаданными:
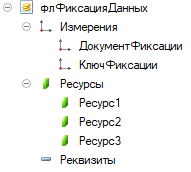
По списку ресурсов видно, что в рамках одной настройки фиксировать можно до трех цифр. Соответственно, отслеживать изменения можно по этим цифрам. В нашем примере использованы два ресурса – количество и стоимость.
Измерение «Документ фиксации» хранит в себе ссылку на служебный документ, о котором мы поговорим позже. Пока посмотрим внимательнее на измерение «КлючФиксации». Он имеет тип справочник «КлючиФиксацииДанных».
Смысл этого справочника очень прост – он позволяет компактно хранить данные об аналитиках, не отягощая регистр накопления множеством измерений. Если данные фиксируются в разрезе одних контрагентов, ключ будет содержать только ссылку на контрагента. Если добавить организацию, ключ будет на пару контрагент + организация. Тут ничего особо нового нет – так же хранятся, например, ключи аналитики в РАУЗ УПП.
Работать с ключами напрямую вам не придется – они создаются автоматически, при выполнении фиксации. Пользователь видит лишь форму ключа, когда хочет найти расхождение:

Что именно попадает в ключ, решает настройщик в справочнике «Настройки фиксации данных»:
Запрос может возвращать много полей, а в ключ попадут только нужные, указанные в настройке.
Типы аналитик ключа
Было бы неразумно с нашей стороны поставить тип «Любая ссылка» для аналитик ключа, т.к. любое изменение метаданных конфигурации приводило бы к долгой реструктуризации. Поэтому мы сделали просто: доступные типы аналитик регулируются планом видов характеристик «флТипыКлючейФиксацииДанных».
После внедрения в конфигурацию просто зайдите в этот план видов характеристик, и настройте тип значения характеристик так, как вам нужно – добавьте те типы, которые вам нужны для составления ключей. Состав типов вы можете расширить в любой момент – правда, каждое изменение может вызывать длительную реструктуризацию.
Конечно, правильнее было бы использовать не план видов характеристик, а определяемые типы, но они не работают в некоторых режимах совместимости (например, для УПП).
Документ «Фиксация данных»
Это служебный документ, который выполняет три функции:
- Фиксирует данные;
- Фиксирует расхождения;
- Акцептует расхождения.
Работать с ним вручную придется редко, только при выполнении акцепта расхождений (см. ниже). Вообще, выглядит он вот так:
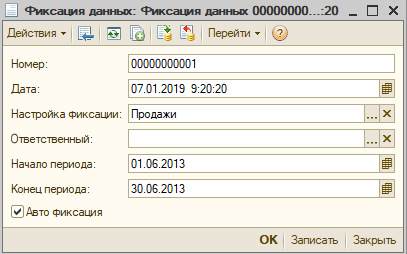
Значимых реквизитов три: настройка фиксации, начало и конец периода фиксации.
Алгоритм работы
Алгоритм работы достаточно прост:
- Создаем настройку фиксации, пишем запрос и схему компоновки, определяем параметры фиксации;
- Регламентное задание «Фиксация данных» выполняет, собственно, фиксацию данных – создает на каждый период документ «Фиксация данных», который пишет свернутые данные в наш регистр накопления. Количество создаваемых документов равно количеству периодов. Например, если выбрана периодичность месяц, и фиксируются данные за 3 года, то получится 36 документов.
- То же регламентное задание «Фиксация данных» периодически выполняется и ищет новые периоды, для которых еще не выполнена фиксация. Прошел еще один месяц – добавит один новый документ. Важно: фиксация периода выполняется только один раз, т.е. заново переформировывать документы регл.задание не будет.
- Регламентное задание «Проверка фиксации данных» выполняет главную функцию – контролирует, соответствуют ли текущие данные зафискированным. Работает просто – выполняет тот же запрос, за тот же период, и сверяет два результата. Если изменений нет, идет дальше. Если изменения есть, фиксирует расхождения в отдельном регистре накопления «Расхождения фиксации данных»:
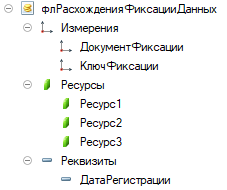
Как видите, этот регистр почти не отличается от предыдущего, разница только в наличии реквизита «Дата регистрации» - там запоминается дата обнаружения расхождения. В регистр же просто пишутся разница ресурсов и ключи, по которым эта разница обнаружена:

Например, на этом скриншоте видно, что изменилось значение ресурса 1 (это у нас количество) и ресурса 2 (это сумма) по ключу «Другой некий контрагент». Щелкнув по ключу, мы узнаем его состав – в нашем случае, это контрагент. Щелкнув по документу, мы узнаем период, в котором произошли изменения – в нашем случае это сентябрь 2017 года. Ну и дата регистрации нам говорит, что изменения зафиксированы 07.01.2019 г. в 9:24.
Остается сходить в версионирование, отфильтровать изменения по дате (07.01.2019), типам документов (реализации, корректировки реализаций), дате этих документов (сентябрь 2017 г.) и контрагенту («Другой некий контрагент»). Останется выборка из нескольких (а скорее - одного) документов, с указанием пользователя, внесшего изменения.
- Регламентное задание «Проверка фиксации данных» будет периодически заходить и перепроверять наличие расхождений.
Если кто-то устранит обнаруженное ранее расхождение, т.е. текущие данные снова станут равны зафиксированным, запись из регистра «Расхождения фиксации данных» просто исчезнет.
Если кто-то усугубит ситуацию, добавив в тот же период еще немного расхождений, данные в регистре «Расхождения фиксации данных» просто обновятся.
- Если расхождения признаны законными, и исправлять их никто уже не будет, то необходимо акцептовать эти изменения. Делается это просто – открываем из регистра документ фиксации, и проводим его вручную.
При этом выполняются две операции. Во-первых, происходит повторная фиксация периода – новые данные, с учетом расхождений, становятся эталоном. Во-вторых, стираются записи о расхождениях. Все, больше расхождений нет.
Отслеживание изменений
Все отслеживание изменений сводится к одному простому действию – контролю наличия записей в регистре накопления «Расхождение фиксации данных». Нормальное состояние этого регистра – когда он пустой.
Как только в нем появились данные – кто-то что-то испортил. Что с этим делать – написано выше. Важно только не пускать этот процесс на самотек, а решать судьбу каждого расхождения – либо исправлять данные, либо акцептовать расхождения.
Для автоматизации контроля за наличием расхождений рекомендуем использовать «Автозадачи» - тогда заходить каждый день в регистр не придется. Как только появится расхождение, вы об этом сразу узнаете. А когда расхождение будет устранено, тем или иным способом, автозадача закроется.
Простой и удобный инструмент для проверки данных (справочников, документов) сразу в момент записи. Позволяет значительно повысить качество информации, вводимой в любую систему на платформе 1С:Предприятие 8.2-8.3. Прост в освоении и использовании, оптимизирован по быстродействию.
Качество данных, попадающих в учетную систему на платформе 1С - один из важных факторов эффективного использования системы. Как обеспечить это качество за разумные средства?
Отчасти эту задачу решает сама система. Например, Управление производственным предприятием не позволит вам купить услугу на склад - спасибо ему за это. Но легко позволит отнести товар, например, на бухгалтерский счет 69.06.3 "Взносы в ФОМС" - как и на любой другой балансовый счет.
А дело тут вот в чем.
Во-первых, большинство программ 1С - очень доверчивые. И чем больше и сложнее программа, тем больше она доверяет пользователю.
Во-вторых, почти все внутренние проверки конфигураций предназначены для грубой, черновой проверки данных, и правильность анализируется с точки зрения разработчика, а не с точки зрения методиста или заведующего учетом предприятия-клиента. Цель таких проверок, в основном - чтобы программа работала, а не чтобы учет корректный был.
В-третьих, в конфигурациях нет единого механизма контроля качества данных. Есть небольшие, локальные "проверяльщики" с непохожими друг на друга механизмами настройки.
Работа пользователей реального предприятия в учетной системе требует принципиально иного подхода к контролю качества данных. Одна из главных особенностей такого контроля - он должен работать к данным системы.
Например:
- Если мы продаем со счета 10.01, то счет доходов должен быть 91.01, иначе - 90.01;
- В требовании-накладной на основное производство, если номенклатура из папки "Металл", то статья затрат должна быть "Металлы основного производства";
- В заказе покупателя обязательно должен быть указан грузополучатель и его адрес;
- Если в плане ДДС указано подразделение "Отдел продаж", то расход денег может быть только наличный.
- И т.д.
Если поручить программисту реализовать такие проверки, то он сразу заскучает. И будет писать код, за который потом самому будет стыдно - искать данные по коду или наименованию, добавлять константы или какие-нибудь регистры для хранения этих самых "металлов" и "отделов продаж".
В большинстве случаев остаются только старые средства офлайн-проверки - консоль отчетов, групповая обработка справочников и документов, небольшие специализированные отчеты, заточенные под конкретные ошибки. Решение тоже достаточно грустное, хотя и выхода обычно нет.
Но теперь есть повод для радости - появилось решение Проверка данных.
Если кратко, то это настраиваемая в пользовательском режиме проверка документов и справочников.
Основные возможности и особенности:
- Проверять можно любой справочник или документ, который есть в вашей программе на платформе 1С;
- Работает в любой конфигурации на платформе 1С, начиная с версии 8.2.16;
- Проверка выполняется при записи. Если проверка не прошла - записать не даст;
- Настраивать - не сложнее, чем делать отбор в отчетах;
- При желании и соответствующих навыках, для реализации проверки можно писать произвольный запрос через СКД;
- Можно на время отключить проверки для определенных пользователей. Например, для группового перепроведения документов;
- Можно массово проверить старые справочники и документы по новым проверкам (а не только при записи);
- Замер производительности - оценит, насколько увеличилось время записи/проведения при включении проверки;
- Разные варианты исполнения проверок с точки зрения производительности.
В итоге, с помощью Проверки данных вы создадите обучаемую систему контроля для своей учетной системы.
Вы сами научите ее, что правильно, а что нет, как нужно делать а как - не стоит. Вам понравится.
Производительность
При разработке продукта особое внимание мы уделили производительности. Искали и пробовали различные варианты, общались с партнерами и разработчиками 1С, проводили тесты на реальном предприятии в течение нескольких месяцев.
В итоге мы получили результаты, которыми гордимся.
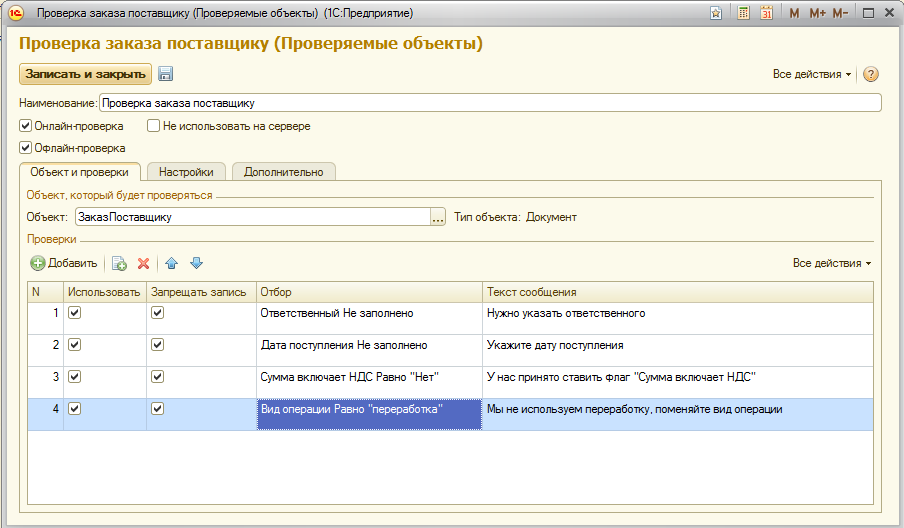
Первое и главное - мы научили систему делать несколько проверок одним запросом. Запрос - это самая "тяжелая" часть проверки, когда идет обращение к базе данных.
Например, на картинке, приведенной ниже, показано, что при записи заказа поставщику будет выполнено 4 проверки - и все одним запросом.
4 проверки одним запросом
Второе, не менее важное - мы реализовали несколько вариантов исполнения проверки.
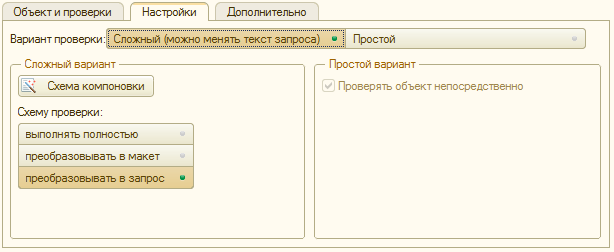
Наличие нескольких режимов - результат нашей борьбы за производительность. Универсального способа сделать проверку быстро и красиво, увы, платформа нам не дает. Поэтому мы использовали все возможности, лазейки, обходные пути и нетривиальные решения, чтобы не нагружать вашу систему.
