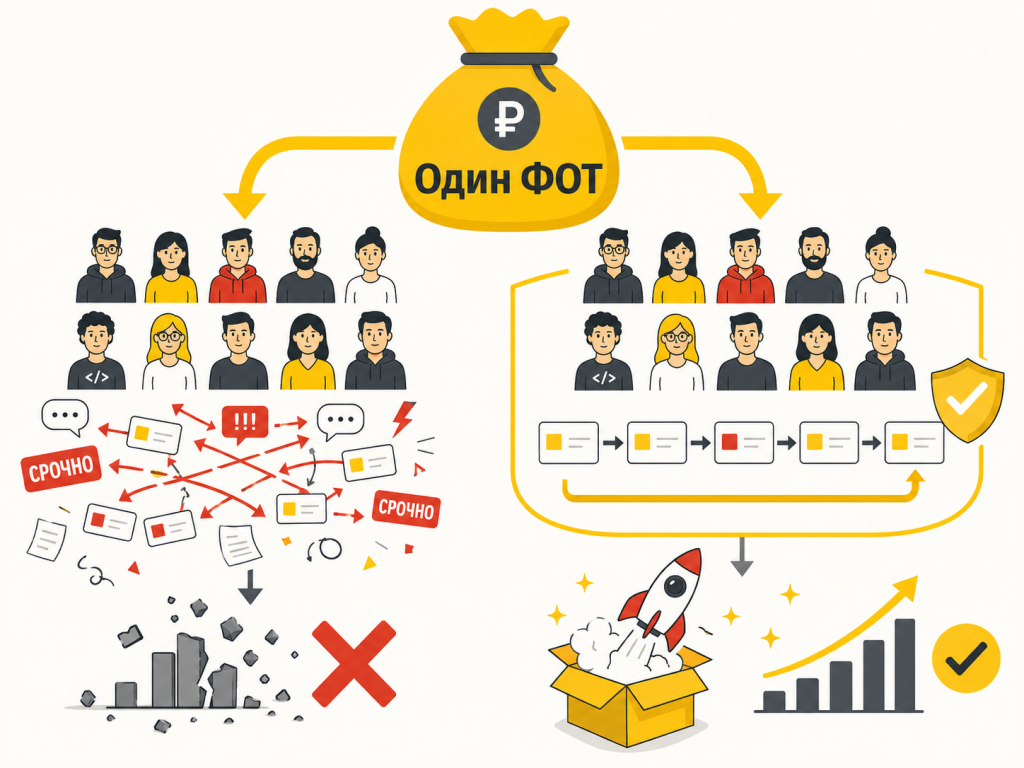
Самое неприятное в сравнении разных команд — итог виден не сразу.
В первый месяц все выглядят занятыми: задачи идут, созвоны проходят, в чатах активность, релизы как-то собираются. А потом проходит полгода или год.
И становится видно: одна команда спокойнее выпускает релизы, чаще закрывает задачи в нижней границе оценки, меньше возвращает доработки на переделку и сама предлагает улучшения.
Вторая команда тоже не бездельничает. Люди работают, устают, тушат инциденты, закрывают задачи. Но результат двигается тяжелее: приоритеты скачут, поддержка дергает напрямую, часть работы застревает на уточнениях, а день разработчика разбивается на мелкие переключения.
Через год по итогу эффект разный.
Я бы не спешил с выводом “в первой команде люди сильнее”. В моей практике чаще видно другое: нормальные специалисты начинают давать слабый результат, если вокруг них плохо организована работа.
ФОТ покупает время людей. Но он не гарантирует, что это время превратится в релиз, качество и пользу для бизнеса.
Обычная сцена: все заняты, а задача не двигается
У разработчика в работе задача к ближайшему релизу. Нужно доработать механизм, проверить несколько сценариев, пройти code review, передать на тестирование.
В середине дня прилетает “срочно”. Не авария, не остановленный бизнес-процесс, не ошибка, из-за которой пользователи не могут работать. Просто пользователю давно неудобно, руководитель направления напомнил, и запрос сразу получил повышенный приоритет.
Разработчик переключился. Посмотрел. Начал уточнять детали. Оказалось, что в обращении не хватает сценария. Подключили поддержку, потом аналитика, потом еще одного человека, который “помнит, как это раньше работало”.
Прошел день. Все были заняты. В чатах было много движения. Но основная релизная задача почти не сдвинулась.
