





















Вступление
В наше время новые LLM выпускаются чуть ли не каждую неделю. Дообученных моделей ещё больше.
В какой-то момент мне захотелось тоже попробовать чему-то дообучить LLM, и под эту задачу хорошо подошёл 1С Элемент. Из-за его новизны с ним плохо работают даже топовые LLM вроде Sonnet/Opus, GPT или Gemini.
Я решил попробовать подготовить датасет, обучить какую-нибудь LLM базовым знаниям Элемента и посмотреть, что получится. Собственно, результат доступен на hugging face.
Базовая модель
За базовую модель была взята Qwen3 4B Instruct 2507.
Почему 4B?
1. С текущим уровнем задач в датасете всё равно ничего нормального не сделаешь. Для первого теста, чтобы поиграться, её хватает.
2. С 4B проще в плане железа. Я могу её легко протестить на своём старом ноуте, и при обучении выходит достаточно дёшево.
Почему Instruct, а не Thinking?
Потому что для Thinking сложнее делать датасет из-за необходимости добавлять кроме самого вывода, ещё <thinking>...</thinking>-часть, которую сейчас делать не хочется.
Датасет
В датасете около 16 000 инструкций.
Примерно 12 000 инструкций на решение небольших задач на базовые темы программирования и 4 000 задач на объяснение кода (зеркальные от первых).
