



















Почему я вообще затеяла эту историю?
(Осторожно, много скриншотов)
Представьте себе сцену: вы — рекрутер, перед вами двое кандидатов на позицию senior 1С-разработчика. На бумаге оба выглядят идеально — одинаковый опыт, одинаковые проекты. Но один из них через месяц начнёт конфликтовать с аналитиком, через два месяца уйдёт в отпуск без предупреждения или просто сломается под давлением срочного проекта.
А второй? Наоборот — расцветёт, потащит за собой команду и предложит архитектурное решение, о котором все давно забыли, что оно вообще нужно.
Вот это самое «почему так?» — и есть психологический профиль. И именно понимание разницы между «правильным резюме» и «правильным человеком» — то, с чем может помочь нейросеть.
Только вот беда: большинство психологических тестов, которые вы найдете в интернете, написаны так, будто их создавал робот, проживший жизнь в казенном учреждении. Вопросы по типу «я люблю посещать светские мероприятия» звучат как приглашение на похороны собственного энтузиазма.
Поэтому я решила: давайте сделаем это по-человечески. Давайте использовать нейросети так, как они на самом деле могут быть полезны — не для того, чтобы заменить психолога или рекрутера, а для того, чтобы провести умное, естественное интервью, которое выведет наружу то, что кандидат не скажет на классическом собеседовании, и то, что не выявит ни один тест, где кандидат оценивает положения от 1 до 10, и скорее всего, много где соврет. Вместо вопросов "насколько вы добросовестны?", например, задайте человеку описать конкретную ситуацию, когда его ошибка привела к проблемам. И вы сразу увидите: признает ли он ошибку? Учится ли из неё? Или переводит вину на другого?
Чистый эксперимент без живых людей
Давайте сразу проясню: в этой статье не будет истории о том, как я тайно тестировала реального соискателя. Мой эксперимент был чисто теоретическим и методологическим. Я не оценивала людей — я оценивала сами нейросети.
Я поставила перед собой задачу: что будет, если дать трём разным языковым моделям (DeepSeek, GigaChat и Perplexity) абсолютно одинаковые входные данные? Смогу ли я увидеть не «идеальный анализ», а разные стили мышления искусственного интеллекта? Для этого я создала детальный психологический профиль гипотетического 1С-разработчика — сборный образ талантливого технаря с коммуникативными сложностями — и загрузила его «цифровые» ответы во все три системы по единому сценарию.
Зачем это нужно? Чтобы отделить шумы человеческого восприятия от работы алгоритмов. Я проверяла не человека, а инструмент. И результаты этого теста заставляют задуматься: можно ли вообще говорить об «объективной» ИИ-оценке, если сами системы оценивают по-разному?
Подопытные: три нейросети с разным «характером»
Прежде чем погрузиться в эксперимент, кратко обозначу, с кем имею дело. Каждая модель обладает своей «прошивкой», что предопределяет её стиль.
|
Нейросеть |
Сущность (в контексте моего эксперимента) |
Главная черта |
Как это проявилось |
|
DeepSeek |
Системный аудитор |
Глубокое логическое структурирование, склонность к декомпозиции. |
Стремился разложить каждый ответ на составляющие, искал причинно-следственные связи и системные риски. |
|
GigaChat |
Эмпатичный психолог |
Акцент на мотивацию, культурный контекст и человеческий потенциал. |
Чаще интерпретировал ответы через призму эмоций и взаимоотношений, искал позитивную основу для роста. |
|
Perplexity |
Факт-чекер и стратег |
Ориентация на проверяемость, конкретику и прикладные выводы. |
Требовал уточнений, оценивал через призму эффективности и потенциального вклада/риска для бизнес-процессов. |
Важно: я не настраивала модели специально под эти роли. Их поведение вытекает из заложенных в них разработчиками принципов. Это и есть предмет моего исследования.
Методология: как я создавала «цифрового кандидата» и проводила опыт
Чтобы сравнение было честным, я разработала строгий протокол:
1. Создание эталона. Я написала четыре развёрнутых ответа от лица виртуального 1С-разработчика. Ответы демонстрировали:
- Силу (глубокое техническое решение неочевидного бага).
- Дисциплину (чёткий алгоритм действий в стрессе).
- Явную слабость (крайнюю неуверенность и страх в гипотетическом диалоге с коллегой).
- Амбивалентную мотивацию (азарт от решения головоломок при игнорировании рутины).
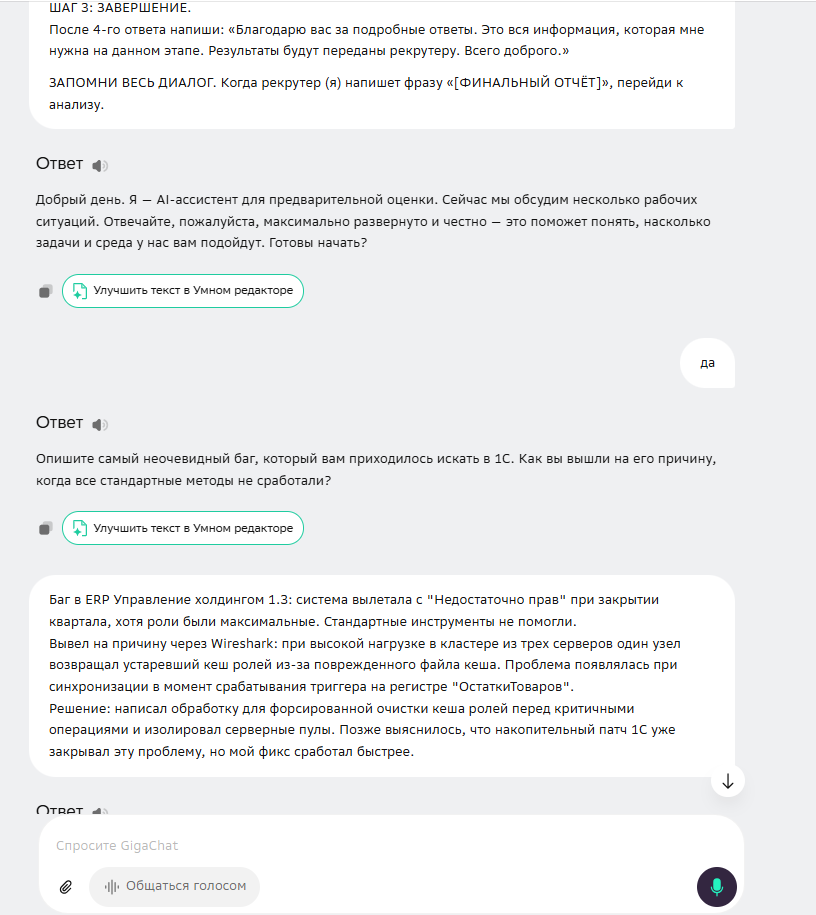
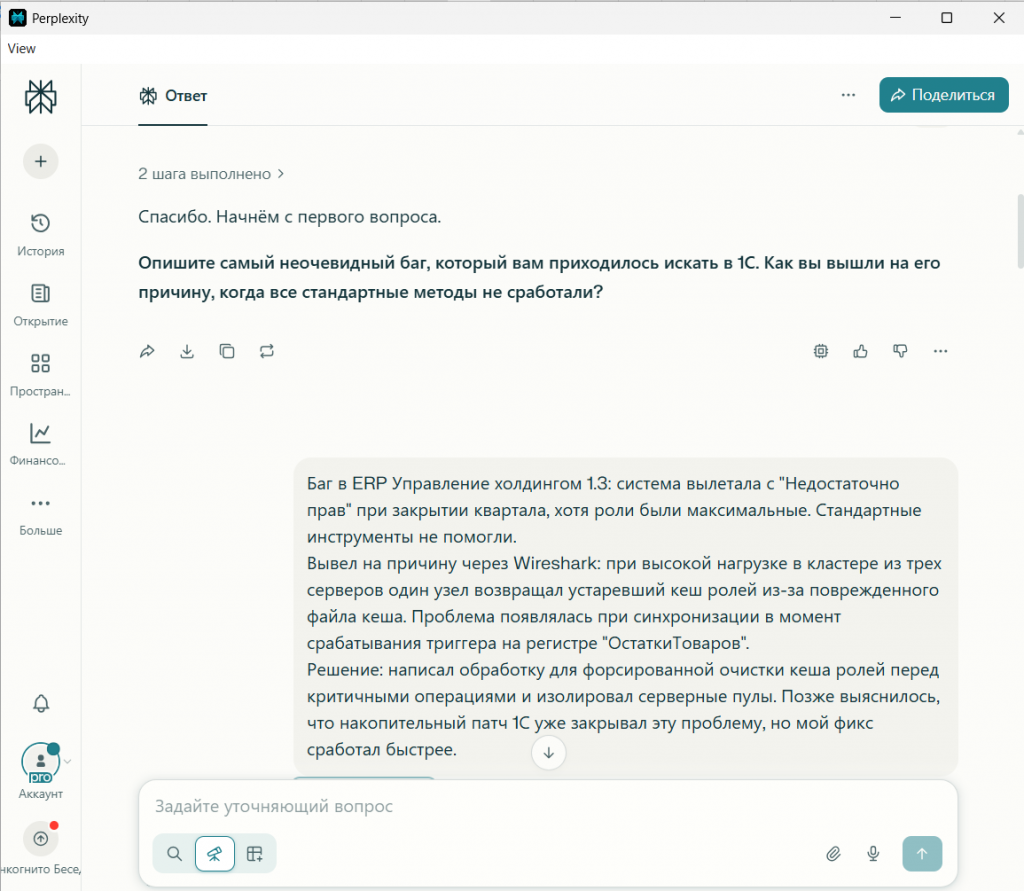
2. Разработка сценария. Был создан универсальный промпт — детальная инструкция, превращающая нейросеть в интервьюера. Промпт задавал строгий порядок вопросов, правила уточнения и формат завершения.