Через несколько таких дней команда снова обсуждает, почему задача ушла за верхнюю границу оценки. Формально причина есть: появились срочные обращения. Но если смотреть честнее, проблема не в одном обращении.
Проблема в системе.
Кто решил, что это действительно срочно? Что сняли из работы, когда взяли новый запрос? Почему поддержка пришла к разработчику с сырым обращением? Почему релизная задача не была защищена от переключений?
Вот здесь и начинается управленческая часть работы: не отгородить разработчиков от всего мира, а настроить правила, при которых команда не теряет результат каждый день по чуть-чуть.
Почему одинаковая зарплата не дает одинаковый выход
Зарплата важна. Нормальная оплата помогает удерживать людей и показывает, что работа ценится. Но зарплата сама по себе не выстраивает рабочую систему.
Один и тот же оплаченный час разработчика может уйти на полезную работу.
А может уйти на потери: переключения, переделки из-за неясного результата, ожидание решения по приоритету, переписку в личке вместо нормального маршрута задачи, ручной разбор сырых обращений.
В отчете эти потери часто не видны. На дистанции именно они дают разницу.
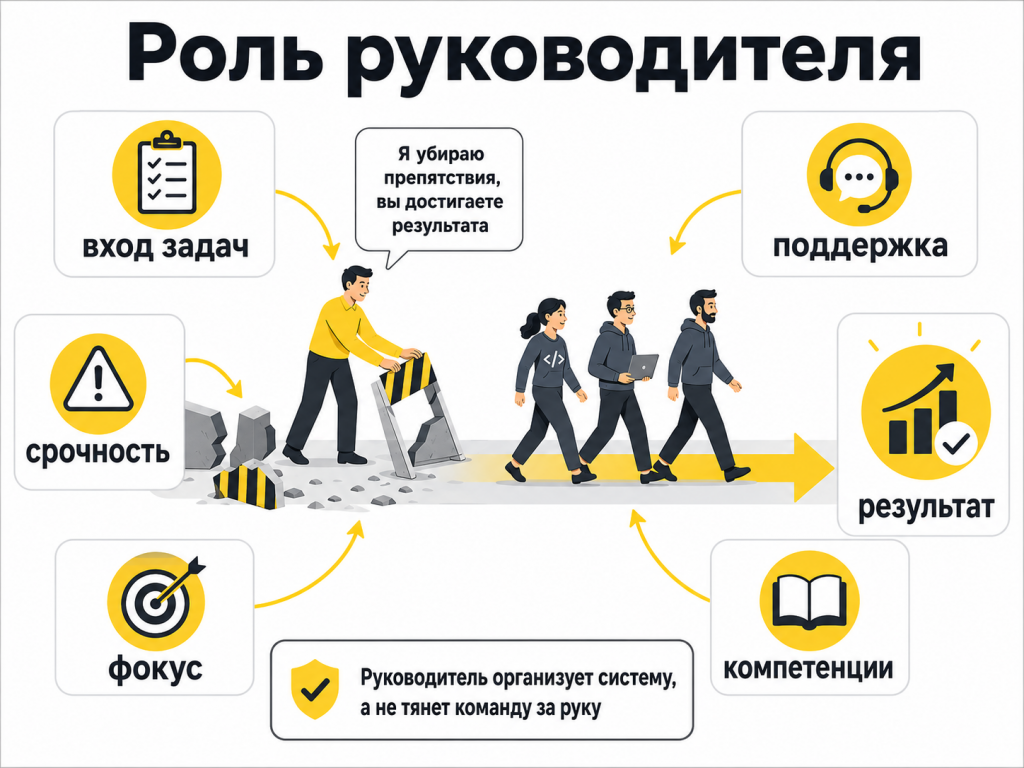
Тимлид не пишет код за всех, но влияет на экономику результата
Иногда роль тимлида или руководителя разработки недооценивают. Мол, результат делают разработчики.
На практике эффективность команды — это не просто сумма эффективности отдельных людей.
Разработчик может быть сильным, но если его весь день дергают по случайным обращениям, он будет двигаться медленнее. Если задачи уходят в разработку без ясных критериев готовности, команда заплатит переделками. Если у поддержки нет правил эскалации, разработчики постепенно станут дорогой первой линией.
Для меня сильный тимлид в разработке — это не тот, кто лучше всех говорит про мотивацию. Я бы смотрел проще: замечает ли он, где команда каждый день теряет время, и делает ли с этим хоть что-то системно.
Где чаще всего теряется результат
Вход задач
Если задачи заходят в команду хаотично, команда рано или поздно начинает работать в этом же хаосе.