Из 12 000 задач где-то для 2 000 условия сгенерированы мной, а для остальных - взяты из интернета.
Темы задач самые базовые: работа с примитивными типами, условные операторы, циклы, работа с коллекциями.
В датасете нет документации. Специально, чтобы не было претензий на тему авторских прав.
Инференс
Запуск
Подключать её в Cursor или его аналоги я даже не пробовал.
Если интересно посмотреть на её работу, то проще это сделать в LM Studio. В ней можно скачать модель, запустить и сразу же початиться.
Для скачивания в строке поиска нужно ввести "soratnik", и модель найдётся:

Если у вас слабая видеокарта, то LM Studio позволяет выполнить всё на CPU и RAM. Будет медленно, но, чтобы поиграться с моделью размером 4B, процессора хватит.
Для этого, при загрузке модели, нужно указать 0 в поле "Передача на GPU":

Температуру лучше установить где-то около 0.1
Чат
LM Studio не отображает пробельные символы в начале строк, и код из-за этого выглядит нечитабельно. Но при копировании в буфер обмена, всё копируется правильно, с отступами.

Бенчмарк
Помимо создания своих и дообучения чужих языковых моделей, многие ещё заняты созданием бенчмарков для сравнения этих моделей. Но для 1С Элемент, конечно же, их нет. Поэтому придётся сравнивать работу моделей с 1С Элемент самостоятельно.