Простой вариант
В этом варианте запрос и все его параметры заполняются автоматически. Вы лишь настраиваете отборы и пишете тексты сообщений - также, как это делается в типовых отчетах.
Но и в простом варианте нашлось место оптимизации - если установить флаг "Проверять объект непосредственно", то обращения к базе данных не будет происходить вообще. Это самый оптимальный способ исполнения, для несложных проверок - но таких, по нашему опыту порядка 30 %.
У этого, первого способа исполнения, есть особенность: если в проверке использовать вложенные поля, то производительность начинает снижаться. Так происходит потому, что вложенное поле - это т.н. "разыменование ссылки", т.е. неявный запрос к базе данных. Наша система эту особенность знает, и честно вас предупредит об использовании вложенных полей - выдаст рекомендацию поменять вариант.
Если флаг "Проверять объект непосредственно" снять, то получится второй способ исполнения - выполнение запроса. Это самый распространенный режим исполнения, в котором работают примерно 40 % проверок. Его производительность несколько ниже, чем у первого способа.
Сложный вариант
Сложный вариант отличается тем, что становится доступно редактирование схемы компоновки, которая исполняется при проверке. Такой вариант используется, когда для проверки справочника/документа нужно знать нечто большее, чем его реквизиты. Например, остатки или какие-либо настройки. Этот вариант используется, как правило, только программистами, т.к. требует специализированных знаний.
Сложный вариант имеет три способа исполнения.
Первый способ - самый "тяжелый" с точки зрения производительности, т.к. при проверке будет исполняться схема целиком. На практике применяется редко, когда нужна архисложная проверка - не более 2 %.
Второй способ - преобразование схемы в макет компоновки. Формирование макета компоновки - самый длинный этап программного выполнения схемы. Но на это обращают внимание не все разработчики - и мы в числе тех, кто не сразу заметил, что макет компоновки можно создать заранее, а потом просто выполнять. И что бы вы думали - время выполнения готового макета в 4 раза меньше, чем выполнение схемы целиком. Мы не могли упустить такую возможность для оптимизации, и этот способ исполнения нашел отражение в продукте.
Подготовленный заранее макет почти ничем не отличается по функциональности от схемы - работают вычисляемые поля, внешние функции, функции вычисления параметров... Но ложка дегтя все-таки есть: в макете нельзя использовать стандартные периоды (Начало сегодняшнего дня, Начало предыдущего месяца и т.д.). При компоновке макета эти периоды вычисляются, и запоминаются уже конкретные даты. На практике такой способ исполнения применяется, но с учетом ограничения - примерно 5 % проверок.
Третий способ - преобразование схемы в запрос. В таком режиме из схемы компоновки "добываются" только текст запроса и значения параметров - и этого, как правило, достаточно. Отдельно отмечу, что текст запроса берется не тот, который написал разработчик, а тот, который формирует сама схема при компоновке. В него, к примеру, включаются все сделанные в схеме отборы (в виде условий).
Не используются вычисляемые поля, внешние функции, но это не страшно - практика показала, что для целей проверки данных эти возможности нужны крайне редко.
Практика показала, что такой режим используется примерно в 20-25 % случаев.
Для контроля производительности, оценки и выбора подходящего режима мы разработали отдельное средство.
Использование реквизитов проверяемого объекта в тексте сообщений
Когда объект - документ или справочник - не проходит проверку, выдается сообщение. Текст этого сообщения пишет разработчик проверки. Раньше он мог написать только буквы, которые, один к одному, выводятся пользователю.
Теперь он может написать текст сообщения, используя реквизиты объекта. Например, "Вы зря поставили номенклатуре "Вал распределительный" единицу измерения "кг". Так не бывает. Поставьте "шт" и не отвлекайте серьезных людей от работы".
Если проверка сложная, с использованием схем компоновки, то в текст сообщения можно вставлять любые поля, которые вернул запрос. Например, "Не получится отгрузить 10 шт номенклатуры "Валенки", потому что на складе "Основной" осталось лишь 5 шт. И вообще, уважаемый господин Федоров (администратор), больно часто вы на ошибку натыкаетесь. Смотрите сначала отчет с остатками, потом вбивайте документы".
Замер производительности
Зная о любви программистов к экспериментам - мы и сами такие - включили в продукт средство измерения производительности проверок.
Суть его проста. Вы указываете конкретный документ или элемент справочника, который хотите проверить, система его записывает и измеряет два показателя:
-
Сколько всего ушло времени на запись;
-
Сколько ушло времени конкретно на проверки.
Результат замера - насколько увеличилось время записи из-за применения проверки:
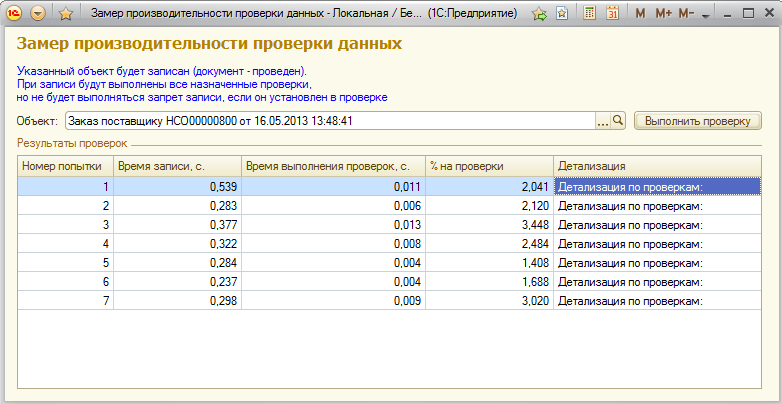
На скриншоте, например, видно, что проведение заказа поставщику увеличилось на 1.4 - 3.5 %.
Во многих видах бизнеса, особенно в ИТ, ключевое значение имеют компетенции сотрудников. Избитая, знакомая всем фраза. На сайтах большинства компаний, где присутствует раздел миссии или ценностей, написано что-нибудь вроде «наше главное богатство – это наши сотрудники».
Фраза хоть и избитая, но я с ней согласен. У нас самих бизнес именно такой. Его успехи и провали полностью зависят от нас, его сотрудников. И не важно, о каких именно видах деятельности идет речь – продажах, маркетинге, разработке, сопровождении, отладке, публикациях, переговорах – все это делают люди, т.е. мы.
И вот что получается. Успех бизнеса зависит от компетенций сотрудников. Мы, как и вы, пытаемся управлять бизнесом. Считаем деньги, выработку, управляем задачами, что-то пытаемся делать с проектами, налоги вычисляем… Управляем всем, чем можно, кроме чего? Компетенций.
То есть самым главным-то мы не управляем.
Проблемы с компетенциями
Первое. Мы только примерно представляем себе, о каких именно компетенциях идет речь. Конечно, если бизнес построен на выполнении одного-двух видов работ, то управление не требуется. А если видов работ – десятки, и сотрудников – сотни?
Какие компетенции у нас уже есть? Каких не хватает? На какие мы даже замахиваться не смеем? А нашим клиентам какие компетенции нужны? Продукт новый мы можем сделать, имея только наши компетенции? А может, нам не хватает одной-двух компетенций, чтобы выйти на другой рынок?
Второе. Мы плохо себе представляем развитость компетенций. Примерно, крупными мазками, мы понимаем: Коля – спец по реакту, а Вася хорошо пишет продающие тексты. А Гена? А ангуляром кто владеет? А по «Управлению холдингом» кто что умеет? Есть ли у нас компетенции по ERP? А то все ее продают, а мы в стороне. Вроде, Серёга что-то знает по ERP… Но что именно, и насколько качественно?
Третье. Мы привыкли измерять получение компетенций прохождением курсов и наличием сертификатов. Хотя понимаем, что реальные компетенции рождаются только практической работой. Но, т.к. развитие компетенций не измеряем, приходится довольствоваться суррогатом – дипломами, курсами и сертификатами. Бесспорно, определенное влияние на компетенции получение бумажек оказывает, но это лишь стартовый импульс, за которым должно следовать применение теоретических знаний на практике. А в реальности что происходит с этим импульсом?
Четвертое. Компетенции не живут в голове вечно. Сегодня решил задачу по новой для себя технологии, пару месяцев к ней не возвращался, потом сел – ничего не помнишь. Какие-то остатки знаний присутствуют, конечно, но «взять и сделать» уже не получится – все равно придется разбираться. Да что там говорить, даже в своем коде разобраться не всегда быстро получается.
С другой стороны, если компетенция используется регулярно, то доходит до автоматизма и перестает быть проблемой. Получается, нужно эту регулярность как-то измерять и поддерживать, чтобы не терять компетенции.
Пятое. Бизнес часто зависит от компетенций. Иногда – очень сильно.
Например, если есть сотрудник с уникальными навыками. Если он уйдет, может целое направление бизнеса закрыться, хотя бы на время.
Компетенции, зачастую, формируют структуру продаж. Если у нас мало специалистов по ERP, то образуется естественный предел продаж услуг по этому классу решений – он равен физической способности к выработке у этих компетентных людей. Если компетенции не управляются, то бизнесу приходится «добирать объем» другими видами деятельности, зачастую менее востребованными и более рискованными.
Иногда телега ставится впереди лошади. Мы формируем портфель продаж исходя из компетенций, а не наоборот. Обучаем сотрудников, платим за это деньги, а потом надеемся, что продажи изменятся, по объему и структуре.
Но реальность остается на месте – компетенции управляют бизнесом. Формируют ограничения, которые мы вынуждены учитывать.
Шестое. Существует постоянно тлеющий конфликт между сотрудниками и бизнесом, в части компетенций. Человек, как правило, хочет «сидеть на теме» - освоить небольшой спектр компетенций, если получится – стать в нем экспертом, и забирать себе значительную часть работ по выбранным темам.
Человеку хорошо, и бизнесу бывает неплохо. Но если компании нужно освоение новых компетенций? Для бизнеса это – риск, для человека – тем более. Особенно, если за освоение новых компетенций не доплачивают. Человек, банально, может остаться на хлебе и воде, исполняя стратегический план компании.
Седьмое. Когда мы берем нового сотрудника, то варианта три. Если он – большой специалист или носитель уникальных компетенций, то все хорошо – мы взяли его целенаправленно, схантили, и затыкаем им какую-нибудь дыру, либо завязываем на него новое направление работы.
Если он – середнячок по нашим основным компетенциям, то быстро интегрируется и просто работает. Тоже неплохо – мы усилили основной поток работ.
А если он новичок, то на некоторое время попадает под пристальное внимание. Бывает, конечно, что мы просто говорим – вот компьютер, вот таск-менеджер, сиди работай. Но, как правило, у всех давно есть какой-нибудь курс адаптации и обучения. Мы прикрепляем к новичку наставника, даем теорию и задачи по выбранным компетенциям, и зорко следим за его успехами.
Проблема случается, когда новичок прошел курс молодого бойца. Человек растворяется - в массе тех самых середнячков, муравьев бизнеса. Пока он был под прицелом, мы понимали его компетенции и управляли ими. Когда он влился, то стал, как все. Вроде, неплохой парень. А что умеет? Да черт его знает… Что все, то и он.
Проблем с компетенциями много, и мы решили их победить. Автоматизировали работу с компетенциями.
Компетенции
Для начала определяемся, что такое компетенции. Пусть это будет иерархический справочник. В нашем случае он выглядит так:
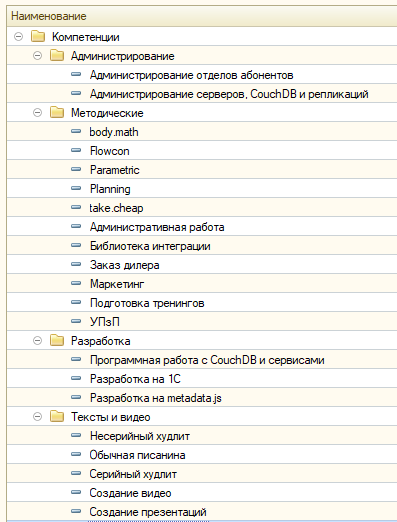
Вообще, четких правил по заполнению этого справочника нет. Принципиально он должен решать три задачи:
- Быть небольшим;
- Описывать текущую картину компетенций – что у нас уже есть;
- Описывать целевую картину компетенций – чего у нас еще нет, но оно нам очень нужно.
Я, заполняя этот справочник, решил только первые две задачи. Целевых компетенций еще не придумал.
