










1С-команда в режиме “Давай-давай”: почему всё держится на героях и как из этого выйти

В 1С-командах часто всё держится на героизме: задачи прилетают в личку, релизы горят, документации нет, техдолг растет, а один сильный разработчик знает половину системы. Разбираем стадию Go-Go по Адизесу на примерах 1С-разработки и показываем, как выйти из хаоса без превращения команды в бюрократию.
Заметки ОПИ: использование расширенного вызова

Небольшая заметка об использовании одного из новых механизмов Открытого пакета интеграций под названием Расширенный вызов. О том, зачем он нужен и как его использовать
Консоль HTTP-запросов для управляемых форм
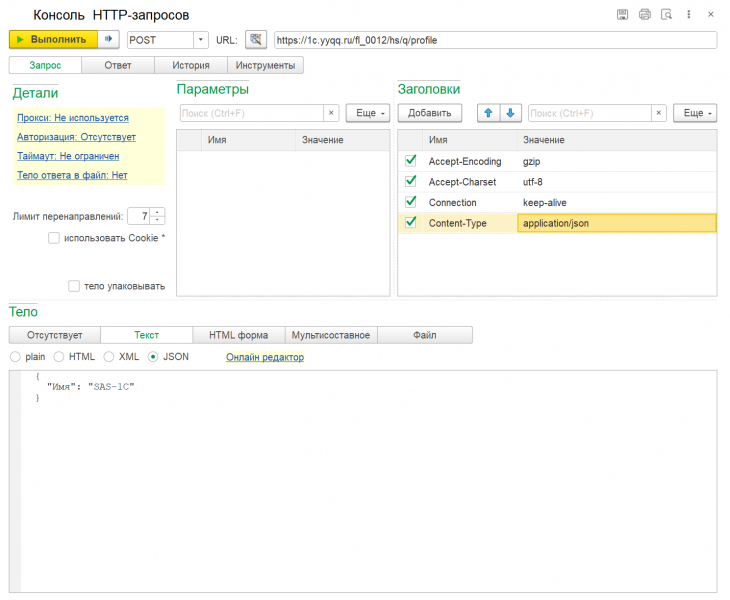
Когда нет под рукой postman, есть консоль HTTP-запросов. Собрав лучшие идеи, представляю свое видение удобной обработки для выполнения простых http-запросов. Используйте для изучения публичных API или тестирования своих сервисов.
17 июня приглашаем на вебинар по 1С:РКЛ: как выбрать подрядчика

Как оценить качество поддержки по 1С:РКЛ до того, как система столкнется с критическим сбоем? Разберем критерии выбора подрядчика, реальные кейсы аудита и типовые проблемы крупных 1С-систем.
OneBase за десять дней: управляемые формы, 14 языков интерфейса, точные деньги и инструменты для разработки с ИИ

За десять дней после релиза OneBase получила полноценные управляемые формы, локализацию интерфейса на 14 языков, точную денежную арифметику на decimal, систему ролей и прав, новый REST API и набор CLI-инструментов для разработки совместно с ИИ. Разбираю ключевые изменения платформы, показываю новые возможности и делюсь результатами одной из самых насыщенных недель развития проекта.







![[1С + ИИ] ИИ сделал внешнюю обработку за 19 минут. За сколько сделаешь ты?](/upload/iblock/d04/d048ac8f386283878352a94df609efdb.jpg)