Из-за особенностей датасета, Соратник, пока, в обычном запросе не добавляет "метод Скрипт()", так что придётся простить ему это и добавлять эту часть вручную.
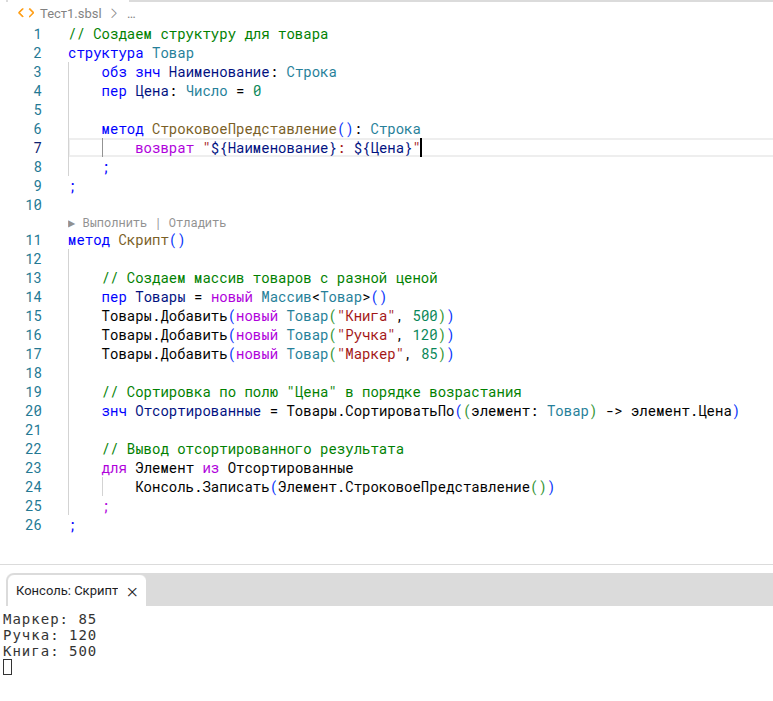
Возьмём несколько простых задач:
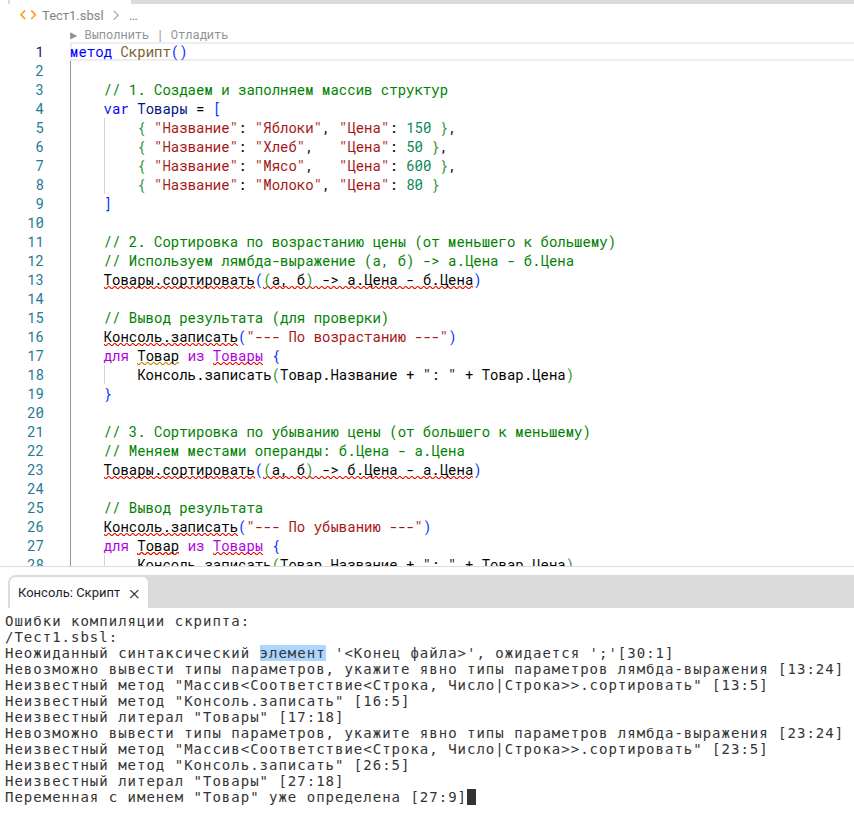
1. Промт:
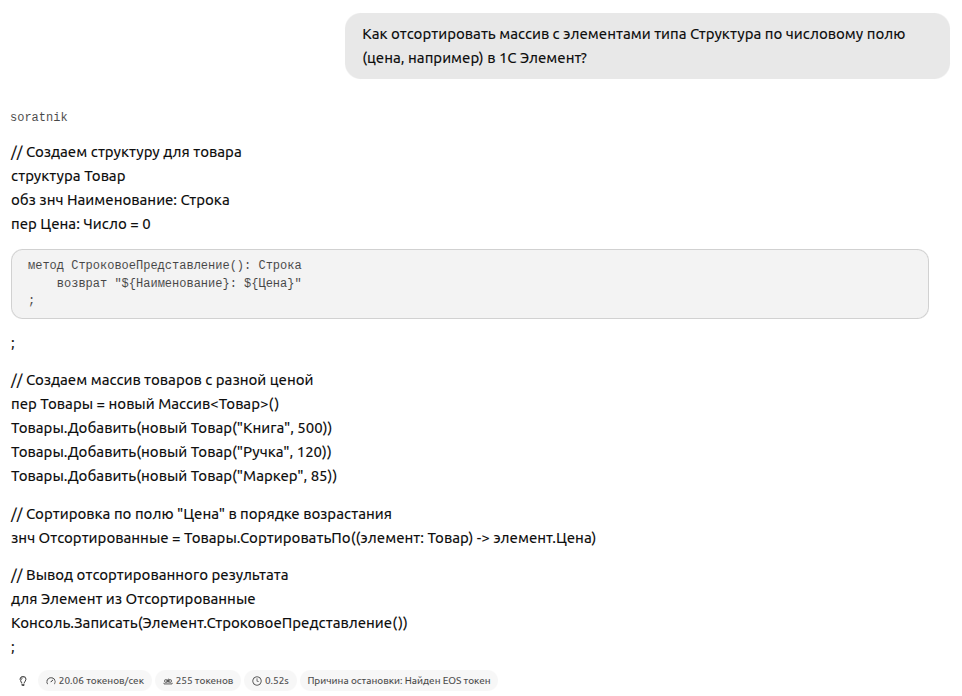
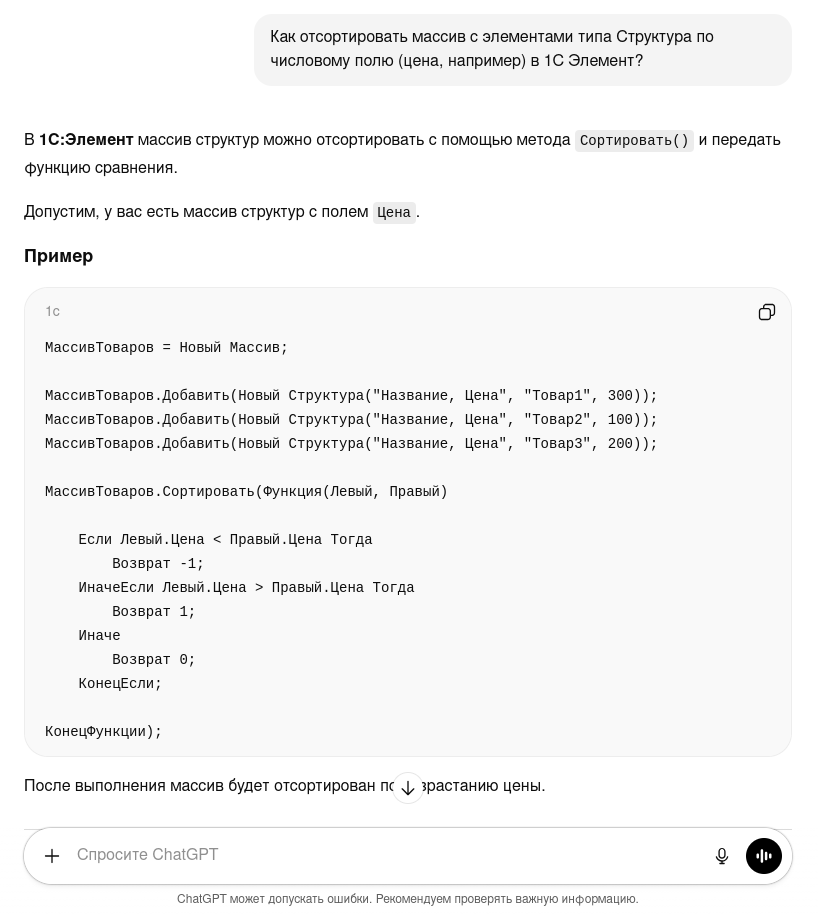
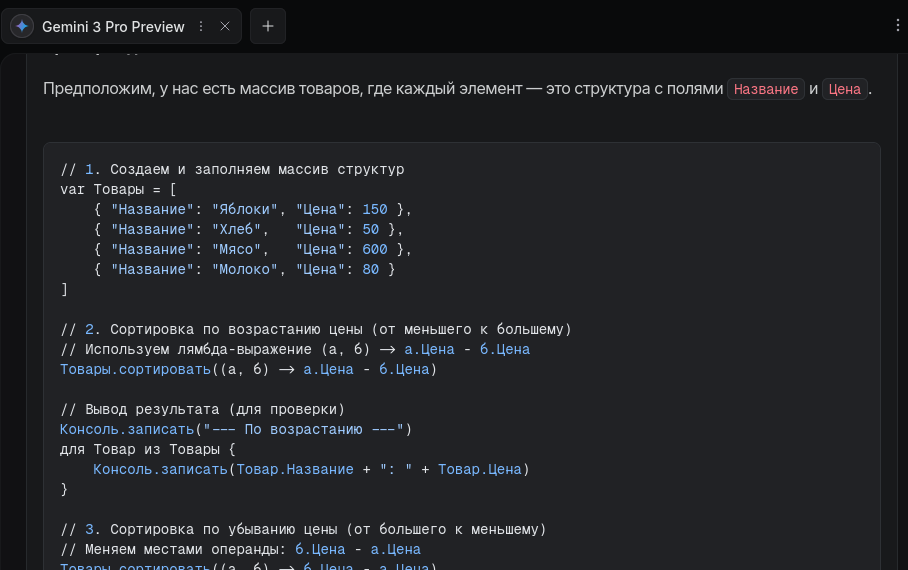
Как отсортировать массив с элементами типа Структура по числовому полю (цена, например) в 1С Элемент?
Соратник справился.
ChatGPT и Sonnet 4.5 не справились.
Код от Gemini был больше похож на 1С Элемент. Как и у Соратника, код был без "метод Скрипт()", его я также добавил. Но в итоге, код получился совсем нерабочий.
2. Промт:
напиши программу на 1С Элемент, на каждом этапе вывода добавляй вывод заголовка:
1) программа спрашивает у пользователя строку
2) вычисляет её длину и количество слов в ней
3) выводит слова в обратном порядке
4) определяет уникальные слова из исходной строки и сортирует их по убыванию длины
5) выводит список слов, содержащих букву "а"
Соратник технически справился. Size он придумал, так как он не знает английского диалекта Элемента. Но код оказался рабочим.