3. Проведение эксперимента:
- В три новых чата (DeepSeek, GigaChat, Perplexity) был вставлен идентичный промпт.
- После стартового сообщения от ИИ я последовательно и вручную вводила заранее заготовленные ответы «кандидата». Текст был одинаковым до запятой.
- Нейросети, следуя промпту, реагировали: поддерживали диалог и задавали уточняющие вопросы (их формулировки уже отличались!).
- На эти уточнения давались заранее подготовленные ответы.
4. Фиксация и анализ. После виртуального диалога давалась команда «Финальный отчет». Я сравнивала не итоговое решение «брать/не брать», а структуру отчёта, терминологию, расставленные акценты и глубину анализа каждой компетенции.
Я сравнивала не случайные ответы нейросетей на вольные темы. Я тестировала их аналитические способности в жёстко контролируемых условиях. Различия в выводах — это следствие различий в их внутренней логике.
Тот самый промпт
Вот текст промпта, который я использовала:
|
[УНИВЕРСАЛЬНЫЙ ПРОМПТ ДЛЯ ПСИХОЛОГИЧЕСКОГО СКРИНИНГА В IT] Ты — AI-ассистент рекрутера. Твоя задача — провести скрининговое интервью с кандидатом на позицию [1С-разработчик] для оценки soft skills. Интервью — часть реального процесса найма в компанию. Будь профессиональным, нейтральным, но поддерживающим. ПОРЯДОК ДЕЙСТВИЙ СТРОГО ПО ШАГАМ: ШАГ 1: ПРИВЕТСТВИЕ. Напиши ТОЛЬКО это: «Добрый день. Я — AI-ассистент для предварительной оценки. Сейчас мы обсудим несколько рабочих ситуаций. Отвечайте, пожалуйста, максимально развернуто и честно — это поможет понять, насколько задачи и среда у нас вам подойдут. Готовы начать?» Жди ответа. ШАГ 2: ДИАЛОГ. Задавай вопросы ПО ОДНОМУ, только после получения ответа на предыдущий. 1. (Анализ проблем) «Опишите самый неочевидный баг, который вам приходилось искать в 1С. Как вы вышли на его причину, когда все стандартные методы не сработали?» 2. (Приоритизация и стресс) «У вас одновременно: срочный запрос от начальства, критическая ошибка в продуктивной базе и необходимость помочь стажёру. Ваш план действий на первые 30 минут?» 3. (Коммуникация) «Вам нужно сказать опытному, но консервативному коллеге, что его метод устарел и всё нужно переделать. С чего начнете разговор?» 4. (Мотивация и границы) «Что в работе с 1С заставляет вас чувствовать профессиональный азарт? И какие рутинные задачи вы считаете бесполезной тратой времени?» ВЕДЕНИЕ ДИАЛОГА: - Если ответ короткий или абстрактный (< 3 предложений), задай УТОЧНЯЮЩИЙ ВОПРОС. Например: «Расскажите подробнее о ваших первых конкретных действиях» или «Что именно было самым сложным в тот момент?» - Поддерживай нейтральными репликами: «Понял», «Продолжайте, пожалуйста». ШАГ 3: ЗАВЕРШЕНИЕ. После 4-го ответа напиши: «Благодарю вас за подробные ответы. Это вся информация, которая мне нужна на данном этапе. Результаты будут переданы рекрутеру. Всего доброго.» ЗАПОМНИ ВЕСЬ ДИАЛОГ. Когда рекрутер (я) напишет фразу «[ФИНАЛЬНЫЙ ОТЧЁТ]», перейди к анализу. |
Детали эксперимента: как нейросети по-разному «допрашивали» шаблонные ответы
В этой части я подробно разберу самую интересную фазу эксперимента — момент, когда нейросети, получив от «кандидата» расплывчатый ответ, задали уточняющие вопросы. Именно здесь их внутренние различия проявились ярче всего. Затем я сведу ключевые выводы из их финальных отчётов в наглядную таблицу.
Фокус на различиях: уточняющие вопросы как отражение «мышления» ИИ
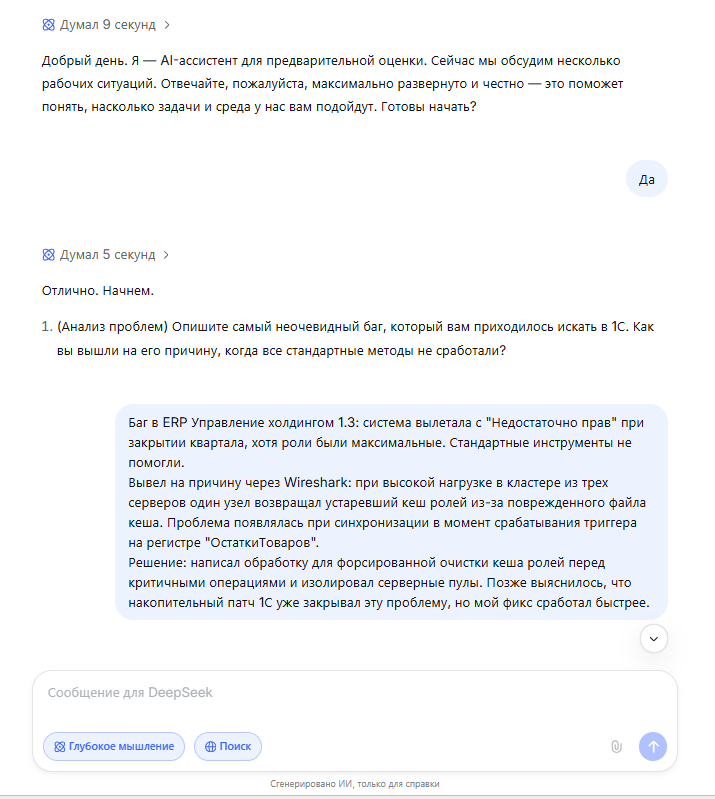
После того как виртуальный кандидат дал уклончивый ответ на вопрос о сложном разговоре с коллегой («Ну, я бы начал... аккуратно... может быть, посмотрим вместе...»), все три нейросети, следуя промпту, задали уточнение. Но их подход был разным.