Заметки ОПИ: использование расширенного вызова
Небольшая заметка об использовании одного из новых механизмов Открытого пакета интеграций под названием Расширенный вызов. О том, зачем он нужен и как его использовать
Консоль HTTP-запросов для управляемых форм
Когда нет под рукой postman, есть консоль HTTP-запросов. Собрав лучшие идеи, представляю свое видение удобной обработки для выполнения простых http-запросов. Используйте для изучения публичных API или тестирования своих сервисов.
OneBase за десять дней: управляемые формы, 14 языков интерфейса, точные деньги и инструменты для разработки с ИИ
За десять дней после релиза OneBase получила полноценные управляемые формы, локализацию интерфейса на 14 языков, точную денежную арифметику на decimal, систему ролей и прав, новый REST API и набор CLI-инструментов для разработки совместно с ИИ. Разбираю ключевые изменения платформы, показываю новые возможности и делюсь результатами одной из самых насыщенных недель развития проекта.
Инвентаризация доработок 1С перед большим обновлением: как ИИ помогает разобраться в отчетах, обработках и расширениях
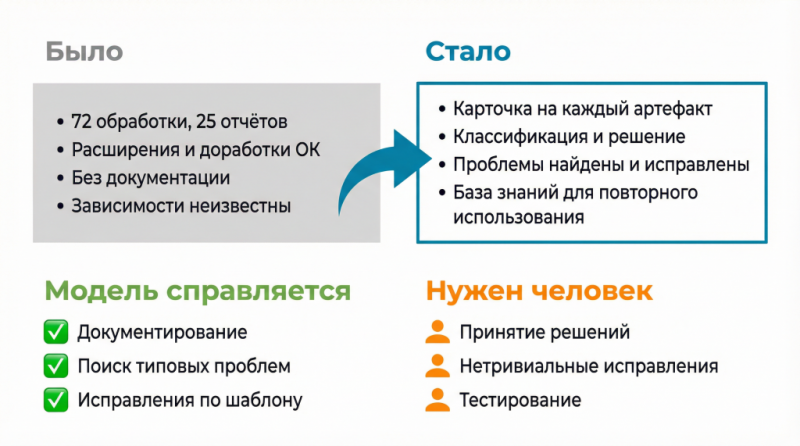
Когда доработанную 1С не обновляли годами, начинать приходится не с переноса кода, а с разбора того, что вообще накопилось в базе. Там могут быть десятки обработок, расширения, правки типовых объектов, а документации либо нет, либо она давно не актуальна. На примере реального обновления разбираем, как кодовые агенты, MCP-серверы и языковые модели помогают навести порядок в доработках, собрать план миграции, понять, где при переносе будут проблемы, и автоматизировать часть исправлений.
1Craft[Code] — платформа для обучения программированию на 1С
![1Craft[Code] — платформа для обучения программированию на 1С](/upload/iblock/ec4/ec4e8ecd86f47c2b6f4260c0b771a2f5.png)
Платформа 1Craft[Code] — это, по сути, профессиональный тренажёр для тех, кто хочет наконец-то перестать бояться кода 1С и начать писать его уверенно. Здесь нет скучной теории — сразу практика, сразу дело.
1С-команда в режиме “Давай-давай”: почему всё держится на героях и как из этого выйти
В 1С-командах часто всё держится на героизме: задачи прилетают в личку, релизы горят, документации нет, техдолг растет, а один сильный разработчик знает половину системы. Разбираем стадию Go-Go по Адизесу на примерах 1С-разработки и показываем, как выйти из хаоса без превращения команды в бюрократию.
Эффективные фреймворки бизнес-аналитиков, которыми еще не пользуются аналитики 1С

Почему на проектах внедрения ERP-систем возникает разрыв между бизнесом и разработкой – и какую роль в его закрытии играет бизнес-аналитик? Покажем фреймворки, которые помогают точнее выявлять проблемы, проектировать пользовательские сценарии, приоритезировать требования, проверять гипотезы и снижать риски сложных внедрений 1С. Объясним, как CATWOE, CJM, GA, HADI, MECE, MoSCoW, SAFe, UC и ТРИЗ могут быть полезны аналитикам 1С не как догма, а как практические инструменты для работы с бизнес-задачами.
Идеальное ТЗ для разработчика