Группы у меня получилось четыре. Главная – «Разработка», наш основной хлеб, будь то услуги или создание продуктов. Как вы, возможно, знаете, мы разрабатываем на двух платформах – 1С и metadata.js, а в качестве СУБД используем CouchDB. Отсюда и три основных компетенции в разработке.
Можно было, конечно, разбить ту же разработку 1С на отдельные компетенции, вроде СКД, управляемых форм, работы с оборудованием и т.д. Но конкретно нам это не нужно – слишком давно 1С занимаемся.
Второй по важности раздел – «Методические». Проще говоря, это знание и понимание конкретных продуктов, на какой бы платформе они не были реализованы. Сами понимаете, мало знать язык программирования и среду разработки – надо еще понимать архитектуру, процессы и схемы работы конкретного решения, его методическую составляющую.
Тут я тоже решил не мельчить, и просто перечислил продукты и сервисы. Сюда же затесалась «Административная работа» - не знал, куда ее приткнуть. Ну и «Маркетинг», как вид работ – он мне показался больше методическим.
Дальше – «Тексты и видео». Это писанина всех мастей и создание презентаций, видео, и т.д.
Ну и «Администрирование» - у нас его не очень много, хотя компетенция очень важная, т.к. мы продаем аренду серверов.
Шаблоны компетенций
При разработке компетенций сразу встал вопрос удобства ввода данных. Понятно, что компетенции придется где-то перечислять, и не один раз. Если ввод данных будет неудобным, или станет отнимать слишком много времени, люди просто не будут этого делать.
Поэтому появился справочник «Шаблоны компетенций». Элементарный контейнер, содержащий в себе несколько компетенций с распределенными долями использования. Своего рода спецификация, как состав изделия.
Например, вот так выглядит шаблон, которым я оценивал задачи по разработке 1Сной части Flowcon:
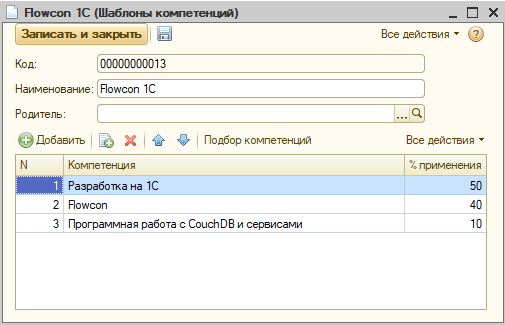
Первая строка – разработка, вторая – методическая, третья – тоже разработка, т.к. Flowcon довольно много взаимодействует с сервисами и CouchDB.
Ну а дальше – полный кайф. Почти весь поток задач по Flowcon я оценивал одним шаблоном. Сколько времени на это ушло – напишу в конце статьи.
Приобретение компетенций
Тут все очень просто – компетенции у нас приобретаются любым способом. Точнее, система позволяет «начислить» компетенции любым способом, даже выдуманным.
Можно начислять компетенции за решение задач. Можно – за продажи, или за прирост эффективности, за прохождение курса, за снижение дебиторки, за вовремя сданную отчетность, или просто так.
Мы для себя решили, что будем начислять компетенции только за решенные задачи.
Принципиально в решении есть три способа начислить компетенции:
- Перечислить их в решенной задаче;
- Перечислить их в произвольном объекте;
- Начислить автоматически, ничего нигде не перечисляя.
Кратко пробежимся по способам начисления.
Компетенции в задачах
В задачах есть табличка «Компетенции», в которой можно перечислить компетенции или шаблоны.
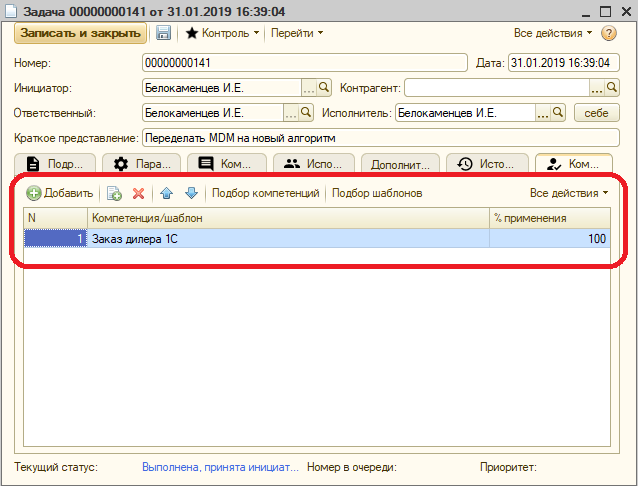
Сначала я сделал заполнение по шаблону – выбираешь его, и в таблицу попадают конкретные компетенции. Потом подумал – блин, неудобно же. Можно просто указать конкретный шаблон, а в отчетах динамически вытаскивать его содержимое.
Так и сделал. Большинство задач, так или иначе, несложно стратифицируются на потоки. Каждый поток, внутри себя, содержит однотипные, с точки зрения компетенций, задачи. Вот и пусть в задаче будет указан шаблон.
Дополнительное удовольствие приносит мысль о том, что шаблон можно изменить. Мало ли, ошибся я, неверно расставил доли компетенций, или какую-то забыл включить. Если бы в задачах лежали конечные компетенции, пришлось бы их все перелопатить. А сейчас достаточно изменить шаблон, и цифры в отчетах сразу изменятся.
Компетенции в произвольных объектах
Быстро стало понятно, что недостаточно указывать компетенции только в задачах. Во-первых, не все пользуются именно флаконовскими задачами. Во-вторых, если начали пользоваться задачами вчера, как быть с компетенциями, полученными за предыдущие периоды?
Причем, проблема прошлых периодов актуальна и для нас. Задачами во Flowcon мы пользуемся с ноября 2018 г., до этого был гитхаб с загрузкой в 1С. Не хочется терять такой объем данных о компетенциях.
Поэтому мы сделали отдельную таблицу, регистр сведений, в котором лежат компетенции, привязанные к любым объектам системы. В нашем случае – к самодельному справочнику «Задачи Гитхаб».

Внутри – уже знакомая табличка с компетенциями. Точно так же можно указать шаблон.
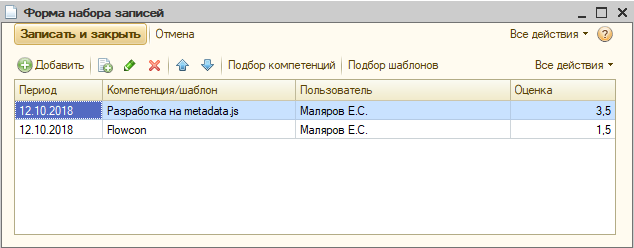
И так – для любого объекта, который вы посчитаете носителем задач. Достаточно лишь расширить тип измерения «Объект» в регистре сведений «флПолученныеКомпетенции», и он автоматически прицепится к формам.
Автокомпетенции
Вариант для умных, но ленивых. Если есть объекты, компетенции по которым всегда начисляются одинаково – например, один и тот же шаблон – то зачем каждый раз что-то в них заполнять? Пусть работает схема компоновки.
Просто пишем запрос, которые вернет нам объекты, период начисления, сотрудников, компетенции и оценки. И всё, компетенции будут начисляться автоматически.
Технически управление автоматическим начислением компетенций управляется справочником «Автокомпетенции». Он прост и скучен – надо лишь указать схему компоновки, и взвести флаг использования автокомпетенции.
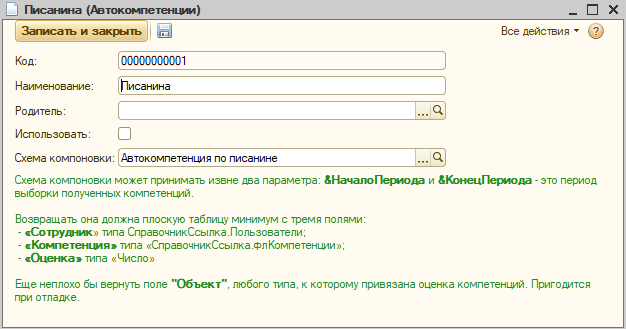
Что важно: автокомпетенции нигде не хранят результаты начислений, все происходит динамически. Мы просто формируем отчет, он на лету производит вычисления и выводит результат.
Преимущества такого подхода очевидны. Компетенции – такая вещь, с которой постоянно нужно «играться». Мы просто меняем схему компоновки, и получаем новые данные.
Еще одно применение такого подхода – моделирование разных систем оценки. Можно изготовить два, или три разных варианта автокомпетенций, и посмотреть на одни и те же данные под разным углом.
Оценки и периоды
При начислении компетенций важно не только что именно развивается, но и на сколько и когда. Для количественной оценки компетенций мы используем те же единицы, что и для оценки задач – баллы, условные единицы.
Другим людям никто не мешает оценивать компетенции в любой другой единице. Например, в часах и рублях. Достаточно указывать в поле «Оценка» то, что нужно. Какую бы единицу вы не выбрали, она все равно будет понятна только вам. Главное – динамика.
Важным параметром оценки является «период» - это дата, к которой мы привязываем получение компетенций. Например, для задач это – дата выполнения. Дата создания не подходит, т.к. компетенции приходит в процессе работы, и процесс этот может начаться через год после постановки задачи.
Период нужен и для произвольных объектов, и для автокомпетенций. Ничего сложного в определении периода нет, надо лишь о нем не забывать. Иначе будет неправильно считаться износ компетенций.
Износ компетенций
Как мы определились во вступлении, компетенции имеют свойство убывать. Там же мы пришли к выводу, что некоторый остаток остается. Будем считать, что навсегда.
Вот это «убывание» компетенций мы решили назвать износом.
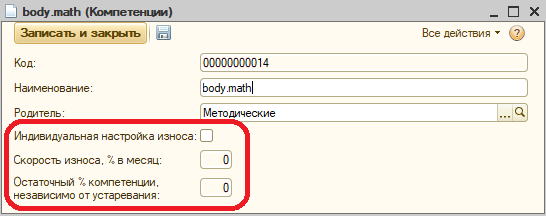
Получается, нам нужны две величины – скорость износа и величина остатка. Эти параметры хранятся в настройках.

Зная, что оценки компетенций у нас относительные, скорость износа и остаток можно выразить только в процентах – так мы и сделали. Главный вопрос – какие цифры поставить?
Если честно, не знаю. И спросить не у кого. Да и незачем. Скорость износа можно определить по практике. Я выбрал 50 % в месяц – по моим наблюдениям, через два месяца вспомнить компетенцию уже достаточно сложно. В качестве остатка выбрал 10 %.
И вот у нас есть две величины – приобретение компетенций (приход) и износ компетенций (расход). Не хватает третьей – остатка.
Остаток – это самое крутое в компетенциях. Это «несгораемая сумма», реальный багаж знаний, доступный без предварительной подготовки. Если угодно, это ПЗУ специалиста. Именно такие компетенции человек использует максимально эффективно – просто садится и делает.
Или по-другому: остаток компетенций – это как накопления в банке, или надежные инвестиции. Получил доход, отложил 10 %, а остальное – потратил зря. Ну, то есть, не зря конечно – надо же питаться, одеваться, развлекаться и т.д. Но в перспективе, затраты текущего периода особой роли не играют, не делают вклада в будущее.
А инвестиции – наоборот, работают на будущее. Как и остаток компетенций.
На всякий случай, мы заложили возможность управления скоростью износа и величиной остатка индивидуально для каждой компетенции.
Скорость ввода данных
Разработав систему учета компетенций, мы начали применять ее на себе. Я, зная, что скорость работы с компетенциями имеет решающее значение, сделал замеры – количества задач и времени.
Итак:
- Я заполнил компетенции в 3 000 задач (это примерно за полтора года, на двоих);
- Одновременно я заполнял справочник компетенций, шаблонов;
- Параллельно я исправлял обнаруженные ошибки;
- Решил не использовать автокомпетенции, т.е. все объекты обработал вручную;
- Все это я сделал за 6 часов.
Так как задачи были старые, то быстро заполнять не получилось – приходилось сидеть, вспоминать, о чем вообще была речь. Тем более, что некоторые задачи я видел впервые, потому что оценивал не только себя. Иногда приходилось останавливаться и размышлять о том, какие элементы в справочник компетенций добавить.
Но итоговая цифра меня порадовала – примерно 7.2 секунды на задачу. Время грязное – с учетом перекуров, чаепитий, открытия и записи объектов.
3000 задач за полтора года – это примерно 8 задач в день на двоих. При наличии заполненного справочника компетенций и настроенных шаблонов на весь учет будет уходить 57 секунд в день. Шикарно.
Профили компетенций
Учет – это хорошо, но надо и управлять, в том числе компетенциями. Учет дает понимание текущей картины, насколько развиты те или иные навыки, каков остаток, в каком направлении и с какой интенсивностью идет динамика.