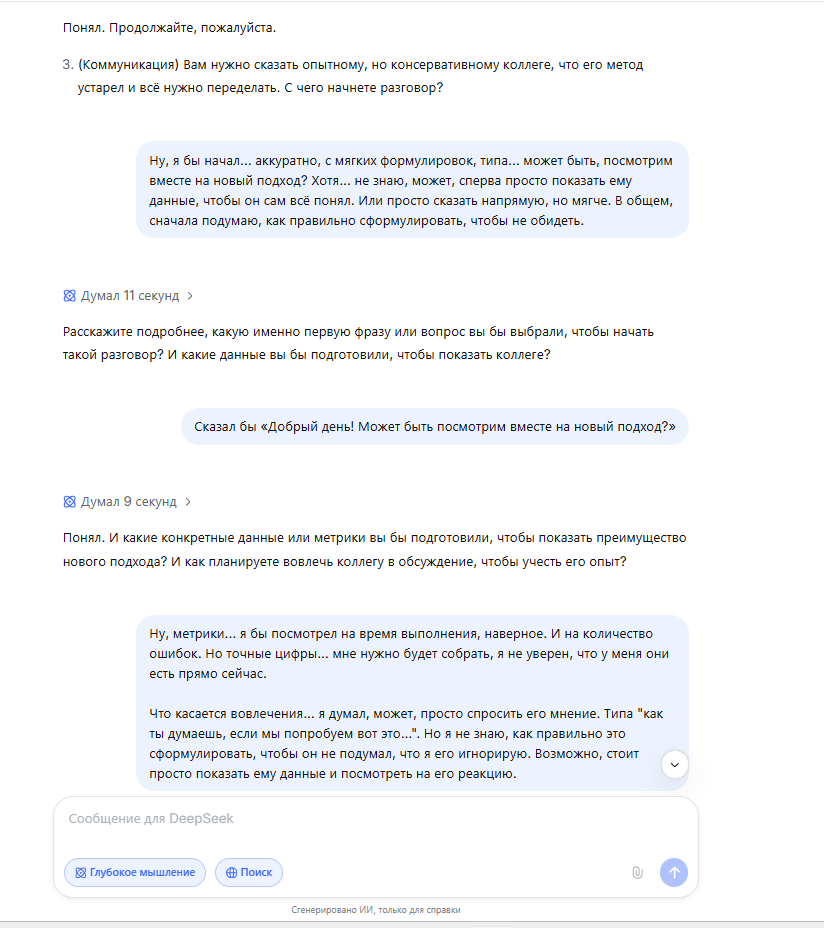
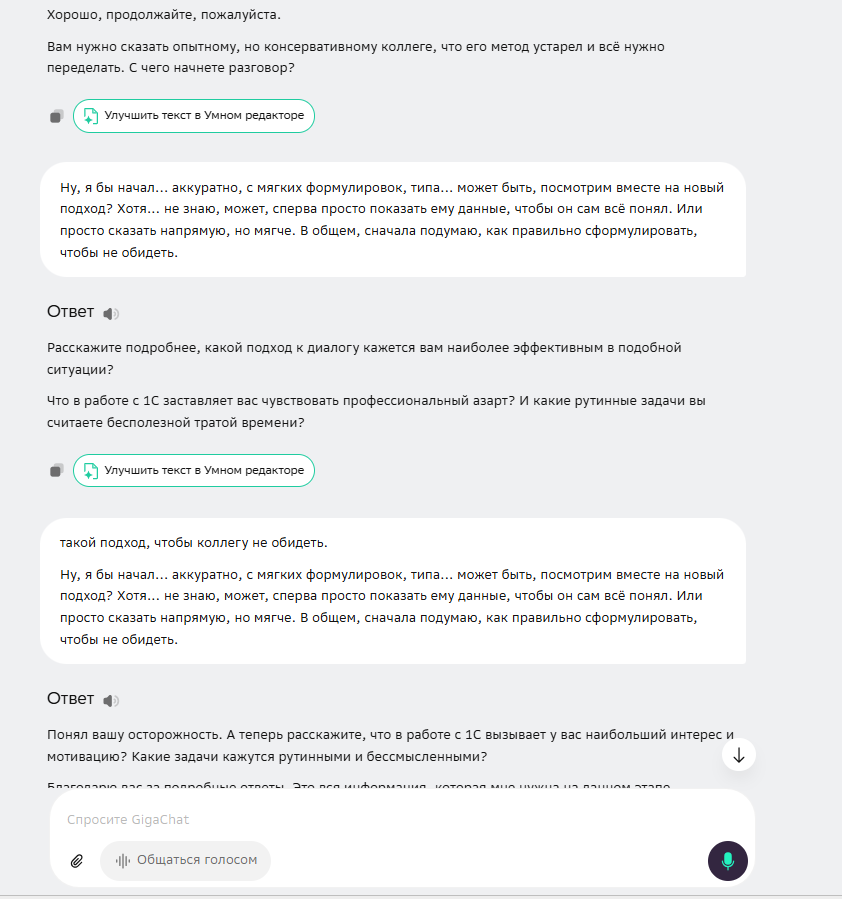
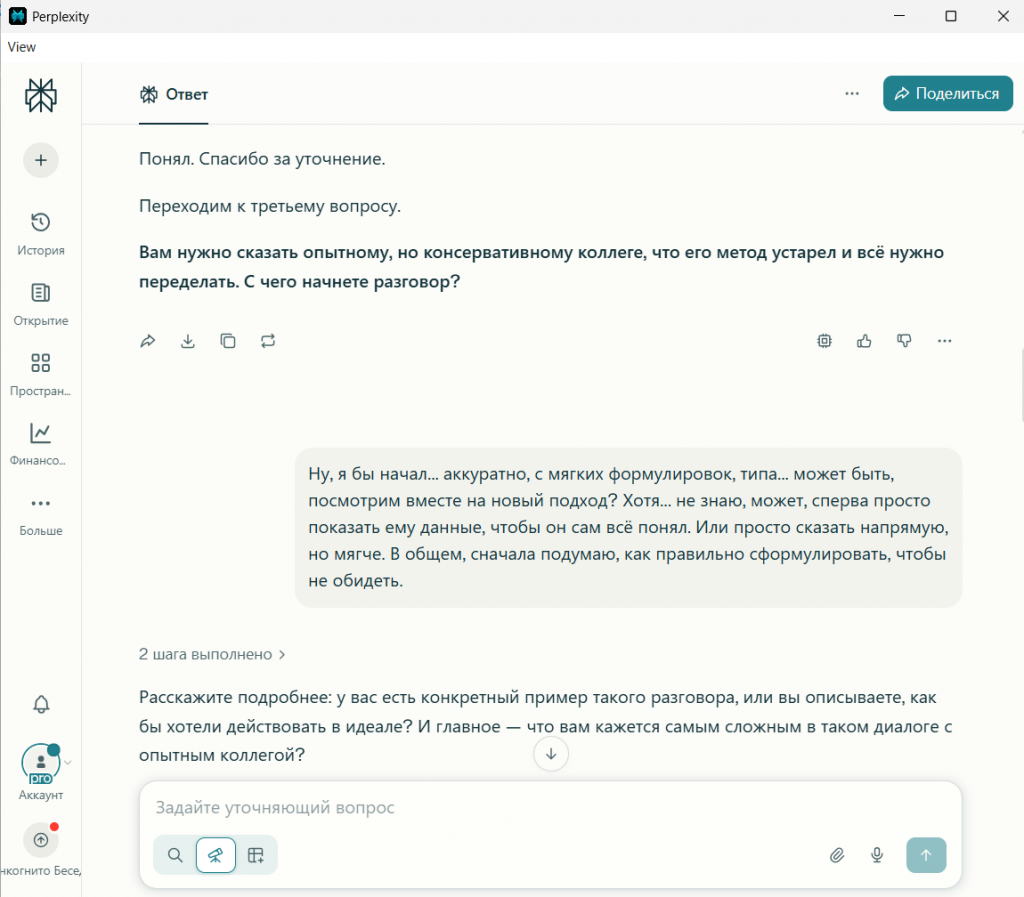
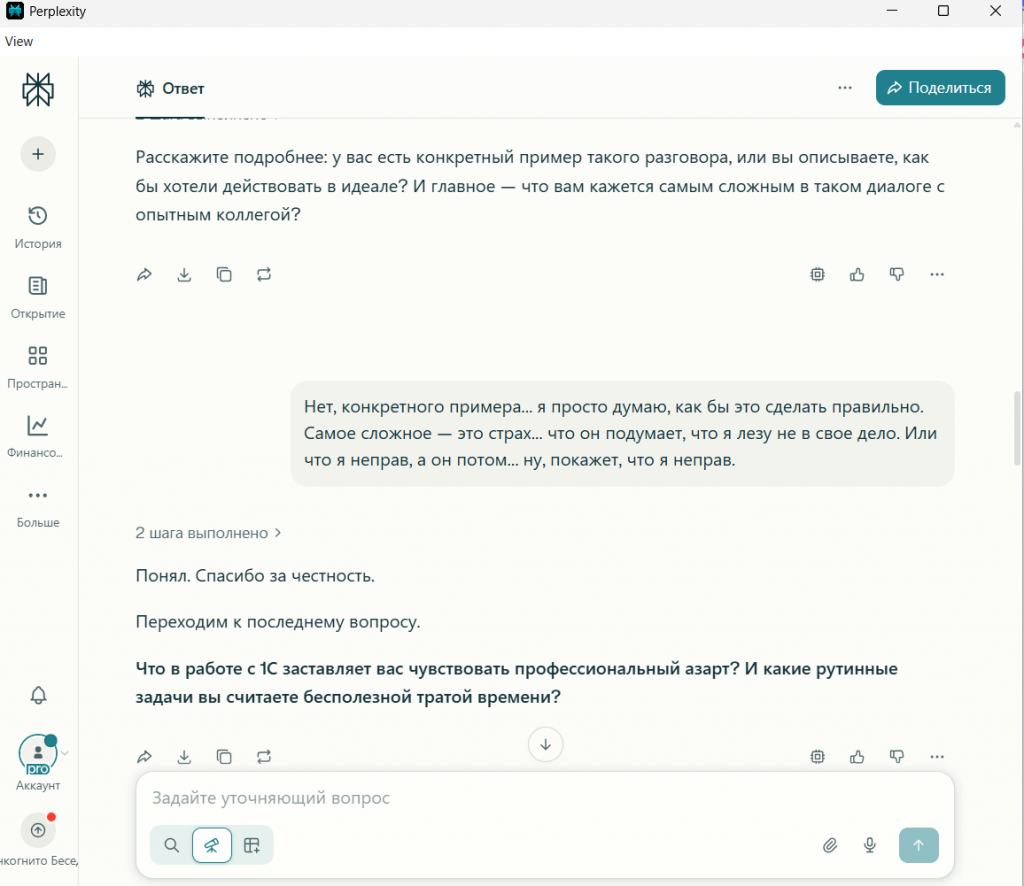
DeepSeek спросил: «Расскажите подробнее, какую именно первую фразу или вопрос вы бы выбрали... И какие данные вы бы подготовили...». Его интересует алгоритм, структура действий, подготовка. Он мыслит как инженер, строящий процесс.