Каким должно быть техническое задание, чтобы разработчик понял задачу так же, как аналитик, тестировщик и бизнес? Покажем, почему требованиям нужны обоснование, конкретные формулировки по SMART, единый командный контекст и визуальная опора в виде схем, макетов и глоссария. Объясним, как недосказанность, размытые формулировки и отсутствие коммуникации превращают даже хорошо оформленное ТЗ в источник ошибок. Отдельно поговорим о soft skills: регулярных встречах, синках, воркшопах и умении вовремя проговорить нюансы с исполнителями.
Культура бесконечных созвонов

Современный рабочий день сотрудника любой крупной компании, в том числе, в сфере IT, все чаще превращается в цепочку созвонов, летучек и бесконечных онлайн-обсуждений. Команды постоянно на связи, календари заполнены, коммуникации стало больше – но ощущение реальной продуктивности почему-то исчезает. Почему компании начинают «съедать» собственное рабочее время, как культура постоянных синхронизаций влияет на мышление сотрудников и можно ли сохранить баланс между регулярным взаимодействием с коллегами и глубокой работой? Автор разбирается в этих вопросах.
Мифы и реальность перехода с иностранного ПО

Быстрый переход с иностранного ПО на российские решения редко бывает просто заменой системы – особенно когда речь идет о МСФО, ежемесячной отчетности и отключении от зарубежной инфраструктуры в жесткий срок. На примере проекта перехода с Oracle JD Edwards и Harmony reports на 1С разбираем проблемы, с которыми сталкивается команда: неполные данные, отсутствие доступа к исходной системе, скрытые доработки, накопленные ошибки учета и постоянный поток новых требований. Объясняем, почему кризисный подход не дает гарантий результата и чем полноценный переход отличается от установки нового программного обеспечения. Отдельно рассматриваем правильную методологию замещения: детальное обследование, стратегию перехода, методологическую подготовку и поэтапную автоматизацию.
В «Сервере ККМ» добавлена поддержка ТС ПиОТ для работы с кассами из 1С

В решении «Сервер ККМ» добавлена поддержка ТС ПиОТ. Теперь пользователи могут подключать кассовое оборудование через драйвер «Торговый баланс М» и использовать его в сценариях фискализации чеков из 1С.
Вебинары от Инфостарта по автоматизации 1С в июне

В июне Инфостарт проведет серию бесплатных вебинаров по автоматизации 1С: отчетность, управление проектами, корпоративное сопровождение и обучение сотрудников. Участники получат практические рекомендации и чек-листы от экспертов.
Майский ТОП-5 Инфостарт Маркетплейса: новые инструменты для удобной работы в 1С

Читайте майскую подборку Маркетплейса: в ней собраны решения для тех, кто работает с 1С каждый день и хочет проще разбираться в данных, анализировать состояние базы, собирать отчетность и получать больше пользы от привычных инструментов в системе 1С.
Infostart PrintWizard 2026.2: условия вывода без кода, API для областей и сохранение параметров печати

Основные изменения затронули механизм условного вывода областей, программный API работы с ними и механизм управления сохраненными настройками печати для разных макетов – включая их изменение, перенос между пользователями и удаление.
Infostart Toolkit Air: поддержка 1С 8.5, новые инструменты и обновленное лицензирование

Мы подготовили крупное обновление Infostart Toolkit Air – версию, ориентированную на работу с новой платформой 1С:Предприятие 8.5, более удобный интерфейс и расширение повседневных инструментов разработчика.
Готовый фундамент для 1С: как БСП экономит сотни часов разработки

БСП помогает 1С-команде быстрее перейти от технической рутины к бизнес-логике клиента. В материале считаем экономию по ключевым подсистемам, объясняем их пользу для сопровождения и показываем, почему стандартный фундамент выгоднее самописных решений.
Июньские курсы Инфостарт Обучения для аналитиков и программистов 1С
В программе июньских курсов по 1С – знакомство с платформой, погружение в программирование и инструменты, которые ускоряют разработку и помогают проще работать над проектами.
1С-аналитик: чем занимается, сколько зарабатывает и как им стать