Теперь нужно управлять – ставить цель и двигаться к ней. В компетенциях цели простые – чего-то сделать поменьше, чего-то сделать побольше.
Ну а дальше – детали. Добавить новую компетенцию, установить для нее целевую оценку, и решать задачи по этой теме. Наоборот – снизить применение какой-то компетенции, если она мешает развиваться специалисту или компании в целом. Изменить баланс компетенций, отдав приоритет одним в ущерб другим. Определить профиль специалиста определенной категории, и отслеживать реальное изменение компетенций, чтобы избегать перекосов.
Все это, по-русски, называется «планирование», которое есть основа управления. У нас для компетенций можно планировать два параметра – объем (=оценку) и баланс.
Для планирования мы создали простой справочник под названием «Профили компетенций». В нем просто перечисляются компетенции, ставятся оценки и баланс в процентах. Справочник – многоцелевой, и каждый может использовать его по-своему.
Например, я решил изменить свой текущий баланс компетенций и написал для себя целевой профиль:
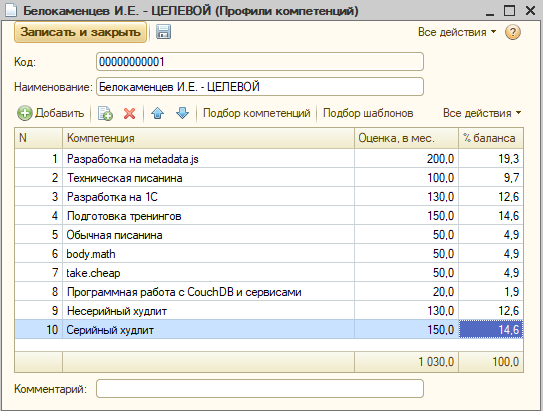
Другой пример – решили мы нарисовать профиль разработчика. Оценки нас, допустим, не интересуют – только баланс. Его и заполним:
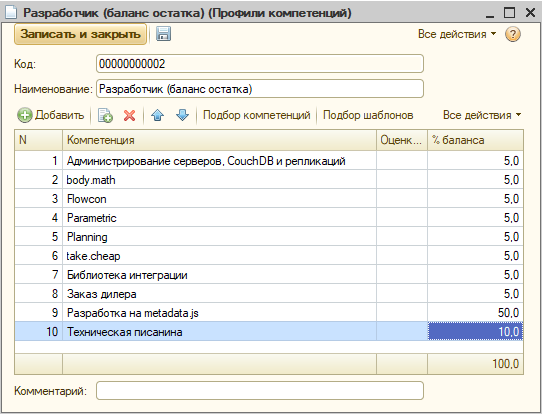
Теперь мы можем любого сотрудника сверять с этим профилем и понимать, правильно он развивается, или нет. Причем, оценивать можем и по динамике – например, как прирастали компетенции за последний месяц, и по остатку – каков баланс несгораемых компетенций он накопил.
Оценка соответствия профилю выполняется в отчетах.
Отчеты
Данные есть, теперь их надо увидеть. Сейчас в системе три отчета по компетенциям, но из них, с помощью настройки, можно сделать пару десятков, для ответов на конкретные вопросы.
Когда накопится практика работы с системой, сделаем новые отчеты.
Отчет «Компетенции»
Это – самый универсальный отчет. Он просто выводит данные о полученных компетенциях за период. Собирает отовсюду – из задач, произвольных объектов и автокомпетенций.
Вот мои компетенции за полтора года:
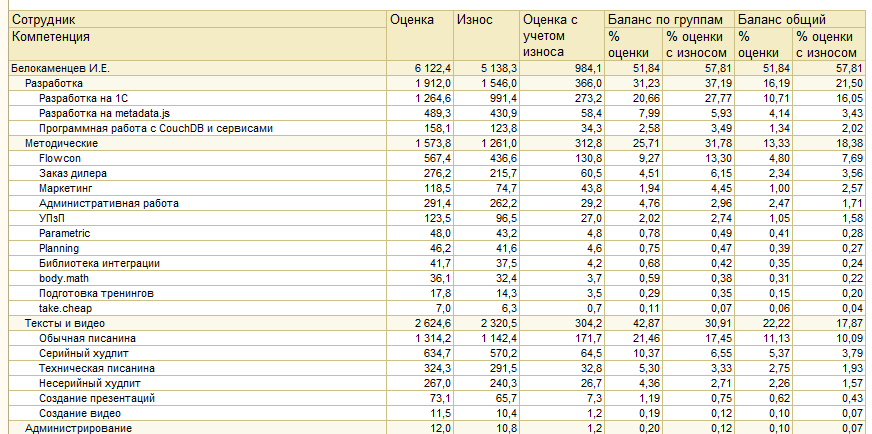
Что тут видно? Ну, меня видно – см. верхний левый угол. Видно иерархию компетенций. Видна оценка – приход навыков за полтора года. Износ рядом написан – сколько компетенций улетели в трубу естественным образом. Остаток с учетом износа – видно, что он намного ниже прихода.
Кстати, на картинке данные отсортированы по убыванию остатка, и получается забавная картина – приход по писанине больше, чем по разработке, а остаток – наоборот. О чем это говорит? Я последние пару месяцев сильно увлекся разработкой, и эти компетенции еще не успели улетучиться.
Ну и две группы колонок фактического баланса. Одна показывает процент в текущей группе («Разработка», «Методические» и т.д.), другая – в общей массе.
Проверим мою гипотезу о том, что в последнее время я разработкой увлекся. Ограничим период прошлым месяцем:
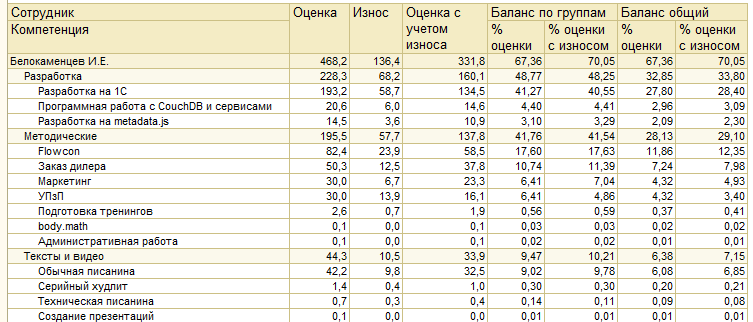
Ну да, 70% - разработка. Посмотрим без сотрудников, по всей компании за полтора года:
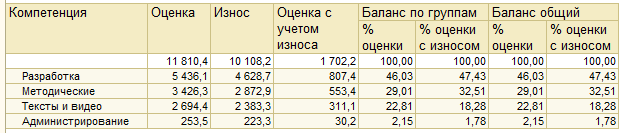
Чудесно. Все-таки, мы больше разработчики, чем писатели.
Отчет «Диаграмма компетенций»
Не знаю, как вам, а мне не нравятся отчеты в виде таблиц. Приходится вглядываться, соотносить, ковыряться. Без обычных отчетов, конечно, никуда, но нужно и графическое представление.
Для вывода информации в графическом виде мы сделали отчет «Диаграмма компетенций». Вот, например, профиль остатка моих компетенций за полтора года:
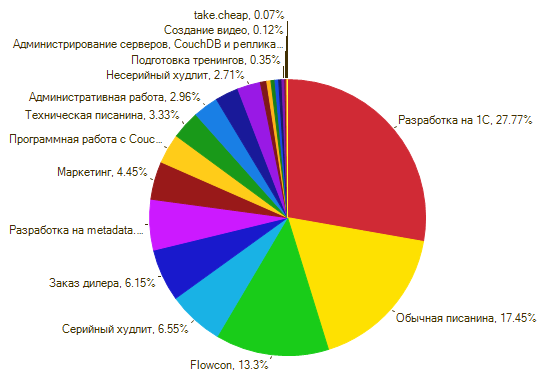
Или гистограмма компетенций всей компании по верхнему уровню иерархии:
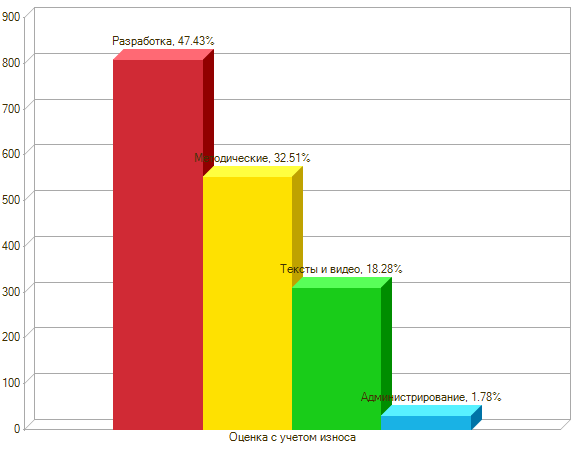
А вот график, показывающий, когда мы накапливали компетенции, которыми сейчас пользуемся. Или по-другому, это история накопления остатка компетенций.
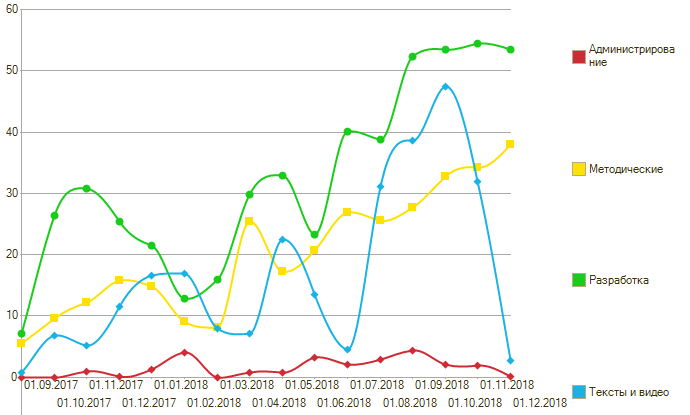
Можно сравнить компетенции людей в графическом виде:
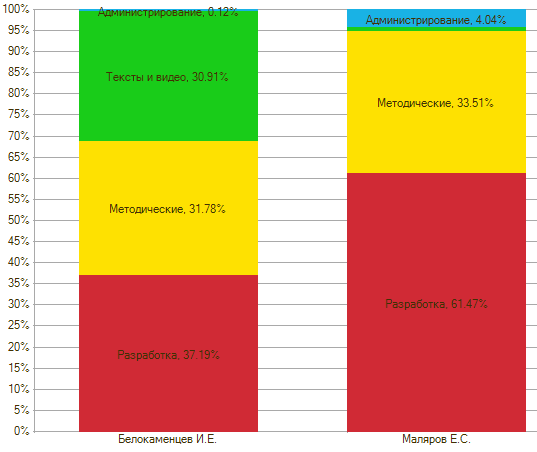
А можно детализировать и сравнить компетенции, относящиеся только к разработке:
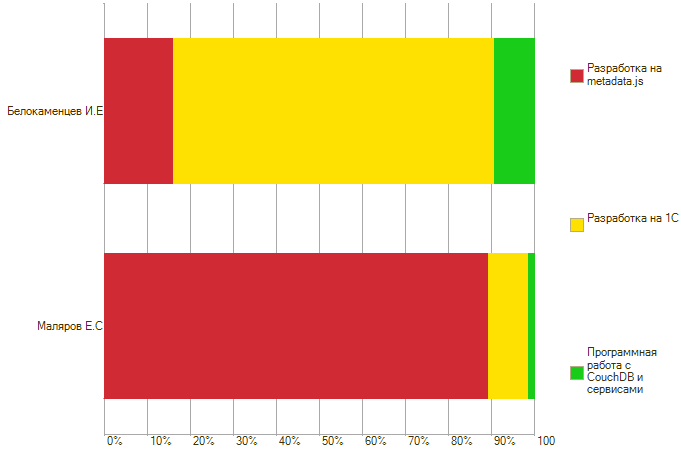
Из этого сравнения очевидно, почему я в своем целевом профиле поставил почти 20 % разработки на metadata.js. Кстати, о профилях.
Отчет «Соответствие профилю компетенций»
Это очень простой отчет, и создан он для одной цели – сравнивать план и факт. План – это профиль компетенций. Факт – это реально полученные за период компетенции.
Посмотрим, насколько я соответствую профилю компетенций, который сам для себя составил:
Как видите, одна краснота – нет ни одной компетенции, соответствующей целевому балансу. Значит, мои компетенции не управляемы и не соответствуют стратегии компании. Значит, может ничего не получиться и надо срочно меняться.
Для примера я составил профиль абстрактного сотрудника – разработчика, который мог бы у нас работать. И проверил себя на этом профиле:
Пф… Что ж я за человек-то такой… Все, завтра начинаю новую жизнь.