Часть задач приходит через трекер, часть — через личку, часть — от поддержки или внутреннего заказчика, который “просто спросил, можно ли быстро”. В итоге трудно управлять очередью, приоритетами и ожиданиями.
Пользователь просит “маленькую доработку”, а за ней оказывается изменение типового сценария, влияние на права, печатную форму, обмен или обновление.
Например, просьба “добавить поле в документ” может потянуть за собой форму, права, заполнение по умолчанию, печатную форму, обмен с другой системой и поведение при обновлении. Если это не увидеть на входе, разработчик формально сделает задачу, а потом она начнет возвращаться кусками.
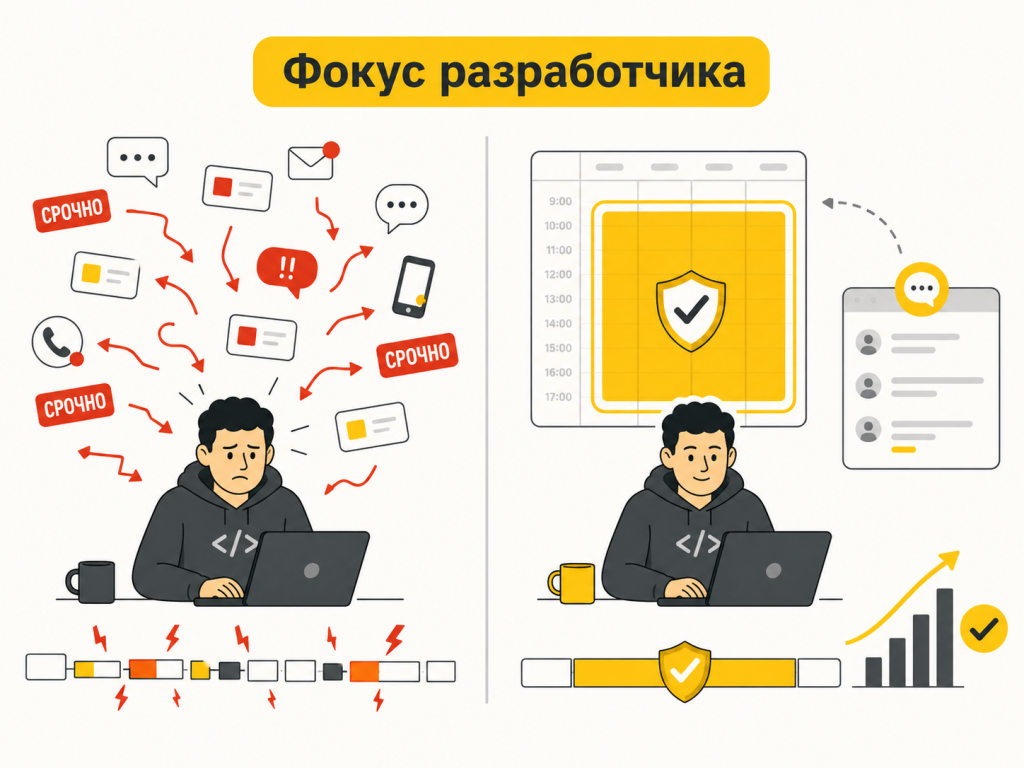
Срочность и фокус
Срочные задачи есть в любой IT-команде. Проблема начинается, когда срочным становится почти все.
Если каждый второй запрос получает повышенный приоритет, команда перестает понимать, что действительно важно. Приоритет превращается в эмоциональную метку: кто громче попросил, тот и срочный.
Я бы здесь смотрел не на слово “срочно”, а на последствия: остановлен ли процесс, заблокированы ли пользователи, есть ли обходной путь, что случится, если сделать завтра.
И еще один вопрос, который часто забывают: что мы снимаем из работы, если берем это прямо сейчас?
Фокус разработчика легко разрушить. Разработчик только погрузился в задачу — его дернули. Вернулся — нужно заново вспомнить контекст. К вечеру человек не бездельничал, но сложная задача почти не двигалась.
Не все отвлечения можно убрать. Но их можно сделать управляемыми: договориться с поддержкой об эскалациях, выделить окна для несрочных вопросов, не превращать личку в таск-трекер.
Компетенции
Есть ловушка: команда может быть постоянно занята, но не становиться сильнее.
Задачи закрываются. Релизы выходят. Инциденты чинятся. Но через год команда не стала самостоятельнее, не научилась лучше проектировать решения, не стала увереннее проходить review, не разобралась глубже в типовых механизмах.