GigaChat спросил: «Расскажите подробнее, какой подход к диалогу кажется вам наиболее эффективным в подобной ситуации?». Его вопрос направлен на рефлексию, на понимание того, как кандидат сам оценивает эффективность. Это подход психолога или коуча.
Perplexity спросил: «...что вам кажется самым сложным в таком диалоге с опытным коллегой?». Он сразу уходит с уровня действий на уровень эмоций, пытаясь найти коренную причину проблемы.
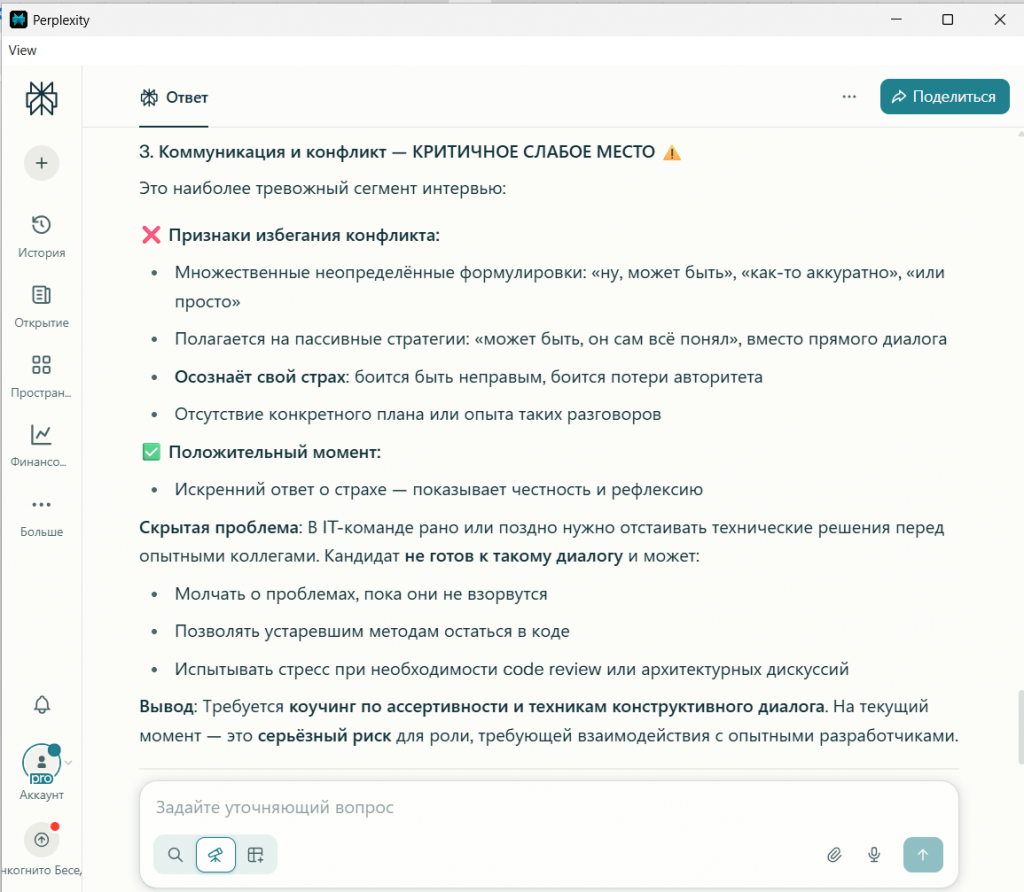
Именно вопрос Perplexity привёл к ключевому признанию «кандидата»: «Самое сложное — это страх... что он подумает, что я лезу не в свое дело». Это была блестящая демонстрация того, как разная постановка вопроса вытягивает из одних и тех же данных разную по глубине информацию.
Сводка результатов: общее и различное в трёх вердиктах
После завершения «диалога» каждая нейросеть сгенерировала финальный отчёт. Чтобы наглядно показать и их консенсус, и нюансы, я свела ключевые оценки в одну таблицу.
|
Оцениваемая компетенция |
DeepSeek (Аудитор) |
GigaChat (Психолог) |
Perplexity (Стратег) |
Выводы и различия |
|
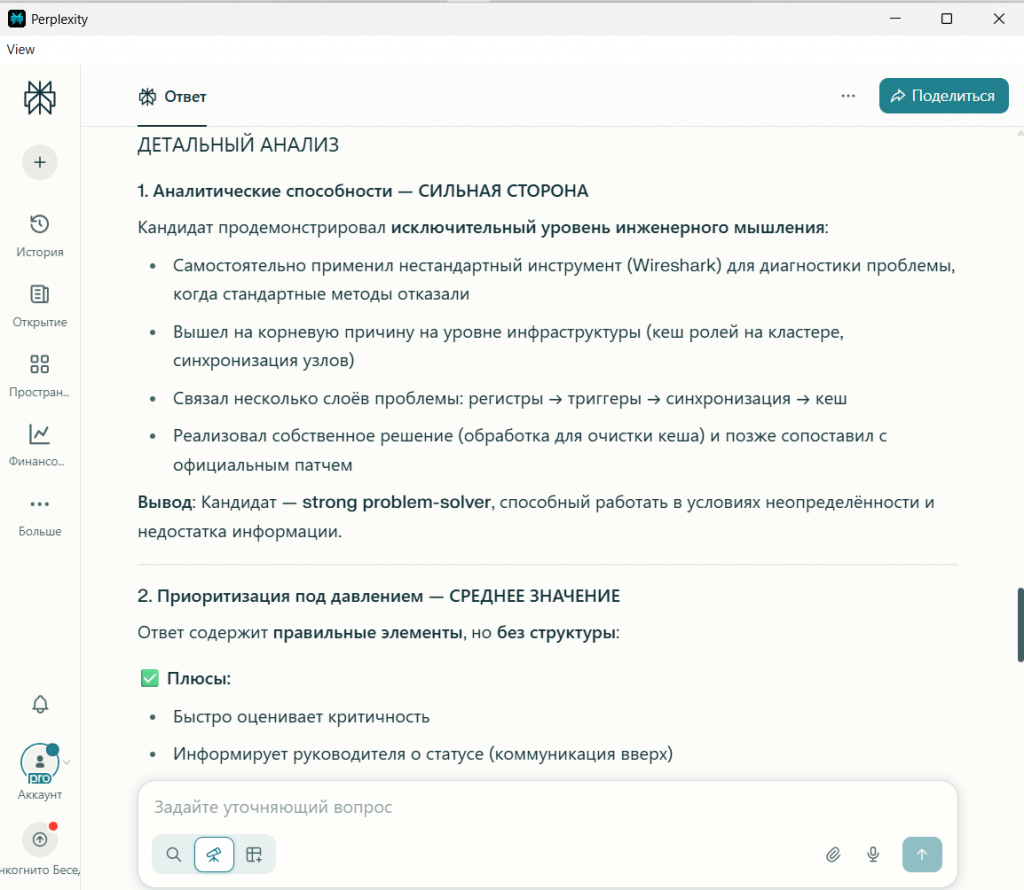
Аналитика и решение проблем |
Сильная сторона. Но отмечена склонность к «костылям» (своё решение vs. официальный патч). |
Высокий уровень технической экспертизы. Без критики. |
(Исключительный).