Итого
Реальность, к сожалению, ужасна. Компании нужно одно, сотрудники делают другое. И я – в том числе.
А так, пока цифр не знаешь, живешь себе спокойно и радуешься. Только не понимаешь, почему компания не развивается теми темпами, которые хочется видеть. А причина-то, оказывается, во мне.
Компетенции не дают реализовывать новые продукты, осваивать другие рынки, выходить за рамки одной страны и вообще. Ну, у каждого свое «вообще».
Вы как хотите, а я буду меняться. Начну с себя.
Суть проста (как и реализация, впрочем). Довольно часто нужно, чтобы пользователям информационной системы ставились задачи. Причины разные - или что-то пошло не так, или надо что-то доделать, или обработать связанные данные, или выполнить свой кусок процесса.
Самый простой и востребованный пример - отложенное исправление ошибок (тех, которые сразу не видны). Например, бухгалтер забыл сделать выписку, и у исходящих платежек не стоит признак Оплачено. Или возникли отрицательные остатки по товарам в бух.учете. Или числится одновременное сальдо на 60.01 и 60.02. И т.д.
Такого рода ошибки сразу никто не кидается исправлять. К тому же, зачастую, это не очень просто. Ошибка может быть создана не одним, а несколькими документами и пользователями, поэтому с ней не справляются средства контроля при записи, наподобие Проверки данных.
Казалось бы - ну и ладно. Можно использовать отчеты с нужными настройками. Можно использовать средства контроля, наподобие Консилиума.
А нет, не ладно. Отчеты обладают существенным недостатком - они требуют дисциплины и внимания. Человек должен не забыть зайти в отчет. А когда не забыл - должен не полениться. Не говоря уже о том, что он должен сделать то, чего от него требуется.
Мы, допустим, человеку не доверяем. Хотим знать, работает ли он с проблемной областью. Как это проверить? Путь один - тоже заходить и смотреть те же самые отчеты. Если там совсем ничего не происходит, вывод очевиден - не работает человек. А если что-то меняется, но ошибки все равно есть? Как часто он работает с этими ошибками? Сколько исправляет в день или неделю? Сколько времени эти ошибки уже болтаются в базе? А если мы - ребята продвинутые, и хотим управлять негативными состояниями по принципу Айсберг?
Теперь уберем слово "ошибка", заменим словом "задача". Нам нужно, чтобы человек что-то сделал - неважно, исправил ли ошибку, согласовал ли заявку, оформил ли перемещение, создал ли бюджет, совершил ли 10 звонков, и т.д. Как автоматизировать управление такими задачами?
Обычно мы делаем либо бизнес-процессы (через конфигуратор или какой-нибудь рисовалкой из типовых решений), или кучу отчетов, или букет разнообразных напоминалок/выскакивалок/письмоотправлялок.
Автозадачи значительно упрощают этот процесс:
- автоматически создают задачи, когда возникли подходящие условия;
- описывают необходимый контекст задачи - ссылки на документы, справочники, приводят количественные данные;
- автоматически закрывают задачи, когда человек сделал все, что нужно (или условия изменились, и задача более не актуальна);
- позволяют третьим лицам контролировать выполнение задач, в т.ч. ретроспективно.
Не буду больше ходить вокруг да около, изложу инструкцию по работе с автозадачами.
Программирование автозадач
АЗ программируются в справочнике «Параметры автозадач» - это вроде как типы АЗ.
Центральное место в программировании АЗ занимает составление схемы компоновки. В чем ее суть:
- Схема должна описывать, при каких условиях есть задача. Например, схема возвращает платежку исходящую, которая проведена, но в ней не стоит флаг Оплачено. Это будет задача – сделать выписку, чтобы в регистрах списались деньги;
- В то же время, когда человек выполнит задачу, схема должна вернуть пустую выборку – это будет означать, что задача выполнена;
- Ну т.е. должно быть четкое понимание при разработке схемы, при каких условиях задача есть, а при каких она выполнена. Это одно из основных отличий АЗ от прочих подобных механизмов – АЗ не привязаны к событиямсистемы, нет понятий «возникновение задачи» или «закрытие задачи»;
- Одна из аналогий АЗ – отчеты, которые пользователь настраивает сам себе, чтобы понять, что ему еще надо сделать. В примере из п.1 это будет отчет «Неоплаченные исходящие платежи»: если отчет что-то показал – есть задача, если вышел пустой – все в порядке, задачи нет.
Требования к схеме компоновки:
Схема компоновки должна обязательно содержать три поля:
- КлючЗадачи – любого типа. Должно быть всегда, в разделе «Выбранные поля» схемы;
- ТекущийОстаток – числового типа. Должно быть всегда, в разделе «Выбранные поля» схемы;
- Исполнитель – типа «Справочник.Пользователи» или «Справочник.флРолиПользователей». Должен быть в зависимости от типа определения исполнителя (см. раздел ниже).
КлючЗадачи (КЗ) – это поле, которое отвечает за количество созданных АЗ. Своего рода способ группировки. Каждая задача должна к чему-то относиться, как-то идентифицироваться в этом мире.
Также, ключ задачи имеет важное значение при определении срока выполнения задачи.
Если вернуться к примеру с платежками, то варианты могут быть такие:
- Ключ задачи – платежка. В этом случае задач будет ровно столько, сколько неоплаченных платежек. В задаче будет ссылка на одну эту платежку. Срок выполнения надо будет определять, исходя из знаний об этой платежке – например, дата документа + сутки;
- Ключ задачи – начало дня платежки. В этом случае задач будет ровно столько, сколько разных дней есть в неоплаченных платежках. Например, если есть неоплаченные платежки за сегодня и за вчера, то автозадач будет две. Срок выполнения можно вычислять, исходя из ключа задачи – например, ключ задачи + сутки, или ключ задачи + 8 часов.
- Ключ задачи – пустой, или какое-то постоянное значение (типа «», 1, Истина, «ключ»). В этом случае задача будет одна, и в ней будут все неоплаченные платежки. Когда настанет момент, что все платежки будут оплачены, задача закроется. Когда вновь возникнут неоплаченные платежки, создастся новая задача. Ну это, вообще, общее правило АЗ – если задача закрылась, она уже не откроется – всегда будет создана новая.
Теперь про «Текущий остаток». Любую задачу можно измерить с помощью цифры. Например, в примере с платежками это может быть количество документов, или общая сумма. Сам я на практике обычно использую количество документов/справочников.
Так вот, эта количественная характеристика и хранится в поле «Текущий остаток». Как только текущий остаток становится равен нулю – задача закрывается. Собственно, если при выполнении схемы компоновки не вернулось вообще ничего (пустая выборка), текущий остаток считается равным нулю.
Также, внутри автозадачи есть история изменения текущего остатка, в виде табличной части. Это для тех задач, которые могут выполняться поэтапно. В примере с платежками это варианты ключа задачи 2 и 3. Например, было 10 документов – тек. остаток будет 10. Человек сделал выписку, 2 дока оплатились – текущий остаток будет 8. И т.д., до нуля.
Ограничений по использованию вычисляемых полей, функций общих модулей – нет.
Определение исполнителя
Исполнитель задачи определяется двумя способами:
- Просто указывается в параметрах автозадачи – там есть соответствующее поле Исполнитель. Можно выбрать конкретного пользователя или роль пользователя. В таком варианте поле «Исполнитель» не является обязательным для схемы компоновки. Например, в случае с платежками именно такой вариант подойдет, т.к. с ними работает, как правило, один человек и он известен;
- Определяется схемой компоновки – это тот случай, когда информация об исполнителе хранится где-то внутри объектов, к которым привязана автозадача. Например, если вы хотите сделать автозадачу по согласованию договора, а перечень согласующих хранится в табличной части, то исполнителем и будет согласующий. В таком варианте схема компоновки должна обязательно содержать группировку Исполнитель. В параметрах автозадачи, при этом, надо ставить флаг «Исполнитель из схемы».
Группировки схемы компоновки
Тут всего два варианта:
- Если исполнитель определяется в параметрах автозадачи, то группировка должна быть одна - <Детальные записи>. Все остальные поля – в выбранных полях;
- Если исполнитель берется из схемы, то первой должна идти группировка «Исполнитель», в ее иерархии - <Детальные записи>. Все остальные поля – в выбранных полях.
Сроки выполнения автозадач
Срок выполнения автозадачи определяется, исходя из самой автозадачи. Вычисление срока реализуется на встроенном языке платформы, с помощью произвольной формулы. В формуле доступны все конструкции языка, а также доступна формируемая задача (типа "СправочникОбъект.флАвтозадачи"). Имя переменной – Источник. Результат вычисления по формуле должен быть помещен в переменную Результат.
Это стоит учитывать при разработке схемы компоновки и выборе ключа задачи.
Если ключом задачи является какой-то документ, то обычно срок определяется датой этого документа. Например, если задача должна быть решена через сутки после создания документа, то формула будет:
Результат = Источник.КлючЗадачи.Дата + 3600 * 24.
Если не сутки, а конец того дня, когда был создан документ, то формула будет такой:
Результат = НачалоДня(Источник.КлючЗадачи.Дата) + 3600 * 17.
Если ключом задачи является, например, дата (сама задача при этом содержит несколько документов), то формулы будут такие:
Результат = Источник.КлючЗадачи + 3600 * 24, или Результат = НачалоДня(Источник.КлючЗадачи) + 17 * 3600.
Также, при вычислении срока доступны все реквизиты задачи. Например, у задачи есть реквизит ДатаПостановки – он равен дате создания задачи, его тоже можно использовать. Формула будет такой, к примеру:
Результат = НачалоДня(Источник.ДатаПостановки) + 17 * 3600.
И так далее, с разными вариациями. Например, можно делать запрос к производственному календарю, если срок задачи измеряется в рабочих днях.
Формулы вычисления сроков живут в справочнике флПроизвольныеФормулы. В параметрах автозадачи выбирается конкретный элемент этого справочника. У меня, например, чаще всего используются два элемента этого справочника – «3 рабочих дня от даты постановки» и «Конец дня постановки задачи».
Написание текста и заголовка задачи
У автозадачи есть заголовок, который отображается в списках, и есть текст, который читает пользователь, когда зайдет в задачу. Заголовок потом превращается в наименование элемента справочника флАвтозадачи.
Самый простой вариант – написать обычным текстом заголовок и текст задачи. В этом случае при формировании автозадачи тексты просто скопируются. Но так не совсем интересно - лучше сделать задачу контекстно зависимой.
В текстах можно вставлять вычисляемые куски. Доступна переменная Задача, в которой содержится записываемая автозадача (тип "СправочникОбъект.флАвтозадачи").
Вычисляемый кусок в тексте оформляется квадратными скобками, например:
[Формат(ТекущаяДата(), «ДФ=dd.MM.yyyy») + « г.»]
Если в примере с платежками, то примерно так:
- Для варианта, когда ключом задачи является платежка, можно сделать такое краткое представление: «Оплатите платежку [Задача.КлючЗадачи]!!!»
- Для варианта, когда ключом задачи является дата платежки, можно написать так: «Надо сделать выписку и оплатить платежки от [Формат(Задача.КлючЗадачи, «ДФ=dd.MM.yyyy») + « г.»]»
Правила вычисления одинаковы для краткого представления и для текста задачи. Я в тексте задачи обычно даю более подробное описание того, что надо сделать, какие условия выполнить, чтобы задача закрылась.
Расшифровка автозадачи
Результат выполнения схемы возвращается человеку в виде расшифровки. Расшифровка очень важна, т.к. она позволяет человеку прямо из задачи проваливаться в нужные документы, справочники и т.д. и делать то, что просит автозадача.
Расшифровка бывает двух типов:
- В виде табличного документа – применяется, когда автозадача выдает несколько объектов для обработки;
- В виде ключа задачи – когда объект один.
Также, можно эти варианты комбинировать, но я сам такую настройку ни разу не использовал.
Расшифровка в виде табличного документа – это просто выгруженный в таблицу результат компоновки. Из результата запроса автоматически убираются служебные поля (КлючЗадачи, ТекущийОстаток, Исполнитель), все остальное попадает в табличный документ. Соответственно, в выбранные поля схемы компоновки можно и нужно добавлять то, что поможет пользователю быстро решить задачу.
Например, в случае с платежками, когда мы выводим все платежки за день, я добавляю в выбранные поля саму платежку, расчетный счет и сумму. Пользователь видит в расшифровке таблицу из трех колонок, может выбрать исходя из своего понимания ситуации, провалиться в документ и сделать то что надо.
Сам табличный документ будет отображен пользователю в форме автозадачи.
Хранится табличный документ в регистре сведений флРасшифровкиАвтозадач. Я намеренно вынес его из справочника автозадач, чтобы можно было по истечении определенного времени безболезненно удалить расшифровки старых автозадач (регистр чистить значительно проще, чем справочник).