Остальные LLM повторили свои прошлые результаты. Мне уже стало лень всё это копировать сюда, извините)
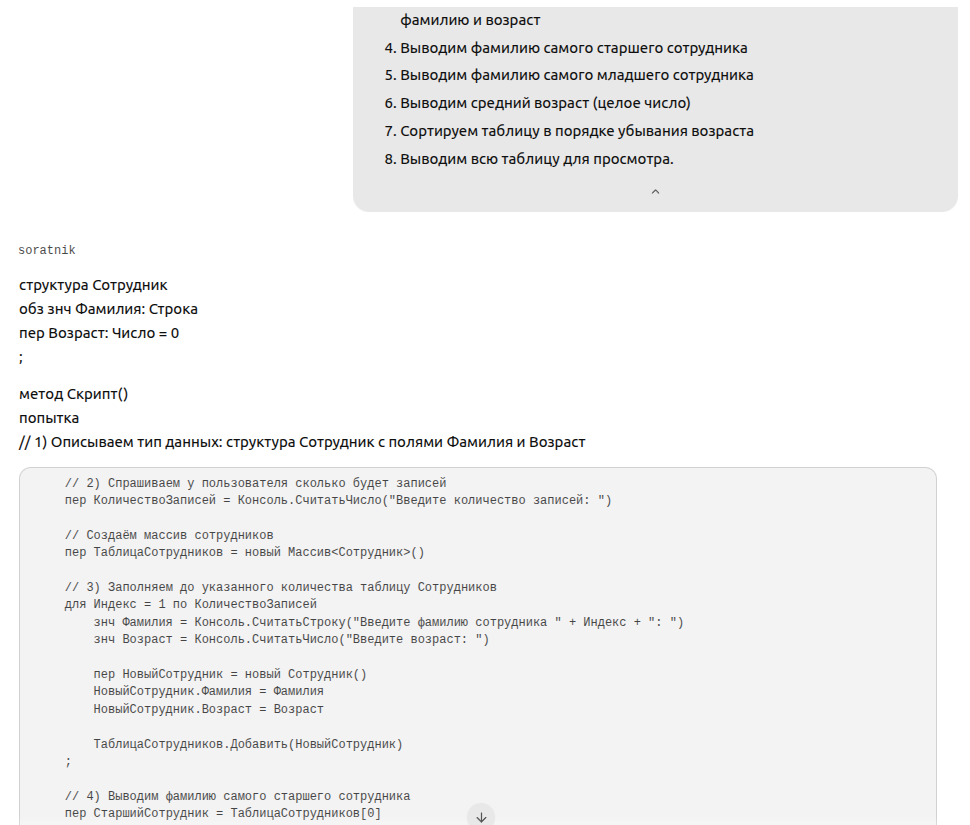
3. Промт:
допиши программу на 1С Элемент:
метод Скрипт();
1) Описываем тип данных: структура Сотрудник с полями Фамилия и Возраст
2) Спрашиваем у пользователя сколько будет записей
3) Заполняем до указанного количества таблицу Сотрудников (массив элементов типа Сотрудник), для чего спрашиваем у пользователя фамилию и возраст
4) Выводим фамилию самого старшего сотрудника
5) Выводим фамилию самого младшего сотрудника
6) Выводим средний возраст (целое число)
7) Сортируем таблицу в порядке убывания возраста
8) Выводим всю таблицу для просмотра.
Тут я сразу добавил "метод Скрипт()", чтобы не дописывать после. Соратник вывел немного лишнего и накосячил с инициализацией структуры (поправил вручную во 2 строке). Но, в целом, код рабочий, думаю, можно засчитать)
Остальные LLM отработали как и в прошлые разы.
Итоги:
С небольшой натяжкой засчитаем Соратнику 3 балла и признаем SOTA-моделью в программировании на 1С Элемент)
На самом деле, конечно, модель много ошибается и придумывает. Но всё-таки, другие модели без справки не могут написать и этого.
Что дальше?
Планирую посмотреть, с чем модель косячит больше всего, и дополнить датасет задачами на эту тему.
Дальше, увеличить количество базовых задач и дополнить датасет задачами по работе с XML, JSON, HTTP-запросами, файлами, серверами 1С - то есть, примерно, задачи уровня 1С Элемент Скрипт. Во "взрослый" 1С Элемент, конечно, смысла лезть нет, я это не осилю.
____________________________________________________________________
Возможно, вам будут интересны мои предыдущие публикации:
1. Редактор кода для "1С:Документооборот 3"
2. Проверка запросов на лишнюю выборку и разыменование полей составного типа
3. Редактор форм в режиме предприятия
Вступайте в нашу телеграмм-группу Инфостарт