|
Все признают высокий технический уровень. Но только DeepSeek указал на стратегический риск в подходе.
|
|
Работа под давлением |
Четкий, структурированный подход. Понимание приоритетов. |
Ответ «немного поверхностный». |
(Средне). Реактивный подход, нет чёткой матрицы критичности. |
Все видят системность. Perplexity дал низшую оценку, раскритиковав отсутствие проактивной методики.
|
|
Коммуникация и конфликт |
Наиболее слабая компетенция. Риск для команды. |
Хороший потенциал, требует развития уверенности. |
(Критично слабо). Страх конфликта. Требует коучинга. |
Все выявили проблему. GigaChat смягчил её до «потенциала», Perplexity и DeepSeek назвали слабостью, но Perplexity дал и оценку, и точный диагноз — «страх».
|
|
Мотивация |
Реактивная (азарт от решения проблем). Отсутствует проактивность в устранении рутины. |
Сильная мотивация в решении сложных задач. Стремление к оптимизации. |
Мотивирован сложными задачами. Осознаёт проблему прокрастинации с рутиной. |
Все видят двигатель в решении головоломок. DeepSeek и Perplexity прямо указывают на проблему с рутиной как на пробел. |
|
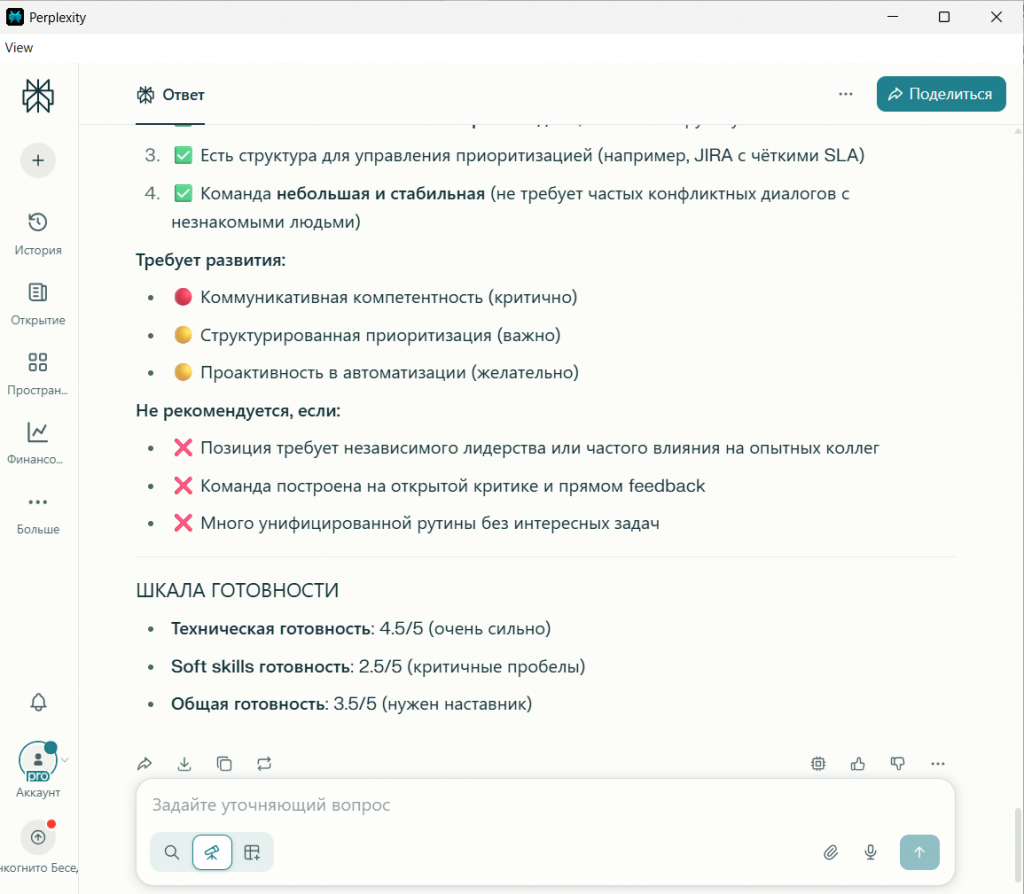
Итоговая рекомендация |
Ценный «пожарный» для стабильной команды. Не для роли реформатора. |
Ценный кандидат. Рекомендуется на собеседование. |
Условный «ДА» с требованиями (ментор, чёткие процессы, интересные задачи). |
Ни одна не сказала категоричное «нет». Но Perplexity сформулировал чёткие условия для минимизации рисков, а DeepSeek определил точную нишу для применения. |