Чтобы пользователь увидел расшифровку, надо в параметрах автозадачи поставить флаг «Показывать расшифровку».
Второй вариант – показывать только ключ задачи. Это тот случай, когда автозадача содержит только один объект для обработки.
Тут все значительно проще – пользователю на форму будет просто выводится ключ задачи. При этом в параметрах автозадачи можно указать заголовок для ключа (чтобы не было написано «Ключ задачи» или «Объект»). Например, когда ключом задачи является сама платежка, можно задать заголовок ключа «Вот эта платежка, которую надо оплатить».
Ключ задачи будет выведен пользователю на форму в виде гиперссылки, он сможет в неё проваливаться.
Чтобы пользователь видел ключ, надо в параметрах задачи поставить флаг «Показывать ключ».
Остальные реквизиты настройки
- Ответственный – можно указать пользователя или роль человека, который отвечает за выполнение задачи. Это, вроде как, ответственный за процесс, или просто начальник исполнителя задачи. Можно не указывать;
- Единица измерения остатка – строковое поле, которое добавляется к текущему остатку по задаче. Например, «док.» или «руб.»;
- Количество знаков после запятой – для форматирования вывода текущего остатка автозадач;
- Закрывать по окончании срока – если флаг установлен, то задача будет автоматически закрываться по окончании срока выполнения. При этом в задаче будет стоять признак «Закрыта»;
- Закрывается вручную – это для задач, у которых нельзя запросом отследить, что они выполнены. У меня одна такая задача – удаление пользователей из домена/почты при увольнении. Возникновение задачи отследить можно, исполнение – нет. Для ручных задач в форме появляется кнопка «Отметить выполнение», и пользователь должен ее нажимать сам;
- Кто видит задачу – таблица, где можно перечислить зрителей. Я использовал для RLS;
- Расписание - расписание формирования конкретно этого типа автозадач.
Формирование автозадач
Для формирования автозадач используется регл.задание флФормированиеАвтозадач.
Что оно делает:
- Смотрит, какие типы автозадач уже пора обновить;
- Выполняет все схемы компоновки параметров задач из п.1;
- Формирует таблицу новых актуальных задач;
- Формирует таблицу старых актуальных задач (которые не выполнены и не закрытые);
- Сравнивает таблицы новых и старых актуальных задач;
- Если задача совсем новая – создает, если уже была такая – обновляет. Сравнение идет по полям «КлючЗадачи» и «Исполнитель». Это означает, к примеру, что при изменении исполнителя в параметрах автозадач все ранее поставленные задачи будут перепоставлены новому исполнителю;
- Закрывает старые задачи, которые стали не актуальными;
- Закрывает задачи, у которых вышел срок и стоит флаг «Закрывать по окончании срока».
Расписание регл.задания я ставлю через консоль. С учетом того, что на каждый тип автозадачи можно назначить свое расписание, думаю, что нормально поставить раз в минуту.
Примеры из моей практики
Расскажу несколько примеров использования автозадач из своей практики.
- Все согласования проходили через автозадачи. Заявки на расход денег, договоры, спецификации, разные проверки качества, служебки, акты на списание и т.д. Все процессы, где для продолжения кто-то должен поставить флажок. Такие автозадачи очень просты. Нет флага - есть автозадача. Есть флаг - закрылась автозадача.
Исполнителей легко определить по штатной структуре.
- Напоминалки, не требующие каких-то действий в системе, тоже стали выводить в автозадачи.
Типовые напоминания, например, о днях рождения контактных лиц контрагентов, требуют отслеживания - надо в каждом зайти и нажать, чтобы система напоминала о дне рождения. Причем, напоминать она будет менеджеру, который указан в контрагенте. Если менеджер уволился, то новому менеджеру придется повторить настройку.
Автозадача проще - она сообщает за несколько дней обо всех днях рождения по контрагентам выбранной папки, причем всему отделу сразу. Как уж там они поздравляют - их дело. Задача закрывается либо по сроку (на следующий день после ДР), либо руками.
Ну и напоминалки попроще - ввести бюджет подразделения, оформить табель, зарезервировать ДС на неделю, составить отчет по состоянию проектов. Такие напоминалки контролируются автоматически, т.к. в системе что-то появляется - документ бюджета, например. А если не появился - хрен с ним, задача закроется по истечению срока (мало ли, не нужен человеку резерв денег).
- Реальные оцифрованные задачи, в основном по снабжению.Реальными я их называю потому, что от их качества и исполнения зависят важные бизнес-процессы, коим являлось снабжение.
Задача содержала в себе все позиции с количествами, которые конкретный снабженец должен был заказать.
"Заказать" - это оформить заказ поставщику. Количества и позиции определялись с помощью универсального механизма планирования.
Как только снабженец все заказал, задача закрывалась. Как только появлялась новая потребность - задача открывалась снова.
Другой реальной задачей было опустошение склада возвратов. На этом складе была продукция от поставщиков, которая не прошла ОТК, и ее надо было вернуть. На возврат - 30 дней. Ответственный за вывоз - тот, кто купил (он известен из приходной накладной). Задача закрывалась, когда продукция исчезала со склада возвратов.
Еще была задача для склада и менеджеров по пополнению склада филиала, который территориально находится в сотнях километров. Система (универсальный механизм планирования) вычисляла, какие позиции номенклатуры и в каких количествах там нужны, и формировала автозадачу. Закрывалась задача, когда появлялся внутренний заказ на перемещение.
- Задачи на корректность отложенного заполнения справочников/документов.Отложенное - это когда значение сразу зааполнить нельзя, т.к. неизвестно, чем заполнять.
Банальный пример - добавляем нового сотрудника в 1С, в пользователе надо указать физ.лицо, а кадровая служба работает неоперативно, и физ.лицо появится через пару дней. У нас физ.лицо было нужно в пользователе, т.к. в нем живет и контактная информация, и через физ.лицо работали многие автозадачи - например, чтобы понимать место пользователя в штатном расписании.
Получается простая автозадача - вывалить список пользователей, у которых не заполнено физ.лицо.
Другой пример - коды ТНВЭД в номенклатуре. Номенклатуру создает один человек, код ТНВЭД знает другой человек, работать синхронно они не могут. Появляется автозадача - поставить код ТНВЭД, со сроком исполнения дней пять.
Вообще к номенклатуре много чего привязывалось. Например, плановое время поставки нужно было вводить. Указать, в сборе поставляется или по частям. Ввести плановую себестоимость, для расчета коммерческих предложений.
- Задачи на следующие этапы бизнес-процесса. Как таковые бизнес-процессы не использовались - они тяжелые, скучные и громоздкие. А вот отслеживать важные этапы с помощью автозадач - самое оно, потому что видеть бизнес-процесс в виде карты, со всеми этапами - никому не интересно. А вот не профукать что-то важное - то, что надо.
Например, зарубежные закупки и авансы зарубежным поставщикам. Сами знаете, сколько там надо бумажек собрать и предоставить в бухгалтерию, и все это асинхронно - т.е. нельзя, например, запретить приходование продукции, пока нет бумажек, потому что они реально могут несколько дней идти.
Делаем нашлепку к поступлению товаров и услуг с галочками, типа "такой-то документ предоставлен", и вешаем автозадачу ответственному за поступление. А одновременно - и бухгалтеру, чтобы подпинывал менеджера. Принес бумажку, поставили галку, задача закрылась.
Отдельная тема - контроль авансов зарубежным поставщикам. Финконтроль за такие дела штрафует, когда вы запулили в Китай денег, указали срок аванса, а по его истечении у вас нет накладной или какой-то там бумажки (не помню, как она называется). Чтобы не попасть на штраф, вешалась автозадача, привязанная к авансовому документу.
Еще пример - те же заказы поставщикам. Оформление заказ поставщику снимает задачу "заказать продукцию", но порождает другую - подписать спецификацию с поставщиком (он ведь должен знать, что мы ему что-то заказали). Приделываем простецкую галочку к заказу поставщику - "спецификация согласована обеими сторонами" - и вешаем автозадачу, чтобы снабженец галку в течение 5 дней поставил. Заодно не даем потом заказ менять, когда галка стоит.
Для юристов делали автозадачу по предоставлению оригиналов договоров. Создание, согласование договоров, замечания, хранение сканов - все в системе. Но еще в архиве должны быть оригиналы. На эту тему - автозадача. Как только договор согласован, с инициатора в 30-дневный срок требуется предоставить оригинал, подписанный обеими сторонами. Предоставил, юрист поставил галку, задача исчезла.
Схожая задача - для бухгалтерии, по сбору оригиналов бумажек (накладные, счета-фактуры, ТОРГи, ГТД, инвойсы и т.д.). Был простенький механизм, который сам определял, какие бумажки должны быть предоставлены по конкретному документу в 1С, и бухгалтер ставил там галочки "предоставлен". А чтобы ответственный за документ не забывал бумажки сдать, ему вешалась автозадача.
Еще задача - удаление пользователей из системы при увольнении. Появился документ увольнения, в нем указан последний день работы - вот и вся необходимая информация. Вешается автозадача админу базы - удалить пользователя. Закрывается, когда пользователь деактивирован.
- Задачи по контролю убегающей адекватности - это когда сегодня данные нормальные, а завтра уже нет.
Простейший пример - сроки поставок. В заказе поставщику по каждой позиции стоит дата, когда мы ее ждем у себя. Поставщик эти сроки тоже знает - они в спецификации стоят. Если поставщик не успевает, он в 99% случаев об этом будет молчать до тех пор, пока не спросят. А чтобы спросили - есть автозадача для снабженца. Подошел или прошел срок - звони поставщику, выясняй что не так, договаривайся о новом сроке. Автозадача закроется в двух случаях - если срок станет адекватным или если заказ приедет к нам. Чтобы не хулиганили - изменение сроков через начальника снабжения.
Я много раз убеждался на практике, насколько значимую роль в учете играют ошибки. Отрицательную роль, разумеется. Наверное, потому, что когда-то сильно увлекался темой управления качеством.
Если ошибку исправить сразу, а не откладывать на потом, то проблем «потом» будет значительно меньше. Если же оставить ошибку, надеясь, что «потом» будет куча времени на ее исправление, то почти всегда наступает разочарование. «Потом» свободного времени будет ровно столько же, сколько и сейчас – поток текучки ведь никуда не девается, даже если на дворе отчетный период. Ошибки исправляются, конечно – как попало, лишь бы закрылось.
В кризисные моменты цейтнота кажется, что вот теперь-то, как только потушим пожар, мы начнем жить по-другому. Будем следить за качеством первички, отрицательными остатками, незакрытыми авансами и помеченными на удаление корректировками. Конечно будем! Ведь мы столько ночей не спали, столько валидола выпили, пока всё это исправляли, когда на носу висели НДС и налог на прибыль!
Но кризис проходит, и все возвращается на круги своя. Стимул-то пропадает. Получается замкнутый круг: пока есть стимул, нет времени, а когда появляется время, пропадает стимул.
Чтобы разорвать этот замкнутый круг, я придумал «Проверку ведения учета», которая позже стала Консилиумом. А потом – «Проверку данных». Первая должна была проверять данные массово, за большой период и по множеству критериев. Вторая – не давала записывать совсем уж корявые первичные документы.
Со второй всё получилось еще в 2015 году, она разошлась огромными тиражами и до сих пор доступна в интернете. Потом попала в Flowcon, где получила дальнейшее развитие.
А вот с «Проверкой ведения учета» поначалу как-то не складывалось. Мир 1Сников, узнав о сборе проверок для массового инструмента, откликнулся с энтузиазмом, начались обсуждения и предложения. А у меня началась работа. Работоспособный вариант инструмента я сделал, но переступить через порог в 10 проверок так и не смог.
Хотя тандем намечался шикарный, чем-то похожий на антивирус.
Есть сканер – «Проверка ведения учета», который проверяет, по сути, всю информационную базу на все виды ошибок – так же, как это делает антивирус, ищущий признаки наличия вирусов из своей базы в файлах на компьютере.
Есть монитор, или фильтр – «Проверка данных», который не дает ошибке появиться на свет, так же, как антивирус-монитор не дает сохранить заражённый файл из интернета или с внешнего носителя.
Ну и в методическом плане сканер и монитор разделяются прекрасно.
«Проверка данных» - это инструмент для кастомизации на месте, т.е. для реализации проверок, специфичных для конкретного предприятия. Можно запретить запись справочника или документа в любой комбинации фильтров, хоть в зависимости от фазы луны.
«Проверка ведения учета» - это проверка информационной базы по критериям, собранным со всего нашего 1Сного мира. Что важно – здесь могут проверяться не конкретные объекты, вроде справочников и документов, а все возможные комбинации. Например, отрицательные остатки, одновременное сальдо, незакрытые регистры и т.д. Такие проверки невозможно реализовать на уровне записи документа. Во-первых, контекст не подходящий. Во-вторых, они никак не связаны с конкретным документом.