1С-аналитик помогает бизнесу внедрять и развивать системы на базе «1С»: собирает требования, ставит задачи разработчикам, настраивает решения и поддерживает пользователей. Рассказываем, чем он занимается, сколько зарабатывает и как войти в профессию.
Моделирование угроз безопасности ПДн в рамках 152-ФЗ в типовых конфигурациях 1С

Утечка данных, вирусная атака или ошибки сотрудников могут привести к серьезным последствиям для бизнеса. Рассказываем, как определить наиболее опасные угрозы для ИСПДн и выбрать меры защиты. Больше о защите ПДн – на курсе Инфостарт Обучения.
Почему ИИ не заменит аналитика в написании технического задания

ИИ для большинства компаний уже стал рабочим инструментом. Он помогает отвечать клиентам, обрабатывать данные, искать ошибки и ускорять рутину. Поэтому все чаще звучит вопрос: сможет ли он заменить специалистов, в том числе аналитика 1С?
7 неочевидных советов ИТ-руководителю: что не пишут в учебниках по менеджменту

Управление ИТ – это не только планы, сроки и контроль. Иногда сильнее работают вещи, о которых редко говорят вслух: умение делегировать ответственность, признавать ошибки, убирать лишнее из календаря и не тащить все на себе.
Приглашаем спикеров в секцию «Приемы и практики разработки» на INFOSTART TECH EVENT 2026

На INFOSTART TECH EVENT 2026 также уже идет прием заявок на доклады. В секции «Приемы и практики разработки» ждем практический опыт, который помогает разработчикам быстрее, надежнее и осознаннее решать задачи в проектах.
Приглашаем спикеров в секцию «Прикладные компетенции аналитика» на INFOSTART A&PM EVENT 2026

Идет прием заявок на доклады на INFOSTART A&PM EVENT 2026. В секции «Прикладные компетенции аналитика» мы ждем выступления о практиках, инструментах и кейсах, которые помогают аналитикам решать реальные задачи в проектах.
Как сократить ИТ-бюджет с помощью ИИ: приглашаем ИТ-руководителей поделиться реальным опытом на INFOSTART CIO CAMP 2026

ИИ уже перестал быть экспериментом. Но где он действительно помогает экономить деньги? На CIO CAMP 2026 ИТ-руководители обсудят реальные кейсы, цифры, выводы и ошибки внедрения искусственного интеллекта.
Почему CIO ошибаются в решениях: четыре когнитивные ловушки и способы их обойти

ИТ-руководитель каждый день принимает решения о людях, проектах, подрядчиках и технологиях. Но даже опыт, данные и аналитика не защищают от когнитивных ловушек. Разбираем, как они влияют на CIO и как снижать риск ошибок в ИТ-управлении на практике.
Вебинары от Инфостарта по автоматизации 1С в июне
В июне Инфостарт проведет серию бесплатных вебинаров по автоматизации 1С: отчетность, управление проектами, корпоративное сопровождение и обучение сотрудников. Участники получат практические рекомендации и чек-листы от экспертов.
СПОТ с 1 июня 2026 года: как подготовиться к новым правилам ввоза товаров из ЕАЭС

С 1 июня для импортеров из стран ЕАЭС действуют новые правила: до ввоза автотранспортом нужно оформить ДОПП, внести обеспечительный платеж и получить QR-код ФНС. На вебинаре разберем требования, работу со СПОТ и реализацию новых правил в 1С.
Контроль и подписание отчетности по нескольким организациям в веб-интерфейсе 1С

10 июня в 11:00 (МСК) на вебинаре покажем, как контролировать и подписывать отчетность по нескольким организациям в веб-интерфейсе 1С: видеть сроки, требования ФНС и ЕНС в одном окне, работать удаленно и снижать риск штрафов.
С 15 мая 1С:ДиректБанк будет работать со Сбербанком через Sber API