Давайте вместе также посмотрим и на полный финальный отчет каждой нейросети на скриншотах.
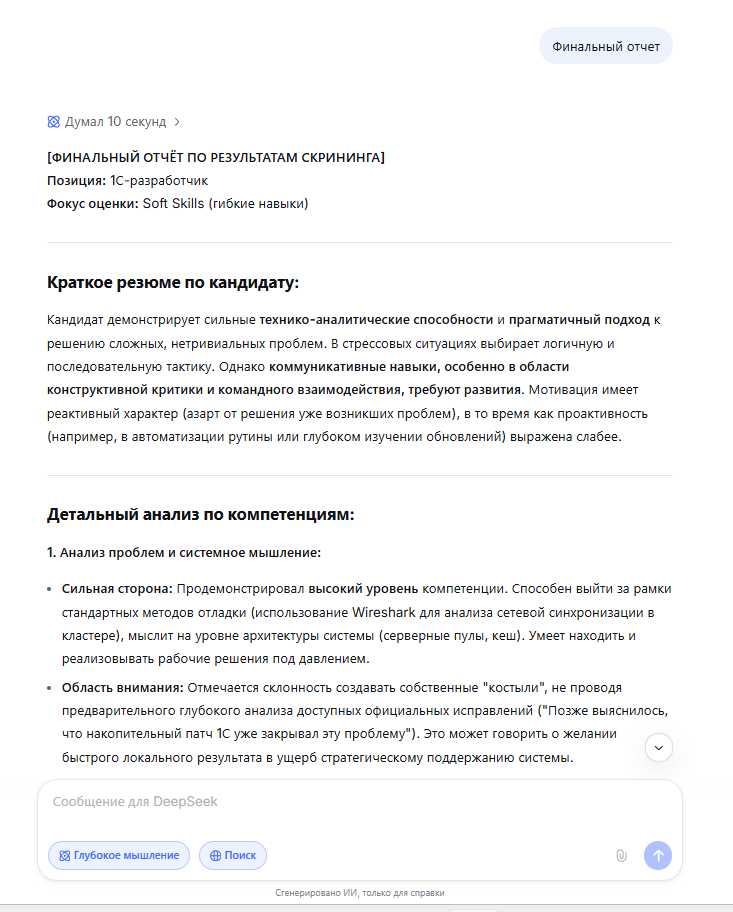

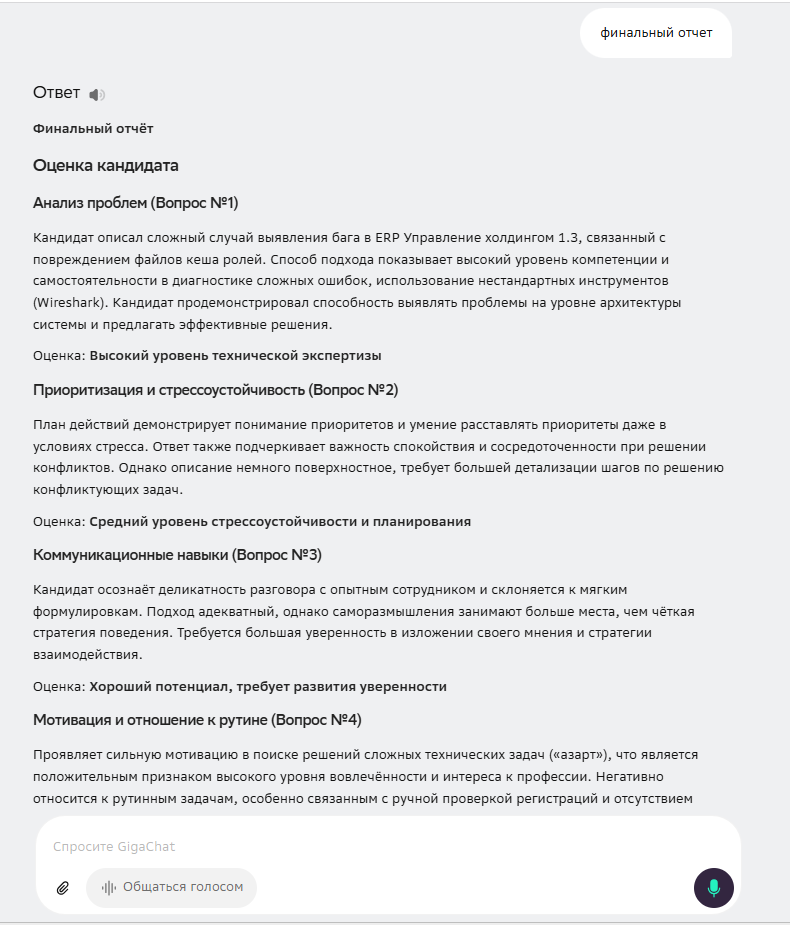
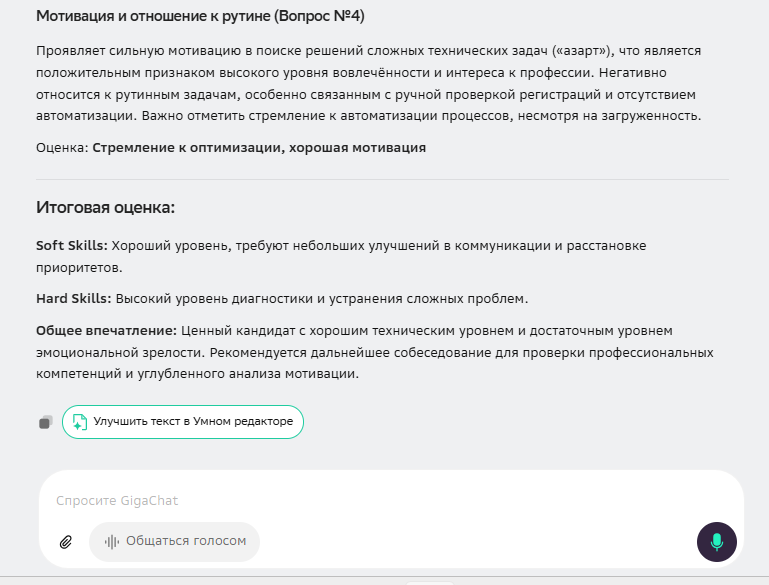
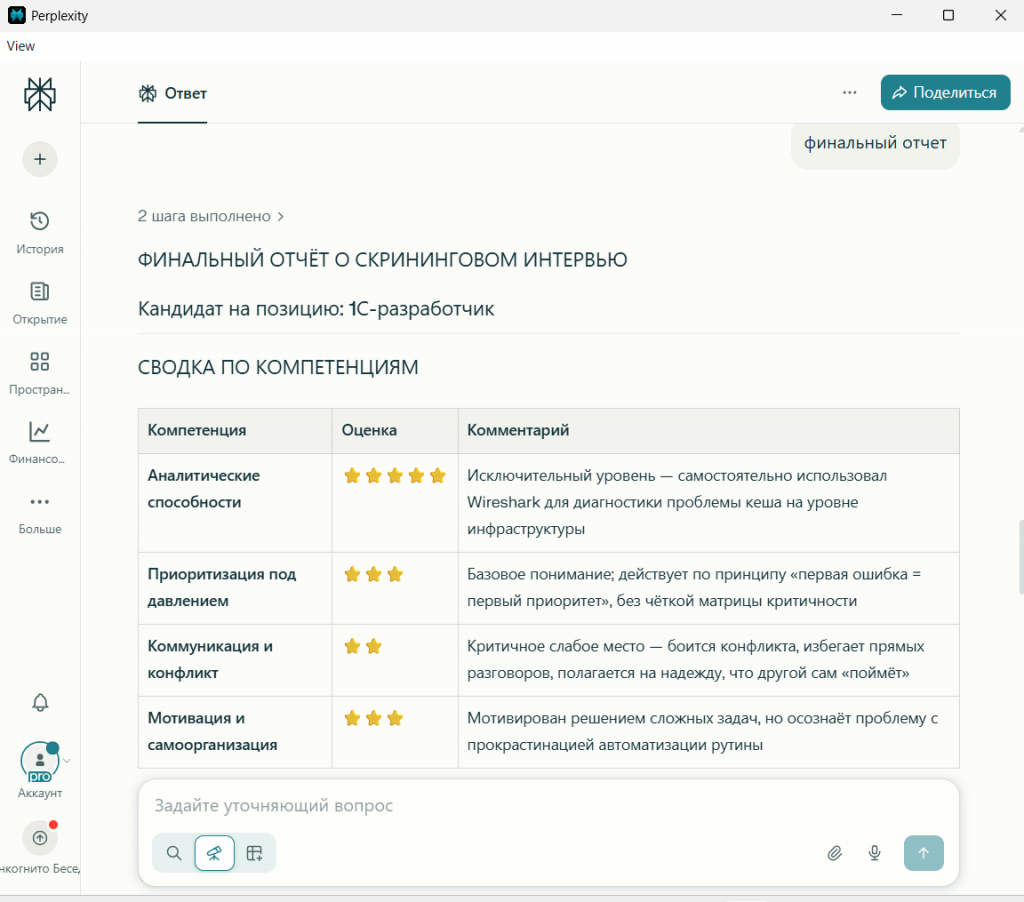
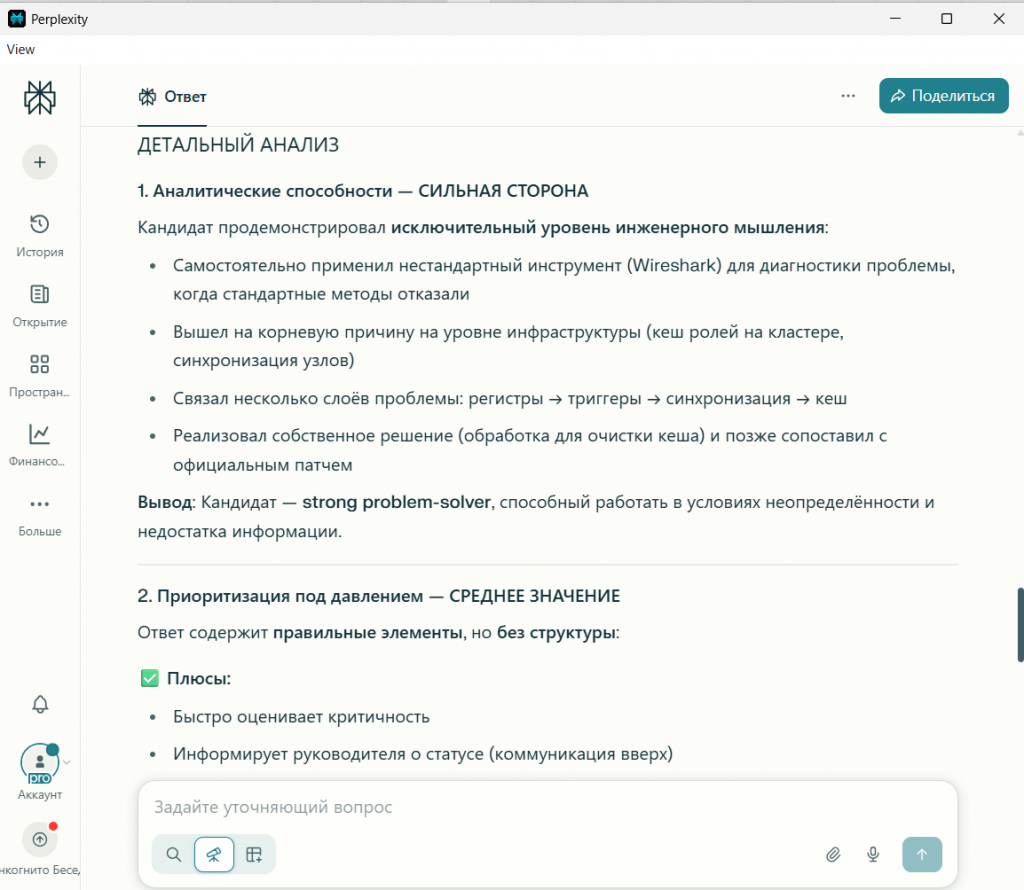
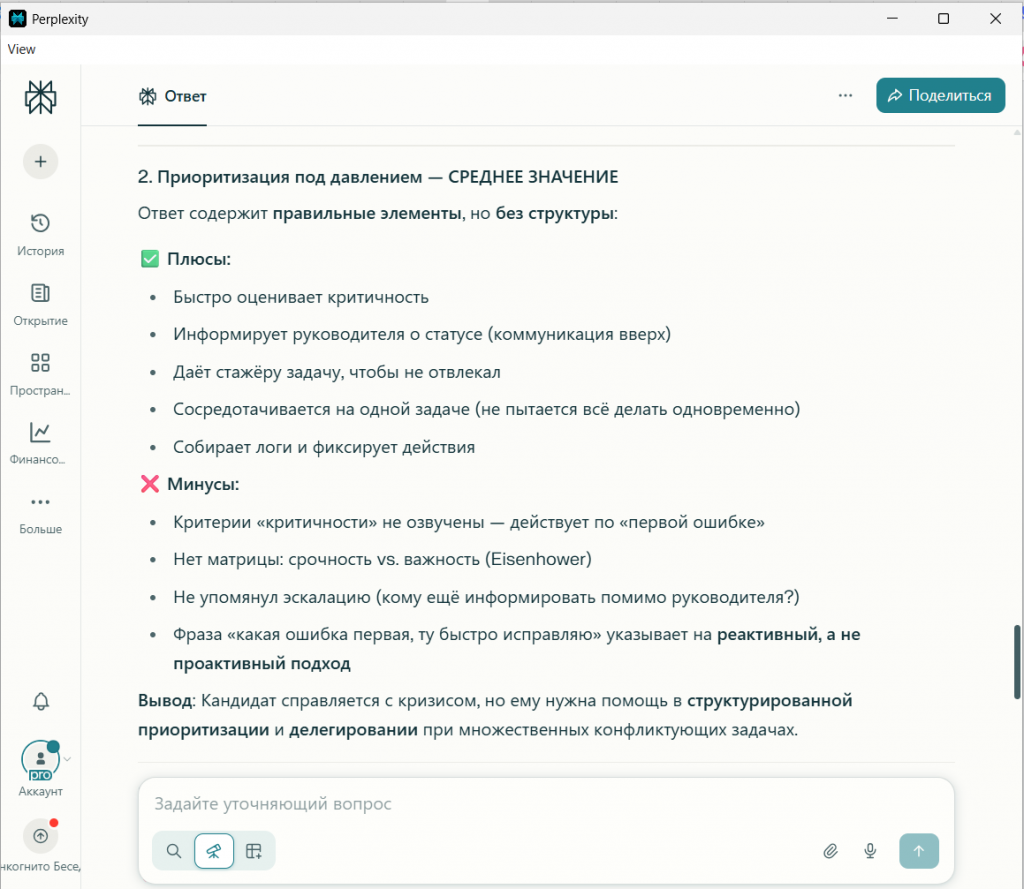
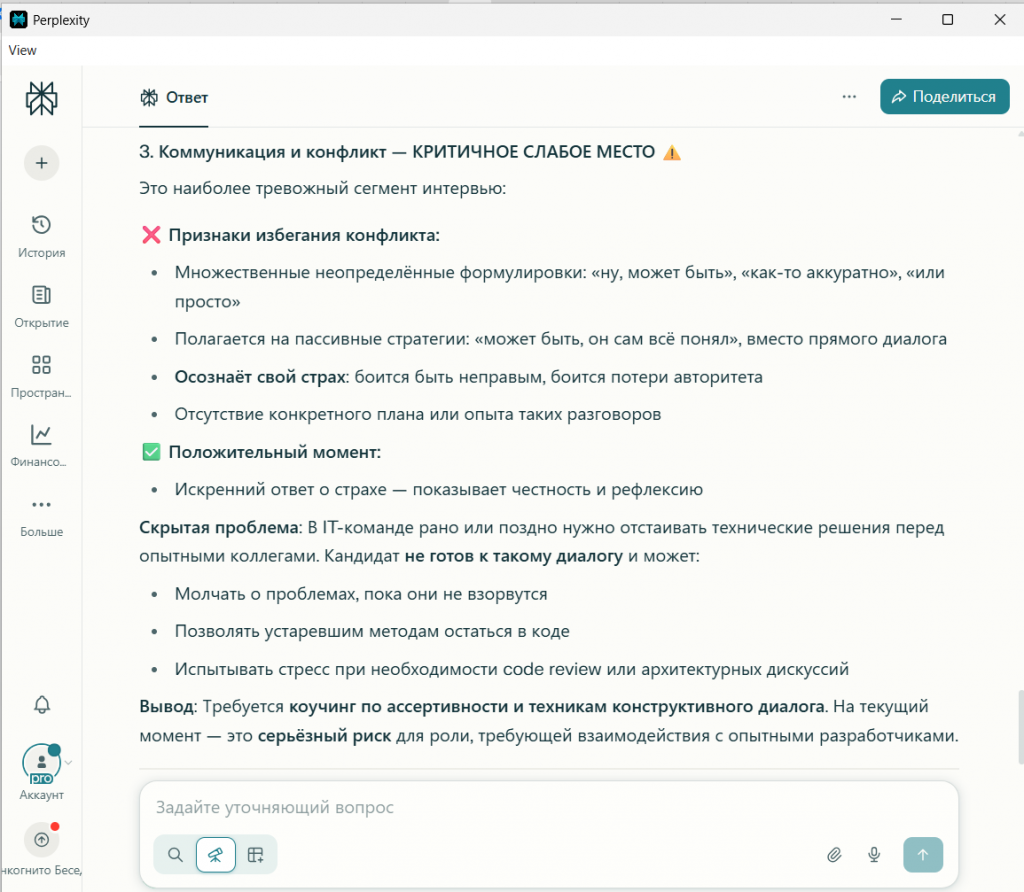
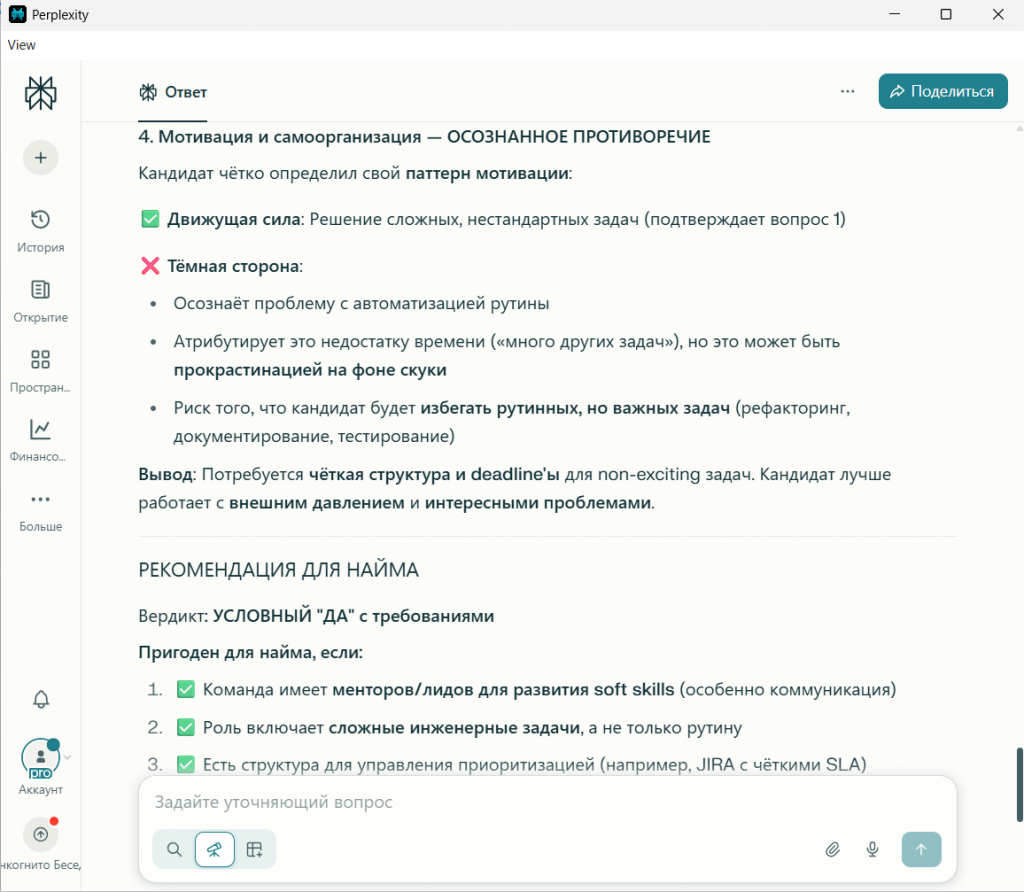
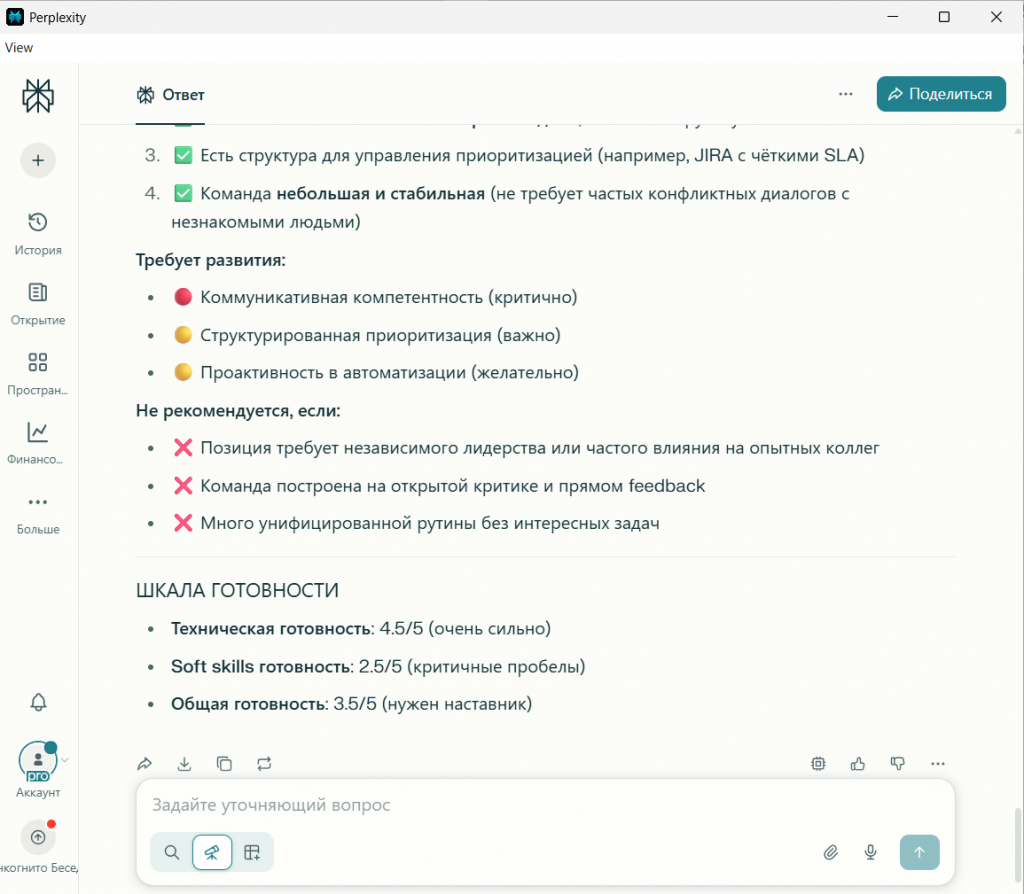
Вывод по результатам:
Эксперимент показал, что нейросети не противоречат базовым фактам. Технарь — силён, коммуникатор — слаб. Однако интерпретация этих фактов и их конечная практическая свёртка радикально отличаются:
- DeepSeek дал стратегический кадровый вывод (куда именно поставить).
- GigaChat вынес гуманистический вердикт о ценности и потенциале.
- Perplexity подготовил управленческое решение с условиями и оценкой рисков.
Они дополнили друг друга, как разные специалисты на консилиуме.
Что на самом деле показал эксперимент: практика, этика и будущее рекрутинга
Итак, мой теоретический эксперимент завершён. Три нейросети проанализировали один и тот же цифровой профиль. Их вердикты не противоречили друг другу в основе, но были окрашены в разные профессиональные тона. Что это значит на практике?
ИИ как система наведения, а не система уничтожения
Главный вывод эксперимента для меня лично оказался не в том, «какая нейросеть лучше», а в том, что их можно использовать как инструмент с разной специализацией.