Но, как ни были хороши мои планы, «Проверку ведения учета» я забросил на отметке в 10 проверок. Сначала на партнерской конференции 1С, потом на Инфостарте. Эти 10 проверок стали психологическим порогом, который я в течение нескольких лет не мог преодолеть.
Однако, появился Консилиум.
Консилиум
Долго рассказывать не буду, есть большая статья на тему Консилиума. Кратко изложу суть, чтоб вам два раза не вставать. Консилиум – это отчет, который при формировании скачивает из интернета проверки для конфигурации, выполняет их и показывает результат. Отчет внешний, работает в любой конфигурации, начиная с платформы 8.2. Не для всех конфигураций уже есть проверки, но психологический порог в 10 штук преодолеть удалось давно.
Была в Консилиуме одна бяка – я обещал, что часть проверок будут бесплатными, а часть – по подписке, за деньги. Эдакая маркетинговая какашка, которая портит всё настроение.
Несмотря на эту заморочку, Консилиум разошёлся весьма неплохо. Отчет скачивают, пишут вопросы, предлагают новые проверки. Кто-то в виде словесного описания ошибочных ситуаций, некоторые присылают готовые запросы или схемы компоновки. Идет дело, короче.
Чтобы шло ещё быстрее и интереснее, я решил выкинуть ту самую ложку дёгтя. Отныне Консилиум – полностью бесплатный проект, безо всяких подписок. Отчет работает, как и прежде – ползёт в интернет, скачивает подходящие для конфигурации проверки, выполняет их, сохраняет и показывает статистику. Я даже выкинул оттуда авторизацию – зачем она нужна, если можно работать под анонимом?
Так что пользуйтесь на здоровье и в удовольствие. А я продолжу пополнять базу проверок, на сколько хватает сил и времени.
Проблемы
В процессе эксплуатации тандема «Проверка данных» + «Консилиум» наметились несколько проблем. Ну, не то, чтобы критичных, но довольно неудобных. Первая и главная – куда и как добавлять свои массовые проверки? Фильтры на запись объектов – понятно, вставляются в «Проверку данных». А как быть, если человек хочет проверять все документы разом на соответствие каким-то критериям? Или не документы, а регистры или их комбинацию?
Теоретически, в «Проверке данных» есть режим массовой проверки, но он – корявый. Система просто выбирает все объекты одного типа, и поочередно применяет к каждому из них проверку. С точки зрения производительности – так себе решение, классический запрос в цикле. Вероятно, поэтому таким режимом мало кто пользуется.
В итоге реализуется один из трех сценариев. Либо человек создает проверки в виде внешних отчетов или сохраненных запросов в консоли, либо создает какой-то контейнер для хранения проверок, либо вообще на занимается проверками, оставляя качество данных в неуправляемом состоянии.
Но так жить неудобно – приходится смотреть результаты проверок, как минимум, в двух местах – Консилиуме и каком-то своем. Своих проверок, наверняка, больше, они лучше и качественнее, поэтому, когда встает вопрос о выборе «одного окна», Консилиум однозначно проигрывает.
Вторая проблема – в самом Консилиуме, это отсутствие настроек. Доступны всего три – период, организация и включение/выключение проверки вообще.
Если запустить Консилиум только для того, чтобы «позырить», то проблемы нет – все формируется, показывается и кликается. Но в реальной практике быстро возникает потребность в настройке. Хочется отфильтровать номенклатуру, или не видеть помеченные на удаление документы, не считать ошибкой документы прошлых периодов и т.д.
Третья проблема, традиционная для всех подобных инструментов – как обеспечить исправление ошибок? Ну есть отчет, который их показывает. Посмотрел главбух, увидел, ужаснулся, сказал исправить – это Лене, это Гале, это самому программисту. Дальше что? Каждый день заходить и проверять?
Немного спасает статистика – можно смотреть динамику ошибок по дням, например. Но что из этого должна исполнить Лена, а что – Галя?
Ну и четвертая проблема – сама необходимость куда-то заходить, что-то проверять, за кем-то следить. Представьте, что вы установили антивирус, который очень много о себе мнит. Он знает, что у вас появились вирусы, но скажет вам об этом только после того, как вы пороетесь в меню «Пуск», найдете ярлык, запустите приложение, чего-то поднастроите и немного подождёте. Скучно ведь. Раз зайдешь, другой – и бросишь. Поставишь другой антивирус, который сам сообщит, что обнаружил проблему.
Решения
Мне очень захотелось решить обозначенные проблемы. Сначала хотел реализовать всё это в самом Консилиуме, но столкнулся с ограничениями.
Во-первых, Консилиум – внешний отчет, со всеми вытекающими последствиями. Никакого вмешательства в конфигурацию он делать не может.
Во-вторых, Консилиум не может стать расширением, т.к. в конфигурациях с режимами совместимости такие штуки не работают.
В-третьих, пришлось бы реализовать в Консилиуме парочку универсальных механизмов, которые я уже сделал в другом месте. Где?
В Flowcon, разумеется. Надо просто разделить Консилиум на две части, сохранив максимум общего. В первую очередь – базу проверок.
Встроенный Консилиум
Итак, в последнем релизе Flowcon появился встроенный Консилиум. Это буквально два объекта – справочник «Проверки Консилиум» и отчет «Консилиум».
Про отчет рассказывать не буду – он почти полностью повторяет своего бесплатного собрата, только проверки берет из базы, а не из интернета.
А вот справочник интереснее. По сути, это – ваша база проверок. Но составляете вы ее не в одиночку, а вместе со всем миром.
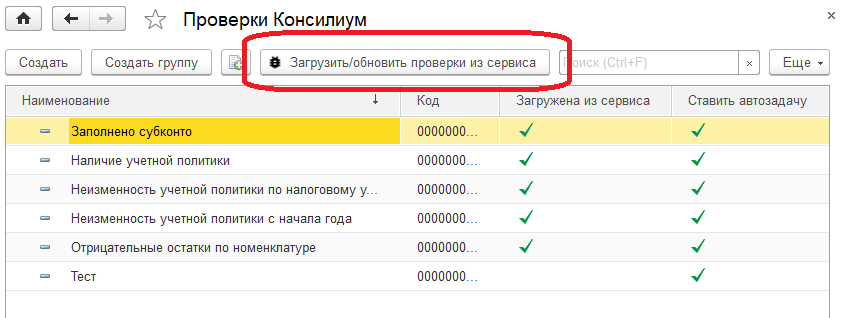
Красным цветом обвел кнопку, которая загружает проверки из интернета. Раньше этот делал сам отчет при выполнении, теперь эти проверки хранятся в вашей базе. Система автоматически определяет, какие новые проверки есть для вашей конфигурации, и загружает их, а изменившиеся – обновляет. Проверки, загруженные из сервиса, помечаются специальным флагом, чтобы вы их случайно не испортили.
Первое, чем можно похвастаться – возможность настройки. Из интернета скачивается схема компоновки, из нее берутся стандартные настройки (поля, отборы, группировки и т.д.), а дальше – дело за вами.
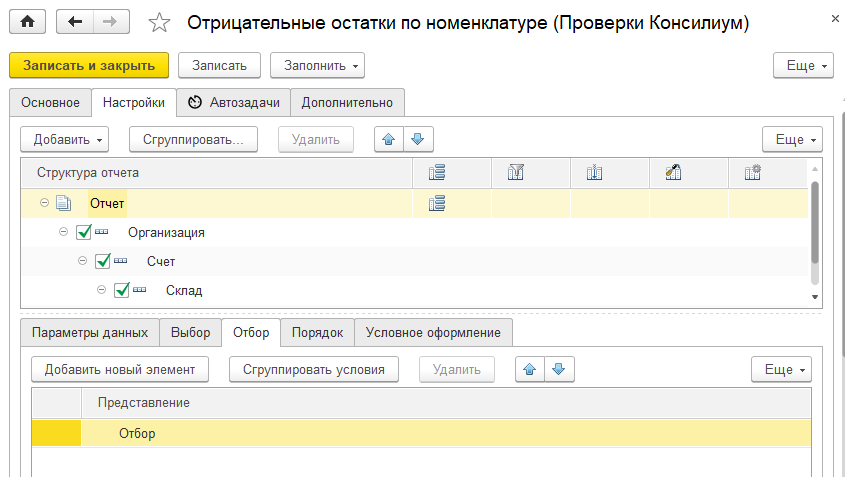
Можете настраивать, как вам угодно, и при выполнении проверки ваши настройки будут учтены.
Вторая приятная мелочь – теперь можно разложить проверки по папкам. В интернете они лежат плоским списком, и загружаются в справочник так же, но вы можете понаделать групп и растолкать по ним проверки. При загрузке/обновлении иерархия не трогается.
Третья фишка - уже совсем не мелочь. Раз проверки теперь – это справочник, то вы можете создавать их сами. В том числе, копируя загруженные из сервиса. Больше не нужны внешние отчеты, обработки, файлы в консолях и непонятные контейнеры. Все проверки лежат в одном месте, с четким разделением на «наши» и «ихние». А выполняются в одном отчете «Консилиум».
Четвертое – как по мне, так чуть ли не самое главное – возможность быстрого создания простых схем компоновки для тех, кому лень или вообще не понятно, что такое «схема компоновки».
Идея взята из «Проверки данных». Там, если помните, достаточно выбрать тип документа или справочника, который хочется проверить, и сразу можно настраивать отборы. Теперь и здесь почти так же.
Появилась в проверках Консилиума такая чудесная кнопочка:
которая открывает маленькое, приятное окошечко:
где мы выбираем нужный тип объекта для проверки
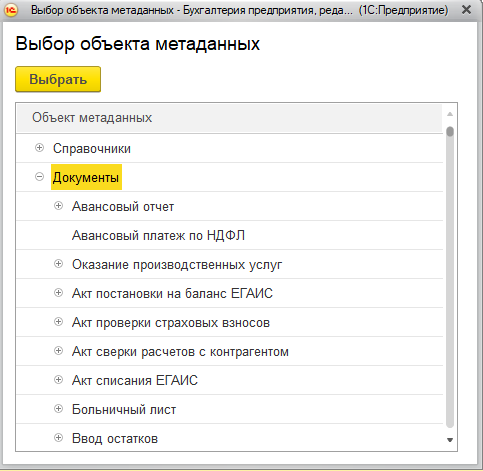
и схема компоновки создаётся сама, а нам остается лишь настроить нужные отборы, сказав Консилиуму, какие объекты считать ошибочными. Справится не только программист, но и продвинутый пользователь. Собственно, как они справляются с «Проверкой данных».
Ну, а кому хочется делать схемы руками – ради Бога, кнопка вызова редактора есть, развлекайтесь.
Теперь вы можете собрать все свои проверки в одном месте, объединив их с нашими.
Консилиум + Автозадачи
Во-первых – да, в последнем релизе Flowcon появились автозадачи. Пока – почти такие же, какими вы их видели раньше. Но с одной очень прикольной фишкой, о которой расскажу чуть ниже.
Идея объединить проверку качества данных с автозадачами – не моя. Ее как-то высказал один толковый программист на переговорах по распространению Консилиума, за что ему большое спасибо.
Итак, всё просто. Автозадачи, если помните, это просто результат выполнения схемы компоновки, которая говорит, что надо сделать – согласовать какой-то заказ, разместить продукцию у поставщика, добавить пользователя в базу, поздравить клиента и т.д. Проверка – это просто результат выполнения схемы компоновки, которая говорит, какие есть ошибки, но не говорит, что и кому с ними надо делать.
Получается, инструменты очень похожи и стоят на одном базисе – выполнении схемы компоновки. Дальше сами догадываетесь.
Приделываем к проверке Консилиума небольшую логику адресации, как в автозадачах:
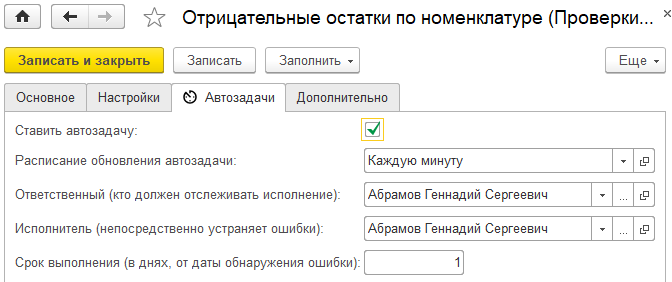
Собственно, всё. Теперь с периодичностью, указанной в поле «Расписание», проверка будет выполняться и, если есть ошибки, создастся соответствующая автозадача.