Сложность редко стоит на месте.
Один разработчик хорошо знает нюансы расширений. Второй лучше разбирается в обменах. Третий понимает, почему запрос начал тормозить на объеме. Если этот опыт остается только в головах отдельных людей, команда становится зависимой от случайного распределения знаний.
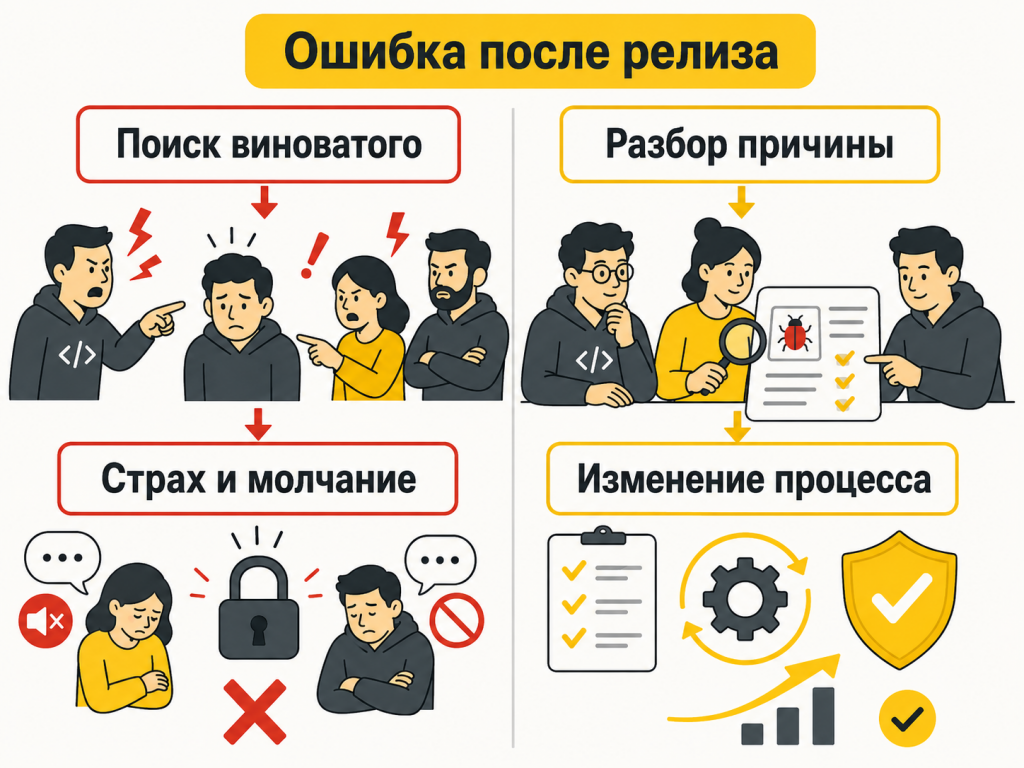
Ошибки после релиза
Ошибки в разработке будут всегда. Вопрос не в том, можно ли построить команду без ошибок. Нельзя. Вопрос в том, что происходит после ошибки.
В одной команде после проблемного релиза начинается поиск крайнего: кто делал, кто проверял, почему пропустили. Иногда эти вопросы нужны. Но если разговор сводится только к виноватому, команда быстро учится защищаться.
Люди начинают позже говорить о рисках, осторожнее признают сомнения и меньше задают неудобные вопросы.
В сильной команде ошибка разбирается иначе: что произошло, где можно было поймать раньше, был ли понятен сценарий, хватило ли проверки, не повторяем ли мы одну и ту же проблему.
Такие разборы особенно полезны после доработок типовых механизмов. Вроде поправили один сценарий, а потом после обновления, на другом виде документа или в обмене вылез побочный эффект. Если просто исправить дефект и не разобрать причину, похожая история вернется.
Почему “заряженная команда” — не про горящие глаза
Я специально не хочу сводить эту тему к мотивации.
Команда не обязана каждый день быть бодрой, вдохновленной и счастливой. Люди могут уставать, спорить, сомневаться, раздражаться на странные требования и не любить отдельные задачи.
Для меня сильная команда видна не по лозунгам, а по поведению: раньше поднимает риски, спокойнее обсуждает ошибки, быстрее уточняет непонятное, не превращает каждую срочность в аврал.
И почти всегда за этим стоит не магия мотивации, а рабочая система, которую не пустили на самотек.