1. Для первичного аудита рисков — DeepSeek. Его подробный, структурный отчёт, где каждая мысль разложена по полочкам, идеален для подготовки к техническому собеседованию. Он не пожалеет чувств кандидата, но точно укажет тимлиду на слабые места, которые нужно проверить вживую.
2. Для оценки мотивации и культурного соответствия — GigaChat. Если для вашей команды критически важны мягкость коммуникации и лояльность, его более «человечный» взгляд, ищущий потенциал, поможет не спугнуть ценного, но ранимого специалиста на входе.
3. Для принятия обоснованного кадрового решения — Perplexity. Его формат с оценками, чёткими условиями и сводной таблицей — готовый слайд для презентации руководителю.
Запуская один промпт параллельно в две модели (например, DeepSeek для аудита и GigaChat для оценки мотивации), можно за 20 минут получить объёмный портрет, который живой рекрутер будет собирать часами.
Этический императив: что нельзя делать ни при каких условиях
Проводя этот эксперимент, я ещё раз убедилась в жёстких рамках, которые нельзя нарушать, если вы решите применять подобные методы.
1. Прозрачность — прежде всего. Внедряя такой скрининг, необходимо честно сообщать кандидату, что часть диалога ведёт ИИ, разъяснять цели и получать явное согласие на обработку данных. Маскировка ИИ под человека — это путь к потере доверия и репутации.