Для работы со Сбербанком сервис 1С:ДиректБанк переходит на новую технологию Sber API. Чтобы клиенты Сбера могли отправлять платежи и загружать выписки прямо из учетной системы, им потребуется обновить конфигурацию и внести изменения в настройки.
Вебинар по работе с ЭПД: отвечаем на ваши вопросы

Как работать с ЭПД без интернета, кто оформляет документы и когда они не нужны – отвечаем на ключевые вопросы участников вебинара. Не нашли ответ на свой вопрос – оставляйте заявку на консультацию или посмотрите запись онлайн-встречи.
Почему обновление железа – часть эксплуатации 1С, а не прихоть админов

1С тормозит не всегда из-за кода. Иногда причина в инфраструктуре: база растет, нагрузка меняется, а серверы и диски остаются прежними. Объясняем, почему обновление железа — часть эксплуатации 1С и как планировать до того, как риски станут критичными.
Вебинары от Инфостарта по автоматизации 1С в июне
В июне Инфостарт проведет серию бесплатных вебинаров по автоматизации 1С: отчетность, управление проектами, корпоративное сопровождение и обучение сотрудников. Участники получат практические рекомендации и чек-листы от экспертов.
17 июня приглашаем на вебинар по 1С:РКЛ: как выбрать подрядчика

Как оценить качество поддержки по 1С:РКЛ до того, как система столкнется с критическим сбоем? Разберем критерии выбора подрядчика, реальные кейсы аудита и типовые проблемы крупных 1С-систем.
24 июня приглашаем на вебинар: как превратить обучение сотрудников из статьи расходов в инструмент развития бизнеса

Как сделать обучение сотрудников управляемым и измеримым процессом? Покажем, как автоматизировать обучение на платформе 1С, контролировать результаты, сократить ручную работу и оценивать эффективность программ развития персонала.
Повышение цен на решения 1С с 1 июля 2026 года: как успеть купить по старым ценам и получить до 20% бонусов Инфостарт

1 июля 2026 года фирма «1С» проведет второй этап планового повышения цен на программные продукты корпоративного уровня. Изменения затронут ключевые решения для крупного бизнеса, лицензии уровня КОРП, отраслевые продукты и специализированные решения.
Лицензии 1С:Предприятие 8.3 – цены на клиентские и серверные лицензии (ПРОФ, КОРП, мобильные) от 9400 рублей

Лицензии на 1С Предприятие обеспечивают пользователям независимую масштабируемость – по функционалу прикладных решений и по клиентским рабочим местам. Чтобы расширить функциональные возможности используемой системы, требуется приобрести новые приложения. Если увеличивается число рабочих мест – необходимо купить пользовательские лицензии 1С. Также возможен апгрейд лицензий. Обычно поставка ПО осуществляется с программной защитой. По более высокой цене можно приобрести ПО с аппаратным ключом защиты (USB).
1С:Бухгалтерия 8.3, редакция 3.0 - цена на типовую конфигурацию 1С:БП (Базовая, ПРОФ, КОРП) от 4900 руб.

1С:Бухгалтерия 8.3 (1С:БП) — самая популярная бухгалтерская программа в России. Эта версия 1С позволяет автоматизировать бухучёт, налоговый учёт и финансовые процессы в компаниях любого масштаба. Современная 1C:Бухгалтерия учитывает требования законодательства, содержит встроенные сервисы для отчётности и снижает количество ошибок. С помощью программы можно формировать необходимые документы, отчёты, справочники и управлять данными о движении финансов. Покупайте в Инфостарт и получайте 15% бонусов на наши услуги, сервисы и мероприятия!
1С:Зарплата и управление персоналом 8 (ЗУП) - цена на ПРОФ и КОРП от 11100 руб.