Исследования — только как ориентир
Мне не нужны исследования, чтобы поверить, что хаос влияет на результат. Это видно в обычной работе: по переносам сроков, переделкам, нервным релизам и усталости людей.
Но исследования полезны как напоминание: состояние команды — это не только настроение, а рабочий фактор. Gallup связывает вовлеченность рабочих единиц с бизнес-результатами. Google re:Work в материалах Project Aristotle выделяет психологическую безопасность, надежность, структуру и ясность, смысл работы и понимание влияния результата.
Я бы не переносил эти выводы напрямую на любую команду. Для меня это ориентир: люди должны понимать, что делают, видеть приоритеты, верить договоренностям и иметь возможность сказать о риске до того, как риск стал аварией.
Расчет на пальцах
В реальной жизни никто не измеряет это идеально. Но масштаб можно прикинуть.
Есть команда из 10 человек. Условно считаем, что ФОТ одинаковый, рабочий год одинаковый, ставки сопоставимые.
Если за счет более нормальной организации работы команда дает на 10% больше полезного результата, это примерно как дополнительный результат одного специалиста за год. Без увеличения ФОТ.
Не потому, что людей заставили работать вечерами. А потому, что меньше времени сгорело на переключениях, переделках, непонятной срочности и повторяющихся ошибках.
Если разница 15%, это уже примерно полтора специалиста по годовому результату.
Если смотреть на сильный сценарий — 20%, — я бы не подавал это как обещание. Но для команды, где раньше было много хаоса, слабая работа с поддержкой и почти не было развития компетенций, такой масштаб разницы на дистанции выглядит рабочим ориентиром.
Это не точный калькулятор. Нельзя взять любую команду, назначить “правильного” тимлида и автоматически получить плюс 20%. Но расчет помогает увидеть масштаб.

Что можно изменить
Я не верю, что команду можно быстро “перезарядить” одним совещанием или красивой презентацией. На практике я бы начинал с мест, где команда теряет время почти каждый день.
Сначала — вход задач. Должно быть понятно, где живет задача, кто ее уточняет, кто определяет приоритет и кто принимает результат. Личка может помогать общению, но она не должна заменять очередь.
Потом — срочность. Если приходит новый высокий приоритет, я бы сразу спрашивал: кто заблокирован, что будет завтра, есть ли обходной путь и что снимаем из текущей работы.
Отдельно — поддержка. Она не должна тащить к разработчику каждое сырое обращение. Нужны простые правила: что является инцидентом, что консультацией, какие данные нужно собрать до эскалации.
После релиза важно смотреть не только на дефект, но и на причину: почему ошибка дошла до пользователей, где ее можно было поймать раньше, что меняем в проверке или review.
И еще один пункт — компетенции. Команда не растет автоматически от количества задач. Нужны разборы сложных решений, обмен опытом и постепенное усложнение зоны ответственности.
Что я не утверждаю
Я не утверждаю, что все зависит только от руководителя. Есть сложность продукта, наследие старых решений, качество входящих требований, состояние архитектуры, внешние ограничения, уровень заказчика, срочные инциденты.
Я не говорю, что зарплата не важна. Важна. Плохой оплатой сильную команду не удержать.
Я не предлагаю выжимать из людей больше за те же деньги. Хорошая рабочая система нужна не для того, чтобы люди работали больше, а чтобы они меньше теряли силы на хаос.
Я не предлагаю строить команду на лозунгах, “горящих глазах” и разговорах про семью.
Финальный вывод
Две команды могут стоить бизнесу примерно одинаково.
Но одна через год будет спокойнее выпускать релизы, быстрее доводить задачи до результата и увереннее проходить сложные участки разработки. А другая будет весь год занята, уставшая, нужная бизнесу, но постоянно теряющая часть результата в срочности, переключениях и переделках.
Разница не всегда в том, что в первой команде собрались супергерои.
Часто разница в том, что в одном случае рабочую систему выстраивают, а в другом команда невольно остается жить в хаосе.
Сильная команда не обязательно работает больше. Часто она просто меньше теряет: на неясных задачах, случайных переключениях, конфликтах, повторных ошибках и постоянной срочности.
Это вопрос управления: кто защищает фокус, проясняет приоритеты, развивает компетенции, разбирает причины ошибок, показывает команде результат и не дает оплаченным часам каждый день утекать в хаос.
И вот это, на мой взгляд, часто и отличает просто занятую команду от команды, которая за тот же год реально продвинула продукт, а не только героически пережила очередной поток задач.