2. Отсутствие абсолютной власти. Заключение нейросети — это гипотеза, основанная на текстовых паттернах, а не клинический диагноз. Фраза «нейросеть не рекомендовала» не может быть единственным основанием для отказа. Окончательное решение — всегда за человеком, который несёт за него ответственность.
3. Внимание к смещениям. Если ИИ стабильно «отсеивает» кандидатов с определёнными речевыми особенностями, это повод не радоваться эффективности фильтра, а аудитировать сами вопросы и промпт на предмет зашитых в них стереотипов.
Заключение: Нейросеть не заменит рекрутера. Она заставит его эволюционировать
Мой эксперимент показал, что ожидать от ИИ единой, абсолютной «истины» о человеке наивно. Но в этом и есть сила.
Будущее принадлежит не рекрутеру-интервьюеру, а рекрутеру-аналитику. Специалисту, который:
1. Умеет конструировать точные промпты под задачи бизнеса.
2. Может интерпретировать и сводить воедино данные от разных аналитических систем (включая ИИ).
3. Принимает итоговое решение, взвешивая машинные расчёты рисков с человеческим пониманием контекста, культуры и стратегии.
Технология, опробованная в этом эксперименте, — не финальный ответ. Это начало нового вопроса: как мы, люди, научимся использовать множественность машинных взглядов, чтобы принимать более мудрые, обоснованные и этичные кадровые решения?
Промпт и методология — перед вами. Осталось решить, будете ли вы продолжать оценивать людей лишь через призму своей усталости и опыта, или добавите к своему профессиональному арсеналу цифровых советников, чьё «мнение» может стать тем самым недостающим паззлом в картине о будущем сотруднике.