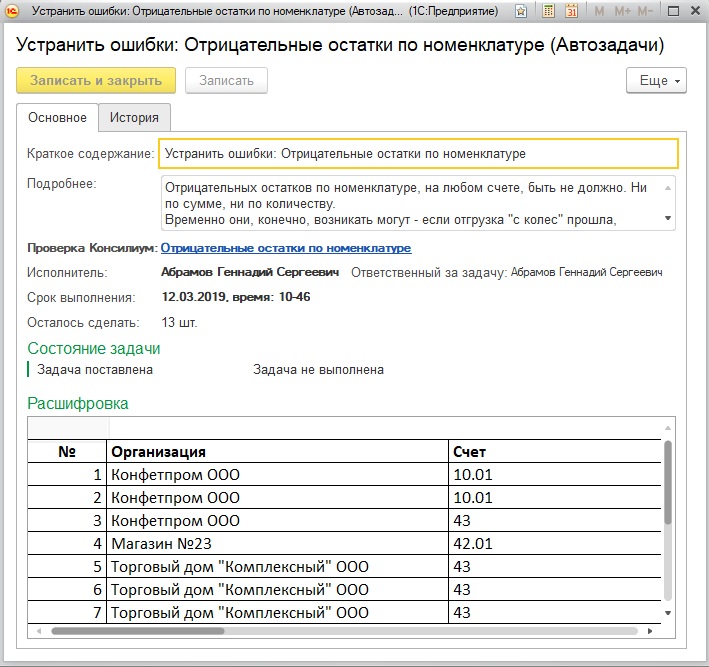
В расшифровке автозадачи будет вся необходимая информация для ее решения - та же, которую выдает Консилиум, только в плоском виде, без группировок.
Но главное – это ведь автозадача! Когда человек исправит часть ошибок, она пересчитается и уменьшится, а если упрётся и устранит все проблемы – автозадача закроется. Сюда же добавьте принцип Айсберг, лежащий в основе автозадач – будут видны и дата появления ошибок, и реальный срок устранения, и история убывания остатка.
При разработке был большой соблазн сделать неудобно – просто как-нибудь соединить автозадачи с проверками, через ссылку, и заставить пользователя мучиться с настройкой не самого простого справочника «Параметры автозадач». Но этот бред, конечно же, я отбросил – там ведь потребовалось бы дублирование схемы компоновки в двух местах.
Поэтому я просто доработал процедуры формирования автозадач, чтобы они брали информацию из двух источников. Поэтому с настройкой автозадач под проверки Консилиума теперь справится пользователь. Единственное непонятное поле – расписание.
Расписания
Расписание выполнения регл.задания в виде справочника? Баг? Нет, фича.
Я много лет сам пользовался автозадачами, переводя на них большинство рутинных и понятных процессов предприятия. Всё мне в них нравилось, кроме одного – формирования всех автозадач разом, в рамках одной сессии регл.задания.
Во-первых, это плохо по производительности. Когда автозадач много, они могут формироваться несколько минут. Значит, нужно всё время расширять расписание – раз в минуту уже не поставишь, регл.задание никогда не завершится.
Во-вторых, автозадачи объективно надо обновлять с разной частотой, которая зависит от частоты изменения соответствующих данных.
Вот есть, например, автозадача вроде «Указать у пользователя физ.лицо» (чтобы запросом получать его контактную информацию, должность и т.д.). Новые пользователи и физ.лица появляются не часто – раз в неделю, а то и раз в квартал. Кажется, было бы достаточно актуализировать автозадачу раз в день.
А есть автозадачи вроде «Согласовать заявку на оплату». Некоторые платежи могут подождать, но есть и такие, что не терпят отлагательства. Значит, неплохо бы их раз в несколько минут обновлять.
А регл.задание-то одно, и расписание у него одно. Вот она и мучилась, пересчитывая всё подряд каждые несколько минут.
Можно, конечно, создать несколько экземпляров регл.задания, но мне такой подход не нравится. Эти демоны не отличаются стабильностью и предсказуемостью, и я каждый раз испытываю трепет, заходя в консоль заданий.
Решение нашлось неожиданно. У объекта типа «РасписаниеРегламентногоЗадания», оказывается, есть такой метод – ТребуетсяВыполнение. Заметьте – у расписания, а не у регл.задания. Расписание, как объект, может существовать само по себе, даже если никакого регл.задания нет и в помине. К тому же, оно сериализуется.
Ну а дальше всё просто. Создал справочник «Расписания», который хранит эти самые расписания. Создаем, настраиваем, записываем, используем.
Еще раз обращаю внимание – без привязки к регл.заданиям. Одно и то же расписание может приняться в автозадачах, проверках Консилиума и, вообще, где угодно.
Дальше – привязка к конкретным объектам. Мы ведь хотим, чтобы разные автозадачи и проверки выполнялись с разной частотой? Не вопрос – просто добавил реквизит в соответствующие справочники. На скриншоте выше показал расписание в проверке Консилиума, а вот оно же в «Параметрах автозадач»:
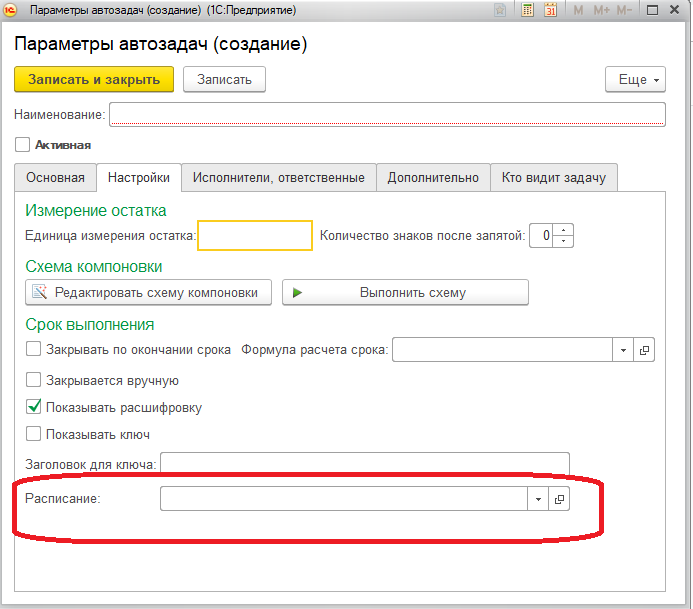
Дальше всё просто. Есть одно, старое регл.задание «АвтоЗадачи». Ставим ему выполнение через короткие промежутки времени – например, раз в минуту. Только теперь оно не сразу автозадачи формирует, а сначала проверяет, кого пора обрабатывать, а кто может еще подождать. Тем самым методом ТребуетсяВыполнение.
Берет каждую пару «Проверка Консилиум» + «Раписание» и «Параметры автозадач» + «Расписание», смотрит дату последнего выполнения для этой пары, и принимает решение. Если рано – обходит стороной. Если пора – делает, что нужно, и запоминает дату выполнения.
Ну разве не прелесть?
Резюме
Теперь победа над ошибками стала на шаг ближе. Хотя, абсолютной, разумеется, она не будет. Есть ведь еще и вредители, которые делают ошибки сознательно.
Но надежда есть. Главная – на то, что чуть больше людей станут следить за качеством данных, если слежение станет проще, удобнее и интереснее. Собственно, ради этого и старался.
Знаешь вопиющую ошибку, понятную с первого взгляда и никак не допустимую? Не дай ей появиться на свет, настрой фильтр в «Проверке данных».
Знаешь ошибку, которую сразу не разглядишь, потому что она создается комбинацией разных данных? Да, она появится, как тихий паразит, надеясь, что никто не заметит ее появления. Но ты не дай ей такого шанса – настрой проверку в Консилиуме, и не забудь подключить автозадачу. Узнаешь о появлении ошибки в тот же день, или даже минуту.
Не знаешь, какие еще неприятности могут таиться в сложной, но такой интересной типовой конфигурации? Загрузи проверки из сервиса, они помогут найти самых экзотических червяков и букашек, о которых ты, возможно, и не подозревал.
Есть еще несколько идей по управлению качеством данных, так что ждите новых релизов Flowcon.
Релиз от 28.12.2018 г.
Управление задачами
В релиз вошла первая версия управления задачами.
Реализовано далеко не все, что хочется, но уже сейчас там больше полезного, чем во всех моих прежних решениях.
Проверка данных
Добавлен функционал использования реквизитов проверяемого объекта в тексте сообщений.
Когда объект - документ или справочник - не проходит проверку, выдается сообщение. Текст этого сообщения пишет разработчик проверки.
Раньше он мог написать только буквы, которые, один к одному, выводятся пользователю.
Теперь он может написать текст сообщения, используя реквизиты объекта. Например, "Вы зря поставили номенклатуре "Вал распределительный" единицу измерения "кг". Так не бывает. Поставьте "шт" и не отвлекайте серьезных людей от работы".
Если проверка сложная, с использованием схем компоновки, то в текст сообщения можно вставлять любые поля, которые вернул запрос.
Например, "Не получится отгрузить 10 шт номенклатуры "Валенки", потому что на складе "Основной" осталось лишь 5 шт. И вообще, уважаемый господин Федоров (администратор), больно часто вы на ошибку натыкаетесь. Смотрите сначала отчет с остатками, потом вбивайте документы".
Рабочий стол
Исправлен ряд ошибок, в основном – по совместимости с платформой 8.2.
Релиз от 07.01.2019 г.
Фиксация данных
В конфигурацию включен инструмент "Фиксация данных", автоматизирующий отслеживание изменений в данных прошлых периодах.
Управление компетенциями
Появился функционал управления компетенциями.
Регулярный менеджмент
Появилась первая очередь функциональности регулярного менеджмента - "Вопросы для контроля". Описание будет чуть позже.
Ошибки
Исправлено несколько ошибок, обнаруженных нами и пользователям.
Автозадачи
В состав конфигурации Flowcon вошли Автозадачи - проверенный временем инструмент для наведения порядка в процессах.
Встроенный Консилиум
Улучшенная, дополненная и расширенная версия бесплатного Консилиума. Теперь ни одна ошибка не спасётся.
Ошибки
Устранён ряд ошибок, в основном - по рабочим столам.
Единая конфигурация начала превращаться в комплект - несколько изолированных решений. Подсистемы будут отделяться от единой конфигурации и превращаться в расширения. Первой "расширилась" Проверка данных.
Более подробная информация в отдельной публикации - //infostart.ru/public/1433602/
Управление проектами и продуктами
Задачи без проектов - скучно и бесцельно. Поэтому делаем управление проектами и продуктами. С методикой использования, чтобы продукты создавались быстрее, а проекты заканчивались в срок.
Планирование закупок
По нашим наблюдениям, проблемы из-за несвоевременных закупок и дефицитов есть примерно у всех предприятий. Поэтому делаем универсальное решение по управлению закупками и дефицитами, учитывающее любые процессы клиента, особенности учета и автоматизации.
Мониторинг показателей
Простая и эффективная система расчета, хранения и мониторинга показателей деятельности компании.
Анализ процессов
Процессы есть везде, даже если не нарисованы и не автоматизированы объектами типа "Бизнес-процесс". Измерить их, проанализировать и оптимизировать можно и без тяжеловесной автоматизации. На то и нужна подсистема "Анализ процессов".
Регулярный менеджмент
Полезные инструменты повышения эффективности ежедневной, рутинной работы руководителя.
Красивые отчеты
Создание маленьких, красивых, приятных глазу руководителя отчетов, содержащих разнородные данные в одной форме. Такие сейчас люди в экселе рисуют.
Информатор
Автоматическое информирование о событиях в системе, в удобном и наглядном виде. Пришли деньги за твой заказ - узнаешь через минуту.
Автоопределитель
Технический инструмент, облегчающий ввод документов и справочников в зависимости от контекста. Половина реквизитов всегда заполняются одинаковыми значениями, еще треть - зависят от контекста. Так чего их вводить каждый раз?
Управление потоками
Методика и автоматизация сбалансированной деятельности и развития - команды, отдела, предприятия, холдинга.
Data cast
Не знаю, получится или нет. Серьезная вещь. Может повлиять на работу целых отраслей промышленности. Не буду рассказывать, боюсь сглазить.
ICE (Incredible Concolidation Ever)
Инструмент быстрой организации консолидации между базами холдинга. Раз - и готово, директор видит, кто сколько продал.
MDM
Абстрактные инструменты для организации совместного редактирования справочной информации в разных базах 1С.
Расчет иерархических структур
Главное назначение - расчет структуры затрат, с учетом всех переделов, складов и т.д. Абстрактно, для любой конфигурации, с учетом переходящих остатков.
Распределение затрат
Расчет управленческой себестоимости по нескольким настраиваемым сценариям, с учетом всех особенностей конкретного предприятия.