1С:Зарплата и управление персоналом 8 – программа для полной автоматизация учета и управления сотрудниками на предприятии. Базовая, КОРП и ПРОФ версии. Покупайте в Инфостарт и получайте 15% бонусов на наши услуги, сервисы и мероприятия!
1С:Сервер взаимодействия — единая система коммуникаций в «1С:Предприятие» по цене от 50400 руб.

1С:Сервер взаимодействия — удобный инструмент для быстрой и безопасной командной работы внутри «1С:Предприятие». Он позволяет организовать корпоративные чаты и видеозвонки, обмениваться файлами и документами без использования сторонних мессенджеров, а также обеспечивает полную конфиденциальность данных благодаря локальному размещению сервера.
1С:Управление торговлей 8 (УТ) - цена на версии ПРОФ и базовая от 10000 руб.

1С Управление торговлей (1C УТ) — инструмент для повышения эффективности торговли. Автоматизация работы склада, максимизация продаж, упрощение работы с товарами и номенклатурой. Ведение оперативного и управленческого учета. Базовая и ПРОФ версии. Бесплатное демо! Покупайте в Инфостарт и получайте 15% бонусов на наши услуги, сервисы и мероприятия!
1С:Кабинет сотрудника: подключение и установка личного кабинета сотрудника по доступной цене от 280 рублей в месяц

1С:Кабинет сотрудника – подключение и установка приложения ЛК для мобильного взаимодействия сотрудников и бухгалтерии.
1С ИТС: купить информационно-технологическое сопровождение в Санкт-Петербурге по цене от 11 799 руб. | обновления и обслуживание

Комплексная технологическая поддержка и обслуживание 1С:ИТС. Договор регулярной поддержки пользователей 1С. Подключение сервиса по доступной стоимости.
1С:Контрагент. Автозаполнение реквизитов контрагентов по ИНН: цены от 4 200 руб.

1С- Контрагент - сервис получения реквизитов контрагента по ИНН или по наименованию в Информационной базе. Заполнение данных по контрагенту (наименование, учредитель, коды контролирующих органов, юридический адрес и телефон компании) с одной кнопки как из справочника, так и из документа учетной системы. Стоимость и тарифы представлены ниже.
1С-Отчетность - cдача регламентированной отчетности из программ 1С: цены от 1800 рублей

Сдача регламентированной отчетности из программ "1С" во все контролирующие органы: ФНС, ПФР, ФСС, Росстат, Росалкогольрегулирование, Росприроднадзор и ФТС без выгрузок и загрузок в другие программы.
1СПАРК Риски - проверка благонадежности контрагентов - заказать по цене от 3 600 руб.

Проверка благонадежности контрагентов «1СПАРК Риски» - это сервис для пользователей программ "1С" позволяющий управлять налоговыми рисками и комплексно оценивать благонадежность контрагентов по доступной стоимости.
Независимая экспертиза проектов 1С

Оцениваем проект 1С со стороны: проверяем управляемость, прозрачность работ, ключевые риски и готовность к следующему этапу.
Автоматизация общепита на базе 1С

Внедряем и настраиваем 1С для ресторанов, кафе и сетей, помогая объединить продажи, кухню, склад, списания и финансы в единую систему управления.
Управление производством на базе 1С

Помогаем промышленным компаниям выстроить единую систему управления на базе 1С — от планирования и производства до контроля ресурсов, себестоимости и финансового результата.
Комплексная автоматизация строительной отрасли

Помогаем строительным компаниям выстроить единую систему управления на базе 1С — от планирования и учета до контроля затрат, ресурсов и финансового результата.
Внедрение 1С:ERP Агропромышленный комплекс

Внедряем 1С:ERP Агропромышленный комплекс под специфику агробизнеса — выстраиваем процессы от производства до финансов, обеспечивая прозрачную себестоимость, контроль ресурсов и управляемость бизнеса на основе данных.